
When working with documents like invoices, receipts, or forms, extracting structured data reliably is one of the biggest challenges in AI. Traditional OCR tools can capture text, but they often miss context, struggle with layouts, or fail when text comes in multiple languages or orientations. That’s where Qwen2.5-VL comes in.
In this guide, we’ll walk through how to fine-tune Qwen2.5-VL on a multimodal dataset. Our fine-tuned model will have the ability to not just read documents, but also understand and transform them into structured, machine-readable formats. With advanced multimodal capabilities, Qwen2.5-VL bridges the gap between vision and language, making it ideal for tasks like invoice parsing, form understanding, and business automation.
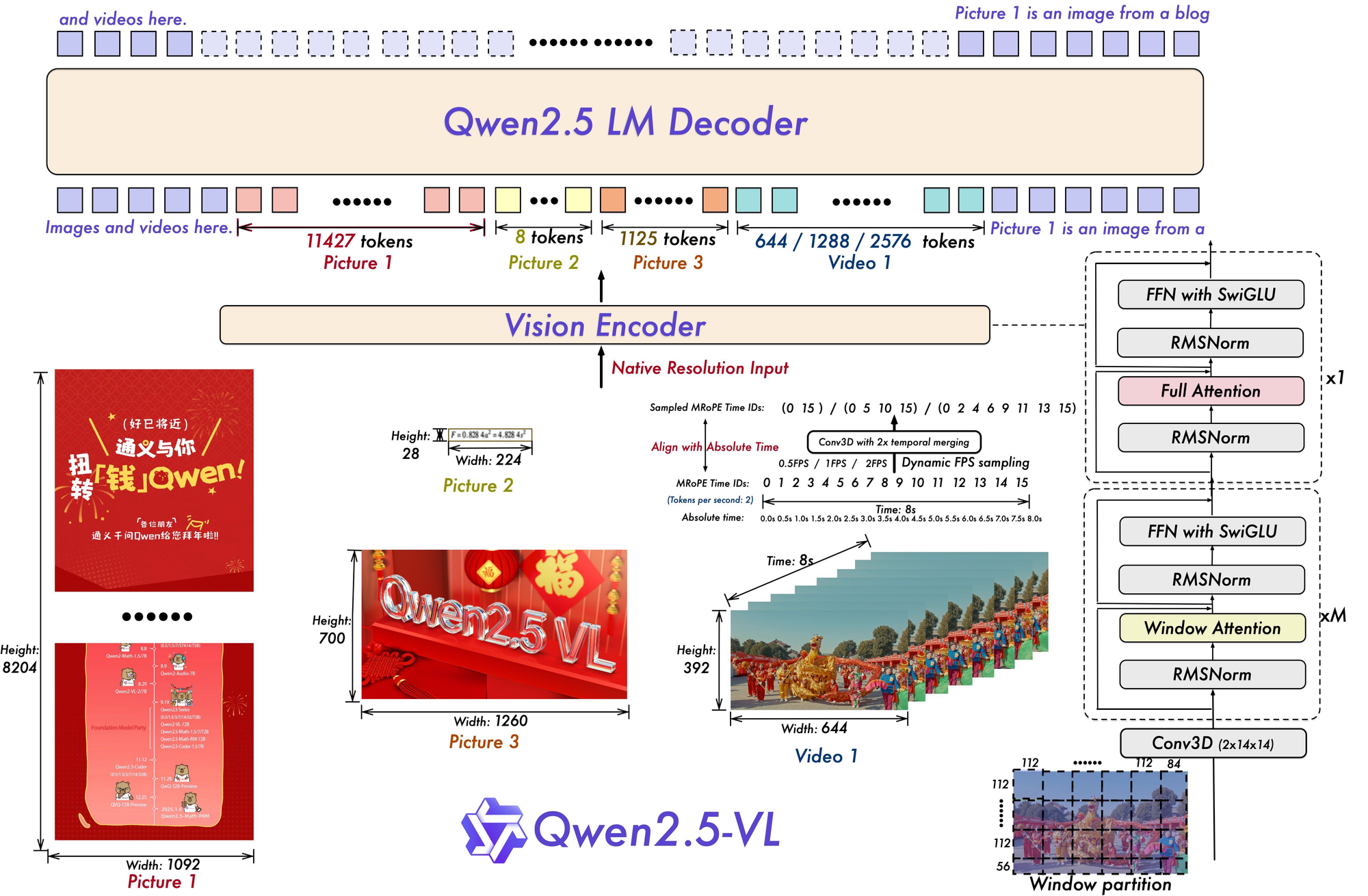
Let's get started!
