
When new multimodal models come out, they need to be tested on reliable benchmarks to see how well they perform across different tasks. Today we'll share some of the best multimodal benchmark datasets you can use to evaluate new models. These diverse and well-structured benchmark datasets push AI systems to reason across text, images, and even video.
Explore the Landscape of Multimodal Benchmark Datasets
Whether you're working with datasets like TallyQA for visual question answering, leveraging the LAVIS benchmarks for a wide array of tasks, or exploring more advanced challenges like POPE for object hallucination, each benchmark below offers unique opportunities to test and refine the capabilities of your models.
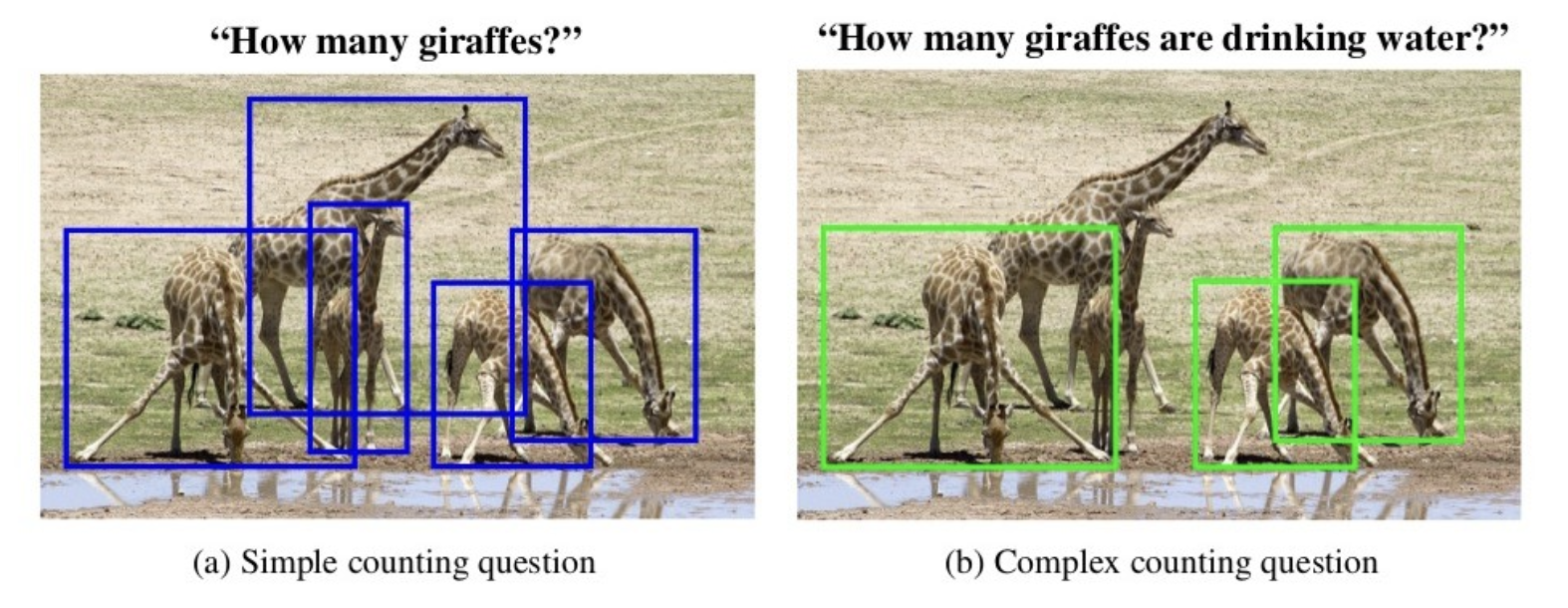
1. TallyQA Dataset
TallyQA is a Visual Question Answering dataset specifically designed to address counting questions in images. It distinguishes between simple counting questions, which only require object detection, e.g., "How many dogs are there?", and complex counting questions that require understanding relationships between objects along with their attributes and require more reasoning. The dataset has 287,000 questions related to 165,000 images, including 19,000 complex questions collected via Amazon Mechanical Turk.
