
Cloud first was the default architecture for computer vision systems for many years. Every frame was streamed to a remote server, and every prediction was generated in a centralized data center.
Today, that paradigm has shifted. The majority of computer vision inference now runs at the edge. Latency constraints, bandwidth limits, tightening privacy regulations, and the rapid growth of ultra high-resolution sensors have made it inefficient and often impractical to send every frame across the network before making a decision.
The debate has also evolved. It is no longer about cloud or edge, but about where each piece of logic should reside. The most advanced computer vision teams are not picking sides; they are deliberately designing systems that combine both.
Cloud Inference for Computer Vision Models
Cloud inference involves running a machine learning or computer vision model on remote servers hosted by providers like Roboflow, AWS, Google Cloud, or Azure, instead of on a local device, by sending data over the internet for processing and receiving the results.
When to Use Cloud Inference
- Foundation Models (SAM 3, Florence-2, VLMs, LLMs): Use the cloud to access large, compute-intensive models that cannot run efficiently on local devices.
- High-Variability Workloads: The cloud is ideal for handling unpredictable or constantly changing data at scale.
- Rapid Experimentation & Prototyping: You can quickly test new models and iterate without provisioning local hardware.
- Massive Ensemble Reasoning: Cloud inference allows running multiple models in parallel to improve overall accuracy.
- Zero-Shot / Few-Shot Generalization: Cloud-based models, such as GPT-5 and Google Gemini 3, can recognize new or unseen data without needing retraining.
The Advantages of Cloud Inference
- Infinite Scalability: You can scale from processing 10 images to millions without provisioning extra hardware.
- Zero Hardware Maintenance: There is no need to update device fleets, manage thermal constraints, or troubleshoot embedded systems.
- Access to frontier models: The latest billion-parameter models, such as Qwen3-235B, are easily available in the cloud and cannot be practically deployed on local devices without incurring significant on-device hardware costs.
The Hidden Costs of Cloud Inference
- Cloud Isn’t Free: While convenient, using cloud resources comes with financial and operational trade-offs that grow with scale.
- Privacy and Compliance Friction: Regulations like GDPR and the EU AI Act can create legal and operational hurdles when sending sensitive data to the cloud.
- Unpredictable Latency: Network congestion and long-distance connections can make inference times inconsistent, which is critical for real-time applications.
- Data Ingress/Egress Costs: Transferring large volumes of data to or from the cloud can be costly, as charges accumulate for every gigabyte moved. Example: A traffic camera continuously streaming 720p video at 10 FPS using H.265 (~1.5 Mbps) would consume approximately 675 MB per hour, 16.2 GB per day, and 486 GB per month. This high data volume can be costly, especially when managing multiple cameras, and may be impractical in bandwidth-constrained locations. By contrast, sending only metadata (~1 kbps) would use just 0.45 MB per hour, 10.8 MB per day, and 324 MB per month, a drastic reduction compared to full video.
RF-DETR Large: Cloud-Based Second-Opinion Orchestration for High-Capacity Vision
RF-DETR is a real-time transformer architecture for object detection and instance segmentation developed by Roboflow. Powered by the DINOv2 backbone, it excels at detecting small objects in aerial imagery such as buildings or vehicles in cluttered satellite scenes, as well as spotting anomalies in high-resolution medical imagery.
DINOv2 also enables RF-DETR with strong generalization capabilities, allowing it to adapt effectively to new domains and significantly improve detection performance.
RF-DETR Large, the most capable and largest variant, is particularly well-suited for cloud deployment. In hybrid architectures, lightweight edge models handle real-time inference on-device, while RF-DETR Large runs in the cloud as a high-precision “second opinion” model.
In this orchestration pattern:
- Edge devices perform low-latency, cost-efficient predictions.
- Uncertain or high-risk cases are escalated to RF-DETR Large in the cloud.
- The cloud model validates, refines, or corrects edge predictions.
- Feedback can be logged to continuously improve edge models over time.
This approach combines the speed of edge inference with the accuracy and contextual reasoning of large-scale transformer models, resulting in a scalable, high-reliability vision system.
