
We are excited to announce that you can now fine-tune PaliGemma-2 for visual question answering on Roboflow. PaliGemma-2 is the latest model architecture in the PaliGemma multimodal model series developed by Google.
In this guide, we are going to walk through how to fine-tune a PaliGemma-2 model on Roboflow. We will create an image-text project, upload data, start training, then deploy the trained model to the edge.
We are going to train a model on a VQA task that involves counting shapes in an image. By the end of this guide, we will have a model that can correctly identify that there are five green shapes in the image below:
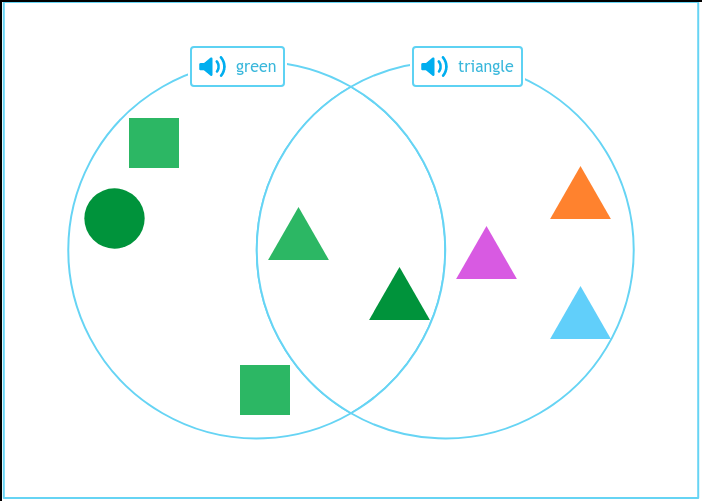
Let’s get started!