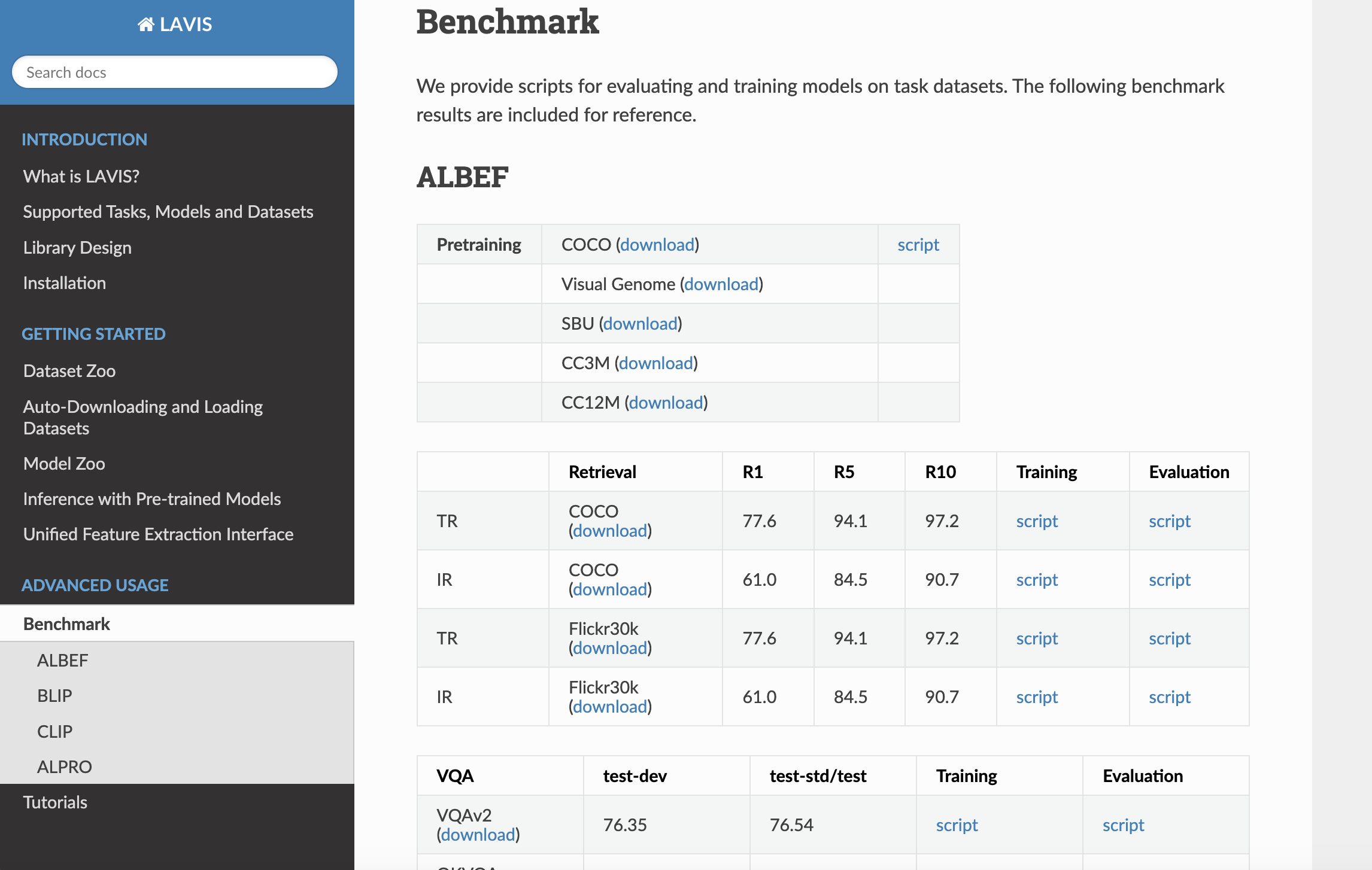
2. LAVIS Benchmark
LAVIS Python deep learning library includes benchmark results for various models, including ALBEF (Align Before Fuse), BLIP (Bootstrapping Language-Image Pre-training), CLIP (Contrastive Language–Image Pre-training), and ALPRO (Action Learning from PROtotypes), across multiple tasks such as image-text retrieval, visual question answering, image captioning, and multimodal classification. Additionally, LAVIS offers scripts for evaluating and training these models on specific datasets.
3. Stanford's Graph Question Answering Dataset
Developed to enhance scene understanding in computer vision, the GQA dataset offers scene graphs, featuring compositional questions over real-world images. The dataset has 22 million questions about various day-to-day images. Each image is associated with a scene graph (JSON files) of the image's objects, attributes and relations, a new cleaner version based on the Visual Genome project. Many of the GQA questions involve multiple reasoning skills, spatial understanding and multi-step inference, thus are generally more challenging than previous visual question answering datasets.