Environment Setup and Preprocessing
To access Qwen2.5-VL, we'll need a Hugging Face API key. Hugging Face is a platform that hosts a variety of models, including Qwen2.5-VL. The notebook provides a helpful link to the settings page (once you've signed up/logged in). From here, click on access tokens and create a new access token.
Additionally, you'll need to get a Roboflow API key.
The colab notebook has a quick snippet and instruction that allows you to easily store these keys in an environment variables, and import it for future use.
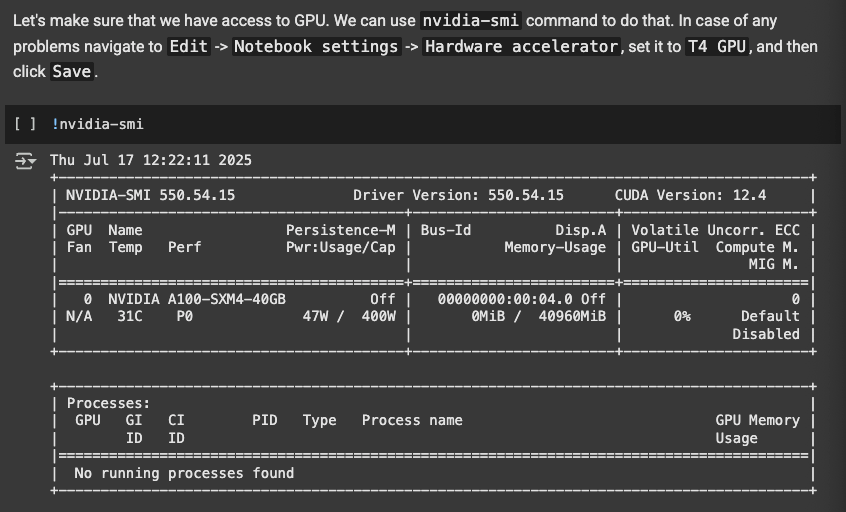
The next step is to use the T4 GPU in colab, because running the model requires accelerated hardware. Following these instructions should allow you to include the T4 GPU:
The next snippets install the necessary libraries, Transformers, Hugging Face's tool for working with state-of-the-art machine learning models, particularly those based on the Transformer architecture. It simplifies the process of downloading, using, and training these models for various tasks across different modalities. It also installes Qwen-VL-Utils, a set of helper functions for integrating VLM info with Qwen-VL. Additonally, we install the Roboflow python package with the next snippet to be able to use download_dataset the function in the next step.
For this guide, you'll need to fork a dataset/project into a Roboflow Workspace. From here, you'll have to replace the contents of the import snippet with your own credentials/IDs:
from roboflow import download_dataset
dataset = download_dataset("https://app.roboflow.com/<YOUR WORKSPACE>/<YOUR PROJECT NAME>/<YOUR DATASET VERSION>", "jsonl")
# Example:
# dataset = download_dataset("https://app.roboflow.com/dev-m9yee/pallet-load-manifest-json-hlbed/1", "jsonl")
We'll also be downloading the dataset in JSONL format, allowing for easy readability and analysis.
