
Counting objects is a human task we take for granted. It seems simple but there's a lot of processing going on to make it happen and extremely useful information to be had in being able to count objects.
Imagine a farmer walking through his field pauses beneath a tree, and asks himself, “How many apples are on this tree?”. This question might seem ordinary, but it holds immense value.
Knowing the count helps the farmer estimate yield, manage the harvest, and plan distribution. However, human counting is not possible at scale.
That's the power of automated object counting with computer vision: teaching machines to see and count quickly and accurately.

Object Counting with Computer Vision Overview
In this article, we’ll explore object counting using computer vision, from basic concepts to real-world applications. You’ll learn:
- What object counting is and why it matters.
- The difference between counting in images vs. videos.
- The challenges machines face (such as occlusion, overlap, and duplicates).
- Real industry applications in manufacturing, healthcare, agriculture, and warehousing.
- How to use tools such as Roboflow simplify the process, from dataset creation to model deployment.
- Why RF-DETR, a transformer-based model, is particularly powerful for counting under challenging conditions.
- And finally, how to build object counting applications for:
- Image-based object counting
- Video-based object counting
- Zone-based counting in video
- Object counting in live camera feed
What Is Object Counting?
Object counting in computer vision is a task where systems automatically identify and count instances of specific objects in images or video frames. The core objective is to detect and enumerate how many objects of interest (e.g., people, vehicles, products) appear in the scene in an image or video.
This approach is applied in different settings:
- In images, the system counts all visible instances at once.
- In video footage, it tracks and counts objects as they move across the scene, such as people walking through a doorway or cars passing a checkpoint.
We will explore both counting objects in images and videos later in this post.
Core Concepts in Object Counting
Object counting in computer vision revolves around a fundamental question:
“How many objects of a specific type are present in an image or video?”
For humans, this task is second nature. In computer vision, the goal is to train machines to replicate this human ability in an automated and reliable way.
The essence of object counting lies in three main steps:
- Understand What to Count: The system first needs to define what counts as an object of interest. This could be anything, from people and cars to animals, tools, or manufactured parts.
- Locate Each Instance: Once the object type is defined, the system must identify every individual occurrence of that object within a scene. Each detected object is considered a separate instance.
- Maintain an Accurate Count: For every object instance found, the system increments a counter. The final output is a number representing how many such objects are present.
How to Count Objects in Images
The process of counting objects in an image typically involves the following key steps:
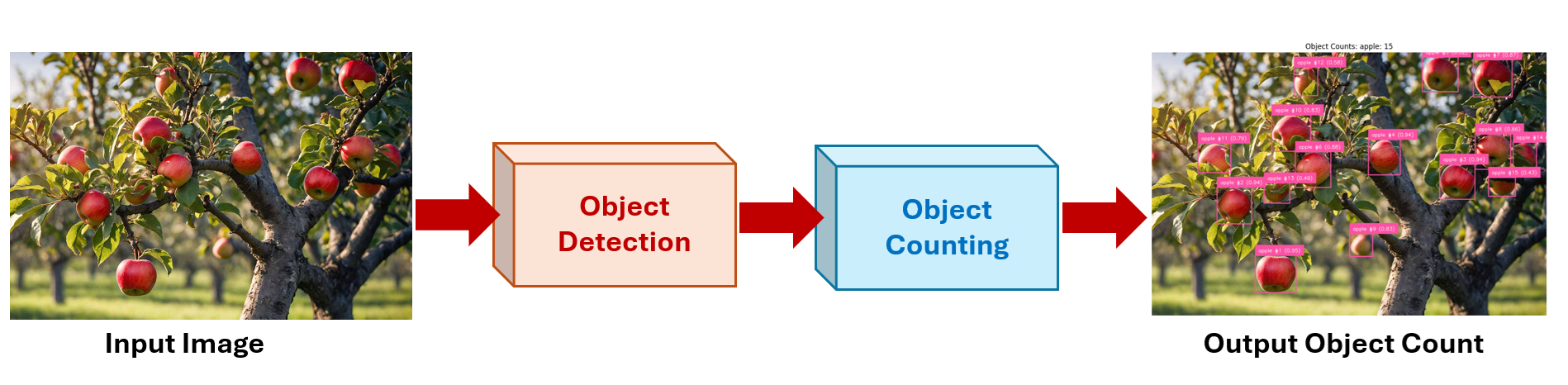
- Image Acquisition: Capture input data in the form of still images. This serves as the raw input for further processing.
- Object Detection or Localization: Apply a computer vision model to identify and locate objects of interest within the image. This step outputs bounding boxes or segmentation masks around each object.
- Object Counting: Count the total number of detected objects by summing up the individual detections. Each valid bounding box or segmented instance is considered one count.