Step #1: Create an Image-Text Project
To train a PaliGemma-2 model in Roboflow, you need an image-text pairs project. This project type lets you annotate data and train models with data formatted as question-answer pairs associated with images.
To get started, first create a Roboflow account. Then, click "Create New Project" on your Roboflow dashboard. Set a name for your project. For the task type, select "Multimodal."
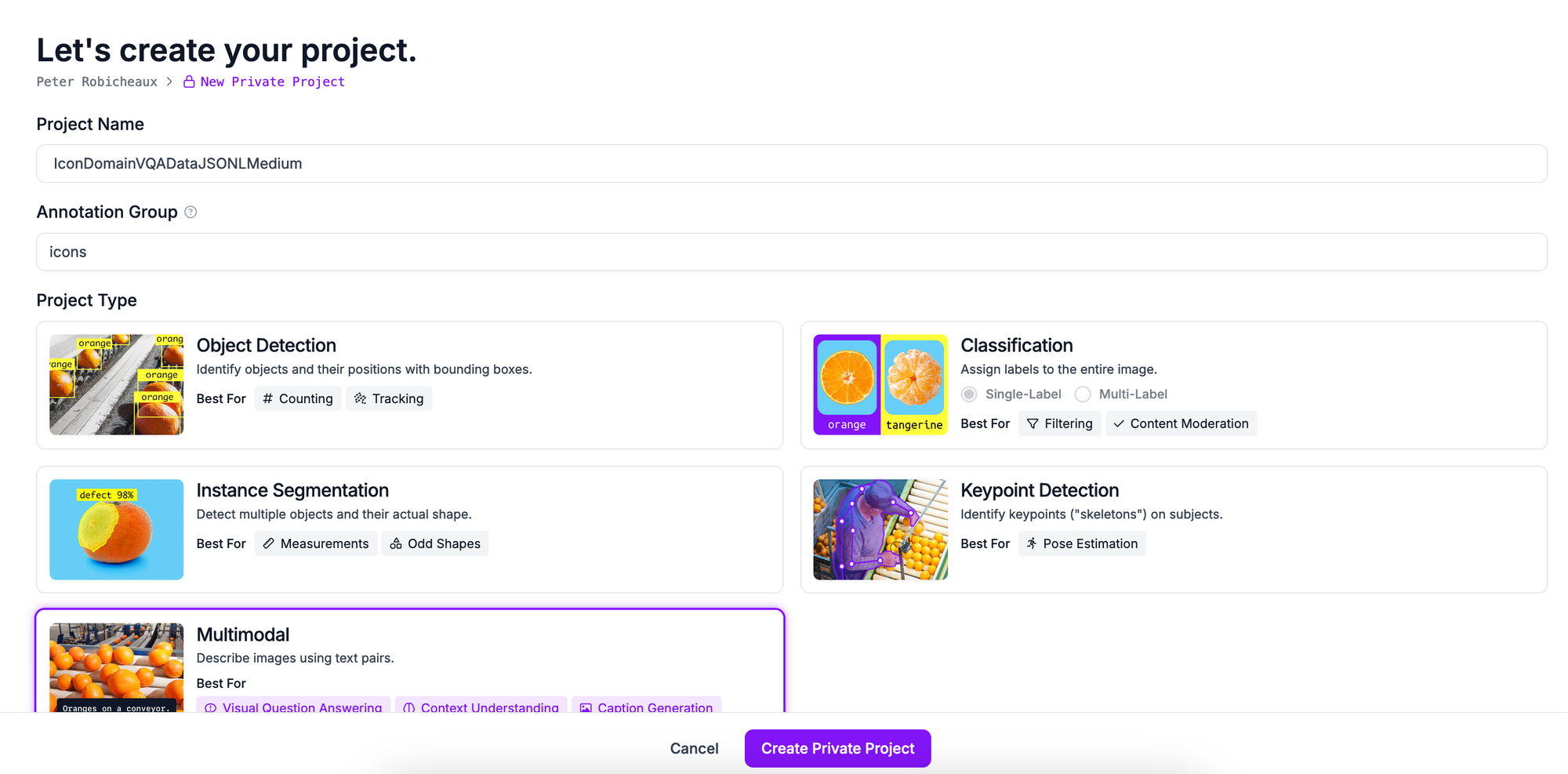
Once you have configured your project, click “Create Project”.
With a new project ready, you can configure the prefixes you want to use for training. Prefixes are used to prompt multimodal models.
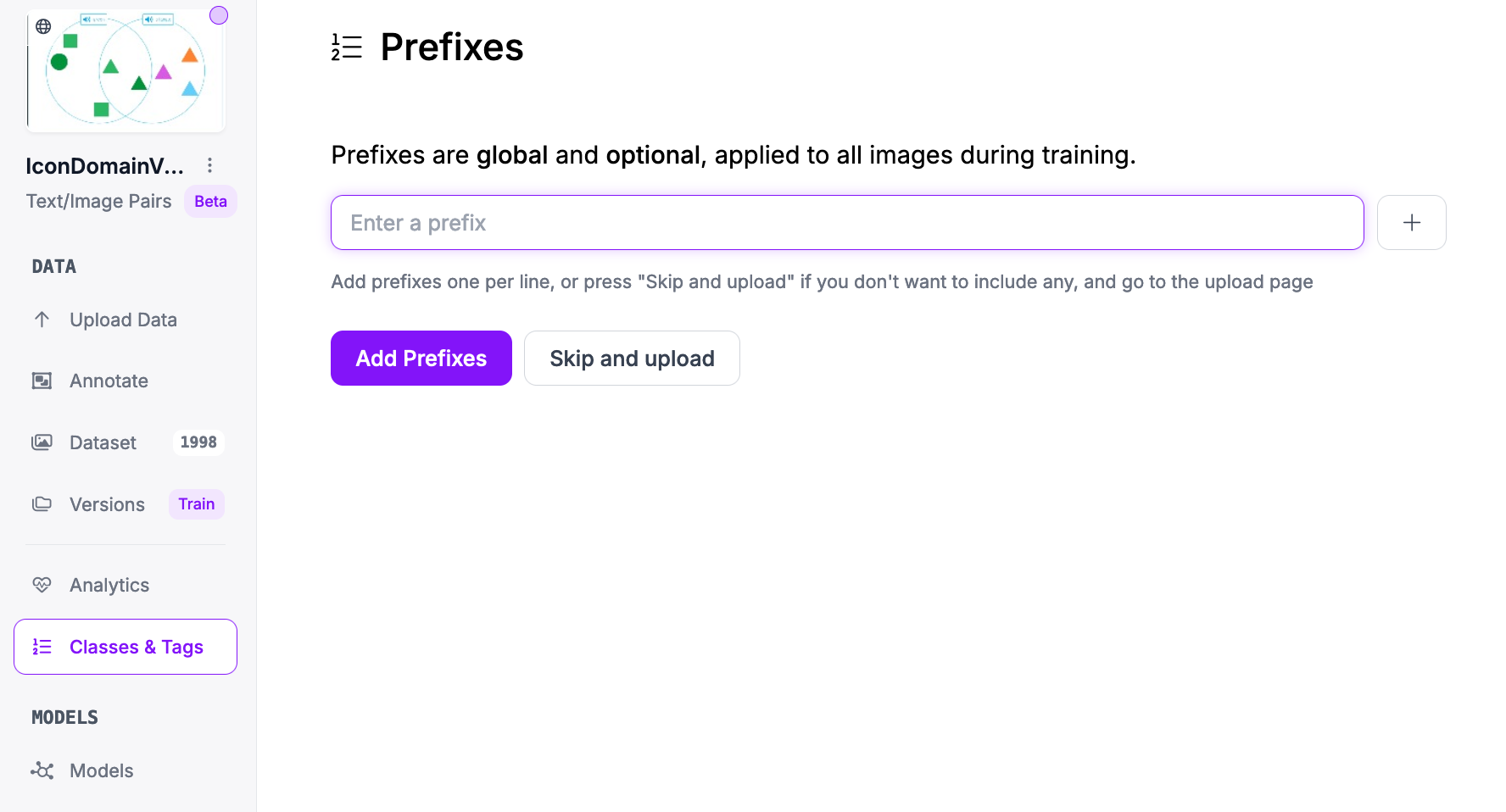
