
Depth estimation is a computer vision task in which a model predicts the distance between the camera and objects in an image or a video frame. The result is a depth map: a gradient image where brighter pixels represent closer objects and darker pixels represent farther ones.
This depth map helps machines understand the 3D structure of an environment, making it useful in applications such as autonomous driving, robotics, augmented reality, and 3D scene reconstruction.
In this blog, we’ll explore various depth estimation models such as Depth Anything V2, DepthCrafter, MiDaS, Depth Pro, Marigold, and FoundationStereo, highlighting their strengths and weaknesses, comparing their performance, and offering recommendations to help you select the model that best fits your needs.

Comparing Popular Depth Estimation Models
Below, we compare several popular models used for depth estimation in terms of their strengths, weaknesses, benchmark performance, and outputs.
The commonly used metrics for comparing depth estimation models include:
- AbsRel: It measures the average relative error between predicted and true depths (lower is better).
- δ₁: Represents the percentage of pixels where the predicted depth is within 25% of the true depth (higher is better).
- F1: In the context of depth maps, it measures boundary accuracy. Specifically, it evaluates how well the model traces sharp object boundaries in the depth maps (higher values are better).
In the case of depth estimation using stereo images, common metrics include:
- BP-2 (Bad Pixel 2): BP-2 is the percentage of pixels in a stereo image where the disparity error, defined as the difference between the predicted disparity and the ground truth disparity, exceeds 2 pixels. Disparity is the horizontal difference of a point between the left and right images of a stereo pair (lower values are better).
- D1: D1 measures the percentage of pixels in a stereo image whose disparity error is greater than 3 pixels and exceeds 5% of the ground truth disparity value(lower values are better).
- EPE (End-Point Error): EPE represents the average per-pixel disparity error across the entire image (lower values are better).
1. Depth Anything V2
Depth Anything V2 is a monocular depth estimation model that generates robust, fine-grained depth maps, capturing intricate details and performing reliably across diverse and complex scenes.
Monocular depth estimation infers depth from a single RGB image, unlike stereo or multi-view approaches, which require two or more images captured from different viewpoints.
Depth Anything V2 produces relative depth predictions, showing which pixels are closer or farther from the camera without estimating absolute real-world distances.
Key Characteristics
It improves upon its predecessor Depth Anything V1 by focusing on three key practices:
- Replacing all labeled real images with precise synthetic images for training the teacher model.
- Scaling up the teacher model’s capacity and using it to generate pseudo labeled real images
- Training lightweight student models on these large scale pseudo labeled real images, enabling them to generalize effectively to real world data while being faster and more efficient for deployment.
- The image below demonstrates these practices:

Strengths
- Compared with recent models built on Stable Diffusion, such as Marigold, the Depth Anything V2 variants are significantly more efficient (over 10× faster), have fewer parameters, and achieve higher depth accuracy.
- Depth Anything V2 produces robust predictions for complex scenes, including but not limited to intricate layouts, transparent objects (e.g., glass), and reflective surfaces (e.g., mirrors, screens).
Weaknesses
- Existing synthetic training sets lack sufficient diversity, which may limit the model’s ability to generalize effectively.
Output Comparisons

Benchmarks
- On the DA-2K benchmark, which consists of diverse dynamic scenes designed to evaluate depth estimation accuracy across synthetic and real-world scenarios, Marigold achieved an accuracy of 86.8 percent. In comparison, Depth Anything V2 demonstrated significant improvements, achieving an accuracy of 95.3 percent for the Small model with a Vision Transformer backbone (ViT-S).
- On the KITTI dataset, which features real-world driving scenarios with challenging lighting and environments, MiDaS V3.1 (ViT-L) achieved an AbsRel of 0.127 and δ₁ of 0.850. Depth Anything V2 (ViT-L) outperformed it with an AbsRel of 0.074 and δ₁ of 0.946.
- In terms of latency, Marigold, with 948 million parameters, required 5.2 seconds to process an image while maintaining 86.8 percent accuracy. Depth Anything V2, on the other hand, reached 97.1 percent accuracy in just 213 milliseconds with the Large model, which has between 335 million and 891 million parameters.
2. DepthCrafter
Depth Crafter is a video depth estimation method designed to generate temporally consistent, long depth sequences with fine details for open-world videos.
It addresses the challenge of estimating depth in videos with diverse appearances, motion, camera movements, and lengths, without requiring additional information such as camera poses or optical flow.
DepthCrafter generates relative depth estimations.
