
Benchmarking 8 Intel Habana Gaudi1 HPUs against 8 NVIDIA A100 GPUs for training YOLOv5 on the 121k-image COCO dataset shows the Gaudi1 cluster costs $0.73 per epoch versus $0.98 per epoch for A100s, a 25% cost advantage per training epoch. The post covers how to spin up the AWS DL1 instance, configure YOLOv5 for HPU training via SynapseAI, and replicate the benchmark, with a note that Gaudi2 accelerators were upcoming at the time of testing.
When you are training machine learning models, it is essential to pick hardware that optimizes your models performance relative to cost. In training, the name of the game is speed per epoch – how fast can your hardware run the calculations it needs to train your model on your data.
Every day, deep learning hardware is pushing the boundaries of what was previously possible. Habana Gaudi HPUs from Intel have been gaining steam in the AI community, particularly for training transformer models in NLP, challenging incumbent NVIDIA GPUs.
Gaudi accelerators differ from their GPU counterparts in that they have been made specifically for the task of running the operations inside machine learning models. The Gaudi accelerators come with PyTorch and Tensorflow bindings written in SynapseAI® (akin to cuda or tensorrt).
At Roboflow, we were interested in evaluating the new HPU cards for computer vision use cases. We chose the popular YOLOv5 model which has a battle hardened PyTorch training routine and healthy augmentation pipeline. We benchmarked YOLOv5 training on the COCO dataset, the standard object detection benchmark with 121k images.
Through the Intel Disruptor program, we put the Habana DL1 instances with 8 Habana Gaudi1 HPU accelerators (soon to be eclipsed by their Gaudi2 successor) to the test against a blade of 8 A100 GPUs. We summarize our initial findings and provide a guide on how you can replicate our study for your own purposes.
In sum:
- 8 NVIDIA A100 -->
$0.98 / COCO epoch - 8 Intel Gaudi1 HPU -->
$0.73 / COCO epoch
Benchmarking 8 A100 GPUs as a Baseline
For our GPU baseline we choose the A100 GPU which represents the best of what NVIDIA offers on the cloud today.

Spinning Up an Instance
To construct the 8 A100 GPU baseline, we spun up an instance with 8 A100 GPUs on the AWS p4d.24xlarge instance for an on-demand price of $32.77/hour.
Once the instance has been allocated, we can SSH into it:
ssh -i ~/.ssh/sshkey IP_ADDRESS
Running Training
After entering the instance, we clone and install YOLOv5 and launch multi-GPU training on the yolov5s model on the COCO dataset with a batch size of 128 on our 8 A100s according to the multi-GPU training guide from Ultralytics:
python -m torch.distributed.run --nproc_per_node 8 train.py --batch 128 --data coco.yaml --weights yolov5s.pt --device 0,1,2,3,4,5,6,7During training, we witness a 1 minute 48 seconds epoch time:

