
Parsing resumes saves employers time and reduces the manual effort required to learn relevant information about a candidate (i.e. the years of experience a candidate has, their previous employers, and other pertinent information).
However, traditional Optical Character Recognition (OCR) methods often face challenges with accurately recognizing text from two-column resumes, a format that is increasingly popular.
In this blog post, we'll show how computer vision and YOLOv5 can be used to efficiently segment two-column resumes, improving OCR accuracy.
Resume OCR: Understanding the Challenge - Extracting Text from Resumes
The main challenge of this task is the presence of multiple columns in resumes, which can make it difficult for traditional Optical Character Recognition (OCR) techniques to accurately extract text.
In recent years, computer vision techniques have been proposed as a solution to this problem. However, most of these methods are based on rule-based approaches and are thus not flexible enough to handle the variability of real-world resumes.
Our approach is based on deep learning techniques, using a neural network to identify different features. In our testing, we have found our approach to accurately segment two-column resumes, regardless of their layout and formatting.
To build a solution to the problem, we collected and annotated a dataset of 3,541 two-column-resume images, trained and evaluated a YOLOv5 model for the task of segmenting resumes into five parts. The results of our experiments show that our approach outperforms existing methods in terms of accuracy and reliability.
Step 1: Collect the Data
First, we needed to collect a dataset of two-column resumes. This dataset will be used to train a computer vision model to perform two-column resume segmentation. In our case, we collected 1,000 two-column resume images using web scraping techniques.
Next, we used Roboflow, an end-to-end platform for computer vision, to label our dataset. Roboflow provides tools to help us label our images quickly and accurately.
Step 2: Label the Data
Next, we need to label the data so that it can be used to train the computer vision model.
One effective way to label the data is using the Roboflow platform. Roboflow Annotate allows you to upload your images and label them using a graphical user interface. The platform also provides a variety of tools to make the labeling process more efficient, such as automated annotation tools and pre-defined label categories.
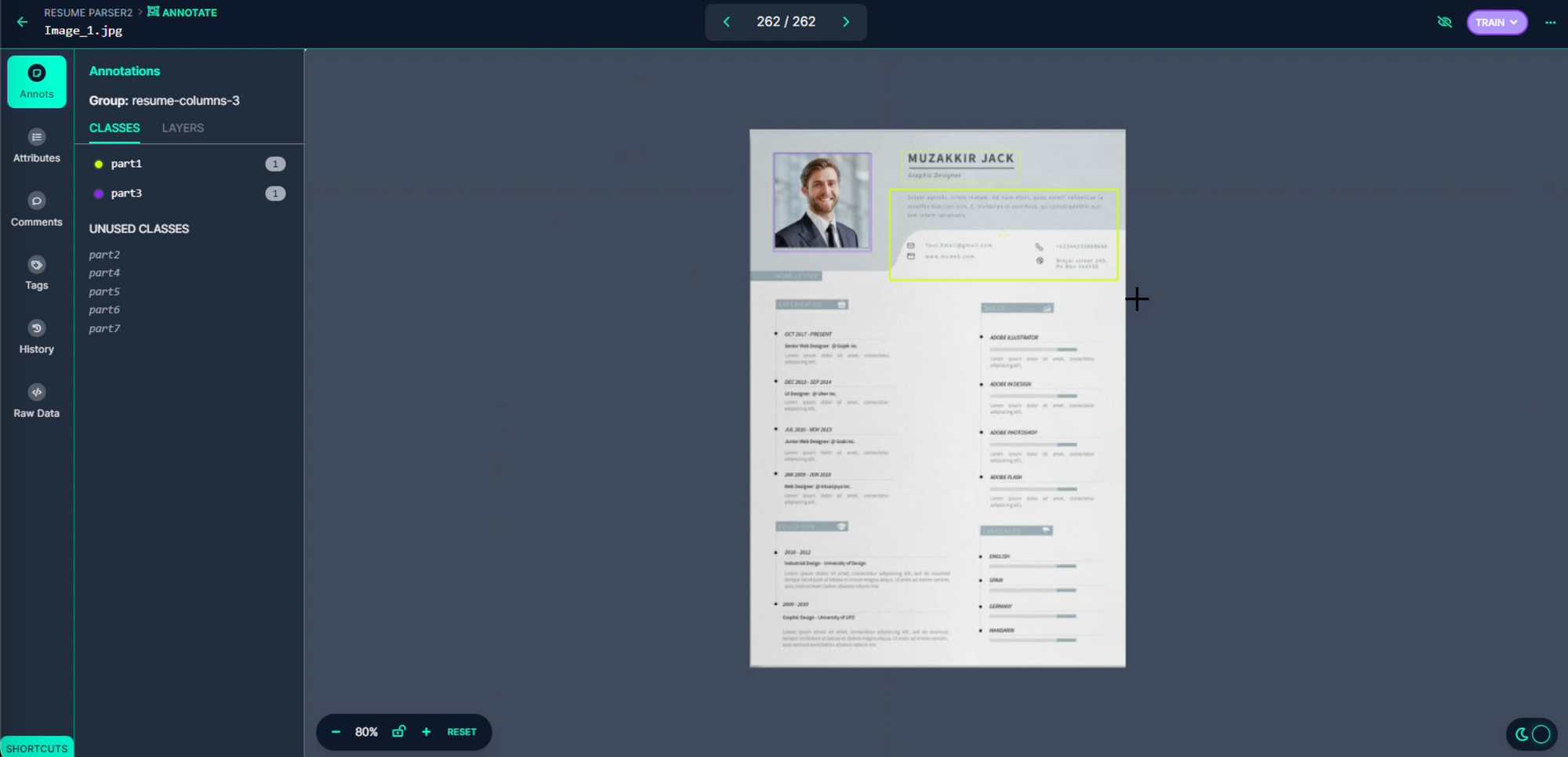
Different columns and resume sections were given their own bounding boxes.
Step 3: Apply Preprocessing and Augmentation Steps
Once we had our labeled dataset, the next step was to add augmented images using a suite of data augmentation techniques, such as flipping, rotation, and color jittering. This lets us increase the size of our dataset and make it more diverse, thus helping the model learn how to identify different features in an image.
