
A machine learning model has two main stages: training and inference. During training, the model learns from large amounts of data. This is where it figures out patterns and relationships in the data.
Once trained, the model moves to inference, where it applies what it's learned to make predictions on new data it hasn’t seen before. Inference is important because it represents the stage where the model delivers real world value.
No matter how accurate a model is during training, its usefulness is ultimately measured by how well and how quickly it can make predictions in deployment.
For example, consider a mobile application that performs object detection on a live camera feed. When the camera captures a frame, the model processes the image and identifies objects (for example below: a raccoon). This short delay between capturing the frame and seeing those boxes appear is called inference latency, and it’s the model’s reaction time.
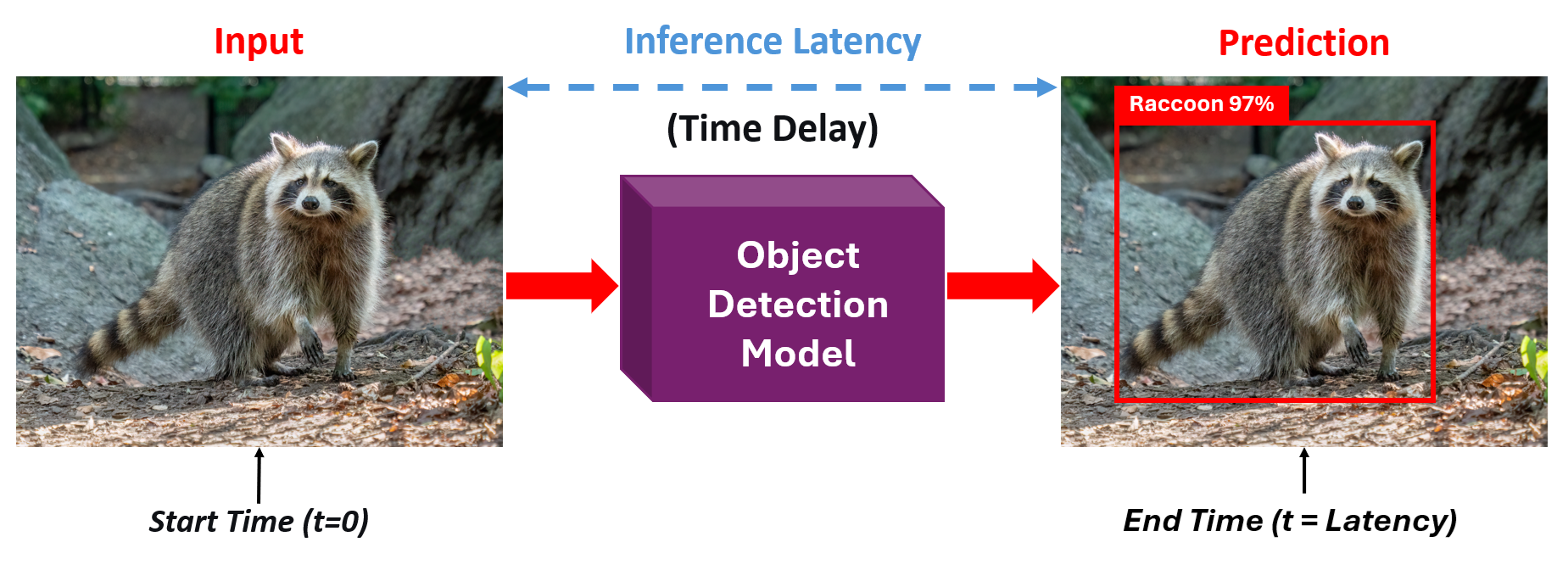
For real time computer vision applications, computer vision models must generate results in real time or near real time. This means inference latency directly impacts the responsiveness, safety, and overall performance of the application. A fast and efficient inference process ensures that the model’s predictions can be used immediately, enabling reliable decision-making in dynamic environments. In autonomous vehicles, for example, low-latency inference allows the system to instantly recognize and react to pedestrians, traffic lights, and obstacles.