How to Count Objects in Videos
Counting objects in videos involves not only detecting objects in individual frames, but also tracking them over time to avoid duplicates. The process typically includes the following stages:
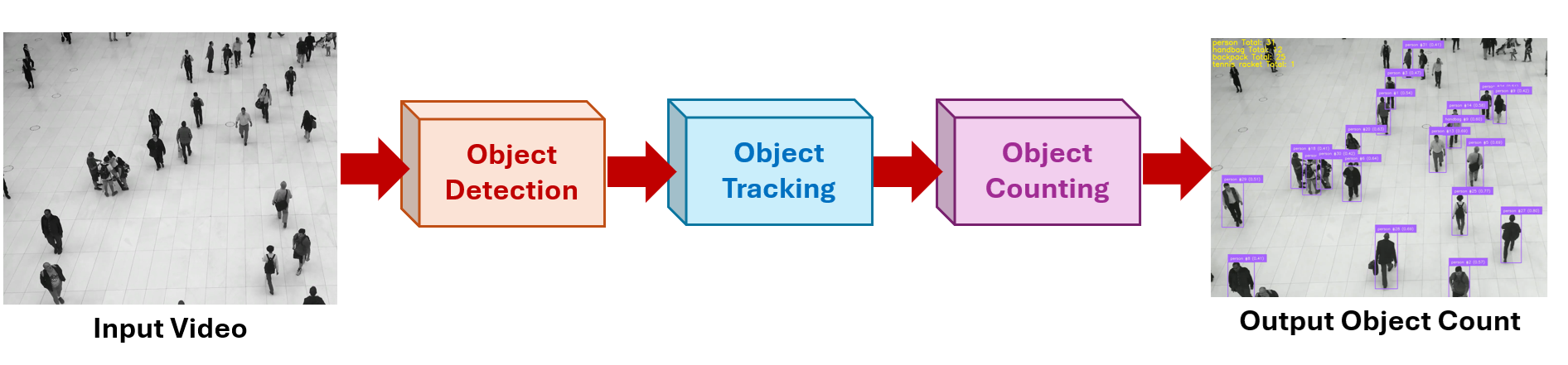
- Detection: A pre-trained object detection model is applied to each video frame. It identifies and locates objects of interest by drawing bounding boxes around them, providing the position and class label of each object in the current frame.
- Tracking: Once objects are detected, a tracking algorithm (such as SORT, DeepSORT, or ByteTrack) assigns a unique ID to each object and follows it across subsequent frames. This ensures that the same object is consistently recognized throughout the video, even as it moves.
- Counting: The system maintains a registry of object IDs and counts each object only once. Counting can be triggered when:
- An object crosses a predefined line or zone (line-crossing logic).
- A new object ID appears in the scene.
- An object completes a specific path or exits the frame.
This approach ensures accurate, real-time counting by preventing repeated counts of the same object and maintaining consistency over time.
Challenges of Object Counting
Although the object counting concept seems straightforward, several challenges make object counting a non-trivial task for machines. These are:
- Distinguishing Between Similar Objects: Objects of the same type might appear very close together, overlap, or look nearly identical. The system must recognize and separate them accurately.
- Avoiding Duplicate Counts: Especially in video streams, the system must ensure that moving objects aren’t counted more than once.
- Handling Occlusion and Clutter: Parts of objects may be hidden behind others or partially out of frame, requiring the system to make smart guesses.
- Adjusting to Variability: Lighting changes, camera angles, object sizes, and background complexity can all impact the accuracy of counting.
Object counting is the automated process of identifying and tallying the number of individual objects in an image or video. The core goal is to detect each distinct object instance and produce an accurate count, similar to how a person would, but done by a machine with consistency and scale. In simple terms, it’s like training a computer to look at a scene and say:
“There are 7 people,” or “12 vehicles passed by.”
This foundational task serves as the backbone for many real-world applications where understanding quantity is critical.
How To Count Objects with Computer Vision (4 Examples)
Here's how you can build object counting applications using Roboflow. For our example we will use RF-DETR and we will build examples for following tasks:
- Object Counting in Image
- Object Counting in Video
- Object Counting in Zone (Video based)
- Object Counting in a Live Camera Feed
Example #1: Object Counting in Image
In this example we will create a Roboflow Workflow which accepts image and detect objects using the RF-DETR base model. We'll create a Workflow and add the Object Detection block and configure it with RF-DETR base model as shown in image below.