On-Device (Edge) Inference for Computer Vision
Edge inference is the process of running a machine learning or computer vision model directly at the edge, where the results are generated, on devices such as smartphones, IoT devices, embedded systems, industrial cameras, or edge computers like NVIDIA Jetson and Raspberry Pi, instead of sending the data over the internet to remote cloud servers for processing.
When to Use On-Device (Edge) Inference
- Real-Time Robotics: Use edge inference when machines must react instantly to their environment, where even small network delays could cause failure or safety risks.
- Industrial Automation: Deploy models directly on factory hardware to ensure low-latency decision-making and uninterrupted operation, even if connectivity is unstable.
- Remote IoT Applications in Agriculture and Mining: In remote locations with limited or unreliable internet access, edge inference enables autonomous operation without constant cloud connectivity.
- High-Security Environments: Keep inference on-device when data cannot leave the premises due to security policies, regulatory requirements, or operational sensitivity.
- High-Resolution Streaming Constraints: Run detection locally when continuously streaming high-resolution video (e.g., 4K at 30 FPS) to the cloud would be too costly or bandwidth-intensive.
The Advantages of On-Device (Edge) Inference
- Sub-10ms Reflex Speeds: Because inference runs directly on the device, there is no network hop or cloud queueing, enabling near-instant decision-making for time-critical applications.
- Offline Autonomy: Edge systems can continue operating even without internet connectivity, ensuring reliability in remote, unstable, or disconnected environments.
- $0 Marginal Inference Cost: After the hardware investment is made, running additional inferences does not incur per-request API or cloud usage fees, making costs predictable at scale.
- The 4K Reality: Continuously streaming 4K video at 30 FPS from thousands of devices to the cloud is financially and physically impractical.
Hybrid Inference in Practice: License Plate Recognition
A modern License Plate Recognition system is a clear example of how edge and cloud inference work together in a hybrid architecture.