What Is Inference Latency?
Inference latency is the time a machine learning model takes to produce a prediction after receiving an input. It is the delay between giving the model some data (such as an image) and getting the result back. Inference latency consists of several sequential steps:
Input Processing
Input processing is the first stage that contributes to inference latency. This step prepares raw data so the model can use it. In computer vision tasks, input processing includes decoding images from formats like JPEG or PNG, resizing them to match the model’s required dimensions, normalizing pixel values, and finally converting the data into a tensor.
Although these operations may appear simple, they can introduce noticeable delays especially on mobile devices or edge hardware with limited compute resources. With high-resolution images or continuous video streams, input processing can become a significant part of the total latency.
Model Inference
Model inference is the main phase of the latency pipeline, where the neural network processes the prepared input and generates predictions. The time taken in this step depends on many factors, such as the model architecture, the number of parameters, the resolution of the input image, and the capability of the hardware running the model.
Precision formats like FP32, FP16, or INT8 also influence speed, as do batch sizes. Larger or more complex models naturally take longer to compute. In most computer vision systems, this stage accounts for the majority of total latency, often making up 60-90% of the entire processing time.
Post-Processing
Post-processing converts the raw output of the model into final, meaningful predictions. The operations involved depend on the specific computer vision task. For object detection, this may include decoding bounding boxes, applying Non-Maximum Suppression (NMS), filtering predictions by confidence, and converting coordinates back to the original image size. Segmentation tasks may require converting probability maps to class labels, upsampling masks, or cleaning up predictions. Pose estimation involves extracting keypoints and grouping them into skeletons. Even classification tasks require softmax activation or selecting top predictions. If not optimized, post-processing can add a significant amount of time especially when dealing with many detections or high-resolution inputs.
Different models have different stages that are added to the inference pipeline and contribute to inference latency. For example, RF-DETR adds a transformer-based detection pipeline to the inference process. The input image is first passed through a backbone network (such as a DINOv2 pre-trained backbone) to produce rich feature maps. These features are then fed into a transformer decoder that directly predicts bounding boxes and class labels, removing the need for anchor boxes. Because the model relies on attention mechanisms, it can generate detections end-to-end with fewer heuristics. A lightweight post-processing step, optimized NMS tuned for minimal latency, is applied at the end to finalize the predictions.
The inference latency acts like the “reaction time” of an AI system. Low latency means the model responds quickly and the application feels smooth and responsive. High latency, on the other hand, creates noticeable delays that can disrupt real-time tasks and make the system difficult or even impossible to use effectively.
Why Is Inference Latency Important?
Although model accuracy usually gets the most attention during development, inference latency ultimately determines whether a model can be used in real world applications. A model might achieve excellent accuracy, but if it needs several seconds to process a single image, it won’t work for tasks like real-time video analysis.
Inference latency also affects cost, especially when models run in the cloud. Many computer vision applications send images to cloud servers for processing, and these servers must handle thousands or even millions of predictions every day. If each prediction takes longer because of high latency, the system can process fewer requests per second. This forces companies to add more servers or use more powerful machines, which increases operating costs.
On the other hand, increasing throughput can reduce the cost per prediction, but if it makes latency worse, users may experience slow or delayed responses. Because of this trade off, teams need to find the right balance between latency, throughput, and cost based on what their application requires.
Real World Applications
Numerous domains rely on AI models that must deliver predictions within strict time budgets. The following examples illustrate how low latency enables or improves real world applications:
- Defect Detection on a Conveyor Belt: In manufacturing, camera systems inspect products moving on a conveyor belt. If the model takes too long to detect a defect, the defective item may pass the rejection point before the system can trigger an actuator.
- Automated Decision Making in Assembly Lines: Robotic arms and pick-and-place machines rely on computer vision to decide where and when to grab components.
