
A Roboflow Sales Development Representative with no prior computer vision background documents the full process of building a hand gesture recognition model, covering 14 emoji-style gestures, using only Roboflow's platform. Key lessons from the project include the outsized impact of using self-captured images in the target environment over generic web images, the performance gains from dataset augmentation with rotation and scaling, and the value of iterating through multiple dataset versions to diagnose and fix accuracy problems. The result demonstrates that collecting roughly 500 well-matched images and applying augmentation can produce a working classification model without writing custom training code.
As a Sales Development Representative (SDR) with limited prior technical experience before Roboflow, I initially approached this challenge with some apprehension. However, with the help of Roboflow's user-friendly platform and the guidance I received along the way, I was able to overcome obstacles and build a model I’m proud to show. Join me as I share my experience and insights gained from this incredible journey.
The following video shows my model in action:

Selecting a Project
The first hurdle was selecting the right project: something practical and useful to a wide range of users. Initially, I considered creating a model that could identify different types of recyclable materials or recognize various street signs for autonomous driving. However, I soon realized that these projects were limited in their application or had already been done before. I settled on creating a model for recognizing everyday hand gestures found in emoji keyboards, which include the following:
👍 👎 ✌️ 🫶 ✊ 👊 🤘 🤟 🤞 👌 ✋ 🤌 👆 🤙
Roboflow's tutorial page and YouTube videos became my guiding light, offering step-by-step explanations that eased my initial apprehensions.
Collecting diverse and appropriate images for training the model proved challenging. Initially, I gathered images online, but the model's performance was disappointing. Seeking assistance, I turned to a fellow SDR, Alex Hyams, who suggested using images of myself at my computer for better results.