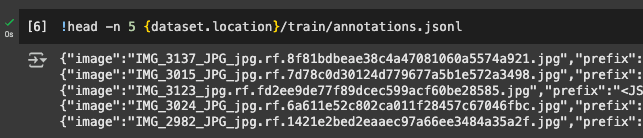
The next snippet allows you to verify the dataset extraction by displaying the first 5 lines of the file, including the image paths:
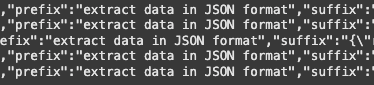
The next snippet edits dataset prefixes, for all the images/annotations, in all three test, train, and valid directories:
!sed -i 's/<JSON>/extract data in JSON format/g' {dataset.location}/train/annotations.jsonl
!sed -i 's/<JSON>/extract data in JSON format/g' {dataset.location}/valid/annotations.jsonl
!sed -i 's/<JSON>/extract data in JSON format/g' {dataset.location}/test/annotations.jsonlFrom changing the prefix <JSON> to "extract data in JSON format", we are giving better instructions to guide the VLM into produce an output of JSON format during training. You can verify this has been changed after running the snippet to see that the prefix attribute for each image has been changed.
Next, to fine-tune the model, we also define a SYSTEM MESSAGE, containing instructions for the VLM for how it must format our data. It is used along with the function created in the following snippet:
def format_data(image_directory_path, entry):
return [
{
"role": "system",
"content": [{"type": "text", "text": SYSTEM_MESSAGE}],
},
{
"role": "user",
"content": [
{
"type": "image",
"image": image_directory_path + "/" + entry["image"],
},
{
"type": "text",
"text": entry["prefix"],
},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": entry["suffix"]}],
},
]This code defines a function format_data that structures image and text data from a dataset entry into a multi-turn conversation format suitable for training with VLMs like Qwen.
The next snippet defines a custom PyTorch Dataset class called JSONLDataset to load and prepare data from JSONL files for training and evaluation, associating each entry with its corresponding image and formatting it into a conversational structure. Using the next bit of code, we instantiate these classes for the test, train, and valid directories of our extracted dateset:
train_dataset = JSONLDataset(
jsonl_file_path=f"{dataset.location}/train/annotations.jsonl",
image_directory_path=f"{dataset.location}/train",
)
valid_dataset = JSONLDataset(
jsonl_file_path=f"{dataset.location}/valid/annotations.jsonl",
image_directory_path=f"{dataset.location}/valid",
)
test_dataset = JSONLDataset(
jsonl_file_path=f"{dataset.location}/test/annotations.jsonl",
image_directory_path=f"{dataset.location}/test",
)We can verify the conversational training structure by examining the first element in train_dataset (after running the snippet):
(<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=3024x4032>,
{'image': 'IMG_3137_JPG_jpg.rf.8f81bdbeae38c4a47081060a5574a921.jpg',
'prefix': 'extract data in JSON format',
'suffix': '{"route": "Z833-QB-702","pallet_number": "5","delivery_date": "3/24/2024","load": "1","dock": "D04","shipment_id": "P49270667963","destination": "08811 Rosario Pike, New Michaelhaven, SD 13213","asn_number": "8219471036","salesman": "SHAUN MORGAN","products": [{"description": "123456 - CASE OF PAPER TOWELS","cases": "64","sales_units": "16","layers": "4"},{"description": "182845 - CASE OF BUCKETS","cases": "2","sales_units": "16","layers": "5"},{"description": "951753 - BOX OF PLASTIC WRAP","cases": "8","sales_units": "8","layers": "4"},{"description": "495867 - 6PK OF HAND TOWELS","cases": "4","sales_units": "64","layers": "4"}],"total_cases": "78","total_units": "104","total_layers": "17","printed_date": "12/05/2024 11:30","page_number": "71"}'},
[{'role': 'system',
'content': [{'type': 'text',
'text': 'You are a Vision Language Model specialized in extracting structured data from visual representations of palette manifests.\nYour task is to analyze the provided image of a palette manifest and extract the relevant information into a well-structured JSON format.\nThe palette manifest includes details such as item names, quantities, dimensions, weights, and other attributes.\nFocus on identifying key data fields and ensuring the output adheres to the requested JSON structure.\nProvide only the JSON output based on the extracted information. Avoid additional explanations or comments.'}]},
