
The Roboflow Python package now supports generating dataset versions, exporting data, and launching model training directly from code, without touching the web UI. These Platform Actions make it practical to build automated pipelines, such as retraining a model on a schedule or triggering a new training run after a set number of newly annotated images, all in a few lines of Python using the roboflow pip package.
Today, we are launching a new set of features, collectively called Platform Actions, for our Roboflow Python package. These features make it easier to generate dataset versions, export them, and train models within your Python code.
In this post, we’re going to talk about Platform Actions in depth and how you can leverage them to reduce the time it takes you to build computer vision models. Let’s get started.
Generate Dataset Versions
You need to create a dataset version before you can train your model on Roboflow. Dataset versions let you create a checkpoint of your model to which you can refer later.
For example, you can create a version with a specific augmentation applied, train a model using that version, and then do the same with another augmentation. You now have two checkpoints that you can compare and evaluate.
In addition, versions ensure that changes you make to your dataset do not affect the results of previous models you have trained.
Now, generating a dataset version can be done in Python in a few lines of code.
To use the feature, first initialize your Roboflow project using the Roboflow pip package:
from roboflow import Roboflow
rf = Roboflow(api_key="API_KEY")
project = rf.workspace("YOUR_WORKSPACE").project("YOUR_PROJECT")Then, you can generate a version of your project in one line of code:
new_version = project.generate_version()You can pass in a dictionary with the augmentation and preprocessing steps you want to apply.
With this change, you could create a system that lets you easily create versions of new projects based on existing configurations that you store locally. Consider a scenario where you maintain multiple aerial imagery projects. If you find that an augmentation that works on one project, you could use our Python package to create a new version of all of your other projects that applies the augmentation.
Consider this code:
version_info = {“augmentation”: { “flip”: { “horizontal”: True }}}
new_version = project.generate_version(version_info)This code creates a version of our dataset where only a flip augmentation is applied. For a full list of the augmentation and preprocessing options, see the Roboflow Python generate_version documentation.
When you generate a new version, it will show up in the Roboflow web interface:
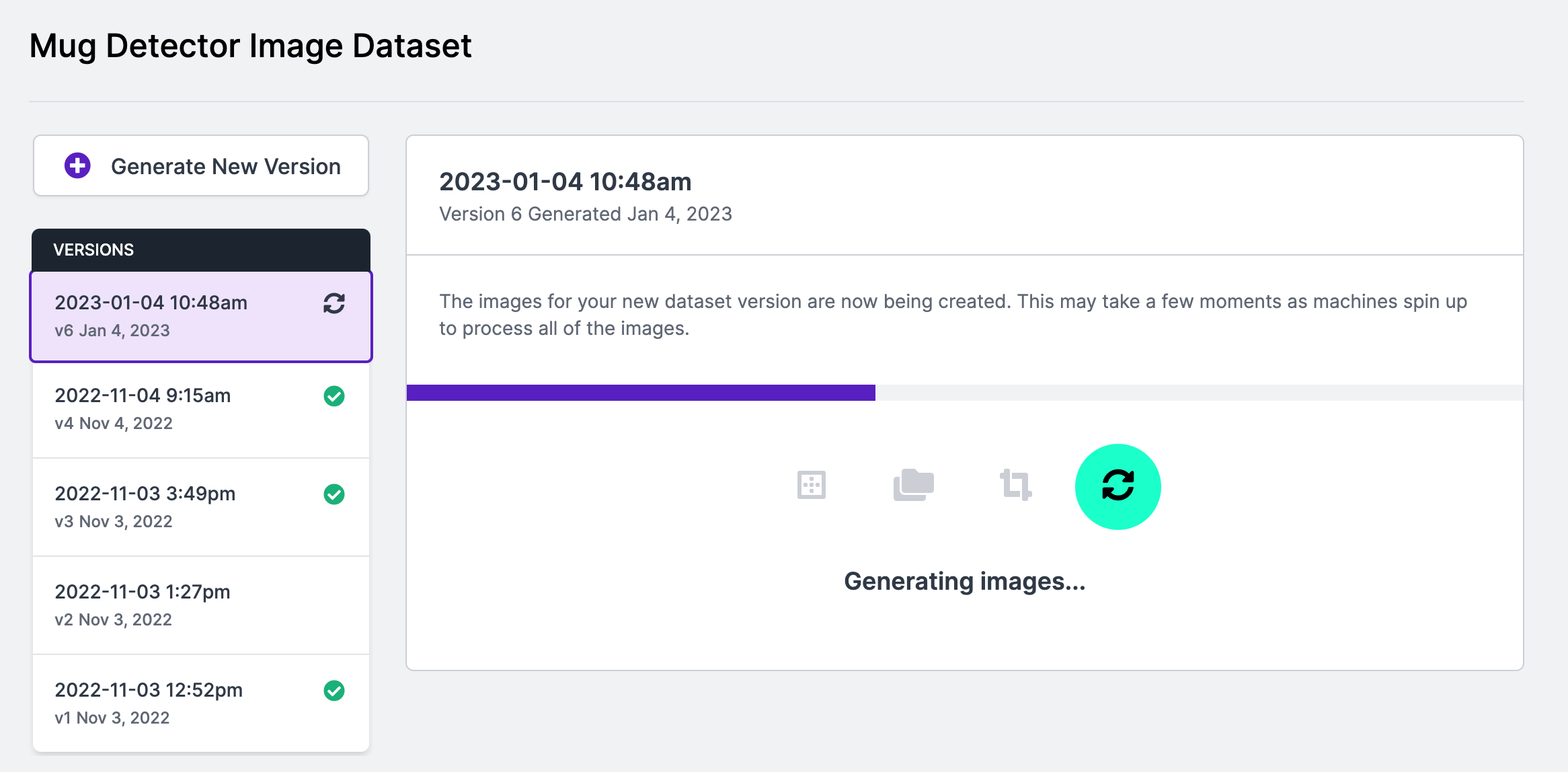
The following code shows how you could apply an augmentation to multiple projects:
from roboflow import Roboflow
rf = Roboflow(api_key=os.environ.get("API_KEY"))
workspace = rf.workspace(os.environ.get("PROJECT_WORKSPACE_ID"))