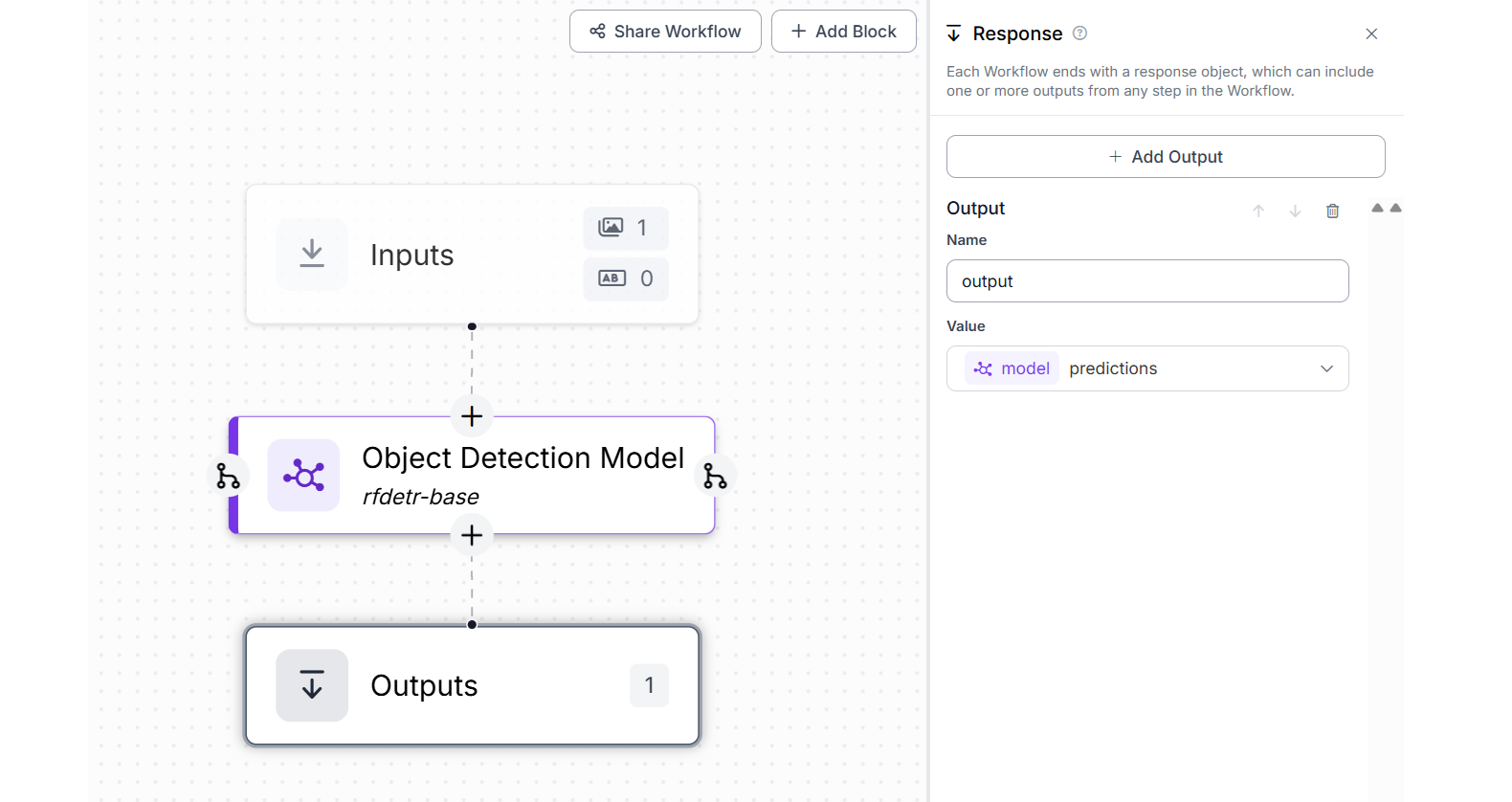
Now deploy this Workflow using code below to detect and count objects.
import cv2
import numpy as np
import supervision as sv
from collections import Counter
import matplotlib.pyplot as plt
from PIL import Image
from inference_sdk import InferenceHTTPClient
# Load original image
image_path = "dogs.png"
image_bgr = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="YOUR_API_KEY"
)
result = client.run_workflow(
workspace_name="tim-4ijf0",
workflow_id="object-counting-image",
images={
"image": image_path
},
use_cache=False
)
# Parse predictions
predictions = result[0]["output"]["predictions"]
xyxy = []
confidences = []
class_names = []
for pred in predictions:
conf = pred["confidence"]
cls = pred["class"]
x_c, y_c = pred["x"], pred["y"]
w, h = pred["width"], pred["height"]
x1 = x_c - w / 2
y1 = y_c - h / 2
x2 = x_c + w / 2
y2 = y_c + h / 2
xyxy.append([x1, y1, x2, y2])
confidences.append(conf)
class_names.append(cls)
xyxy = np.array(xyxy, dtype=float)
confidences = np.array(confidences, dtype=float)
class_names = np.array(class_names)
# Assign per-class object numbers
per_class_counter = Counter()
labels = []
for cls, conf in zip(class_names, confidences):
per_class_counter[cls] += 1
count = per_class_counter[cls]
labels.append(f"{cls} #{count} ({conf:.2f})")
# Supervision Detections object
detections = sv.Detections(
xyxy=xyxy,
confidence=confidences,
class_id=np.zeros(len(xyxy), dtype=int)
)
# Visualize
annotated = image_rgb.copy()
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
annotated = box_annotator.annotate(scene=annotated, detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
# Display
plt.figure(figsize=(12, 10))
plt.imshow(annotated)
plt.axis("off")
plt.title("Object Counts: " + ", ".join(f"{k}: {v}" for k, v in per_class_counter.items()))
plt.show()How it works: This code performs object counting and visualization on an image using the output from Roboflow Workflow. The script loads an image and sends it to a custom Roboflow Workflows using the InferenceHTTPClient.
This workflow contains an object detection model (rf-detr-base), which returns predictions, each with class name, position, size, and confidence. The script converts these detections into bounding boxes, and then assigns a unique number to each detected object class (e.g., dog #1, cat #2) along with its confidence score.
Using the Supervision library, it visualizes the detections by drawing bounding boxes and labels directly on the image. Finally, it displays the image with annotated objects and a title summarizing the count of each class (like Object Counts: dog: 3, cat: 2), effectively turning this into a simple but powerful object counting application.
Running the script on following input image:

Will generate output similar to following:

Example #2: Object Counting in Video
In this example we will learn how you can count objects in a video. For this example first create a Roboflow Workflow as follows.