For this guide, we do not need to add any prefixes. Click "Skip and upload" to continue.
Step #3: Upload and Label Data
Click “Upload Data” in the left sidebar to upload data.
This will open the dataset navigation page.
For this project, we will use a dataset with annotations on object counting, puzzle solving, and more. You can download the dataset from Roboflow Universe for use in following along with this guide, or you can use your own data that you want to use.
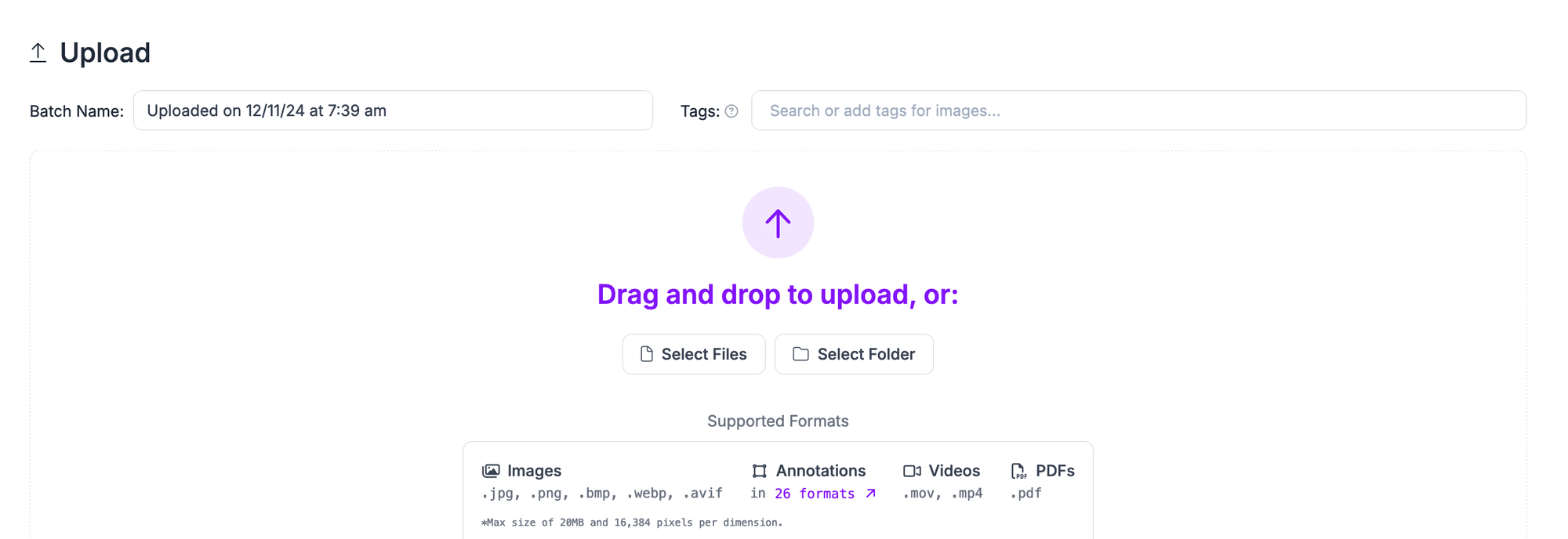
Drag and drop the images you want to label for use in training your model. Once your data has been processed in the browser, click “Save and Continue” to upload it to Roboflow.