# Replace this list with your projects
projects = ["sports-classifier-sl8xy", "sports-classifier"]
for project in projects:
roboflow_project = workspace.project(project)
augmentation = {"augmentation": { "flip": { "horizontal": True, "vertical": True }}, "preprocessing": {}}
roboflow_project.generate_version(augmentation)
This script creates a new version in each of the two specified objects with a horizontal and vertical flip augmentation.
Export Dataset Versions
The new Python export() method lets you export your dataset from the Roboflow platform in one line of code. You can then use download() to save a file that contains your data to your local machine. This is useful if you annotate and process data in Roboflow that you need to use in a custom training pipeline you have built, for example.
You can export your data into any one of many supported export formats. See the full list of supported formats on our Platform Actions documentation for the export method.
Consider a scenario where you want to export your object detection data to the YOLOv5 PyTorch format and save the data to your local machine. You can do so in a few lines of code:
from roboflow import Roboflow
rf = Roboflow(api_key="API_KEY")
project = rf.workspace("YOUR_WORKSPACE").project("YOUR_PROJECT")
version = project.version("v1")
version.export("yolov5pytorch")
version.download("yolov5pytorch")This code exports our model into a zip file that contains YOLOv5 PyTorch data.
This function supports export for object detection, single-label classification, multi-label classification, instance segmentation, and semantic segmentation datasets.
Train a Model
The Roboflow Python package now lets you train a model in two different ways:
- Using a specific version of a generated dataset.
- Generating a new dataset version and training a model on that dataset immediately after.
These two new features mean that training a model with the Roboflow platform is now accessible in only one line of code, once you have initialized a project into your code.
0:00/1×Train a model in a few lines of code.
Train a Model with a Generated Dataset
To train a model using an existing version of a dataset, use this code:
from roboflow import Roboflow
rf = Roboflow(api_key="API_KEY")
project = rf.workspace("YOUR_WORKSPACE").project("YOUR_PROJECT")
version = project.version("v1")
version.train()Generate a Dataset Version and Train a Model
You can generate a new dataset version by using the train() method on a “project” object.
With this change, you can set up automated deployment for new versions of models. For example, say you want to retrain a model every day because you are annotating many images each day. This is now possible within our Python package.
You could also set up automated deployment after a certain number of new images are annotated. For example, for every 200 new images that you annotate, you could generate a new model.