{'role': 'user',
'content': [{'type': 'image',
'image': '/content/pallet-load-manifest-json-1/train/IMG_3137_JPG_jpg.rf.8f81bdbeae38c4a47081060a5574a921.jpg'},
{'type': 'text', 'text': 'extract data in JSON format'}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': '{"route": "Z833-QB-702","pallet_number": "5","delivery_date": "3/24/2024","load": "1","dock": "D04","shipment_id": "P49270667963","destination": "08811 Rosario Pike, New Michaelhaven, SD 13213","asn_number": "8219471036","salesman": "SHAUN MORGAN","products": [{"description": "123456 - CASE OF PAPER TOWELS","cases": "64","sales_units": "16","layers": "4"},{"description": "182845 - CASE OF BUCKETS","cases": "2","sales_units": "16","layers": "5"},{"description": "951753 - BOX OF PLASTIC WRAP","cases": "8","sales_units": "8","layers": "4"},{"description": "495867 - 6PK OF HAND TOWELS","cases": "4","sales_units": "64","layers": "4"}],"total_cases": "78","total_units": "104","total_layers": "17","printed_date": "12/05/2024 11:30","page_number": "71"}'}]}])Here, we can see that for the image in the train dataset, its provided the instructions (SYSTEM MESSAGE).
Now let's load and configure Qwen2.5-VL!
Model Loading and Configuration
The next snippet loads Qwen2.5-VL into the notebooke, with LoRA (Low-Rank Adapation). This adaptation configures Qwen with smaller matrices, saving memory during training due to its smaller size. It also applies 4-bit quantization, preserving the model's performance.
Additionally, with the next snippet, we set a minmax for the image size (# of pixels) for the model. Then, using these values and transformer library functions, we determine an optimal configuration.
In the next snippet, we define the train_collate_fn function, which is used by the PyTorch DataLoader to process a batch of data for training. It takes a batch of data samples, formats them into conversational text and image inputs, tokenizes and pads them, and importantly, masks the system message, image tokens, and user turn in the labels so that the loss is only computed on the assistant's (target JSON) response.
Next, we define an evaluation collat function which is used by the PyTorch DataLoader to process a batch of data for evaluation. Similar to the training collate function, it formats the data into conversational text and image inputs, tokenizes and pads them. However, unlike the training function, it keeps track of the ground truth suffixes (the target JSON outputs) separately and removes the assistant's turn from the input to the model, allowing the model to generate the output for evaluation.
The next snippet creates PyTorch DataLoader instances for the training, validation, and test datasets. These DataLoaders are responsible for iterating over the datasets in batches, using the train_collate_fn for the training data and the evaluation_collate_fn for the validation and test data to format and process the data before feeding it to the model:
from torch.utils.data import DataLoader
BATCH_SIZE = 1
NUM_WORKERS = 0
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, collate_fn=train_collate_fn, num_workers=NUM_WORKERS, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, collate_fn=evaluation_collate_fn, num_workers=NUM_WORKERS)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, collate_fn=evaluation_collate_fn, num_workers=NUM_WORKERS)The next snippet retrieves a single batch of data from the train_loader using next(iter(train_loader)) and unpacks the variables: input_ids, attention_mask, pixel_values, image_grid_thw, and labels. Using this and the following snippets, we can then inspect the processed batch of training data before feeding it into the model.

After going through the inspection, we can now train the model!