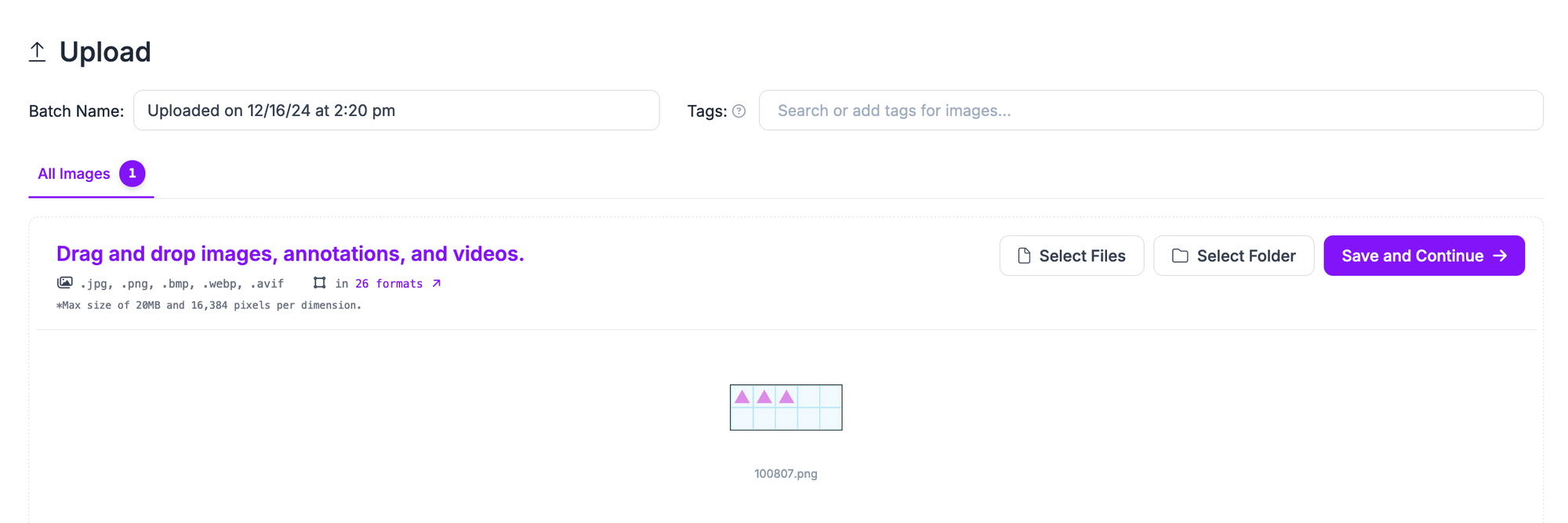
Once your dataset has uploaded, you can start labeling your data. To learn how to label data for multimodal guides, refer to our Multimodal Datasets guide.
Here is an example of a labeled image in our dataset:
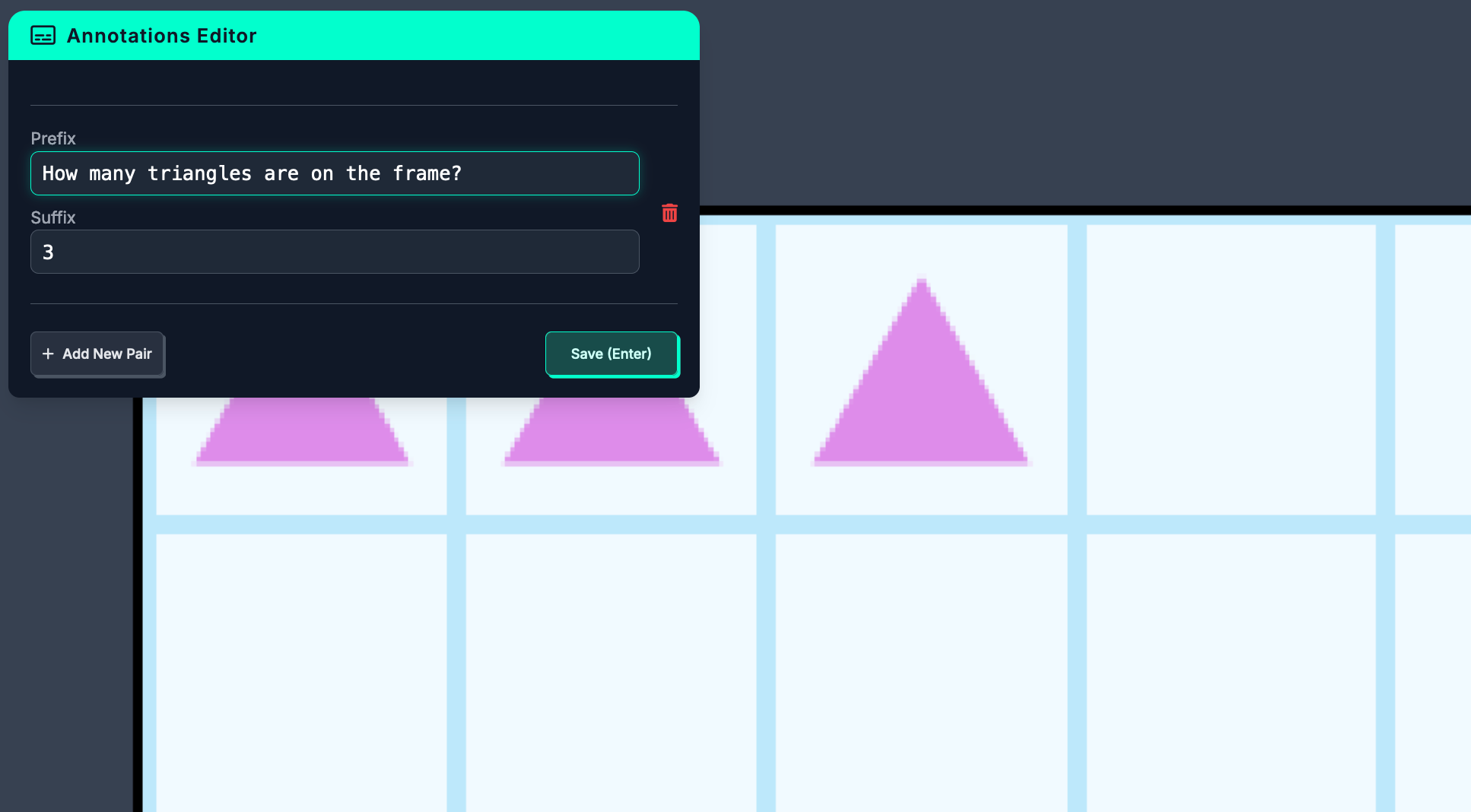
With a labeled dataset ready, you can generate a dataset version for use in training a model. Click “Generate” in the left sidebar. For PaliGemma-2 training, we need to add two preprocessing steps:
- Auto-Orient: Applied
- Resize: Fit within 768x768
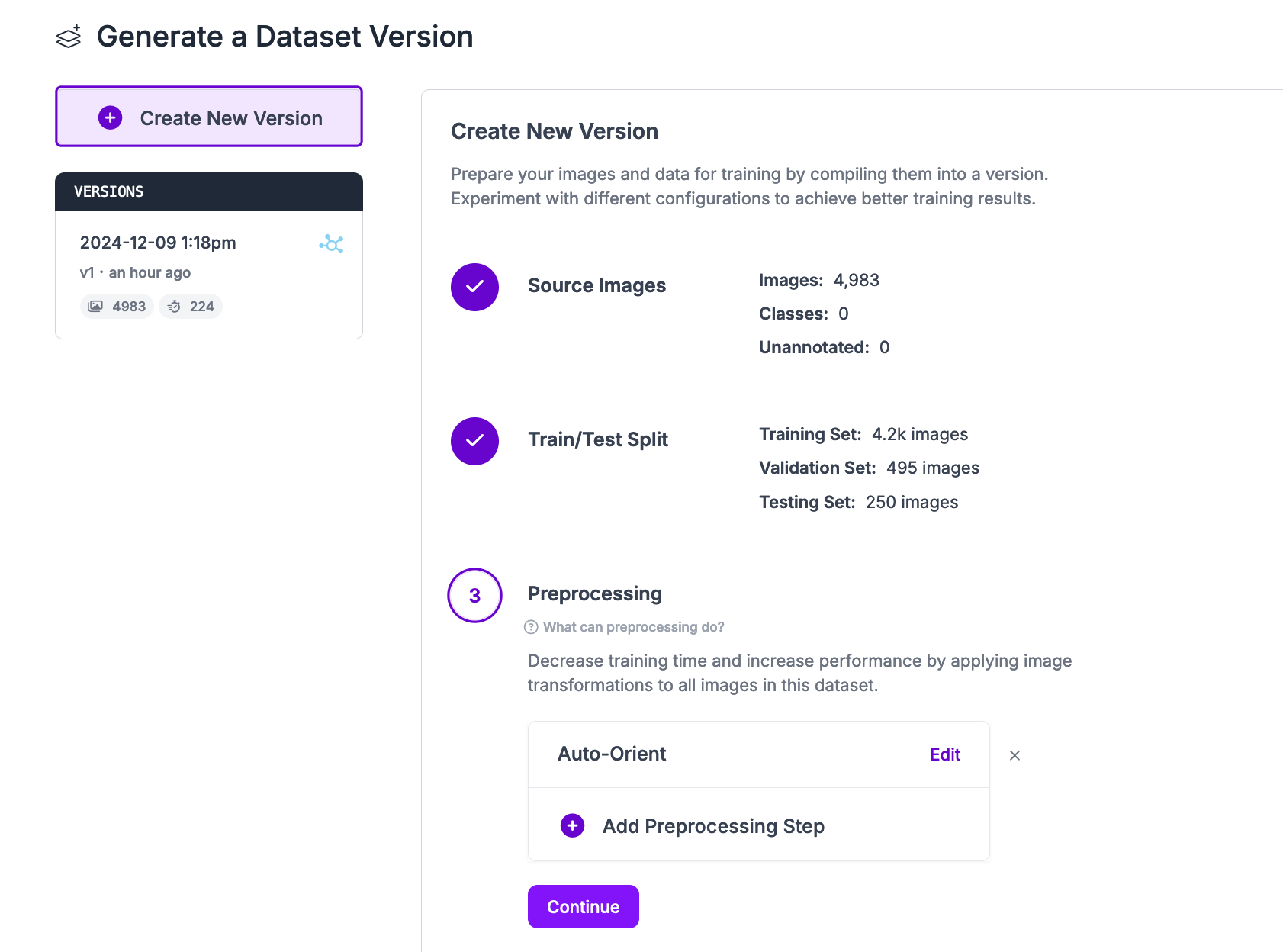
We recommend adding no augmentations for the PaliGemma-2 project type.
Click “Generate” at the bottom of the page to generate a multimodal dataset version. Your dataset will be prepared for use in training. The amount of time this process takes depends on the number of images in your dataset.