Key Characteristics
It is a video-to-depth model trained from a pre-trained image-to-video diffusion model using a three-stage training strategy:
- Stage 1: Train the model on the DepthCrafter realistic dataset (~200,000 paired video-depth sequences derived from binocular videos with varied scenes and motion diversity) with 1–25 frame lengths to adapt spatial and temporal layers for short videos.
- Stage 2: Fine-tune only the temporal layers on longer sequences (up to 110 frames) to capture long-range temporal consistency while keeping memory usage low.
- Stage 3: Fine-tune the spatial layers on the DepthCrafter synthetic dataset (~3,000 sequences from DynamicReplica and MatrixCity, each ~150 frames) to refine fine-grained and precise depth details.
Strengths
- DepthCrafter produces temporally consistent long depth sequences and outperforms Depth-Anything 2 on videos with intricate details in open-world scenarios, without requiring any supplementary information such as camera poses or optical flow.
- Although DepthCrafter is designed for video depth estimation, it can also perform single-image depth estimation and even produce more detailed depth maps than Depth-Anything V2.
Weaknesses
- DepthCrafter is slower than Depth Anything V2, with an inference time of 465.84 ms per frame at a resolution of 1024 × 576 on a single NVIDIA A100 GPU, compared to 180.46 ms achieved by Depth Anything V2.
Output Comparisons

Benchmarks
- On the Sintel dataset, which contains 50 synthetic, dynamic frames commonly used to evaluate performance on challenging motion and texture scenarios, DepthCrafter achieves an AbsRel of 0.270 and a δ₁ score of 0.697. This outperforms Depth Anything V2 (0.367 / 0.554) and Marigold (0.532 / 0.515), representing a 25.7% improvement in AbsRel.
- On the ScanNet dataset, which consists of 90 indoor, static frames designed to evaluate depth estimation in real-world indoor scenarios, DepthCrafter achieves an AbsRel of 0.123 and a δ₁ score of 0.856. This surpasses Depth Anything V2 (0.135 / 0.822) and Marigold (0.166 / 0.769), representing a 5.4% improvement in AbsRel.
3. MiDaS
MiDaS (Monocular Depth Estimation via a Mixture of Datasets) is a state-of-the-art deep learning approach for monocular depth estimation. It was developed to achieve robust and generalizable depth prediction from a single RGB image by leveraging multiple diverse training datasets with different depth annotation characteristics.
MiDaS generates relative depth estimations.
Key Characteristics
MiDaS is characterized by the following aspects:
- It addresses the challenge of training depth estimation models on datasets that have different depth ranges, scales, and sensing modalities (e.g., stereo cameras, laser scanners, structured light sensors).
- MiDaS uses novel scale- and shift-invariant loss functions in disparity (inverse depth) space, which enable the model to effectively learn from these heterogeneous datasets despite unknown depth scale and global shifts.
- The model training employs a principled dataset mixing strategy grounded in multi-objective optimization to combine datasets in a way that maximizes generalization.
- It introduces a new large-scale dataset derived from 3D movies, with 75,074 training frames extracted from 19 films, providing diverse and dynamic scenarios for training.
Strengths
- MiDaS models demonstrate strong zero-shot cross-dataset transfer ability, performing robustly on unseen datasets without fine-tuning, while also enabling the mixing of multiple datasets during training, even if their annotations are incompatible.
- MiDaS produces plausible depth estimates not only for photographs but also for line drawings and paintings, as long as some visual depth cues remain.
Weaknesses
- Despite advances, MiDaS inherits some biases present in the training data. For example, images may be reconstructed with a bias that the lower parts of the image are always closer to the camera, an artifact also related to how humans annotate depth.
- The model struggles with rotated images and can misinterpret reflections and paintings, inferring depth from content rather than physical placement.
- Common failure cases include hallucinated depth at strong edges, missed thin structures, incorrect relative depths between disconnected objects, and blurred backgrounds due to limited resolution and imperfect far-range ground truth.
Outputs

Benchmarks
According to the MiDaS research paper, benchmarking is performed against a baseline model trained only on the ReDWeb (RW) dataset with a ResNet-50 encoder pretrained on ImageNet.
- On ETH3D, a dataset designed for evaluating high-accuracy metric depth in both indoor and outdoor environments, it attains an AbsRel of 0.129, representing a 14.6% improvement.
- On TUM, which features dynamic indoor scenes with humans and tests the model’s performance under challenging motion and occlusions, it achieves a δ₁ accuracy of 0.8571 and represents a 34.1% improvement.
4. Depth Pro
Depth Pro is a foundational model designed for zero-shot metric monocular depth estimation, delivering high-resolution depth maps from a single image without requiring camera intrinsics or image metadata.
