
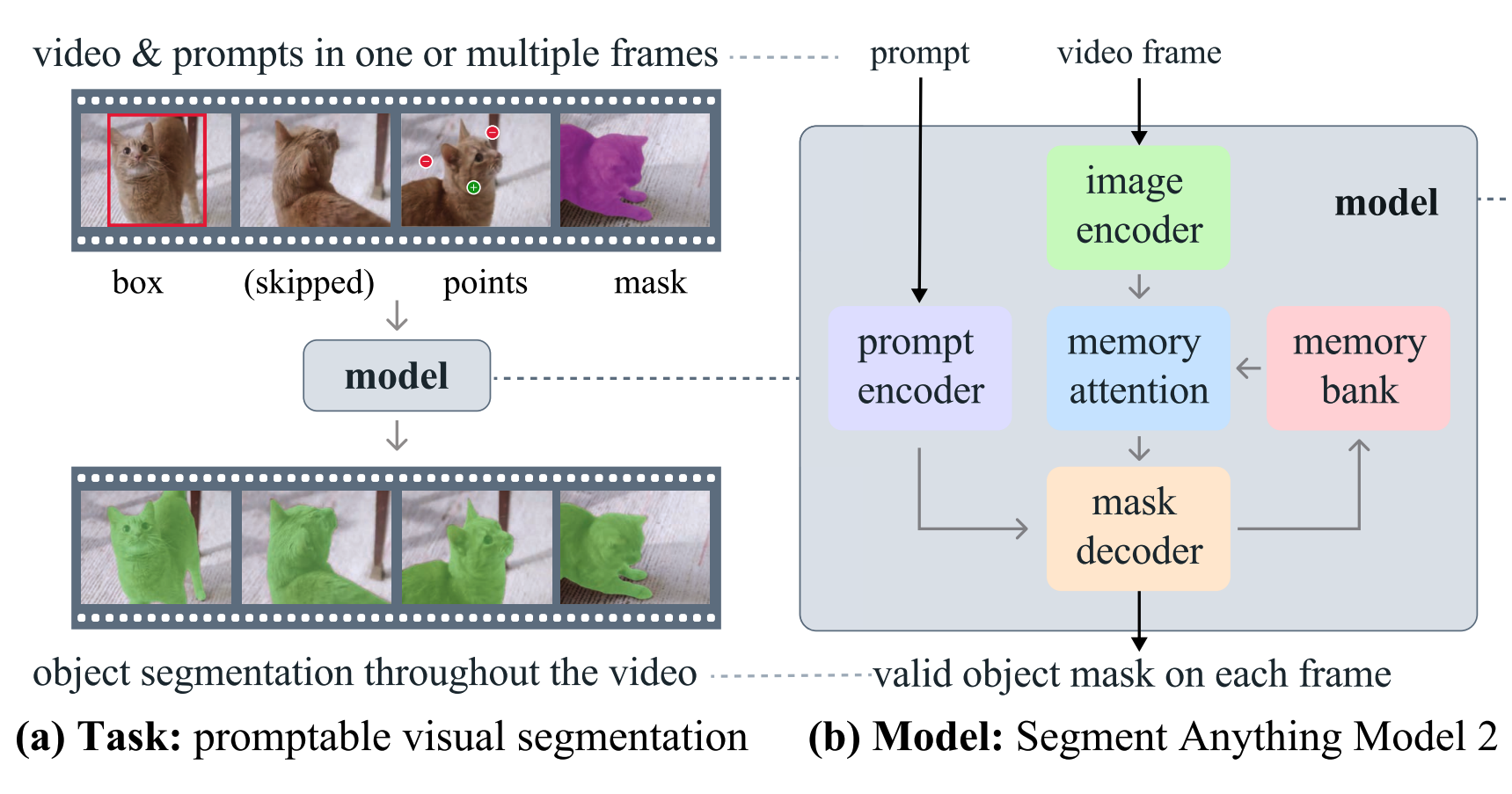
Segment Anything Model 2 (SAM 2) is a unified video and image segmentation model.
Video segmentation presents unique challenges compared to image segmentation. Object motion, deformation, occlusion, lighting changes, and other factors can vary dramatically from frame to frame. Videos are often lower quality than images due to camera motion, blur, and lower resolution, further increasing the difficulty.