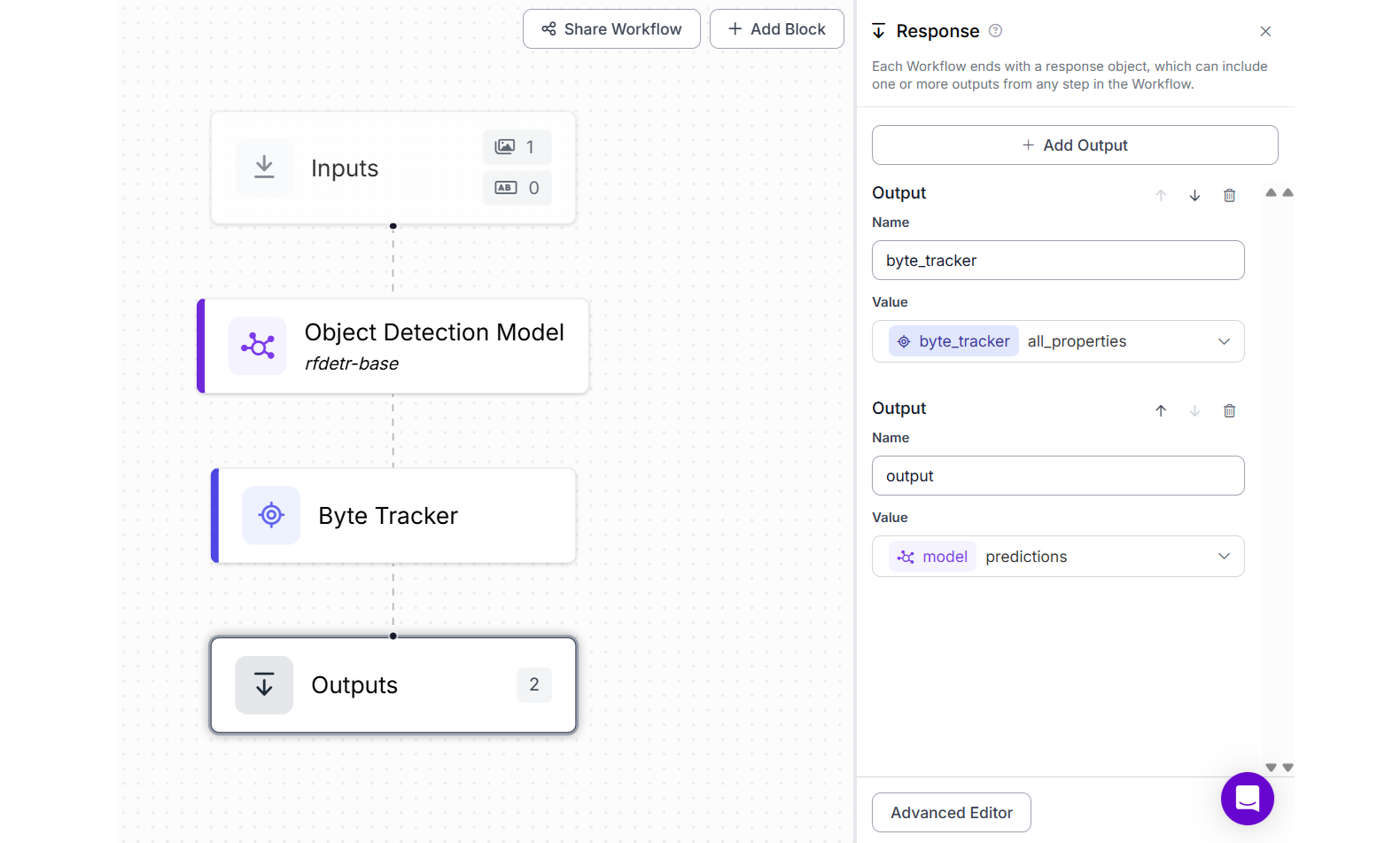
This Workflow combines an Object Detection Model (rf-detr-base) and a ByteTrack block. The detection model identifies objects (like people, dogs, etc.) in each video frame, while ByteTrack assigns a unique ID to each object and follows it across frames.
This setup is essential for object counting, as it ensures that an object is counted only once no matter how long it appears in the video. The workflow outputs both the raw predictions and the tracking information, making it ready for use in cumulative counting applications.
Now deploy the Roboflow Workflow with following script.
