
Atos, a digital transformation firm with over 100,000 employees, built a privacy-first office occupancy counter using computer vision and Roboflow, going from initial data collection to a production client demo running on an NVIDIA Jetson Nano in under 60 days. The system connects to existing security camera feeds, anonymizes individuals before any data is logged, tracks entry and exit events frame-by-frame using bounding box overlap logic, and uses the Roboflow Upload API to feed low-confidence frames back into the training set for continuous improvement.
Building & deploying a privacy-first model to the edge with Roboflow in 60 days
The COVID-19 pandemic changed how and where we work. Fortunately, in some countries, the pandemic appears to be nearing its final act. As companies around the globe make measured decisions regarding returning to the office, keeping track of office occupancy levels is ever important.
Atos, a global leader in digital transformation with over 100,000 employees worldwide, is leveraging computer vision with Roboflow to automate the task of counting entrants and exits at office buildings. In doing so, Atos enables companies to have robust, consistent analytics on the movement of people in and out of its clients' offices. The vision model also connects to security camera feeds that the office already has in place, ensuring the implementation is easy. Lastly, automating the process reduces the costs associated with otherwise manually staffed counting and logging.

Moreover, it's worth noting that, while in this context Atos is logging entrance and exit for COVID safety, the ability to keep track of people flows has valuable implications for sporting events, in-person retail, and much more.)
Building a System to Anonymously Count Office Entrance and Exit
When developers at Atos embarked on the mission to build a system that would keep track of office occupancy, they knew a number of factors would need to be considered, including:
- How much video will be required to train a model? How should the data be organized and prepared?
- How accurate will the model be?
- Can the model identify what a person is as well as keep track of how many there are across video frames?
- What hardware should the system run on? How fast will it be?
- How does the system ensure individual privacy and network security?
The the power of Roboflow's tools, Atos had a working production system for client demonstration in less than 60 days. This is largely thanks to using a system that is an end-to-end computer vision platform: a product that helps developers organize, annotate, preprocess, train, deploy, and monitor the ongoing success of their models in production for continued improvement.
 Kaylee Williams
Kaylee Williams
Notably, the developers on this project at Atos were experienced in .NET and software engineering yet this would be among the first foray into machine learning and computer vision. Equipped with computer vision tools built for software engineers, a developer focused on this project was able to build an accurate and robust production system quickly.
Before going step-by-step, let's take a look at a longer clip to get a sense of what the system looks like in production:
A short clip of Atos's office occupancy tracker working.
Note in the upper-right hand corner of the frames that the system is keeping track of the number of people up and down at any point in time. Moreover, the system is logging the FPS (frames per second) to demonstrate it is running in real-time. The boxes around the people indicate the model is finding individuals, and the associated percentages are how confident the model is in its predictions.
Because Atos planned to run the system on the edge, all video would be analyzed locally without any external network access. The model would also be trained to only understand what pixels constituting the shape of a person are – not specific identification of any one individual's identity. All counts are anonymous: the model knows what a person is, not who it is.
Data Collection and Organization
In order to build a custom model, Atos knew they would need to collect data from the conditions where the model was going to run in production. Because Atos planned to leverage active learning with Roboflow, they were able to get going with only 800 images to deploy a successful initial model. Each of the 800 images were annotated with bounding boxes around people in the images.
Atos also leveraged image augmentation to increase the size and variety of the sample dataset. Specifically, Atos generated 5x more training data with variations of lighting, zoom, contrast, and more.
Jacob Solawetz
Model Development and Deployment to NVIDIA Jetson Nano
Once the dataset was fully prepared, Atos trained a model with Roboflow Train. Because Atos is identifying people in a real-world context, the team used transfer learning starting from the COCO dataset. Said another way: Atos used all the knowledge the model had learned on people in images in other contexts as starting points for the new model fine tuned on their images. This accelerates model training and increases accuracy.
Atos deployed the model to a NVIDIA Jetson Nano. The following video shows how to deploy a model to the Jetson Nano:
Atos experimented with using Microsoft Azure Custom Vision for model training and deployment as well. Atos discovered three key differences in the system developed with Azure compared to Roboflow: model accuracy, model speed, and developer experience.
With Microsoft Azure, the trained model worked similarly well to the model Atos trained with Roboflow. In a frame-by-frame comparison, both models identified persons successfully. However, the model trained with Roboflow (below, right) demonstrated greater confidence in its predictions than the model trained with Azure (below, left).