It produces absolute depth maps measured in physical units (meters), free from ambiguity or scale uncertainty.
Key Characteristics
Depth Pro is characterized by the following aspects:
- Zero-Shot Metric Depth Estimation: Requires no camera intrinsics such as focal length, optical center, EXIF metadata, domain labels, or prior tuning on target images, enabling immediate and wide applicability.
- High-Resolution, Sharp Boundaries: Outputs high-resolution (1536×1536 pixels) depth maps that trace fine object structures and boundaries (such as hair, fur, vegetation) with exceptional accuracy.
- Efficient and Fast Inference: Processes inputs rapidly, generating a 2.25-megapixel depth map in just 0.3 seconds on a standard V100 GPU. It leverages a patch-based, multi-scale vision transformer (ViT) architecture with highly parallel operations, making it ideal for interactive and real-time applications.
- Advanced Training with Boundary Focus: Uses a two-stage approach that first leverages real and synthetic datasets for broad generalization, then refines boundary precision on synthetic data using multi-scale derivative losses, designed to perform well even when the ground truth supervision is imperfect or noisy.
Strengths
- Depth Pro generates depth maps at a native resolution of 1536×1536 in just 0.3 seconds on standard GPUs (e.g., V100).
- It provides metric depth outputs with absolute scale, without requiring camera intrinsics.
Weaknesses
- Depth Pro struggles with translucent objects and volumetric scattering scenarios, where pixelwise depth estimation is inherently ambiguous or ill-posed.
- It’s reliance on synthetic datasets for high-quality ground truth may limit realism in certain training scenarios.
Output Comparisons

Benchmarks
- Depth Pro achieves an F1 score of 0.409 on the Sintel benchmark compared to 0.228 for Depth Anything V2, 0.181 for MiDaS, and 0.068 for Marigold, demonstrating 1.8× to 6× better boundary accuracy.
- Depth Pro achieves a δ₁ score of 0.89 on the Sun-RGBD benchmark compared to 0.724 for Depth Anything V2, demonstrating superior zero-shot metric depth accuracy across evaluated models.
5. Marigold
Marigold is a family of models and a fine-tuning protocol designed to repurpose pretrained text-to-image diffusion models (such as Stable Diffusion) for dense image analysis tasks, including monocular depth estimation.
Its protocol leverages the rich visual priors embedded in large-scale generative models by fine-tuning them with small, high-quality synthetic datasets, enabling strong generalization.
Marigold generates relative depth estimations.
Key Characteristics
Core Concepts of Marigold Depth Estimation:
- Generative Conditional Diffusion: Marigold treats depth estimation as a conditional image generation problem, modeling the distribution of depth maps given input RGB images. It starts from a noisy latent representation and progressively denoises it based on input image features, ultimately producing a depth map.
- Affine-Invariant Depth Normalization: Depth maps are normalized for affine-invariance, ensuring that predictions are robust to unknown scale and shift in various scenes. This makes transfer across different datasets and environments reliable.
- Synthetic Data Training: Marigold is trained exclusively on synthetic datasets, which offer complete, noise-free data free from missing pixels and real-world capture artifacts, allowing for dense supervision and efficient learning. Despite this, Marigold demonstrates remarkable generalization across a wide range of real-world benchmarks.
Strengths
- Marigold builds on pretrained Stable Diffusion models, requiring approximately 2.5 days of training on a single NVIDIA RTX 4090 GPU. Inference is fast, running in under 0.1 seconds on standard hardware, making the model accessible to most labs and researchers.
- It performs zero-shot transfer on unseen datasets, achieving state-of-the-art results. Even without using any real images, Marigold can accurately extract depth maps, surface normals, and intrinsic image decompositions.
Weaknesses
- Limited diversity and domain gaps between synthetic and real data, which can sometimes restrict the model's generalization ability.
- Marigold’s default processing resolution of 768 pixels causes large images to lose detail during downsampling and upsampling.
Output Comparisons

Benchmarks
The model demonstrates strong zero-shot generalization, performing well without any real depth annotations:
- NYUv2 is a large indoor RGB-D dataset, where Marigold v1.1 achieves 0.055 to 0.059 AbsRel and 0.961–0.964 δ₁, outperforming MiDaS and approaching Depth Anything V2.
- ETH3D contains high-accuracy depth images for indoor and outdoor scenes, where Marigold-Depth v1.1 achieves 0.069 AbsRel and 0.957 δ₁, surpassing Depth Anything V2.