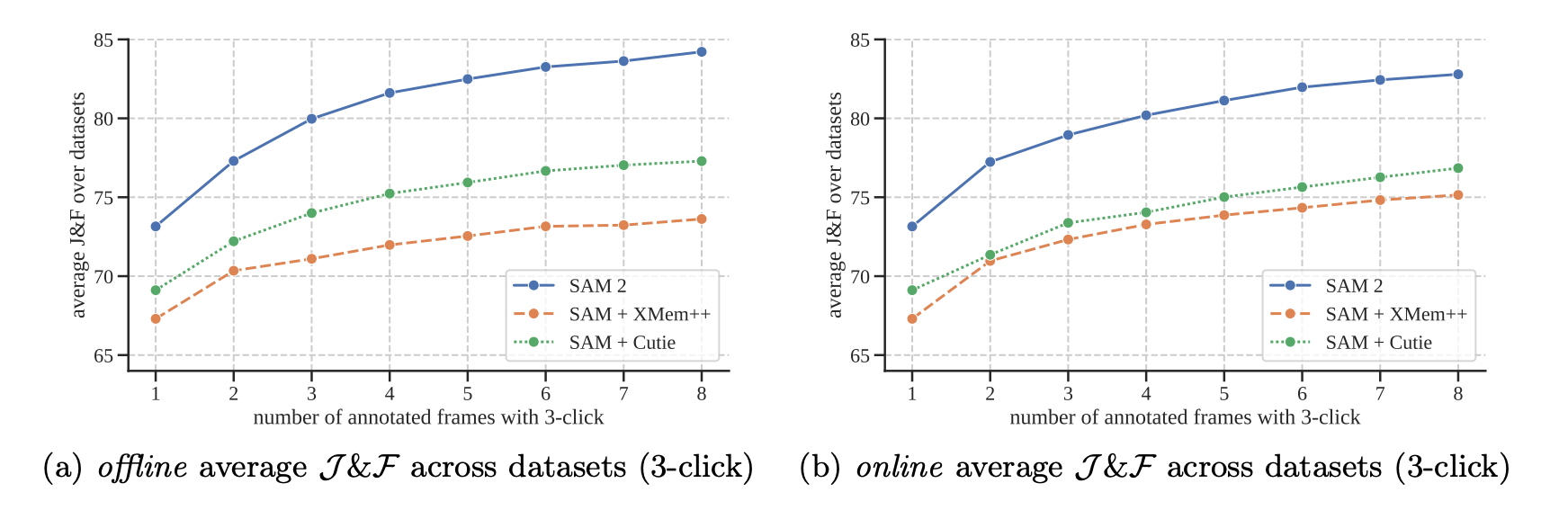
SAM 2 demonstrates improved accuracy in video segmentation, with 3 times fewer interactions than previous approaches. SAM 2 is more accurate for image segmentation and 6 times faster than the original Segment Anything Model (SAM).
You might also be interested in using the newer Segment Anything 3 - a zero-shot image segmentation model that detects, segments, and tracks objects in images and videos based on concept prompts.
Load SAM 2 Model for Video Processing
First, clone the repository and install the required dependencies using the following commands:
git clone https://github.com/facebookresearch/segment-anything-2.git
cd segment-anything-2
pip install -e .
python setup.py build_ext --inplace
Due to a bug in the segment-anything-2 codebase, after installation, you need to run the command python setup.py build_ext --inplace.
In this project, we will also utilize the Supervision package, which will assist us in visualizing SAM 2 results, among other tasks.
pip install supervisionSAM 2 is available in 4 different model sizes, ranging from the lightweight "sam2_hiera_tiny" (38.9M parameters) to the more powerful "sam2_hiera_large" (224.4M parameters). These models also differ in inference speed.
The smallest model processes approximately 47 frames per second, while the largest processes around 30. These values were obtained on an NVIDIA A100, using PyTorch 2.3.1 and CUDA 12.1 under automatic mix precision with bfloat16. The image encoder was compiled using torch.compile.
For this demo, we will utilize the largest model. Links to the weights for other model sizes can be found in the README.md file of the repository. We can download the model weights as follows.
wget -q https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.ptFor image use cases, we load SAM 2 usingbuild_sam2, while for videos, we use build_sam2_video_predictor. This is because video processing utilizes model memory, which is not initialized when processing single images. More on model memory later in this article.
To load the model, we need the path to the previously downloaded weights file and the name of the YAML configuration file. Configuration files for each model size can also be found in the repository.
import torch
from sam2.build_sam import build_sam2_video_predictor
CHECKPOINT = "checkpoints/sam2_hiera_large.pt"
CONFIG = "sam2_hiera_l.yaml"
sam2_model = build_sam2_video_predictor(CONFIG, CHECKPOINT)SAM 2 Data Preprocessing
SAM 2 is equipped with memory that stores information about the object and previous interactions, allowing it to generate mask predictions throughout the video and effectively correct them based on the stored object context from previously observed frames.
Before starting segmentation, SAM 2 needs to know the content of all frames. For this purpose, the frames must be saved to disk. It is crucial to save the frames in JPEG format, as this is currently the only supported format. Since all these frames will be loaded into VRAM in the next step, depending on the resolution of your video, it may be necessary to downscale the frames before saving them to disk. We can accomplish all of this using the supervision package.
import supervision as sv
frames_generator = sv.get_video_frames_generator(<SOURCE_VIDEO_PATH>)
sink = sv.ImageSink(
target_dir_path=<VIDEO_FRAMES_DIRECTORY_PATH>,
image_name_pattern="{:05d}.jpeg")
with sink:
for frame in frames_generator:
sink.save_image(frame)
Initialize the Inference State for SAM 2
SAM 2 requires stateful inference for interactive video segmentation, so we need to initialize an inference state on this video. During initialization, it loads all the JPEG frames in video_path and stores their pixels in inference_state.