from inference import InferencePipeline
import supervision as sv
import cv2
import numpy as np
from collections import defaultdict
# === Output video config ===
output_path = "output_object_counting.mp4"
video_writer = None
output_fps = 30
output_size = None
# Object ID and count state
id_registry = {} # (class_name, tracker_id) -> object_number
next_object_number = defaultdict(int) # class_name -> next id (starting from 1)
total_class_counts = defaultdict(int) # class_name -> total seen ever
# Annotators
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
def my_sink(result, video_frame):
global video_writer, output_size
frame = video_frame.image
tracked = result["byte_tracker"]["tracked_detections"]
# Data extraction
xyxy = tracked.xyxy
class_names = tracked.data["class_name"]
tracker_ids = tracked.tracker_id
confidences = tracked.confidence
labels = []
per_frame_counter = defaultdict(int)
# Assign IDs and prepare labels
for i, (cls_name, trk_id, conf) in enumerate(zip(class_names, tracker_ids, confidences)):
key = (cls_name, int(trk_id))
if key not in id_registry:
next_object_number[cls_name] += 1
id_registry[key] = next_object_number[cls_name]
total_class_counts[cls_name] += 1
obj_number = id_registry[key]
per_frame_counter[cls_name] += 1
labels.append(f"{cls_name} #{obj_number} ({conf:.2f})")
# Build supervision Detections object
detections = sv.Detections(
xyxy=xyxy,
confidence=confidences,
class_id=np.zeros(len(xyxy), dtype=int),
tracker_id=tracker_ids
)
# Annotate with supervision
annotated = box_annotator.annotate(scene=frame.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
# Draw global count summary (cumulative)
y0 = 30
for i, (cls, cnt) in enumerate(total_class_counts.items()):
text = f"{cls} Total: {cnt}"
cv2.putText(
annotated, text,
(10, y0 + i * 30),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 255), 2, cv2.LINE_AA
)
# Init video writer
if video_writer is None:
h, w = annotated.shape[:2]
output_size = (w, h)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, output_fps, output_size)
# Show + save frame
cv2.imshow("annotated", annotated)
cv2.waitKey(1)
# if running on google colab, use cv2_imshow
# from google.colab.patches import cv2_imshow
# cv2_imshow(annotated)
video_writer.write(annotated)
# Roboflow inference pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-video",
video_reference="/content/people-walking.mp4",
max_fps=30,
on_prediction=my_sink
)
pipeline.start()
pipeline.join()
# Final cleanup
if video_writer:
video_writer.release()
cv2.destroyAllWindows()How it works: The Python code sends each video frame to the workflow, receives back the object detections and their unique tracking IDs, and then overlays bounding boxes and labels (like "person #2") using the supervision library.
It keeps a cumulative count of each unique object by checking if its ID has been seen before. The result is a video that visually shows each detected object, its assigned number, and the total number of unique objects detected so far, making it ideal for accurate object counting over time.
Running this workflow on following video:
People Walking Input Video
You will see output similar to following which will display object counting on the top left of the video, along with bounding boxes and object number annotations for each detected video.
Object counting output
Example #3: Object Counting in a Zone with Video
In this example we will learn how to count people entering in a particular area only, in a video stream. We will utilize the same Roboflow Workflow from our Example #2. Once you create the Roboflow Workflow, deploy it with the following code.
from inference import InferencePipeline
import supervision as sv
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
from collections import defaultdict
# Output config
output_path = "output_zone_count_filtered.mp4"
video_writer = None
output_fps = 30
output_size = None
# Tracking state
id_registry = {}
next_object_number = defaultdict(int)
total_class_counts = defaultdict(int)
# Target class
TARGET_CLASS = "person"
# Zone polygon
polygon = np.array([[604, 876], [1313, 864], [1235, 535], [670, 544]])
zone = sv.PolygonZone(polygon=polygon)
# Manual polygon drawer (removes supervision’s default center ID)
def draw_polygon(scene, polygon, color=(255, 255, 255), thickness=2):
points = polygon.reshape((-1, 1, 2)).astype(int)
return cv2.polylines(scene, [points], isClosed=True, color=color, thickness=thickness)
# Annotators
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_scale=0.5, text_thickness=1)
def my_sink(result, video_frame):
global video_writer, output_size
frame = video_frame.image
tracked = result["byte_tracker"]["tracked_detections"]
xyxy = tracked.xyxy
class_names = tracked.data["class_name"]
tracker_ids = tracked.tracker_id
confidences = tracked.confidence
# Supervision detections
detections = sv.Detections(
xyxy=xyxy,
confidence=confidences,
class_id=np.zeros(len(xyxy), dtype=int),
tracker_id=tracker_ids
)
# Filter: by zone
in_zone_mask = zone.trigger(detections)
detections = detections[in_zone_mask]
filtered_class_names = class_names[in_zone_mask]
filtered_tracker_ids = tracker_ids[in_zone_mask]
filtered_confidences = confidences[in_zone_mask]
# Filter: by target class
final_mask = np.array([cls == TARGET_CLASS for cls in filtered_class_names])
detections = detections[final_mask]
filtered_class_names = filtered_class_names[final_mask]
filtered_tracker_ids = filtered_tracker_ids[final_mask]
filtered_confidences = filtered_confidences[final_mask]
# Tracking logic
current_ids_in_zone = set()
labels = []
for cls_name, trk_id, conf in zip(filtered_class_names, filtered_tracker_ids, filtered_confidences):
key = (cls_name, int(trk_id))
current_ids_in_zone.add(key)
if key not in id_registry:
next_object_number[cls_name] += 1
id_registry[key] = next_object_number[cls_name]
total_class_counts[cls_name] += 1 # Cumulative count
obj_number = id_registry[key]
labels.append(f"{cls_name} #{obj_number} ({conf:.2f})")
# Annotate frame
annotated = box_annotator.annotate(scene=frame.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
annotated = draw_polygon(annotated, polygon)
# Draw text on frame
cv2.putText(
annotated,
f"Total {TARGET_CLASS}(s) in Zone: {total_class_counts.get(TARGET_CLASS, 0)}",
(20, 120),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 255),
2,
cv2.LINE_AA
)
cv2.putText(
annotated,
f"{TARGET_CLASS}(s) currently in Zone: {len(current_ids_in_zone)}",
(20,150),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 255),
2,
cv2.LINE_AA
)
# Video output
if video_writer is None:
h, w = annotated.shape[:2]
output_size = (w, h)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, output_fps, (w, h))
cv2_imshow(annotated)
video_writer.write(annotated)
# Start pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-video",
video_reference="/content/people-walking.mp4",
max_fps=30,
on_prediction=my_sink
)
pipeline.start()
pipeline.join()
if video_writer:
video_writer.release()
cv2.destroyAllWindows()How it works: This code is an advanced implementation for counting specific objects (like "person") in a defined zone within a video. The zone polygon was created using the PolygonZone tool and imported into the script as coordinates.