6. FoundationStereo
Stereo depth estimation computes scene depth from a pair of left and right images by analyzing the disparity between corresponding objects. Although deep stereo matching methods have made significant progress, they typically require domain-specific fine-tuning, retraining models on datasets tailored to particular environments such as driving scenes, indoor spaces, or outdoor settings.
In contrast, vision foundation models like CLIP and DINO have shown remarkable zero-shot generalization, performing effectively across diverse tasks without additional training. FoundationStereo extends this zero-shot capability to stereo depth estimation, enabling a single model to generalize across varied scenarios without the need for domain-specific retraining.
FoundationStereo provides absolute (metric-scale) depth when given stereo image pairs.
Key Characteristics
FoundationalStereo Depth Estimation exhibits several key characteristics such as:
- Trained on the FoundationStereo Dataset (FSD), a large-scale synthetic dataset containing over 1 million diverse, photorealistic stereo pairs that span indoor and outdoor scenes, flying objects, and a variety of camera setups. A self-curation pipeline automatically removes ambiguous or low-quality samples, ensuring high data quality and robustness.
- Integrates monocular priors from large-scale depth models such as Depth Anything V2, leveraging a CNN-based Side-Tuning Adapter (STA) to fuse monocular and stereo features, improving accuracy in ambiguous or textureless regions.
- Employs a GRU-based iterative refinement process that progressively enhances disparity predictions in a coarse-to-fine manner, guided by contextual monocular priors for more precise depth estimation.
Strengths
- FoundationStereo achieves strong zero-shot performance, generalizing to diverse unseen domains, including indoor, outdoor, and texture-challenged environments, without per-domain fine-tuning.
- It is trained on 1 million photorealistic synthetic stereo pairs, automatically curated to remove ambiguous samples, vastly surpassing prior stereo depth models that relied on datasets like Scene Flow with 40,000 pairs.
Weaknesses
- The model is not yet optimized for efficiency, requiring 0.7 seconds to process an image of size 375×1242 on an NVIDIA A100 GPU.
- The dataset used contains only a limited collection of transparent objects, which may restrict the model’s robustness.
Outputs

Benchmarks
- On the Middlebury dataset, which evaluates high-quality indoor stereo images, the model achieves only 1.1 percent BP-2, meaning just one in 100 pixels has an error larger than two pixels.
- On KITTI, a real-world driving benchmark, it achieves D1 errors of 2.3 percent on KITTI-12 and 2.8 percent on KITTI-15, highlighting reliable performance in safety-critical autonomous driving scenarios.
- On the Scene Flow synthetic benchmark, it reduces EPE from 0.41 to 0.33, achieving roughly a 20 percent improvement over previous best models and emphasizing its superior synthetic-to-real generalization.
How to Choose the Best Depth Estimation Model
- Depth Anything V2 offers the best overall balance, providing fast inference at approximately 0.3 seconds per frame, strong robustness across diverse scenes, and high-quality results without significant slowdowns. It is available in multiple model sizes, ranging from Small to Giant.
- Marigold and DepthPro are ideal when quality is prioritized over speed. Marigold excels at capturing exceptional fine details but is relatively slow, taking around 1 to 2 seconds per image. DepthPro, in contrast, delivers sharp boundaries, accurate metric depth, and faster performance, processing a 2.25 megapixel image in approximately 0.3 seconds.
- DepthCrafter is recommended for videos. It is specifically designed for temporal consistency, capable of processing 1 to 110 frames at once (variable length), and effectively eliminates flickering artifacts.
- Foundational stereo methods provide the highest accuracy for stereo camera setups. By leveraging geometric constraints, they produce true metric depth when properly calibrated and are a proven solution for robotics and 3D reconstruction.
- DepthPro delivers true metric depth estimation without requiring camera intrinsics. It includes built-in focal length estimation used to convert the estimated inverse depth into true metric depth with absolute scale.
How to Run a Depth Estimation Model on Roboflow Workflows
Roboflow Workflows is a web-based tool for building visual AI workflows, allowing us to seamlessly chain multiple computer vision tasks, such as object detection, depth estimation, bounding box visualization, and more.
The following steps outline how to create a Depth Estimation workflow using the Depth Anything V2 model on Roboflow Workflows, capable of generating depth maps. Depth Anything V2 provides an excellent balance of speed and accuracy, making it ideal for general-purpose applications such as autonomous driving, robotics, augmented reality, and 3D scene reconstruction.
Step 1: Setup Your Roboflow Workflow
To get started, create a free Roboflow account and log in. Next, create a workspace, then click on “Workflows” in the left sidebar and click on Create Workflow.