inference_state = sam2_model.init_state(<VIDEO_FRAMES_DIRECTORY_PATH>)If you have run any previous tracking using this inference_state, please reset it first via reset_state.
sam2_model.reset_state(inference_state)Segment and Track One Object with SAM 2
To get started, let's try to segment the ball in the first frame of the video. Label 1 indicates a positive click (to add a region), while label 0 indicates a negative click (to remove a region). When defining our prompt beyond points and labels, we also need to pass the frame index we interact with and give a unique ID to each object we interact with (it can be any integer).
import numpy as np
points = np.array([[703, 303]], dtype=np.float32)
labels = np.array([1])
frame_idx = 0
tracker_id = 1
_, object_ids, mask_logits = sam2_model.add_new_points(
inference_state=inference_state,
frame_idx=frame_idx,
obj_id=tracker_id,
points=points,
labels=labels,
)


Refine Predictions for SAM 2
Similar to SAM, SAM 2 allows for prompting the model with negative points - points that do not belong to the object. This enables a precise definition of the boundaries of the object of interest.
import numpy as np
points = np.array([
[703, 303],
[731, 256],
[713, 356],
[740, 297]
], dtype=np.float32)
labels = np.array([1, 0, 0, 0])
frame_idx = 0
tracker_id = 1
_, object_ids, mask_logits = sam2_model.add_new_points(
inference_state=inference_state,
frame_idx=frame_idx,
obj_id=tracker_id,
points=points,
labels=labels,
)

According to the Segment Anything 2 paper, the model's accuracy on video tasks increases with the number of labeled video frames. Don't be afraid to annotate several frames in different parts of the video. Make sure to use the appropriate frame_idx in the various add_new_points calls.
Propagate Prompts Across the Video
To apply our point prompts to all video frames, we use the propagate_in_video generator. Each call returns frame_idx (the index of the current frame), object_ids (IDs of objects detected in the frame), and mask_logits (corresponding object_ids logit values), which we can convert to masks using thresholding. We then read each frame, apply the masks to it using a MaskAnnotator, and finally, write the annotated frame to the output video.
import cv2
import supervision as sv
colors = ['#FF1493', '#00BFFF', '#FF6347', '#FFD700']
mask_annotator = sv.MaskAnnotator(
color=sv.ColorPalette.from_hex(colors),
color_lookup=sv.ColorLookup.TRACK)
video_info = sv.VideoInfo.from_video_path(<SOURCE_VIDEO_PATH>)
frames_paths = sorted(sv.list_files_with_extensions(
directory=<VIDEO_FRAMES_DIRECTORY_PATH>,
extensions=["jpeg"]))
with sv.VideoSink(<TARGET_VIDEO_PATH>, video_info=video_info) as sink:
for frame_idx, object_ids, mask_logits in sam2_model.propagate_in_video(inference_state):
frame = cv2.imread(frames_paths[frame_idx])
masks = (mask_logits > 0.0).cpu().numpy()
N, X, H, W = masks.shape
masks = masks.reshape(N * X, H, W)
detections = sv.Detections(
xyxy=sv.mask_to_xyxy(masks=masks),
mask=masks,
tracker_id=np.array(object_ids)
)
frame = mask_annotator.annotate(frame, detections)
sink.write_frame(frame)
Segment and Track Multiple Objects with SAM 2
SAM 2 can also segment and track two or more objects simultaneously. One way is to perform them individually. However, it would be more efficient to combine them so that we can share image features between objects to reduce computational costs. Each object should be assigned a different object ID.


Tracking Objects Across Multiple Videos with SAM 2
During our experiments, we discovered that SAM 2 can detect the same objects visible in shots from different cameras. In our experiment, we used two additional clips looking at the same basketball play. We performed labeling only on frames from one shot and inference on frames from all three clips.
Even though the model had not seen frames from other shots, SAM 2 was able to detect them almost perfectly in all three clips.
SAM 2 for Video Limitations
SAM 2 may struggle with segmenting objects across shot changes and can lose track of or confuse objects in crowded scenes, after long occlusions, or in long videos. It also faces challenges with accurately tracking objects that have very thin or fine details, especially when they are moving quickly.
Another difficult scenario occurs when there are objects with similar appearances nearby. While SAM 2 can track multiple objects in a video simultaneously, it processes each object separately, utilizing only shared embeddings per frame without inter-object communication.
Conclusions
Segment Anything Model 2 (SAM 2) is a significant advancement in image and video segmentation, offering a unified model with improved accuracy, speed, and context awareness.
While it faces limitations in certain scenarios, SAM 2 represents a powerful tool in the field of image and video segmentation with broad applications across various domains.
The release of the original SAM model sparked a wave of projects like HQ Sam, FastSAM, and MobileSAM, and I am excited about the research papers and models that will be published in the coming months as the community builds upon SAM 2's capabilities.
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Aug 1, 2024). How to Use SAM 2 for Video Segmentation. Roboflow Blog: https://blog.roboflow.com/sam-2-video-segmentation/