A high-resolution camera continuously captures a wide scene so that even small or distant license plates remain detectable. An edge model (object detection model) runs locally to identify vehicles and detect license plates in real time.
Once detected, the plate region is cropped directly on the device, and only that small, relevant image is sent to the cloud instead of the entire 4K frame. In the cloud, an OCR model or Vision-Language Model (VLM) performs text recognition, validation, and higher-level reasoning such as database lookups or anomaly detection.
The workflow below demonstrates this end-to-end pipeline: edge-based object detection identifies vehicles and license plates, crops the relevant regions, and forwards them to the cloud, where advanced language-vision model (Open AI’s GPT-4 Vision) extract and interpret the license plate text:
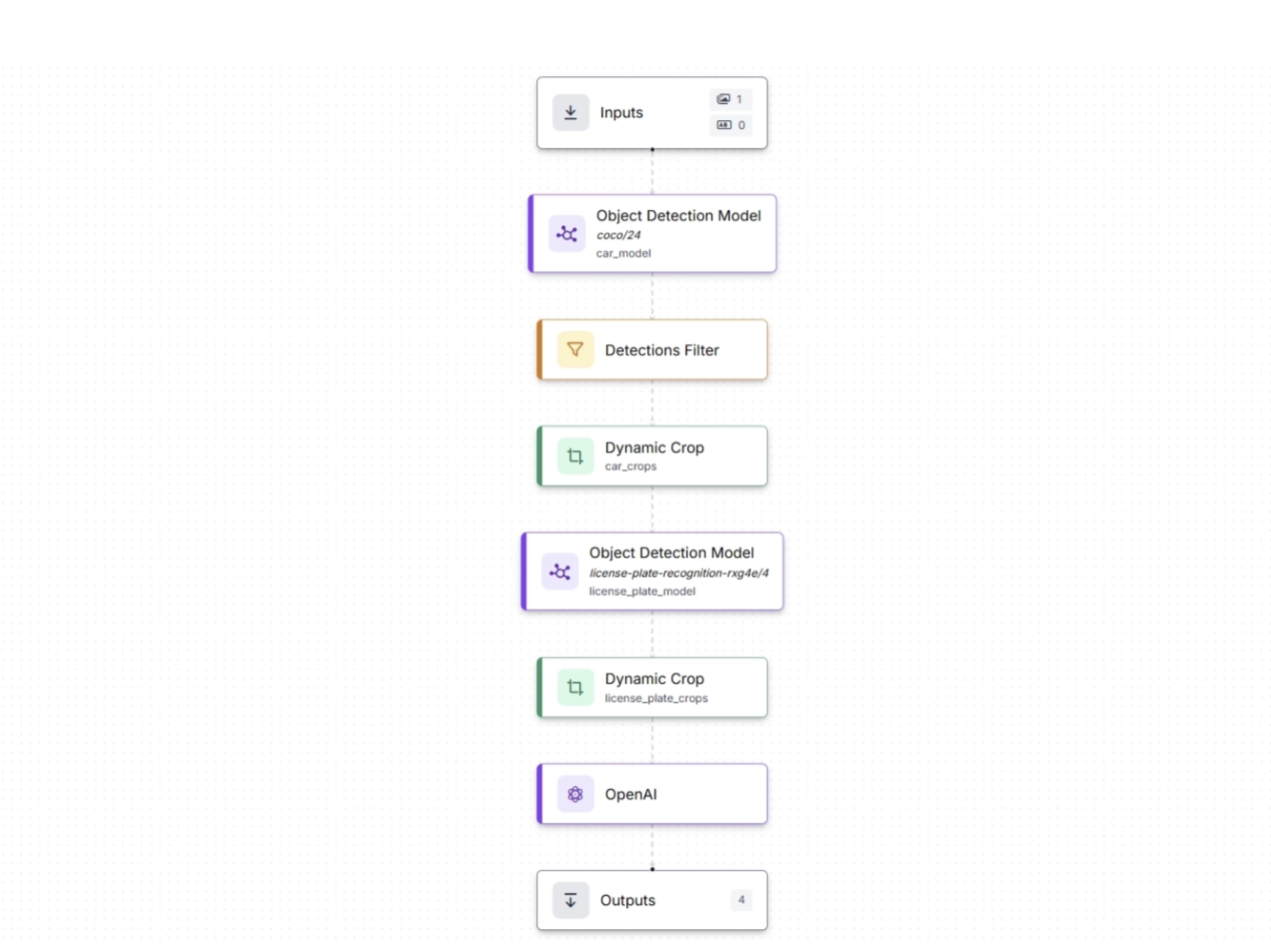
This system preserves bandwidth by sending only cropped license plate images, reduces costs by minimizing data transfer and cloud compute usage, and maintains high detection quality through local high-resolution processing. You can read more about the above workflow in this blog.
Rather than choosing between edge and cloud, it combines fast on-device filtering with deeper cloud-based reasoning.
RF-DETR-Nano/Small: Debunking the Myth That Transformers Are Too Heavy for Edge Devices
Transformers were long considered too heavy for edge devices, but RF-DETR-Nano and RF-DETR-Small challenge this assumption. These models deliver real-time performance comparable to traditional YOLO CNN architectures while maintaining high accuracy, proving that transformers can be both powerful and efficient on edge hardware.
Performance Highlights (Measured on NVIDIA T4 GPU)
- RF-DETR-Nano: 48.4 mAP (50–95) and 2.32 ms latency
- RF-DETR-Small: 53.0 mAP (50–95) and 3.5 ms latency
- YOLOv11-N: 37.4 mAP (50–95) and 2.49 ms latency
- YOLOv11: 44.4 mAP (50–95) and 3.16 ms latency
These results show that RF-DETR-Nano surpasses YOLOv11-N in both accuracy and speed, while RF-DETR-Small achieves even higher accuracy than YOLOv11 without sacrificing competitive speed, making both RF-DETR Nano and Small ideal transformer options for edge deployment.
Technical Advantage of RF-DETR: NMS Free Detection
Non-Maximum Suppression (NMS) is a post-processing technique used in object detection to remove duplicate or overlapping bounding boxes that refer to the same object.