The code uses a Roboflow workflow that includes an object detection model (rf-detr-base) followed by ByteTrack to assign unique IDs to detected objects. These IDs help in tracking each object across frames to avoid double-counting. The script filters detections based on two conditions: whether they are inside the polygonal zone and whether they belong to the target class (in this case, "person"). The Supervision library handles drawing bounding boxes and labels on the video frames, while OpenCV is used for additional annotations like drawing the polygon and text on the frame.
Once a frame is processed, the code checks for objects currently inside the zone and maintains a cumulative count using their tracking IDs. If an object with a new tracker ID enters the zone for the first time, it's added to a registry and counted toward the total.
The script updates and displays two key metrics on each frame: the total number of unique "persons" that have ever entered the zone, and the number of "persons" currently present inside it. These are drawn directly on top of the video frame. Finally, the annotated frames are saved into a new video file, giving a full visual report of zone-based counting. This kind of tracking and zone-aware analysis is especially useful in real-world scenarios like people monitoring, retail analytics, or smart surveillance.
Running the above script on same "people walking" video will generate output similar to following.
Object counting in zone output
Example #4: Object Counting in a Live Camera Feed
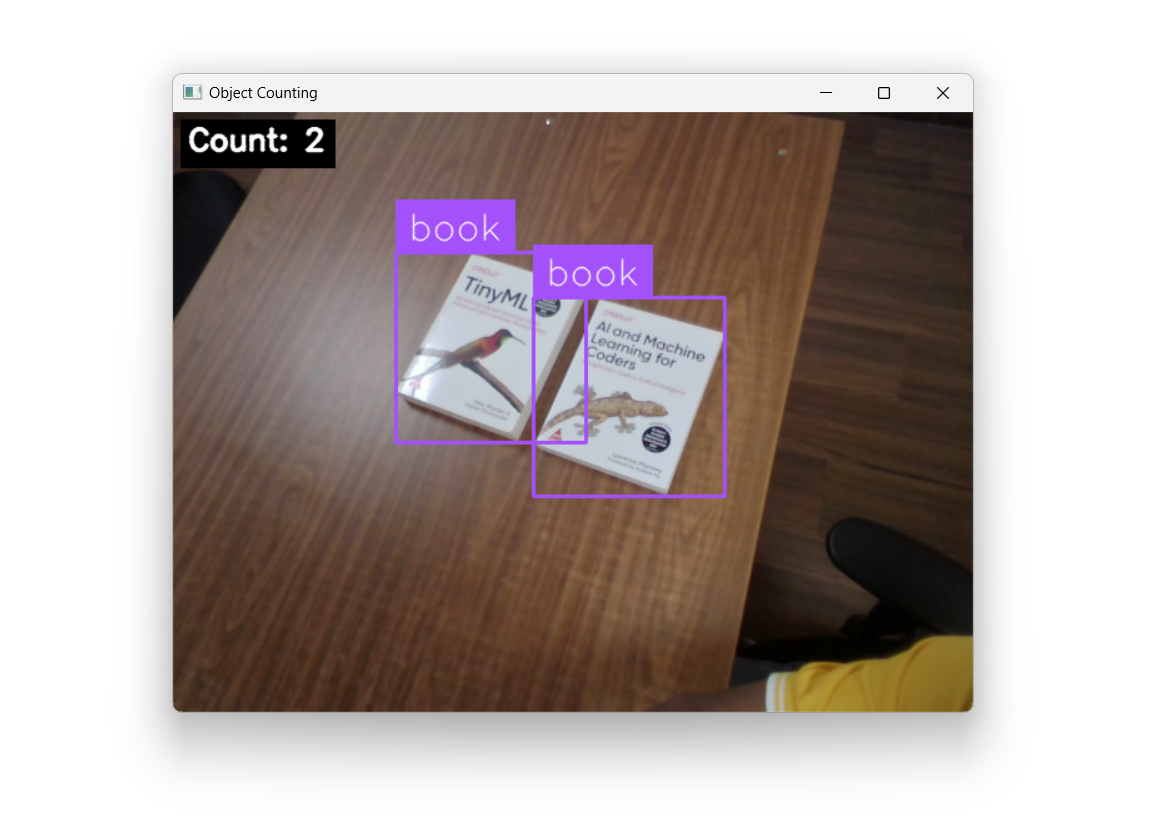
In this example, we count a specific object type (i.e. book in our example), filtered by class, directly from a live camera feed. Since we’re only interested in the number of detected objects in the current frame, there’s no need for tracking, the count resets every frame. This works much like counting objects in a still image, but repeated in real time.
Think of it like the farmer example from the introduction, the farmer points the camera at an apple tree, and the system instantly counts how many apples are currently visible.
To make this possible, we build a Roboflow Workflow with the following blocks:
- Object Detection Block detects objects using the RF-DETR model. For this block set
Class Filterproperty tobook. - Bounding Box Visualization Block draws bounding boxes around detected objects.
- Label Visualization Block overlays class labels on each detection.
- Property Definition Block automatically counts the detected instances of the object.