- Industrial Safety Monitoring: Safety systems use cameras to detect when a worker enters a restricted zone. High latency can delay alerts or machine shutdowns, defeating the purpose of the system.
Monitor Red Zones for Safety with Computer Vision
Latency Sources: Where Time is Spent
Inference latency comes from several small steps added together. Understanding each step helps identify what to optimize.
- Input Preprocessing Time: The time spent preparing the data before it enters the model. For images, this includes resizing, normalization, and converting to tensors. Poorly optimized preprocessing can add noticeable delay.
- Data Transfer Time: The time spent moving data to the device that will run the model. This includes CPU -> GPU transfer or network time if using a remote server. Network delays are often one of the biggest bottlenecks.
- Model Execution Time: The actual time the model takes to run its forward pass. This is usually the largest part of latency and depends on model size, architecture, and hardware speed.
- Post-processing Time: The time needed to turn raw model outputs into usable results. For example, NMS for object detection.
- System Overhead Time: Extra time from the software stack i.e. operating system scheduling, hardware drivers, or switching between processes. These small delays add up and contribute to total latency.
Factors That Impact Inference Latency
Inference latency is influenced by many factors, from the design of the model to the hardware it runs on, such as:
- Model Architecture: This is one of the most significant factors. Larger models with more parameters inherently have higher computational demands and thus higher latency compared to smaller, more efficient architectures.
- Model Size and Complexity: Directly related to model architecture, the number of layers, parameters, and the type of operations influence latency.
- Hardware: Different types of hardware, for example:
- CPUs are flexible but slow for deep learning workloads.
- GPUs handle parallel operations well and give much faster inference.
- TPUs are specialized chips built for deep learning and can offer very low latency for supported models.
- NPUs in phones and edge devices are designed specifically for fast, low-power inference.
- Software and Frameworks: Runtime also impacts latency. Optimized engines like TensorRT, ONNX Runtime, or TensorFlow Lite can run the same model much faster than unoptimized frameworks.
- Precision (FP32, FP16, INT8): Lower precision means faster computation. FP16 is faster than FP32, and INT8 quantized models can be 2-4× faster with only a small drop in accuracy.
- Batch Size: Larger batches increase throughput but also increase latency because you wait for the whole batch to finish. Real-time applications usually use a batch size of 1.
- Input Resolution: Higher-resolution images contain more data and take longer to process. A model running on 1080p frames is much slower than one using 224×224 inputs.
Understanding these factors makes it easier to identify bottlenecks and choose the right strategies to reduce latency and improve real-time performance.
Inference Latency vs. Throughput
It is important to understand the difference between latency and throughput, as they are often at odds with each other.
Inference Latency is the time taken to process a single input. It is measured in units of time (e.g., milliseconds). It is the primary concern for real-time, interactive applications where a user is waiting for an immediate response.
Throughput is how many inferences a system can process per second. It matters when you need to handle a large number of inputs quickly, such as processing large number of images in a dataset. In these cases, you care more about overall speed than the time taken for each individual prediction.
The trade-off comes from batch size. Using a large batch gives higher throughput because the hardware processes many inputs at once. However, this increases latency because the system must wait to collect the full batch, and processing a big batch takes longer than processing a single input. Using a batch size of 1 gives the lowest latency because the system processes each input immediately. But this leads to lower throughput because the hardware is not being fully used. In short, large batches improve throughput but increase latency, while small batches reduce latency but lower throughput.
Optimization Strategies: How to Reduce Latency Without Losing Accuracy
Achieving low-latency inference is a multi-faceted challenge. With the right mix of pruning, quantization, architecture choices, and hardware-aware optimization, it’s possible to build models that are both fast and reliable. Here are the main strategies:
Model Pruning
This technique involves removing redundant or less important parts of a neural network. Think of it as "trimming the fat." This can mean removing entire neurons, channels in a convolutional layer, or individual weights. Pruning reduces the model size and the number of computations required, directly leading to lower latency. Research by Han et al. demonstrates that pruning can reduce the number of parameters in state-of-the-art models without losing accuracy.