Traditional YOLO models rely on Non Maximum Suppression to filter overlapping bounding boxes. This step introduces additional latency and is often excluded from standard benchmarks.
RF-DETR removes manually designed post processing components such as NMS, allowing the model to operate as a fully end to end detector.
Because RF-DETR eliminates dynamic steps like NMS, the entire pipeline from input image to final prediction becomes fixed and predictable. This static execution graph enables CUDA graphs to capture the complete sequence of GPU kernels and submit them together before execution begins.
As a result, the GPU executes the full detection pipeline independently, without repeatedly synchronizing with the CPU for the next instruction. This standardizes inference and significantly reduces latency.
By offloading kernel management entirely to the GPU, RF-DETR eliminates the CPU overhead associated with launching individual operations, which is a major source of delay in real time applications.
Reducing CPU overhead through CUDA graphs is a general optimization principle that typically delivers even greater performance gains on embedded platforms such as NVIDIA Jetson devices, where CPU resources are more constrained than on desktop class GPUs.
The Roboflow Edge: Inference-Agnostic Workflows
Most platforms force you to choose between cloud and edge, but that’s the wrong perspective. Cloud and edge aren’t separate architectures; they are just deployment targets.
The true architecture is your workflow logic, designed once and able to run wherever it makes the most sense: on the cloud, on the edge, or across both.
Roboflow treats cloud and edge purely as deployment targets, giving you the ability to build workflows independent of where they run and to orchestrate both cloud and edge seamlessly as part of a unified system.
Build Once, Deploy Anywhere
Roboflow Workflows allows you to define the logic once, for example, “if a person is detected AND no helmet is worn → trigger an alert”, and deploy it anywhere, including NVIDIA Jetson, Mobile iOS, or an AWS instance, whether on edge or in the cloud. The workflow itself remains unchanged; only the runtime environment varies.
On the cloud, Roboflow Workflows can be seamlessly deployed using its cloud hosting options, which handle all infrastructure. This includes serverless APIs for instant scaling, dedicated deployments for high-volume predictable workloads, and batch processing for efficiently handling large datasets.