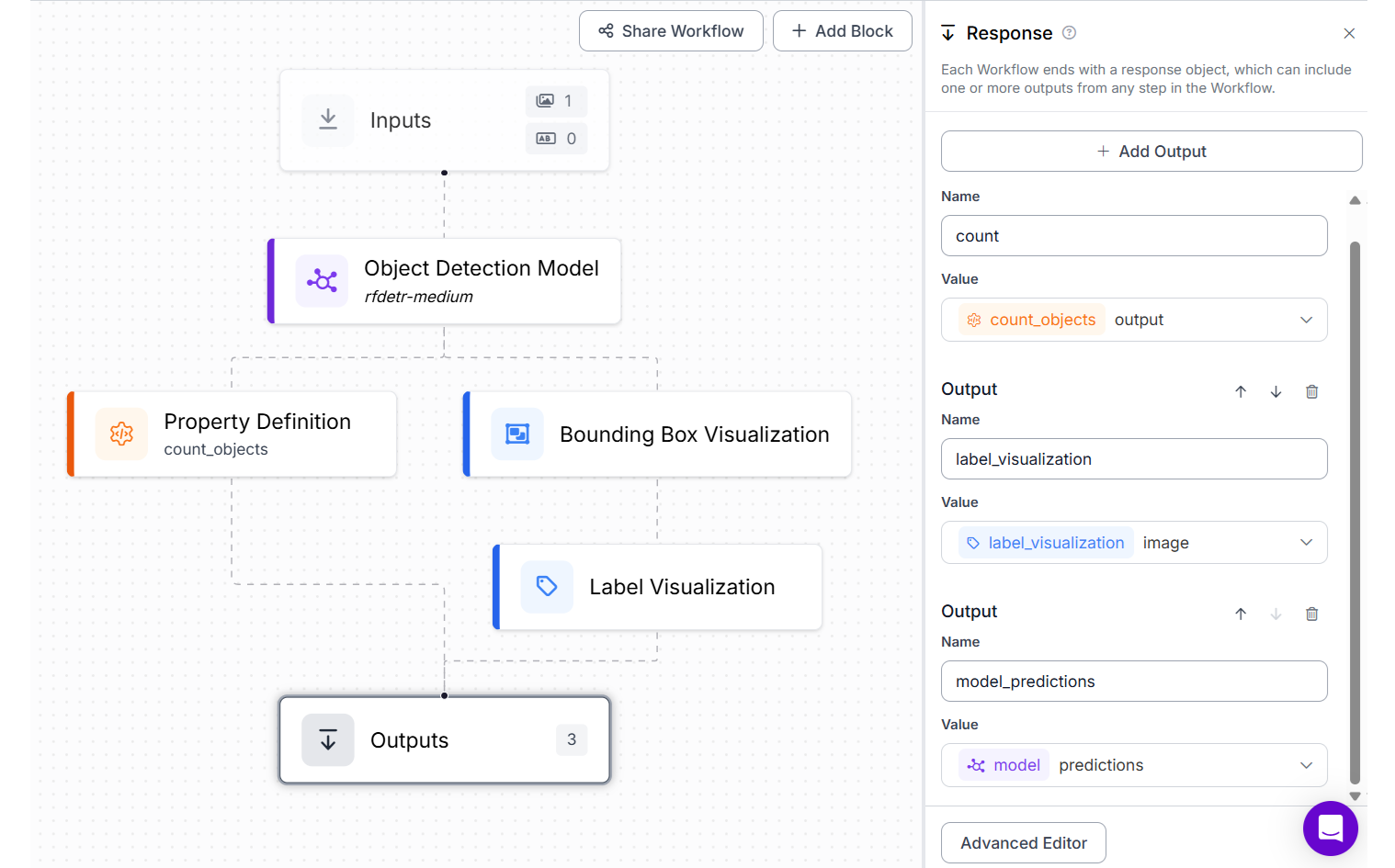
Use the following code to deploy this Roboflow Workflow.
from inference import InferencePipeline
import cv2
def my_sink(result, video_frame):
# Start from the visualization image
frame = result["label_visualization"].numpy_image.copy()
# Read count safely
count = int(result.get("count", 0))
text = f"Count: {count}"
# Text styling
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.8
thickness = 2
margin = 12
# Compute background box for readability
(text_w, text_h), baseline = cv2.getTextSize(text, font, font_scale, thickness)
x, y = margin, margin + text_h
# Draw filled background rectangle (black) then white text
cv2.rectangle(
frame,
(x - 6, y - text_h - 6),
(x + text_w + 6, y + baseline + 6),
(0, 0, 0),
-1
)
cv2.putText(frame, text, (x, y), font, font_scale, (255, 255, 255), thickness, cv2.LINE_AA)
# Show the frame
cv2.imshow("Object Counting", frame)
cv2.waitKey(1)
# initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="YOUR_API_KEY",
workspace_name="tim-4ijf0",
workflow_id="object-counting-camera",
video_reference=0,
max_fps=30,
on_prediction=my_sink
)
pipeline.start()
pipeline.join()
This code connects to the live camera feed and uses the prebuilt Roboflow Workflow to detect and count objects in real time. For each frame:
- The workflow’s label visualization output is used as the base image.
- The count property from the workflow is read (number of detected objects in the current frame).
- The count is drawn at the top-left corner on a black rectangle for readability.