The following code lets you generate a new version of a dataset and train it:
from roboflow import Roboflow
rf = Roboflow(api_key="API_KEY")
project = rf.workspace("YOUR_WORKSPACE").project("YOUR_PROJECT")
project.train()After generating a dataset version, training will begin:
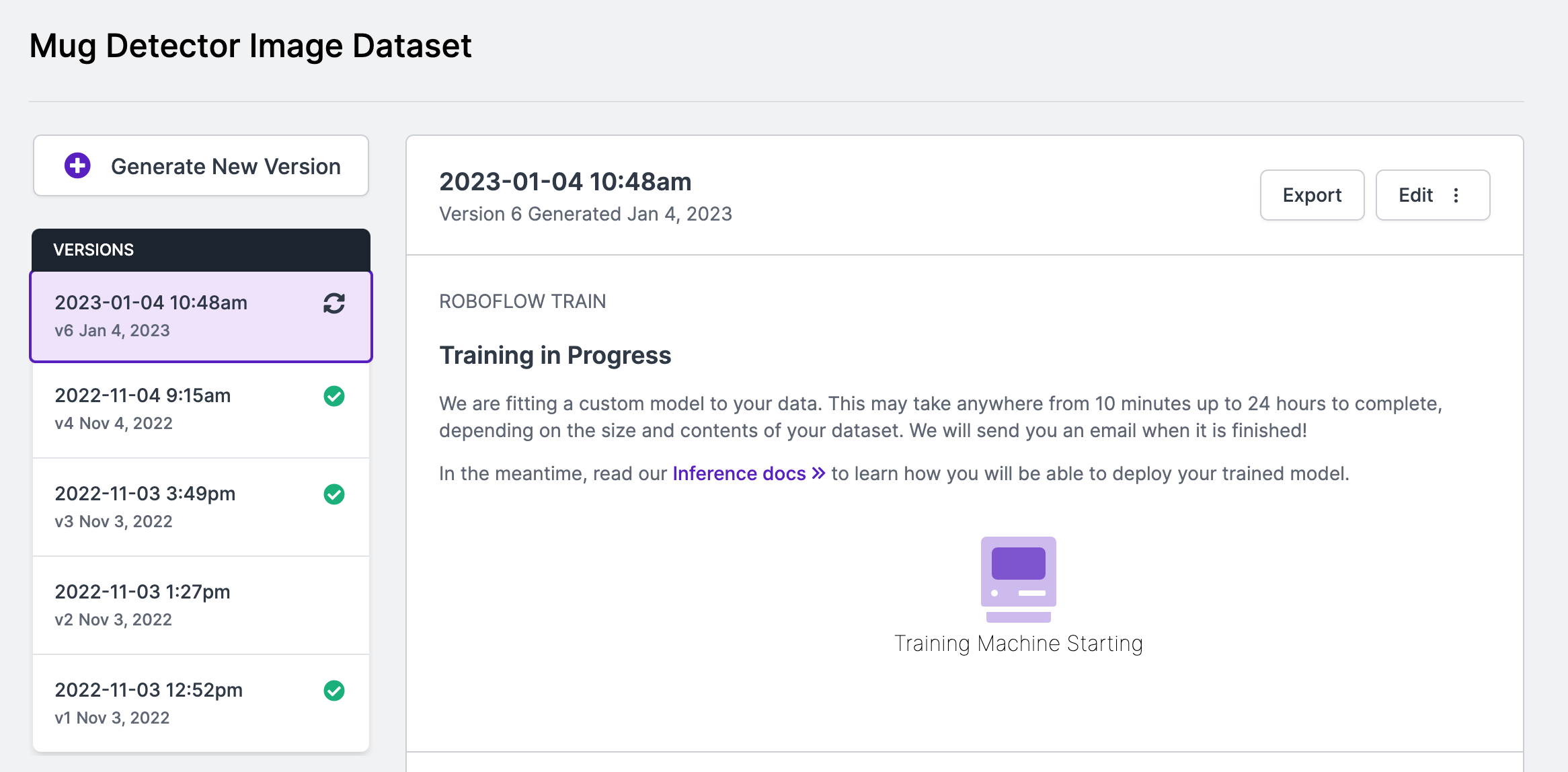
Conclusion
The features we have discussed above are live in the latest version of our Python package. Remember to update to the latest version to make use of our new version, data export, and model training features that we have discussed above. Happy building!
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Jan 4, 2023). Launch: Version, Export, and Train Models in the Roboflow Python Package. Roboflow Blog: https://blog.roboflow.com/launch-version-export-and-train-models-in-the-roboflow-python-package/