Training the Model
To train, we'll be using PyTorch Lightning, a framework for flexible training without sacrificing performance. Install it with the snippet:
!pip install -q lightning nltkThe next bit of code defines a PyTorch Lightning Module called Qwen2_5_Trainer which encapsulates the training and validation logic for fine-tuning the Qwen2.5-VL model. It includes methods for the training step (training_step) to compute the loss, the validation step (validation_step) to generate predictions and calculate the edit distance metric, and configuring the optimizer (configure_optimizers):
import lightning as L
from nltk import edit_distance
from torch.optim import AdamW
class Qwen2_5_Trainer(L.LightningModule):
def __init__(self, config, processor, model):
super().__init__()
self.config = config
self.processor = processor
self.model = model
def training_step(self, batch, batch_idx):
input_ids, attention_mask, pixel_values, image_grid_thw, labels = batch
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=pixel_values,
image_grid_thw=image_grid_thw,
labels=labels
)
loss = outputs.loss
self.log("train_loss", loss, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx, dataset_idx=0):
input_ids, attention_mask, pixel_values, image_grid_thw, suffixes = batch
generated_ids = self.model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=pixel_values,
image_grid_thw=image_grid_thw,
max_new_tokens=1024
)
generated_ids_trimmed = [
out_ids[len(in_ids) :]
for in_ids, out_ids
in zip(input_ids, generated_ids)]
generated_suffixes = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
scores = []
for generated_suffix, suffix in zip(generated_suffixes, suffixes):
score = edit_distance(generated_suffix, suffix)
score = score / max(len(generated_suffix), len(suffix))
scores.append(score)
print("generated_suffix", generated_suffix)
print("suffix", suffix)
print("score", score)
score = sum(scores) / len(scores)
self.log("val_edit_distance", score, prog_bar=True, logger=True, batch_size=self.config.get("batch_size"))
return scores
def configure_optimizers(self):
optimizer = AdamW(self.model.parameters(), lr=self.config.get("lr"))
return optimizer
def train_dataloader(self):
return DataLoader(
train_dataset,
batch_size=self.config.get("batch_size"),
collate_fn=train_collate_fn,
shuffle=True,
num_workers=10,
)
def val_dataloader(self):
return DataLoader(
valid_dataset,
batch_size=self.config.get("batch_size"),
collate_fn=evaluation_collate_fn,
num_workers=10,
)We then set the training configuration with the next snippet. It includes important information like max_epochs and batch_size.
Running the next snippets creates an instance of Qwen2_5_Trainer and provides the necessary info (config, processor, model) for training with PyTorch Lightning.
Finally, running the trainer snippet allows us to initiate training:
Running Inference with Fine-Tuned Qwen2.5-VL
After the model has finished training, the next snippet loads the fine-tuned Qwen2.5-VL model and its corresponding processor from the saved checkpoint directory:
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"/content/qwen2.5-3b-instruct-palette-manifest/latest",
device_map="auto",
torch_dtype=torch.bfloat16
)
processor = Qwen2_5_VLProcessor.from_pretrained(
"/content/qwen2.5-3b-instruct-palette-manifest/latest",
min_pixels=MIN_PIXELS,
max_pixels=MAX_PIXELS
)Next, we create an inference function that takes the fine-tuned model, processor, a conversation list, and optional parameters for generation (like max_new_tokens and device). It formats the conversation, processes the image input, prepares the inputs for the model, generates new tokens using the model, and then decodes the generated token IDs back into readable text, specifically focusing on the model's generated response:
def run_inference(model, processor, conversation, max_new_tokens=1024, device="cuda"):
text = processor.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
image_inputs, _ = process_vision_info(conversation)
inputs = processor(
text=[text],
images=image_inputs,
return_tensors="pt",
)
inputs = inputs.to(device)
generated_ids = model.generate(**inputs, max_new_tokens=max_new_tokens)
generated_ids_trimmed = [
out_ids[len(in_ids):]
for in_ids, out_ids
in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
return output_text[0]We can then test the model by comparing generated results versus expected results with the next snippets:


After running these two, we compare them via HTML:

As shown, it performs quite remarkably!
Conclusion
Congratulations on successfully fine-tuning Qwen2.5-VL for data extractions! With just a few snippets, we were able to create a model that performs quite well for JSON extraction, all without having to train an object detection model for OCR!
Cite this Post
Use the following entry to cite this post in your research:
Aryan Vasudevan. (Aug 26, 2025). How to Fine-Tune Qwen2.5-VL with a Custom Dataset. Roboflow Blog: https://blog.roboflow.com/fine-tune-qwen-2-5/