Quantization
This is one of the most powerful and widely used techniques. Quantization reduces the precision of the numbers used to represent the model's weights and activations. Most models are trained using 32-bit floating-point numbers (FP32). Quantization converts these to lower-precision formats like 16-bit float (FP16) or 8-bit integers (INT8). This makes the model smaller and allows for faster computation on hardware that is optimized for these precisions. Jacob et al. outlines a method for post-training quantization that allows INT8 inference with minimal accuracy loss.
Knowledge Distillation
This technique trains a small, fast “student” model to mimic the behavior of a large, accurate, but slow “teacher” model. Instead of learning only from the original training labels, the student also learns from the teacher’s soft probability outputs, which carry richer information. The result is a compact model that often matches the teacher’s accuracy while running with much lower latency, as described in the seminal paper by Hinton et al.
Model Architecture Selection and Neural Architecture Search (NAS)
Choosing the right model architecture is one of the easiest ways to reduce latency. Some networks like MobileNet (which uses depthwise separable convolutions), EfficientNet (which uses balanced scaling), and SqueezeNet are designed from the start to run fast on limited hardware. You can also use NAS techniques to automatically search for new architectures that meet a specific latency goal on a target device. MNasNet by Tan et al. is a well-known example because it directly uses real device latency as part of the search objective.
Hardware-Aware Optimization and Compilation
Many tools can optimize your model specifically for the hardware it will run on. NVIDIA TensorRT, for example, speeds up models on NVIDIA GPUs by applying optimizations such as layer fusion, precision tuning (like FP16 or INT8), and automatic kernel selection. Apache TVM provides a similar idea in an open-source form, letting you compile and optimize models for many types of CPUs, GPUs, and hardware accelerators. Both tools generate optimized runtime engines that significantly lower inference latency.
Specialized Hardware
Deploy your model on hardware built for the task. While GPUs are great, TPUs and NPUs (like the Google Edge TPU or the Apple Neural Engine) are designed from the ground up to execute neural network operations with extreme power and latency efficiency.
Make Low-Latency Deployment Simple with Roboflow Inference
Reducing inference latency isn't only about model design or hardware choice: the deployment tool also plays a major role. Tools like Roboflow Inference, TensorRT, and ONNX Runtime offer optimized inference pipelines. Roboflow Inference, for instance, is an open-source system built to run computer vision models with low latency across edge devices, local machines, and cloud environments.
One example is the use of UDP inference for real-time video streams. In fast applications such as sports analysis or live camera processing, waiting for slow network acknowledgments can introduce delays. UDP avoids this problem by sending frames without blocking, allowing the model to keep processing even if some packets are delayed or dropped. This leads to smoother, lower-latency streaming compared to traditional HTTP-based pipelines.
Example of running inference with UDP
Roboflow Inference also supports local deployment, which removes cloud round-trip time entirely. You can run models directly on a local CPU or GPU using the inference Python package or a simple Docker container, to get faster predictions, offline capability, and better control over data. The platform is pre-optimized and works with a wide range of architectures, so you don’t need to manually configure runtimes or hardware accelerators.
Example of local computer vision deployment
Together, these features show how deployment choices can be just as important as model optimizations when targeting real-time performance.
Read more in our blogs:
• How to Run Inference with UDP on Roboflow Inference
• How to Deploy Computer Vision Models Offline
• Model Deployment
Conclusion: Inference Latency
Inference latency in computer vision is more than a performance metric. It determines whether AI systems can perceive and interact with the world in real time. By understanding the sources of latency and the factors that influence it, you can make informed design choices that balance responsiveness, accuracy, and cost.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Nov 13, 2025). Inference Latency. Roboflow Blog: https://blog.roboflow.com/inference-latency/