You’ll be taken to a blank workflow editor, ready for you to build your AI-powered workflow. Here, you’ll see two workflow blocks: Inputs and Outputs, as shown below:
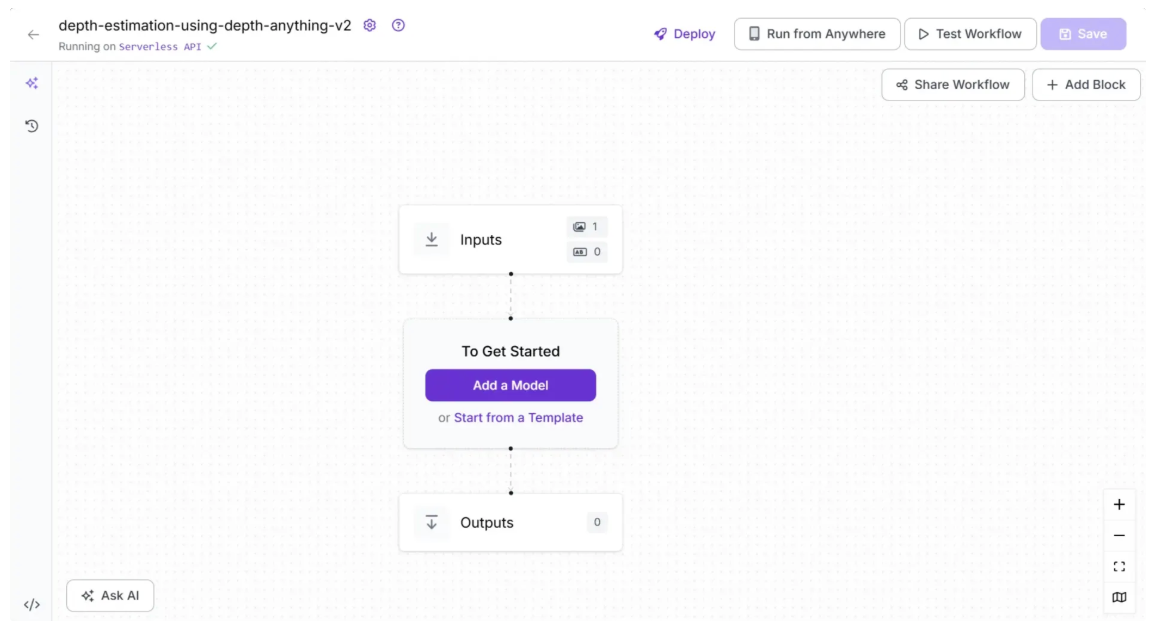
In the top left corner, you’ll see either Running on Serverless Hosted API or Hosted API. Both options support common tasks such as object detection, dynamic cropping, and chaining logic blocks, but neither can perform depth estimation. To include depth estimation support in your workflow, you’ll need a Dedicated Deployment or to self-host your own Roboflow Inference server.
Since our workflow requires depth estimation support, we'll switch to a locally hosted inference server. To do this, click the text that follows Running on in the top-left corner, then select Local Device.
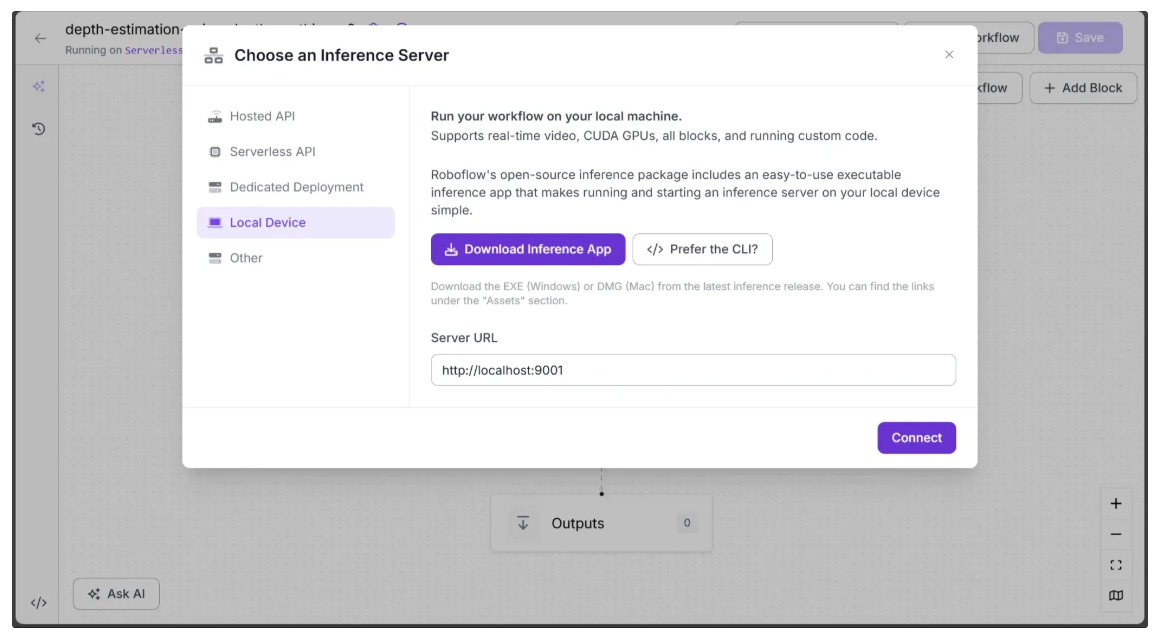
Before connecting to http://localhost:9001, you need to run an inference server on your local device. You can do this either by downloading and installing the Roboflow inference app and running it, which starts a local server on port 9001, or by following the command-line instructions provided here.