Step #4: Start PaliGemma-2 Model Training
When your dataset version is ready, you will be taken to your version page on which you can train a model.
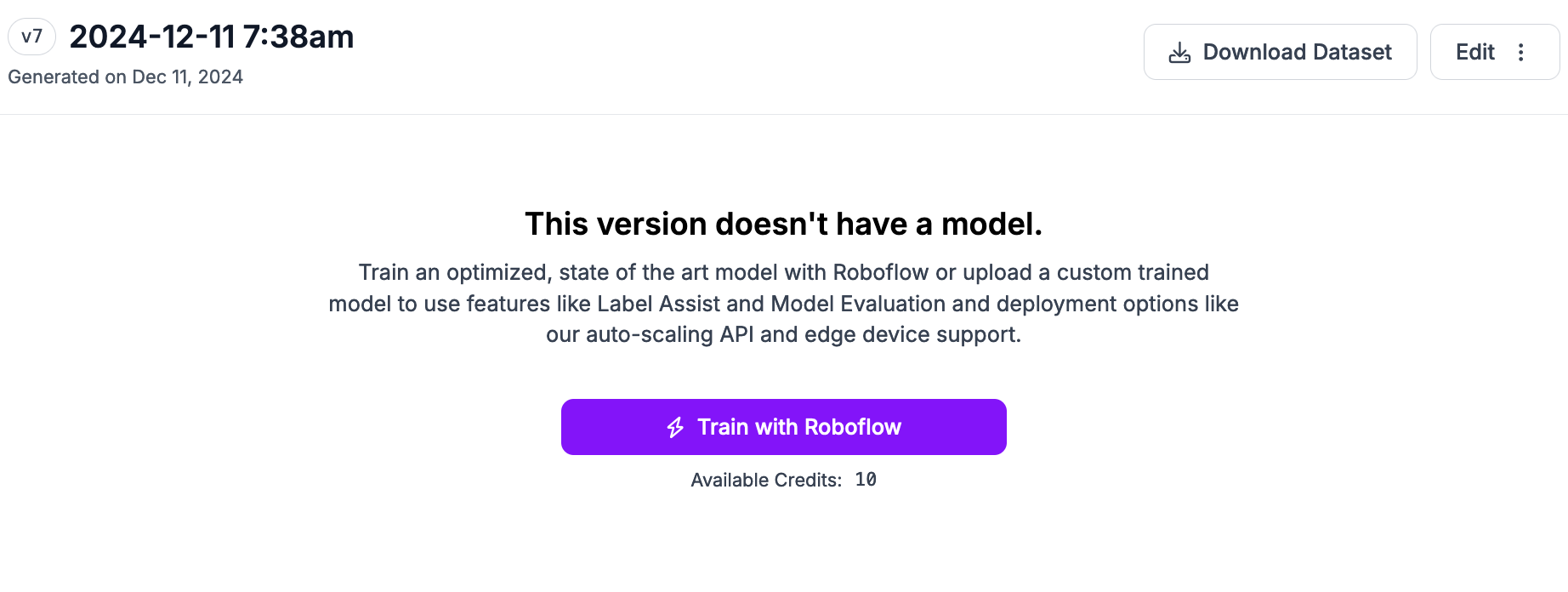
Click “Train a Model”. A window will pop up in which you can configure your model version.
Select the PaliGemma-2 model type. Then, continue following the on-screen instructions to configure your model. Once you have configured your training job, you will receive an estimate of how long we think it will take for your model to train.
While your model trains, you will be able to see training graphs that measure both the loss and perplexity of your model as it trains:
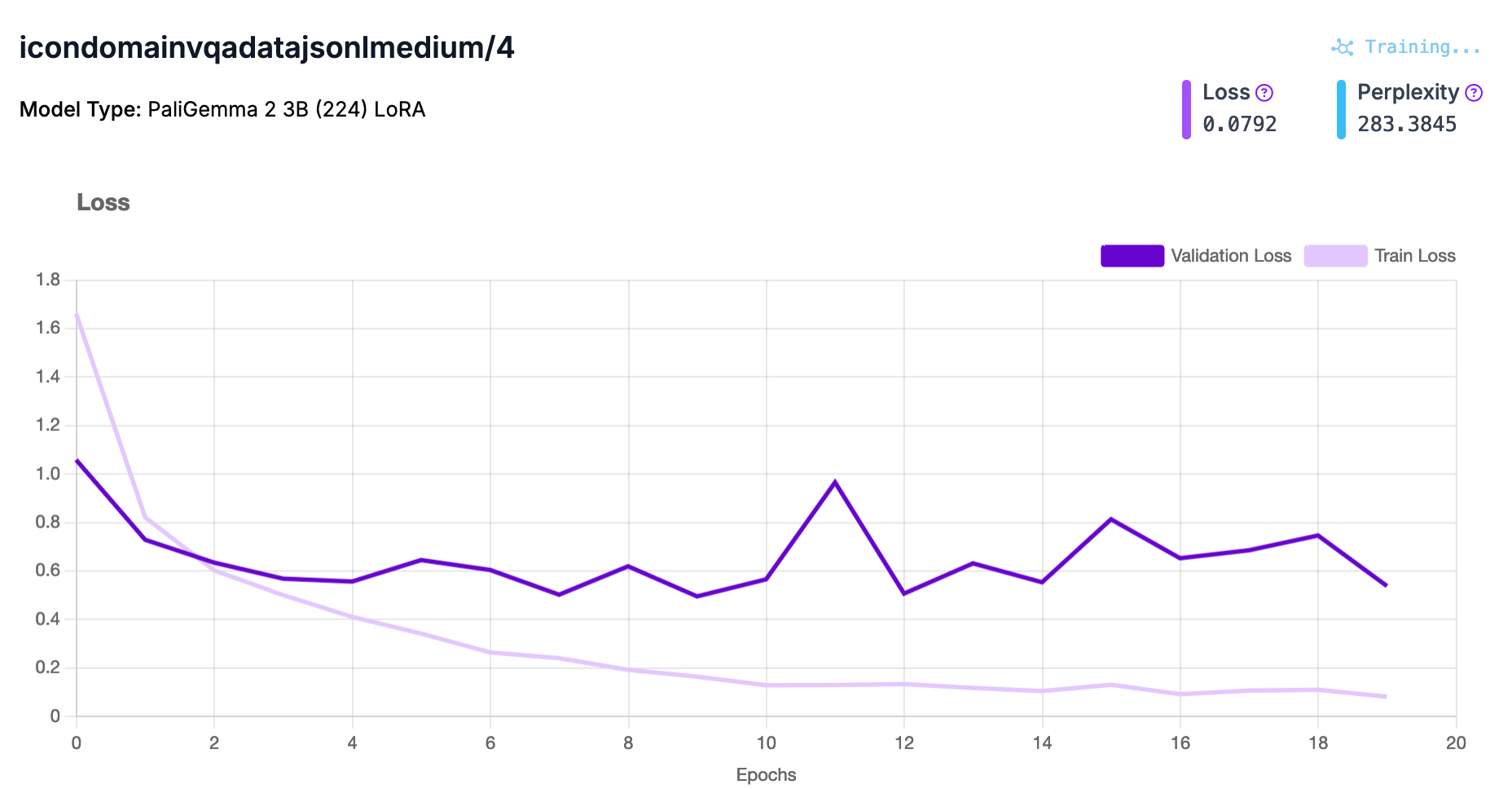