For edge deployment, Roboflow Workflows can run on any edge device via Roboflow Inference, an open-source server that enables workflows to run directly on devices like NVIDIA Jetson or Raspberry Pi.
The Active Learning Loop: Cloud Teaches Edge
The edge runs a lightweight model for real-time decisions, sending only low-confidence or anomalous cases to the cloud.
The cloud stores these cases and uses them to retrain stronger models, which are then redeployed to the edge. Rather than streaming all data, only uncertain cases are sent, creating a system where the cloud learns and the edge executes.
One such active learning workflow is shown below, where the workflow runs on an edge device and both the predictions and the original images are sent to the cloud and saved as part of a dataset for future model training:
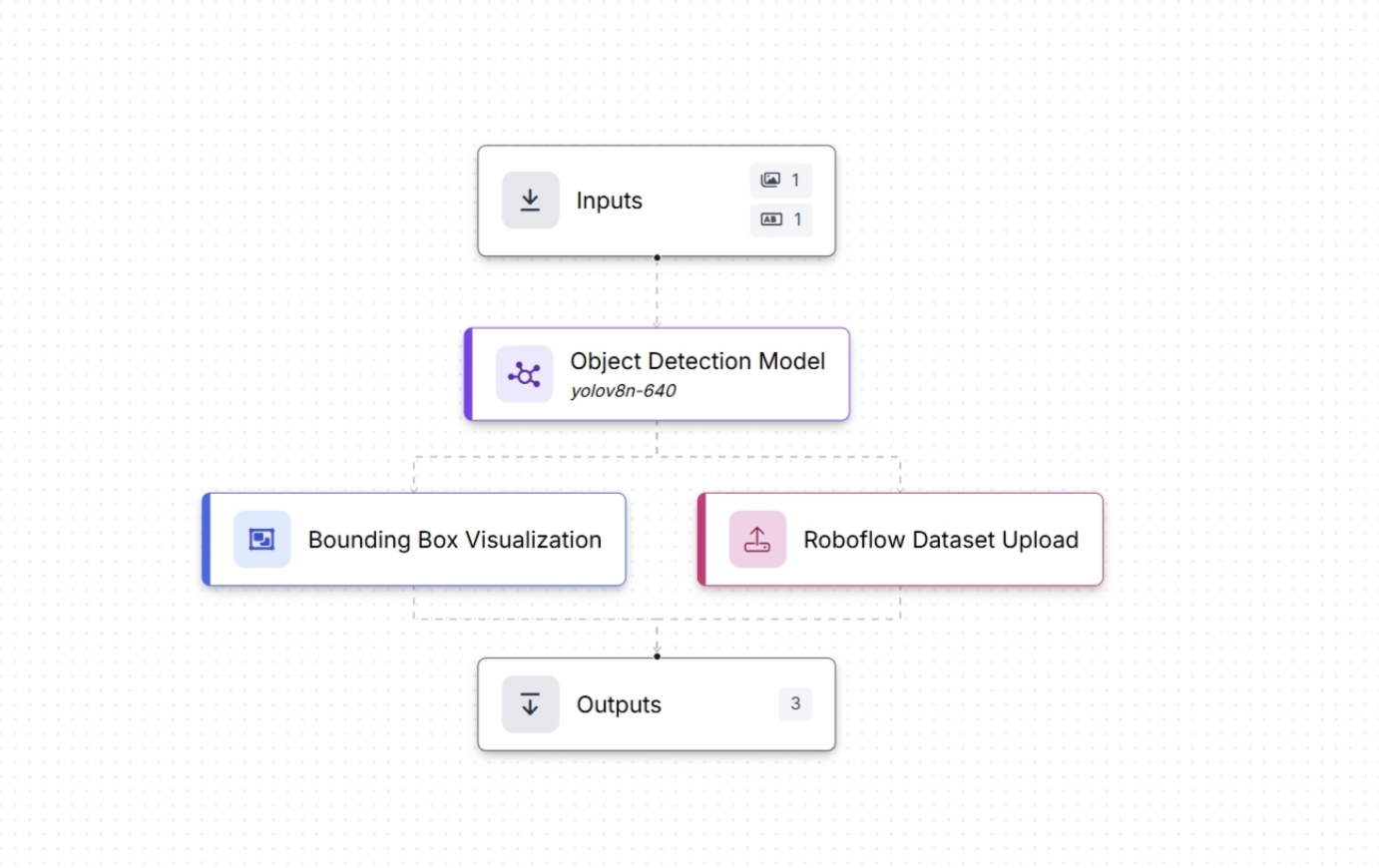
The video below demonstrates the same workflow tested on the Roboflow web app using an image of a container, where both the image and the generated predictions are sent to the cloud (Roboflow Universe) by the workflow and can be used to train new versions of the model.
This blog explains the complete active learning loop shown in the video above.
Deployment Portability
Using the same Docker container across environments ensures consistency from local laptops to gateways and cloud APIs. It prevents environment drift, reduces debugging friction, and accelerates iteration, making it easier to ship improvements quickly and reliably.
Roboflow Workflows are deployed via Roboflow's Inference Server, which runs in Docker containers and provides an isolated, consistent runtime regardless of the host system.
Cloud and On-Device Inference for Computer Vision Models Conclusion
The best computer vision workflows combine on-device reflexes with cloud-based reasoning. On-device systems handle immediate tasks such as detection, which enables prediction-based cropping and filtering to reduce bandwidth usage. The cloud applies larger models to provide broader context, handle rare cases, and generate more complex predictions, while retraining pipelines continuously and automatically update edge models over time.
Business logic can run anywhere, enabling a single workflow across all deployment targets. Get started today.
Written by Dikshant Shah
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Feb 16, 2026). Comparing Cloud and On-Device Inference for Computer Vision Models. Roboflow Blog: https://blog.roboflow.com/comparing-cloud-and-on-device-inference/