4. Massive Multitask Language Understanding
This dataset is a crucial benchmark for evaluating AI models’ general knowledge and reasoning across diverse subjects. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more - great for comprehensively evaluating the breadth and depth of a model's academic and professional understanding. While most contemporary models performed near random chance, the largest GPT-3 model surpassed random chance by nearly 20 percentage points on average.
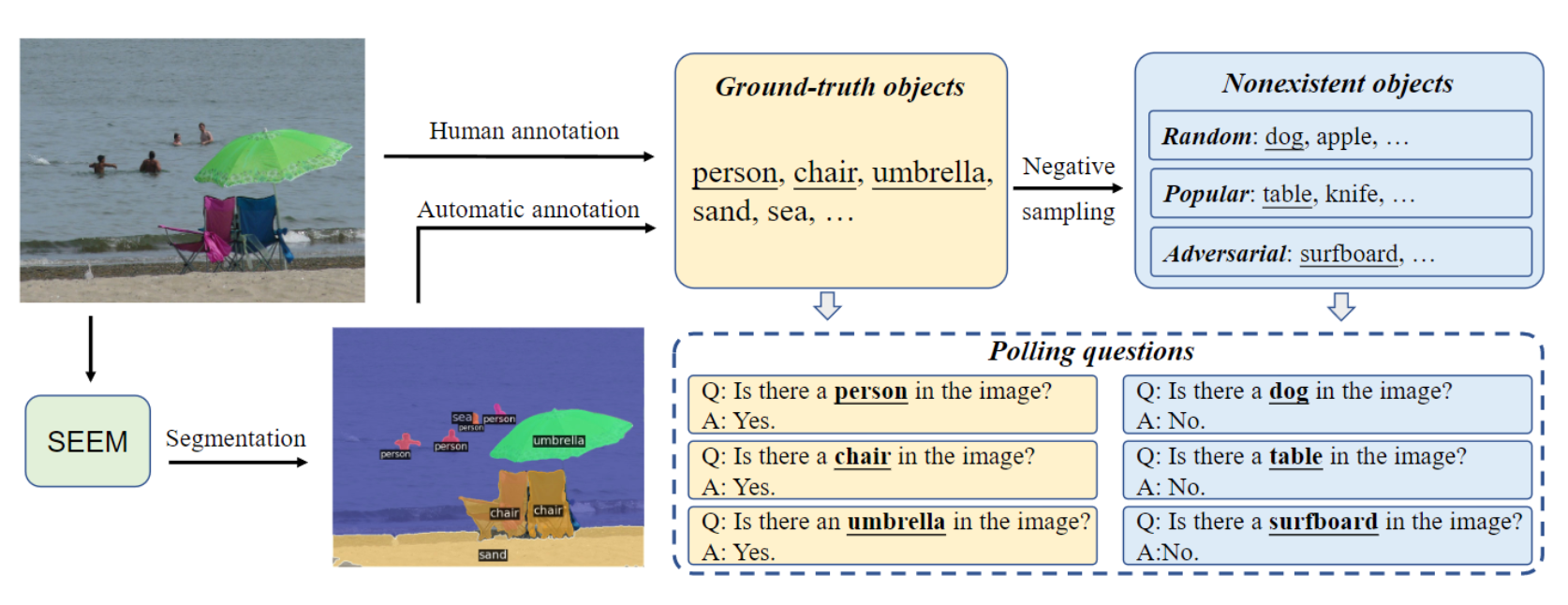
5. POPE
Pose Object Pose Estimation is a framework designed to assess object hallucination in large vision-language models (where a model generates descriptions of objects that are not in the given image).With the help of automatic segmentation tools like SEEM, you can also build POPE on any dataset you want to test.