- The processed frame is displayed live in a window.
- The
InferencePipelinecontinuously runs this process until stopped, ensuring you always see the live count of objects currently in the frame.
When you run the Workflow, you should see output similar to the following.
Using RF-DETR for Object Counting
RF‑DETR is a transformer‑based object detection architecture, specially designed to balance high accuracy and real‑time inference, making it exceptionally suitable for object counting applications.
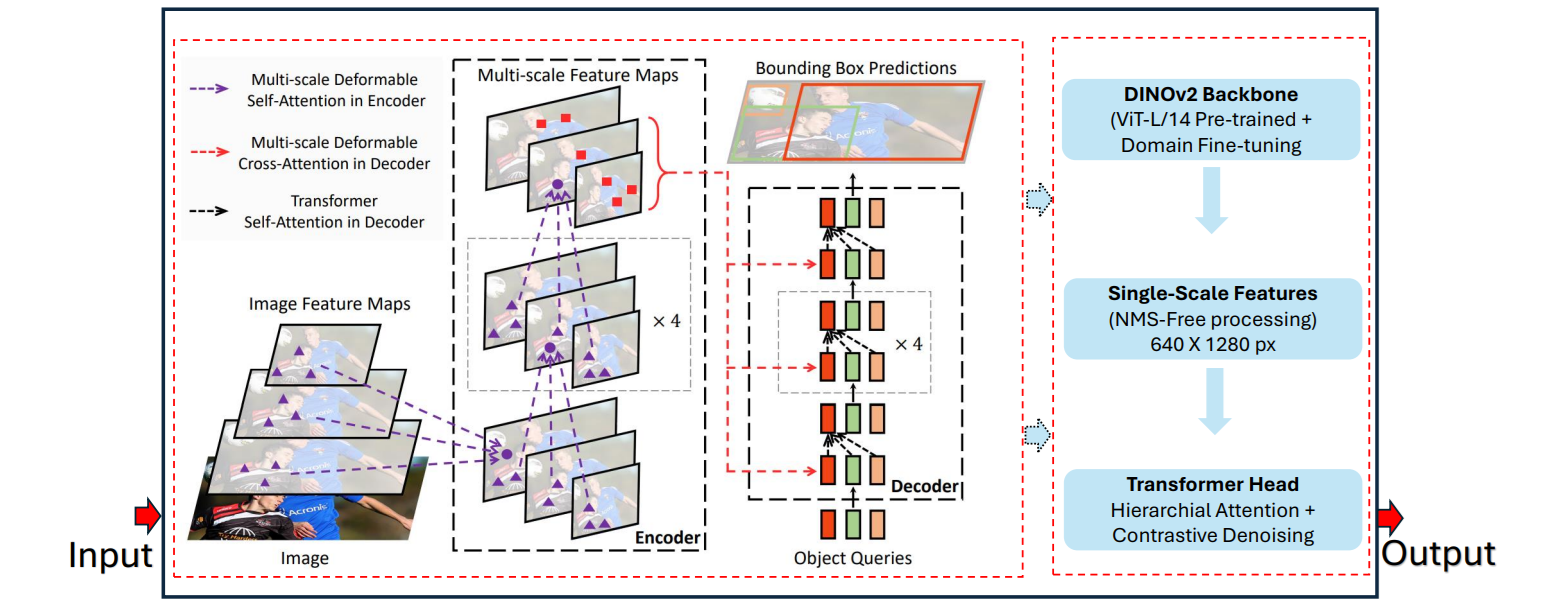
RF‑DETR is the first real‑time object detector to surpass 60 mAP on the MS‑COCO benchmark while running at ~25 FPS on an NVIDIA T4, setting a new standard for accuracy-speed tradeoffs in detection.
Built on deformable transformer architecture and using global self-attention, RF‑DETR excels at handling overlapping or partially obscured objects (“set prediction” without reliance on anchor boxes or NMS).
For example, in agricultural fruit-counting scenarios with heavy occlusion, RF‑DETR achieved an mAP@50 of 0.9464, outperforming in distinguishing occluded vs. visible fruits. See the following results:

Similarly, research shows that in multi-class detection, RF-DETR achieved a leading mAP@50 of 0.8298, showcasing its strong ability to differentiate between occluded and non-occluded fruits.
Object Counting Use Cases with Computer Vision
Object counting with computer vision streamlines operations, reduces manual work, and improves accuracy across industries. Here are just a few examples:
- Manufacturing: Count components on conveyor belts, detect defects in real time, and verify packaging to keep production lines fast and error-free.
- Healthcare: Automate cell counting in diagnostics, track surgical instruments, and verify medication doses to improve safety and efficiency.
- Warehousing: Track pallets and boxes, verify order accuracy during packing, and maintain real-time inventory visibility without manual stock checks.
- Agriculture: Estimate crop yields by counting fruits or plants, monitor livestock populations, and detect early signs of pest infestations.
How to Count Objects Automatically with Computer Vision
Object counting may seem like a simple task, but when powered by computer vision, it becomes a transformative tool across industries, from tracking production lines to monitoring patients or estimating crop yields. With the help of robust models such as RF-DETR, building accurate and scalable counting systems is now more accessible than ever. Try it today with a free Roboflow account.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Aug 8, 2025). Object Counting with Computer Vision. Roboflow Blog: https://blog.roboflow.com/object-counting/