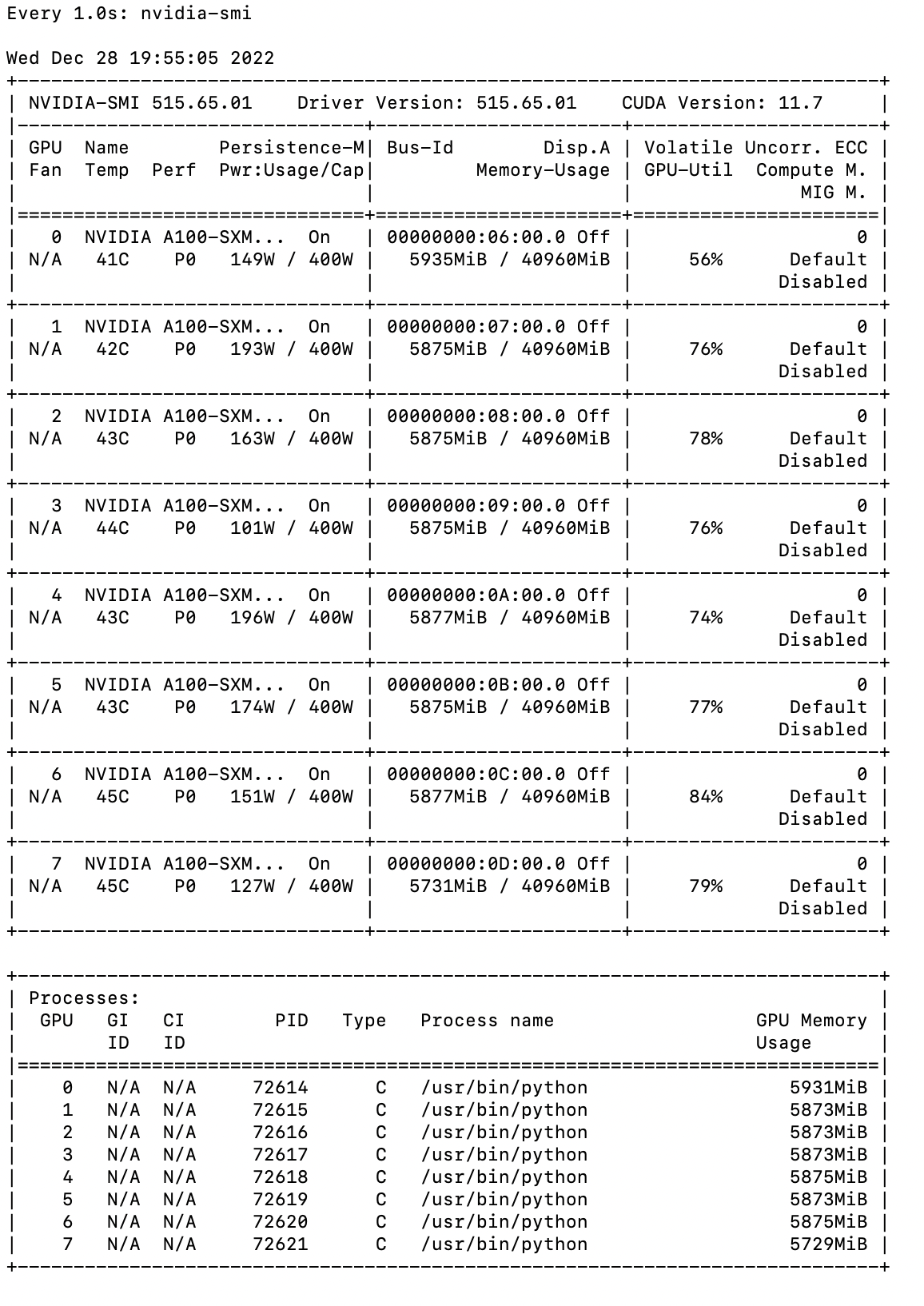
Checking our GPU utilization, we see it is hovering around 80% for each GPU - indicating that we are achieving near full performance for training speed on this setup.
We can also see that all of our CPUs are utilized with htop.
Final GPU Calculation
To calculate the efficiency of our A100 GPUs we take the training time per COCO epoch multiplied by the price per time for the instance to compute a cost per epoch.
(108s / epoch) * ($32.77 / 3600s) = $0.98 / epochThe 8 A100 setup delivers $0.98 / epoch.
Running the 8 Gaudi Accelerator HPUs Baseline

For our HPU benchmark we choose the DL1 instance on AWS powered by Gaudi accelerators from Habana Labs (an Intel company).
The HPUs we test are Gaudi1 accelerators (which are roughly 4x slower than Intel's newer Gaudi2 accelerators). We will have a follow up post on Gaudi2 accelerators when they become more widely available.
Spinning up an Instance
To get started, we launch a dl1.24xlarge instance on AWS. Be sure to launch your instance from the Habana Deep Learning Base AMI in the AWS AMI library to take advantage of all of the Habana and Gaudi pre installations that Intel has provided therein.
To replicate this post, launch on SynapseAI®Ver 1.7.0.

Note: You can always refer to the AWS DL1 quick start guide for more detail.
In addition to launching the base AMI, we need to configure PyTorch bindings for our Gaudi1 accelerator.
pip3 install habana_frameworks
export PYTHON=/usr/bin/python3.8
wget -nv https://vault.habana.ai/artifactory/gaudi-installer/latest/habanalabs-installer.sh
chmod +x habanalabs-installer.sh
./habanalabs-installer.sh install --type pytorchConfiguring YOLOv5 HPU Training
In order to train YOLOv5 on HPU we convert the PyTorch training routine to adapt it to the new hardware. You can read about the basic Habana PyTorch API functionality in this porting PyTorch guide from Habana.
The core modules from Habana we use are:
import habana_frameworks.torch.core as htcore
from habana_frameworks.torch.hpex import hmp
from habana_frameworks.torch.hpex.optimizers import FusedSGD
from habana_frameworks.torch.hpex.movingavrg import FusedEMA
Once we have setup the YOLOv5 code to run on the Gaudi accelerator, we kick off training on COCO with the yolov5s model with batch size 124 for equivalence with our A100 benchmark:
python3 -m torch.distributed.launch --nproc_per_node 8 train.py --noval --data ./data/coco.yaml --weights '' --cfg yolov5s.yaml --project runs/train1 --epochs 300 --exist-ok --batch-size 128 --device hpu --run-build-targets-cpu 1 --run_lazy_mode --hmp --hmp-opt-level O1During training we witness a 3:21 epoch time:

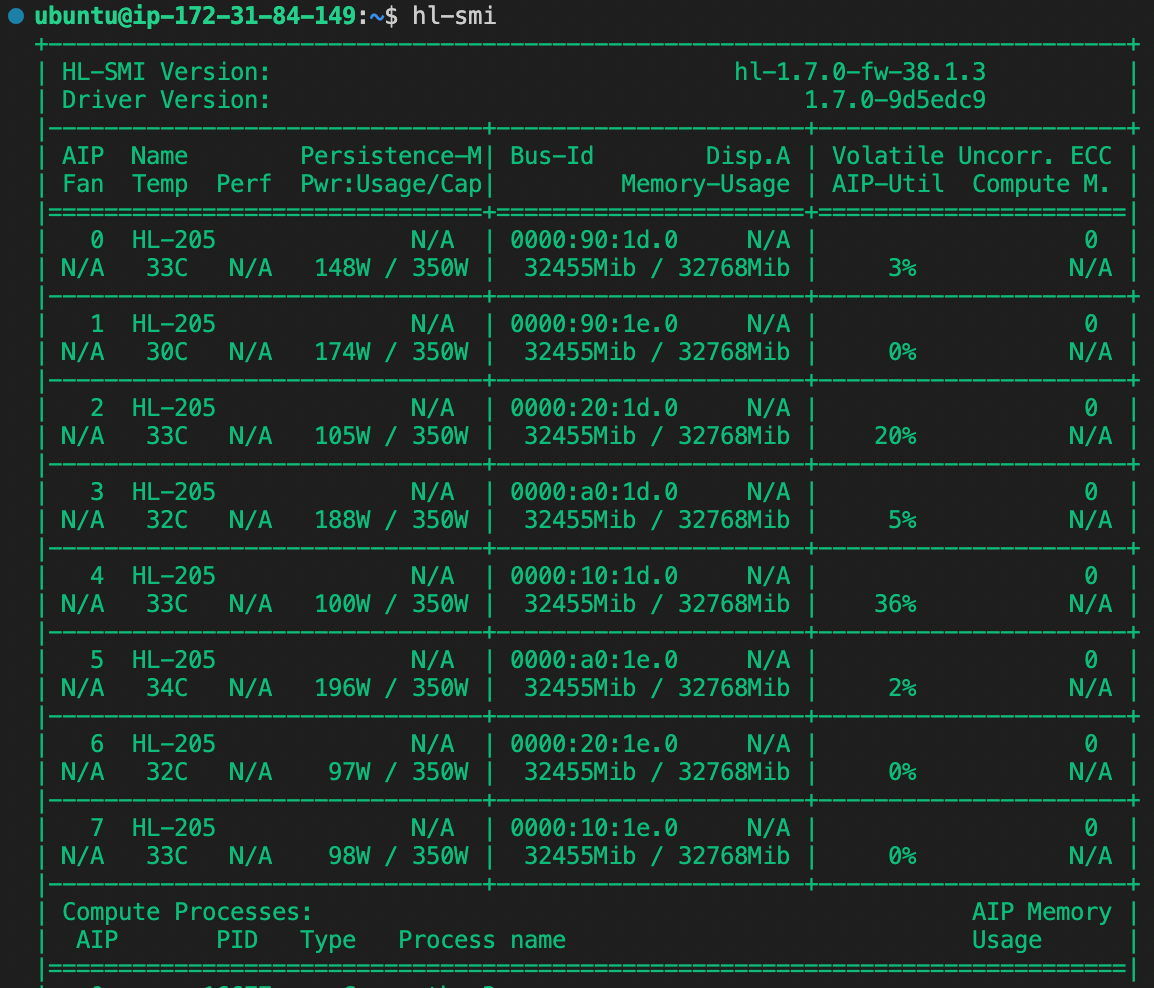
To check if we are utilizing all of the HPU cards we run hl-smi -l. These checks show utilization across all cards with the HPU memory saturated. AIP-Util is not shown to be maxed out on every card, perhaps suggesting there is some additional performance gain to be realized in the training configuration.
We can also check our CPU utilization with htop to be sure we are using the cores we have available.
Final HPU Calculation
To calculate the efficiency of our Gaudi1 HPUs we take the training time per COCO epoch multiplied by the price per time for the instance to compute a cost per epoch.
(201s / epoch) * ($13.11 / 3600s) = $0.73 / epochThe 8 Gaudi1 HPU setup delivers $0.73 / epoch
Conclusion
On the cutting edge of deep learning hardware for computer vision, Habana Gaudi HPUs offer a new alternative to NVIDIA GPUs.
When benchmarking training YOLOv5 on COCO, we found Habana Gaudi1 HPUs to outperform the incumbent NVIDIA A100 GPUs by $0.25 per epoch. That's 25% more epochs per dollar.
- 8 NVIDIA A100 -->
$0.98 / COCO epoch - 8 Intel Gaudi1 HPU -->
$0.73 / COCO epoch
These initial benchmarks for the Gaudi1 accelerators are even more exciting when considering the upcoming release of the Gaudi2 accelerators.
Happy training and wishing your gradients efficient descent!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Dec 30, 2022). HPU vs GPU - Benchmarking the Frontier of AI Hardware. Roboflow Blog: https://blog.roboflow.com/gpu-vs-hpu/