Following Alex's recommendation, I captured, uploaded, and annotated approximately 500 images, focusing on myself at my desk. This adjustment significantly improved the model's performance.
Alex's advice to generate an augmented version of the dataset further enhanced the model's accuracy and robustness. After several iterations and continuous improvement, I presented my model to the leadership team, showcasing significant progress from its initial version.
Version 1
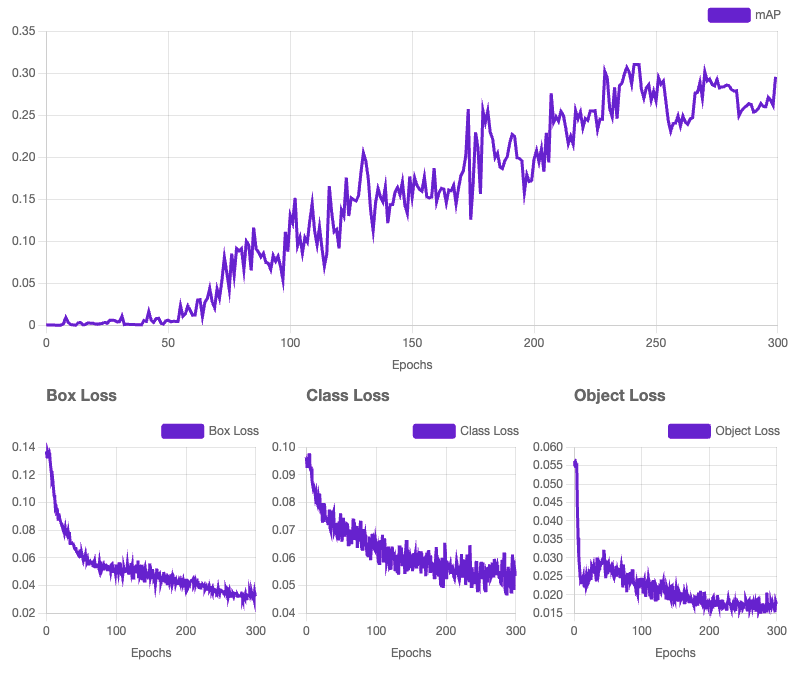

Version 2
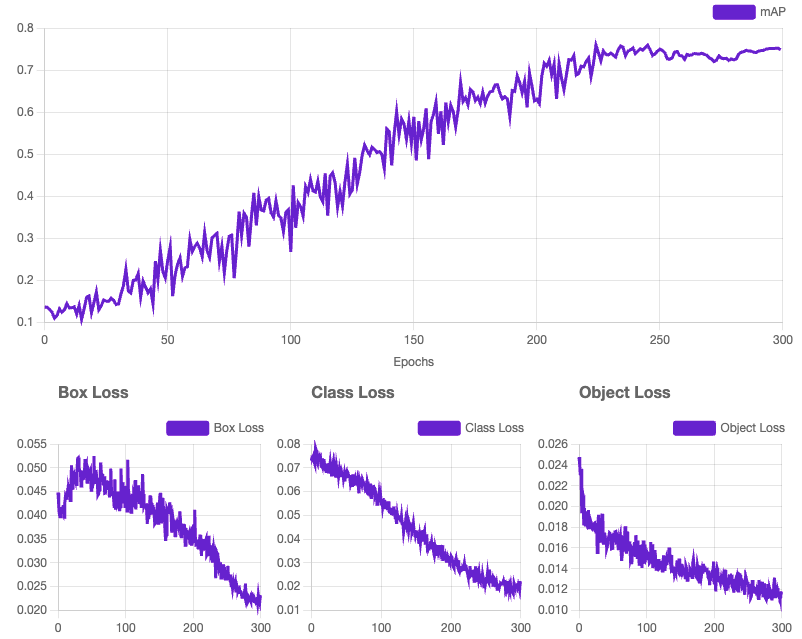

Final Version: Version 6
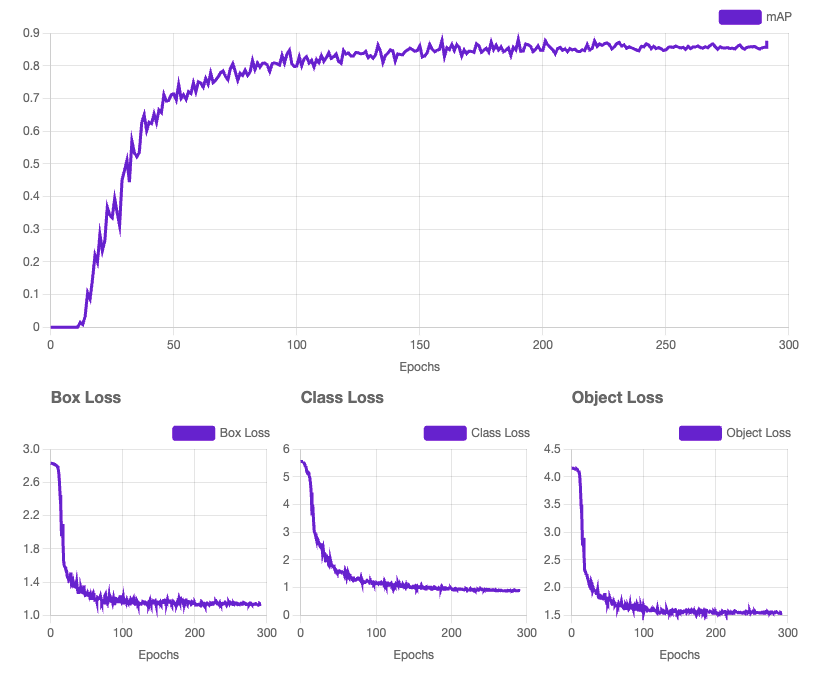

Building a Model
Below, I discuss at a high level the steps I followed to go from my idea to having a computer vision model ready to use and show off to the team!
Collecting Data
This step involves gathering and preparing a dataset of images or videos that will be used to train and validate the model. This step is crucial as the quality and diversity of the data directly impact the performance and accuracy of the model.
It is important to clearly define the specific objects, scenes, or actions you want your model to recognize. This helps in narrowing down the focus and ensures that the collected data aligns with the intended application.
There are many places from which you can collect images, such as online repositories, specific environments, or captured using cameras or sensors. The images should cover different variations, angles, lighting conditions, and perspectives relevant to the target application.
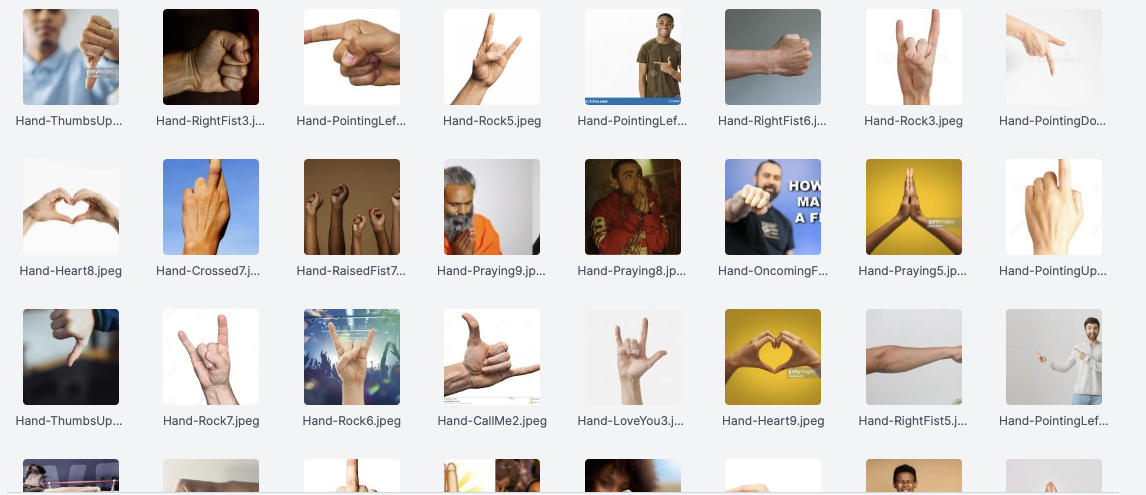
Properly collecting and preparing the data is foundational for building an effective computer vision model. It helps the model learn and generalize patterns from the real-world scenarios it will encounter during deployment, leading to better performance and more reliable results.