Once the local inference server starts, you can verify it by visiting http://localhost:9001 in your browser and click Connect. After connecting, your workflow will run locally on your device.
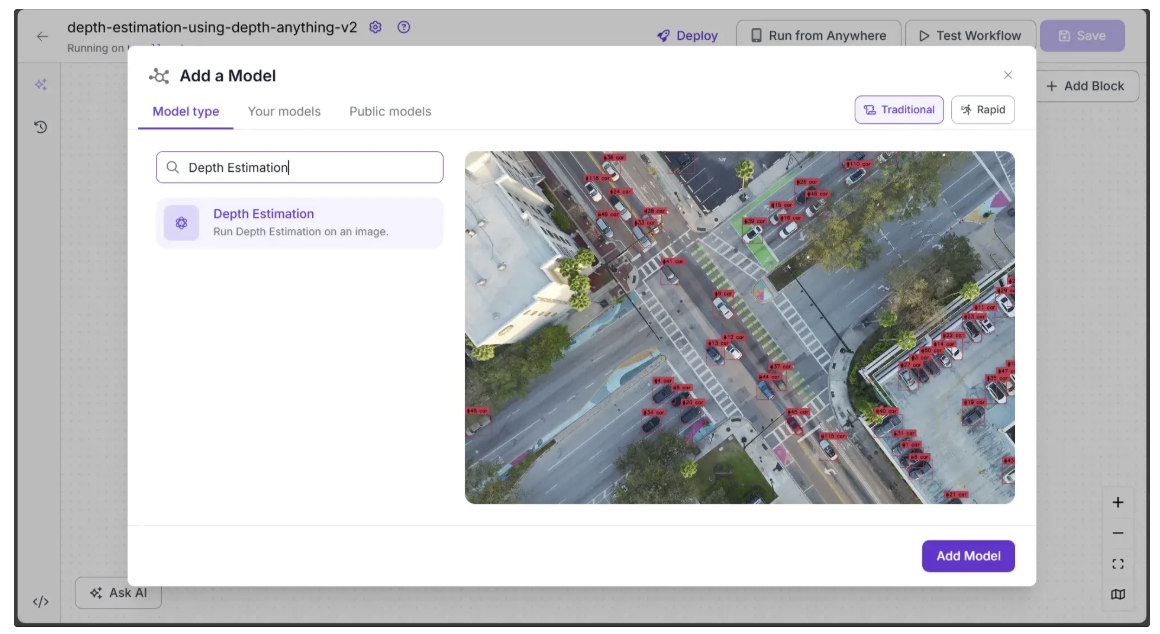
Step 2: Add an Depth Estimation Block
Now, add a Depth Estimation block to your workflow. This block lets your workflow run a depth estimation model without requiring you to set up the model yourself. To do this, click “Add a Model” in the workflow editor, search for “Depth Estimation,” and then click “Add Model.”