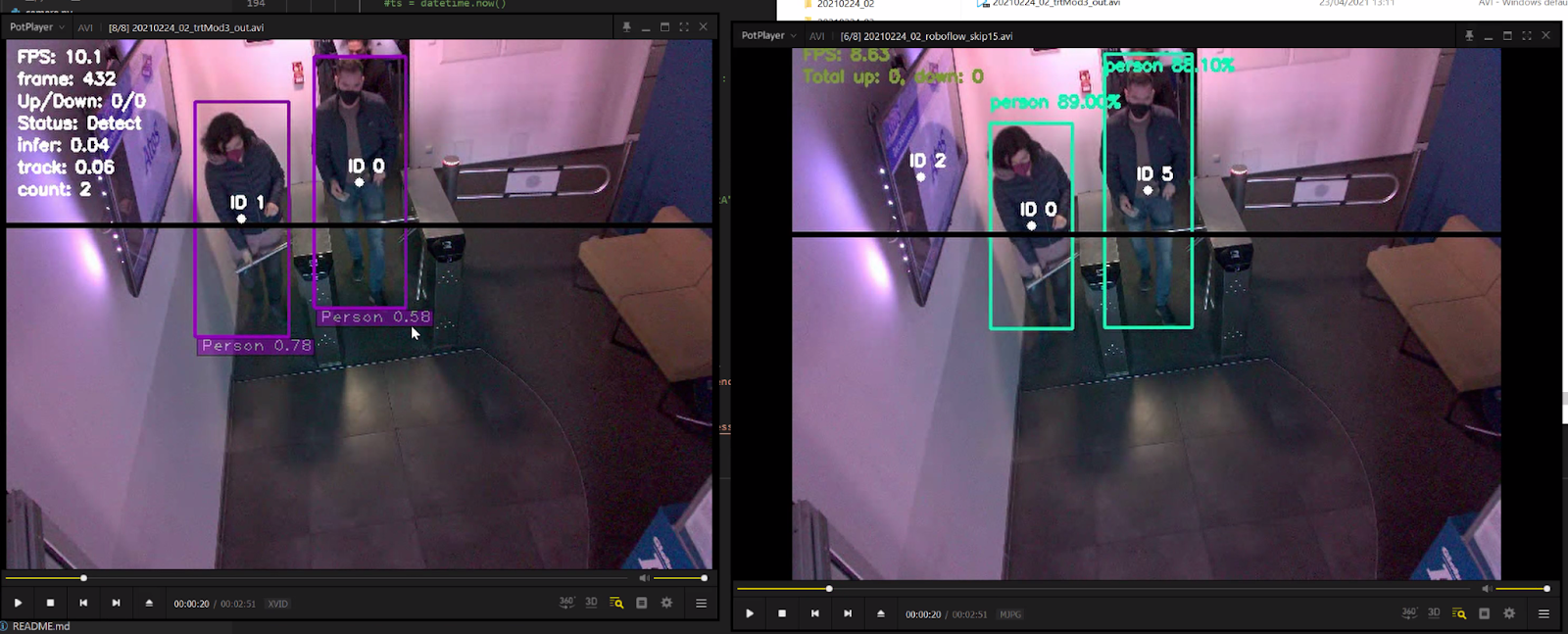
When it came to speed, both trained models achieved the speed performance expectations required for production. Atos leveraged a clever trick to ensure high frame throughput on a constrained compute edge device: they sample every 10th frame from the video stream, which enabled the system to run fast enough to keep up with human movement. In the comparison above, note that the Azure model outputs at roughly 10 FPS and the Roboflow model is outputting roughly 8.6 FPS.
Lastly, when it came to developer experience, Atos found significant advantage to leveraging Roboflow. The Roboflow Train model was able to be run on the Jetson Nano with only three lines of code. By comparison, the model from Custom Vision required many format conversions to obtain a model workable on the Jetson Nano. The model came downloadable in an ONNX format that doesn't work natively with the version of Jetpack available on the Nano. Getting the Azure model deployed took days of configuration compared to minutes with the Roboflow model. Moreover, because Roboflow is end-to-end, any future dataset and model improvements could seamlessly be incorporated for future deployments.
Details for Production: Privacy, Active Learning, and Display
As noted above, the system was architected such that the model would run entirely on the edge on a NVIDIA Jetson Nano. This means video being analyzed would not be externally accessible by default. In addition, the model would be trained to recognize what pixels make the shape of a person rather than learning the identity of any one individual. As such, all model predictions are completely anonymized.
Once the team had an acceptable initial model, they wrote custom logic that logs detections frame-by-frame to keep track of objects in view. This ensured that once a person was found in one frame, they were logged in subsequent frames (as long as the bounding boxes were similar in overlap). Note that in the example media, there's a black line across the center of the frame. When a bounding box crosses this frame going north-to-south, "Down" is logged and when a bounding box goes bottom-to-top "Up" is logged.
As a final touch, the team considered how to incorporate active learning to ensure the model would continue to be performant in an ongoing basis. Active learning means monitoring model performance and continuing to collect data from production conditions so that the system continuously improves. In this case, that includes things like adding logic to save a given anonymized frame when model confidence is below a given threshold, and then (with client consent) using the Roboflow Upload API to automatically add that frame back to the dataset for future annotation, training, and redeployment.
Voila! A production-ready occupancy counter running in real-time on the edge.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Jul 7, 2021). How Atos Uses Computer Vision to Monitor Office Occupancy. Roboflow Blog: https://blog.roboflow.com/computer-vision-people-counting-atos/