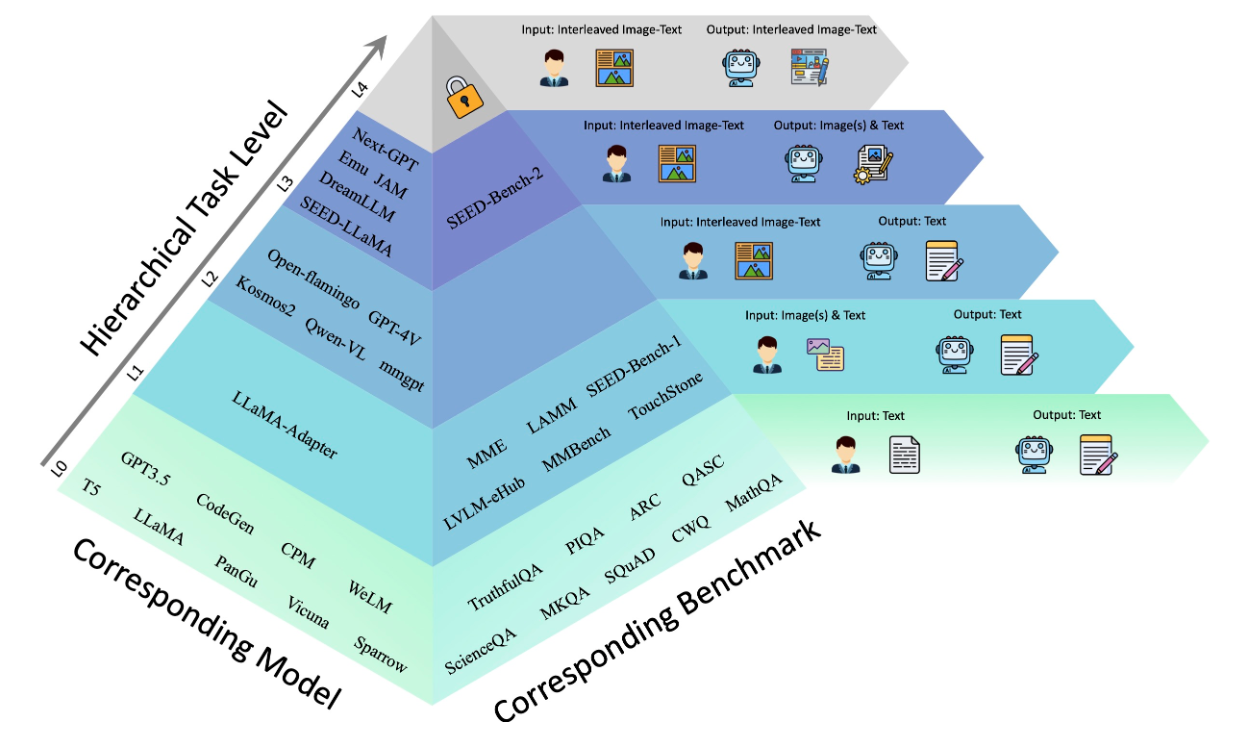
6. SEED-Bench
SEED-Bench-H has 28,000 multiple-choice questions with precise human annotations, spanning 34 dimensions, including the evaluation of both text and image generation. It's a comprehensive integration of previous SEED-Bench series (SEED-Bench, SEED-Bench-2 , SEED-Bench-2-Plus), with additional evaluation dimensions. The GitHub repository has over 300 stars, and models such as Qwen-VL have utilized SEED-Bench for evaluation, achieving state-of-the-art results on this benchmark.
7. Massive Multi-Discipline Multimodal Understanding Benchmark
The MMMU benchmark has 11,500 multimodal questions sourced from college exams, quizzes, and textbooks, covering six core disciplines art and design, business, science, health and medicine, humanities and social science, tech and engineering. The questions span 30 subjects and 183 subfields, incorporating 32 diverse image types such as charts, diagrams, maps, tables, music sheets, and chemical structures. In September 2024, the MMMU-Pro benchmark was introduced as a more robust version.

8. Roboflow 100 Vision Language (RF100-VL)
RF100-VL is the first benchmark to ask, “How well does your VLM do in understanding the real world?” In pursuit of this question, RF100-VL introduces 100 open source datasets containing object detection bounding boxes and multimodal few shot instruction image-text pairs across novel image domains. The dataset is comprised of 164,149 images and 1,355,491, annotations across seven domains, including aerial, biological, and industrial imagery. 1693 labeling hours were spent labeling, reviewing, and preparing the dataset.

Use Some of the Best Multimodal Benchmark Datasets
These benchmark datasets are essential tools for evaluating and advancing multimodal AI models. They provide insights into how well models can understand and reason about complex visual and textual data, from simple counting tasks to intricate scene comprehension.
Test and evaluate new models on real-world image and video datasets with Roboflow Deploy.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (Mar 4, 2025). Multimodal Benchmark Datasets. Roboflow Blog: https://blog.roboflow.com/multimodal-benchmark-datasets/