Your workflow should now look like this:
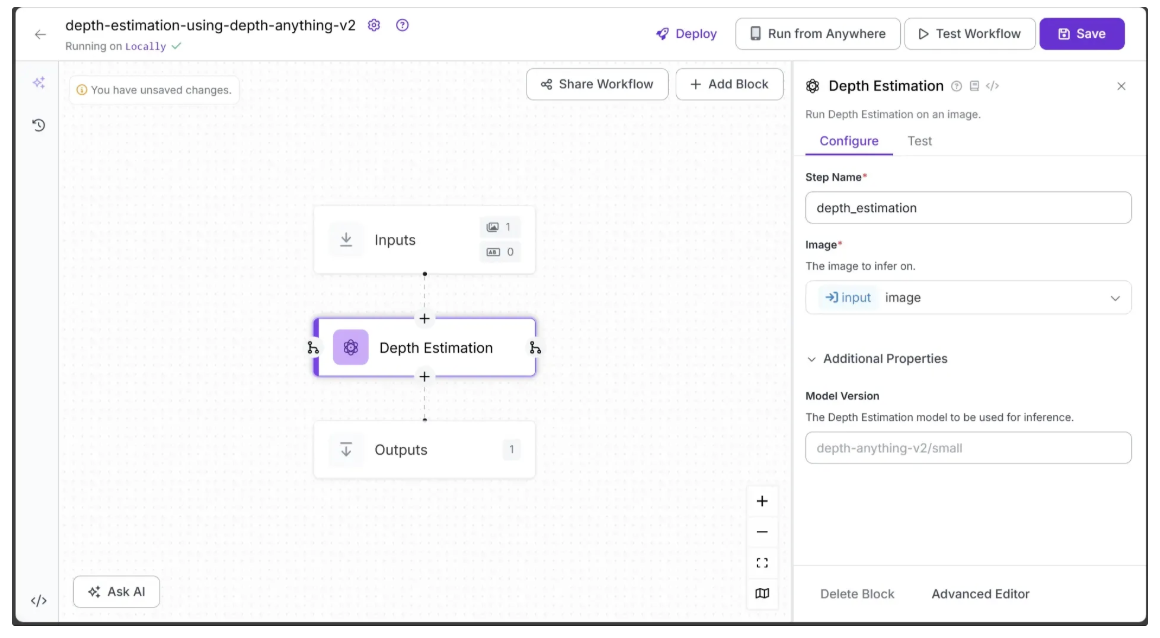
By default, the selected model is Depth Anything V2 in the ‘Small’ variant.
Step 3: Setup Outputs
To Configure the Output from the workflow utilizing Depth Estimation, click on the Outputs block as shown below:
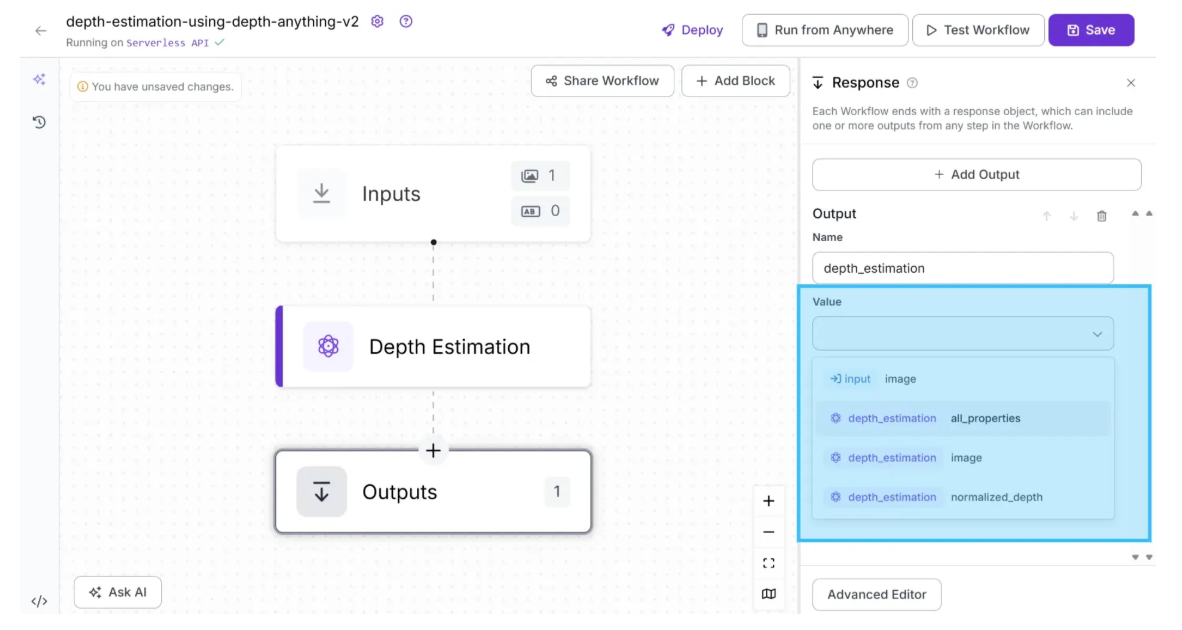
Among the available output options, you can select ‘image’ to obtain a depth-estimated image, a gradient visualization in which brighter pixels represent closer objects and darker pixels represent objects that are farther away.