Annotation
Annotating involves marking and adding labels to specific objects, regions, or attributes of interest within an image or video. Annotating is crucial as it provides ground truth information for training the model to recognize and understand the desired visual elements.
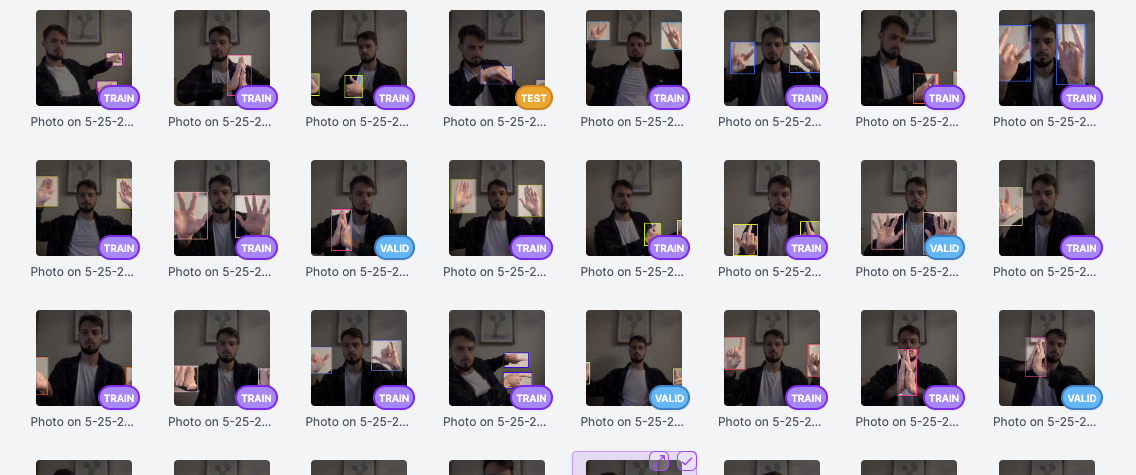
Adding Augmented Data
This step involves generating variations of the original dataset to increase its diversity and improve robustness of the trained model. Augmentations help in reducing overfitting, enhancing generalization, and making the model more adaptable to real-world scenarios. Here are some common techniques used in the creation of augmentations:
- Image transformations: Applying geometric transformations to images, such as rotation, scaling, translation, and flipping. These transformations help the model generalize to different orientations and perspectives.
- Color and brightness adjustments: Modifying the color channels, contrast, saturation, or brightness of the images. This helps the model become more robust to variations in lighting conditions.

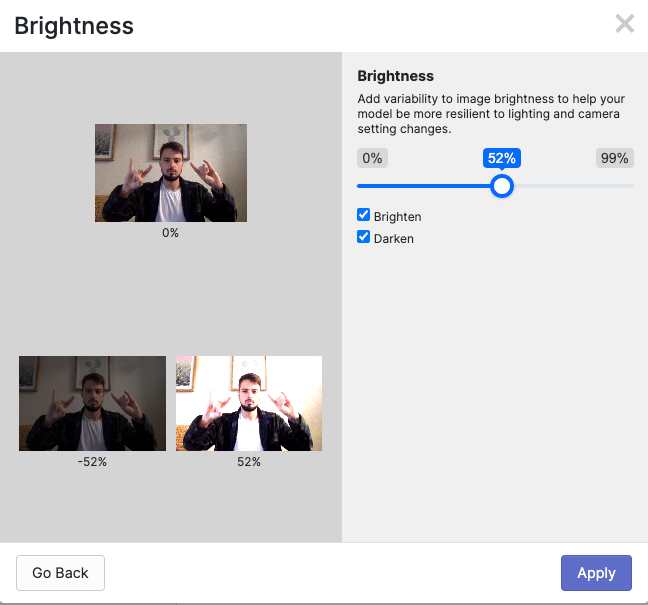
Training
With data ready, we can train a model! You can train models that can accurately classify, detect, or segment objects within images or videos. I trained an object detection model to recognize hand emoji reactions in image data.