When your model has finished training, you will receive an email and the dashboard will update to reflect that your model is ready to deploy.
Step #5: Deploy the PaliGemma-2 Model
You can deploy fine-tuned PaliGemma-2 models with Roboflow Inference, Dedicated Deployments, and Roboflow Workflows. Inference is a computer vision inference server with support for many state-of-the-art computer vision models including Florence-2, YOLO11, and CLIP.
When you deploy a model with Inference on your device, the model runs locally.
To use your fine-tuned PaliGemma-2 model, you will need to install Inference. You can do so with the following command:
pip install inferenceClick “Deploy” in the left sidebar of your project dashboard. Click “Image Deployment”. Then, copy the code snippet and paste it into a Python file. The code snippet will look like this:
from inference import get_model
model = get_model("icondomainvqadatajsonlmedium/8", api_key="API_KEY")
result = model.infer(
"image.jpeg",
prompt="How many shapes are green?",
)
print(result[0].response)The code snippet copied from Roboflow will already have your API key set.
Let's run the model on this image from our test set, and ask how many shapes are green in the image:
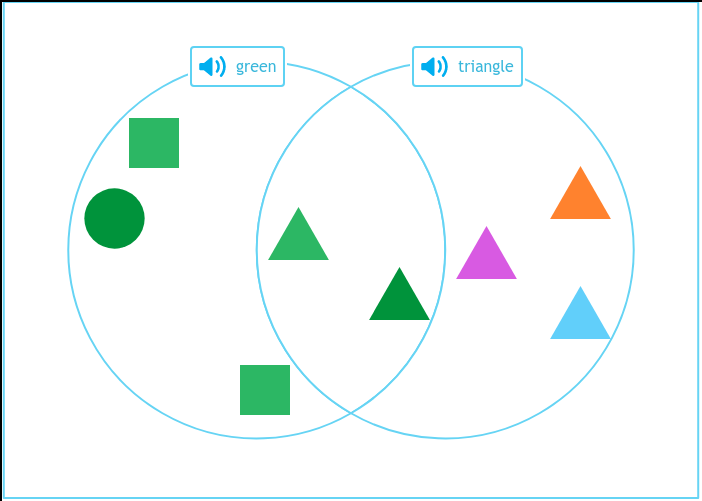
The code snippet returns an object with results from your model:
5We have successfully run PaliGemma-2 for visual question answering on our image! Our model correctly counted the number of green shapes.
Conclusion
PaliGemma-2 is a multimodal model architecture developed by Google. You can fine-tune PaliGemma-2 models with custom datasets on the Roboflow platform.
In this guide, we walked through how to train a PaliGemma-2 model on Roboflow. We created an image-text pairs project, uploaded and prepared data, then trained a model. We then deployed the trained model on our own hardware with Roboflow Inference.
The next step is to build an application that uses your model. For application building, we recommend Roboflow Workflows, a web-based tool for making vision-based applications. You can use over 50 blocks to create production-ready applications with Workflows.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Dec 17, 2024). Launch: Fine-Tune PaliGemma-2 for VQA with Roboflow. Roboflow Blog: https://blog.roboflow.com/fine-tune-paligemma-2-vqa/