You can also choose ‘normalized_depth’ to obtain a 2D array of depth values for each pixel, ranging from 0 to 1, where lower values indicate objects closer to the camera and higher values indicate objects farther away.
Alternatively, selecting ‘all_properties’ will output both the depth-estimated image and the normalized depth array. In this workflow example, we select ‘image’ as the output value.
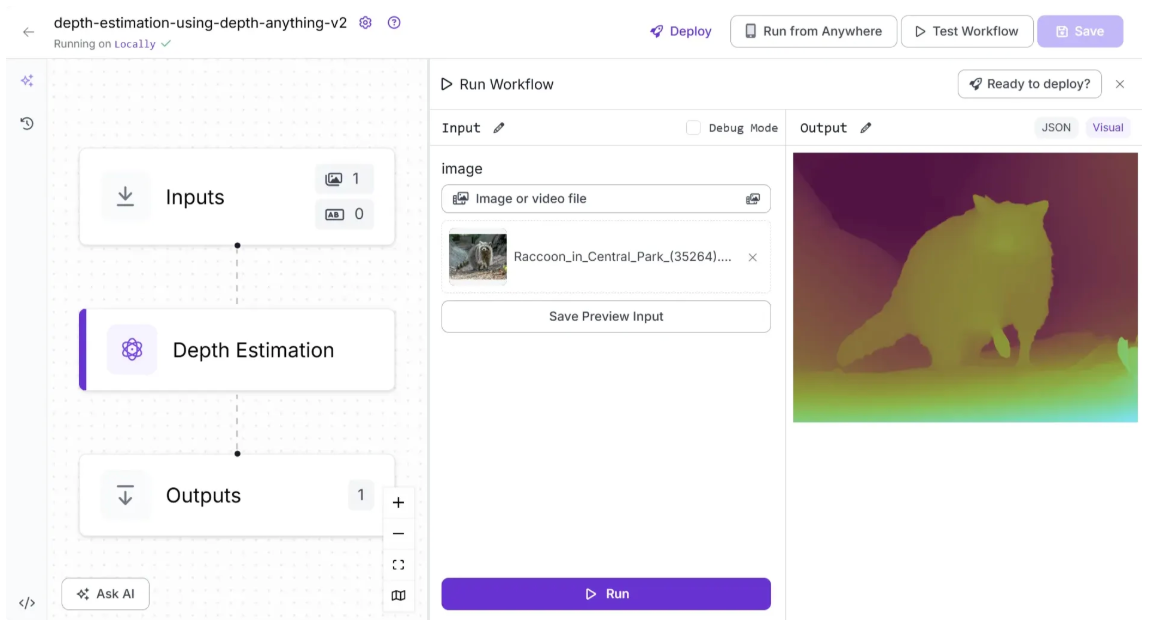
Step 4: Running the Workflow
Your workflow is now complete. To run it, click the “Test Workflow” button in the top-right corner and select “Run”, as shown below.
To run the Workflow as an API using Python, start by running the following code:
pip install inference-sdkNow run the script below:
from inference_sdk import InferenceHTTPClient
import base64
client = InferenceHTTPClient(
api_url="http://localhost:9001",
api_key="YOUR_ROBOFLOW_API_KEY"
)
result = client.run_workflow(
workspace_name="your-workspace",
workflow_id="depth-estimation-using-depth-anything-v2",
images={
"image": "YOUR_IMAGE.jpg"
},
use_cache=True # Speeds up repeated requests
)
# Extract base64 string from result
base64_data = result[0]['depth_estimation']
# Decode and save to file
with open("depth_estimation.png", "wb") as f:
f.write(base64.b64decode(base64_data))
print("Image saved as depth_estimation.png")For the above script, you can find your Roboflow API key by following this guide.
You can find various versions of the script for running locally in different environments by navigating to “Deploy” > “Images” > “Run on Your Server or Computer.”
Conclusion: Best Depth Estimation Models
Depth estimation is a rapidly evolving field, with each model offering distinct advantages depending on the specific task. By understanding the strengths and limitations of each model, you can select the solution that best aligns with your project’s requirements.
Written by Dikshant Shah
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Nov 13, 2025). Explore the Best Depth Estimation Models. Roboflow Blog: https://blog.roboflow.com/depth-estimation-models/