In addition to data augmentation, Roboflow provides image preprocessing techniques, such as resizing, normalization, and cropping. We used these techniques to ensure that our images were in a standard format, ready for use in training.
After completing the labeling process and applying our desired preprocessing and augmentation, we could generate a dataset in a format compatible with popular computer vision frameworks, such as TensorFlow and PyTorch.
Step 3: Train the Model
Once the labeled dataset was generated, we trained a computer vision model. In this case, YOLOv5 is used as the computer vision model.
The Roboflow platform provides a number of tools to help with the training process, such as a pre-trained model based on the Microsoft COCO dataset that can be fine-tuned to your specific dataset as well as tools for visualizing the training process and evaluating the model's performance.
Once the training process is complete, the model will be able to accurately segment two-column resumes into their individual columns.
Step 4: Testing Model Deployment
The following video demo shows our model in action:
Now that we know our model performs as expected, the final step is to deploy the model in a way that makes it accessible to others.
Roboflow Deploy provides a number of tools to make this process easy, such as a pre-built API that can be used to integrate the model into other applications and a web-based demo that allows users to test the model directly from their browser.
Additionally, Roboflow provides a number of tools for monitoring the performance of the deployed model, including performance metrics such as precision, recall, and mean average precision (mAP).
With this deployment, we achieved a mAP of 73.1%, precision of 86.7%, and recall of 69.9%, demonstrating the effectiveness of using computer vision and YOLOv5 for two-column resume segmentation, and demonstrated that our approach outperforms existing methods in terms of accuracy and reliability.
Now that we have the two separate columns, we can run OCR on each one without having to worry about data being malformed as a result of the OCR model failing to understand the two-column format.
Resume OCR
In this blog post, we have demonstrated that by leveraging the power of computer vision and deep learning, we can overcome the challenges posed by two-column resumes and extract relevant information from candidate resumes with greater ease and efficiency.
This post was contributed by Ons Abderrahim
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Mar 29, 2023). Resume OCR: How to Use YOLOv5 for Automated Resume Parsing. Roboflow Blog: https://blog.roboflow.com/resume-parsing-computer-vision/