During training, the model learns to minimize the loss function by making predictions that align with the ground truth labels.
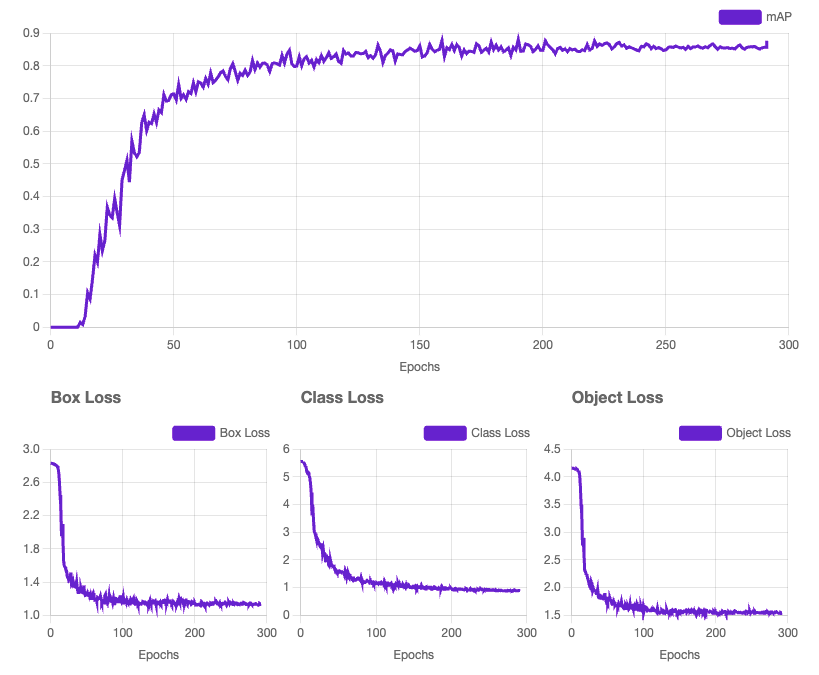
Testing the Model
With a model ready, it is time to test and deploy! Here are some key components typically included in this step:
- Model deployment: Integrating the trained model into the target system or application where it will be used. This may involve creating an API or embedding the model within a software framework.
- Performance evaluation: Testing the model's accuracy, precision, recall, and other relevant metrics on a separate test dataset. This helps assess the model's performance and identify any potential issues or areas for improvement.

I used the webcam tab that is provided and the end of each test through the Roboflow platform but this can be done using any camera system that is connected to the model.
What I Learned
The driving force behind this project was the potential need for my hard-of-hearing nephew to learn sign language. Witnessing the challenges he might face, I aimed to create a practical tool to assist him and others in learning ASL.
By focusing on universally recognized hand gestures, the model's applicability expanded beyond his specific needs. The journey was challenging, but the rewards were gratifying, as I witnessed the growth and potential of the hand signal recognition model.
- Overcoming initial apprehension: Despite having limited experience, I discovered that with determination and the right resources, I could produce a working, practical model.
- Selecting the right project: Choosing a practical and accessible project was crucial.
- Leveraging Roboflow's resources: Roboflow's user-friendly platform, tutorial page, and YouTube videos were invaluable in guiding me through the process.
- Collaboration and assistance: Receiving generous assistance from a fellow SDR helped me to overcome roadblocks and refine the model's performance.
- Importance of diverse and appropriate training data: Initially, gathering images online didn't yield satisfactory results. However, through experimentation and guidance, using self-captured images in a specific environment significantly improved the model's accuracy.
- Augmentation for improved performance: Generating an augmented version of the dataset, incorporating techniques like rotation and scaling, proved to be a game-changer.
My journey building a hand signal recognition model with Roboflow has been a testament to the accessibility and power of the platform, even for those with limited technical expertise.
Through trial and error, I discovered the true potential of computer vision and its impact on real-world applications. Roboflow's intuitive interface, comprehensive resources, and invaluable community support played a pivotal role in turning my vision into a reality.
Cite this Post
Use the following entry to cite this post in your research:
Eli Juergens. (Jun 16, 2023). From Novice to Knowledge: My Journey Building a Gesture Recognition Model with Roboflow. Roboflow Blog: https://blog.roboflow.com/gesture-recognition-model/