
It all started with a question: “What could we do to promote computer vision at SXSW?” When our team first pondered this, we never thought that within two weeks we would be sharing QR codes around the city of Austin, bringing the power of computer vision to hundreds of people’s hands.
Last week, in celebration of SXSW, Roboflow ran a competition to win $1,000, powered by computer vision. In the competition, players were invited to identify 25 objects using their phone. Objects ranged from common items such as cups to uncommon objects, such as tennis rackets (where would one find a tennis racket at SXSW?). For each five objects a player identified, they earned an entry into a contest to win the $1,000 prize. In total, 227 people played the game and identified one or more objects.
The competition ended at the end of Sunday, March 19th, 2023. The winner, who chose to remain anonymous, asked us to donate the $1,000 prize to Make a Wish. Inspired by the donation, several Roboflow employees made personal contributions to Make a Wish.
In this post, we are going to talk through our experience building a computer vision scavenger hunt and using it to power grassroots Marketing at a conference. We’ll touch on how we decided on the gameplay mechanics – leaderboards, anyone? – to what we learned about the limitations of the Microsoft COCO dataset. Curious? Let’s dive in!
The code accompanying this project is open-source. Check it out on GitHub.
Developing the Idea
Computer vision is a powerful technology, with the potential to improve efficiency, safety, and reliability across dozens of industries. Every day, we see how computer vision is used to solve business-critical problems. With that said, computer vision is a growing field; not everyone is using it, and we believe the technological advancements in the industry are not as well known as they should be. One can run a computer vision model in the browser on mobile now, for example.
SXSW is about pushing the boundaries of creativity, so we knew we had to think big. Together, we settled on a scavenger hunt powered by computer vision. The interface was to be simple: create an account, then use your phone to identify objects in the Microsoft COCO dataset.
We decided to use Microsoft COCO because the dataset had 80 classes of common objects, giving players plenty of things to identify. Going in, we knew there were significant limitations for using COCO. COCO is a research benchmark dataset, and thus was not optimized for our use case. In the interest of time, we opted to use COCO. We’ll talk more about our learnings later in this post.
We wanted as many people to play as possible, so we decided to offer a $1,000 prize.
Within hours, we had agreed to build the idea; team members committed to support with engineering, marketing, branding. The next step? To build the application.
Implementing the Technical Mechanics
For this application, we decided to use Node.js, Supabase, and roboflow.js (a wrapper around tensorflow.js that lets you use models trained on Roboflow in the browser). Node.js and Supabase were the ideal combination. Supabase provides an easy-to-use database with utility functions to handle authentication, with a robust Node.js SDK.
We had around two weeks to go from the idea to having a completed app for SXSW so being able to work quickly with intuitive developer tools like Node.js and Supabase was crucial.
Building for the web gave us a critical advantage: we could build once and make the game available on all platforms, saving our team time and bringing the app to more people.
With a tech stack settled, we started to build the app.
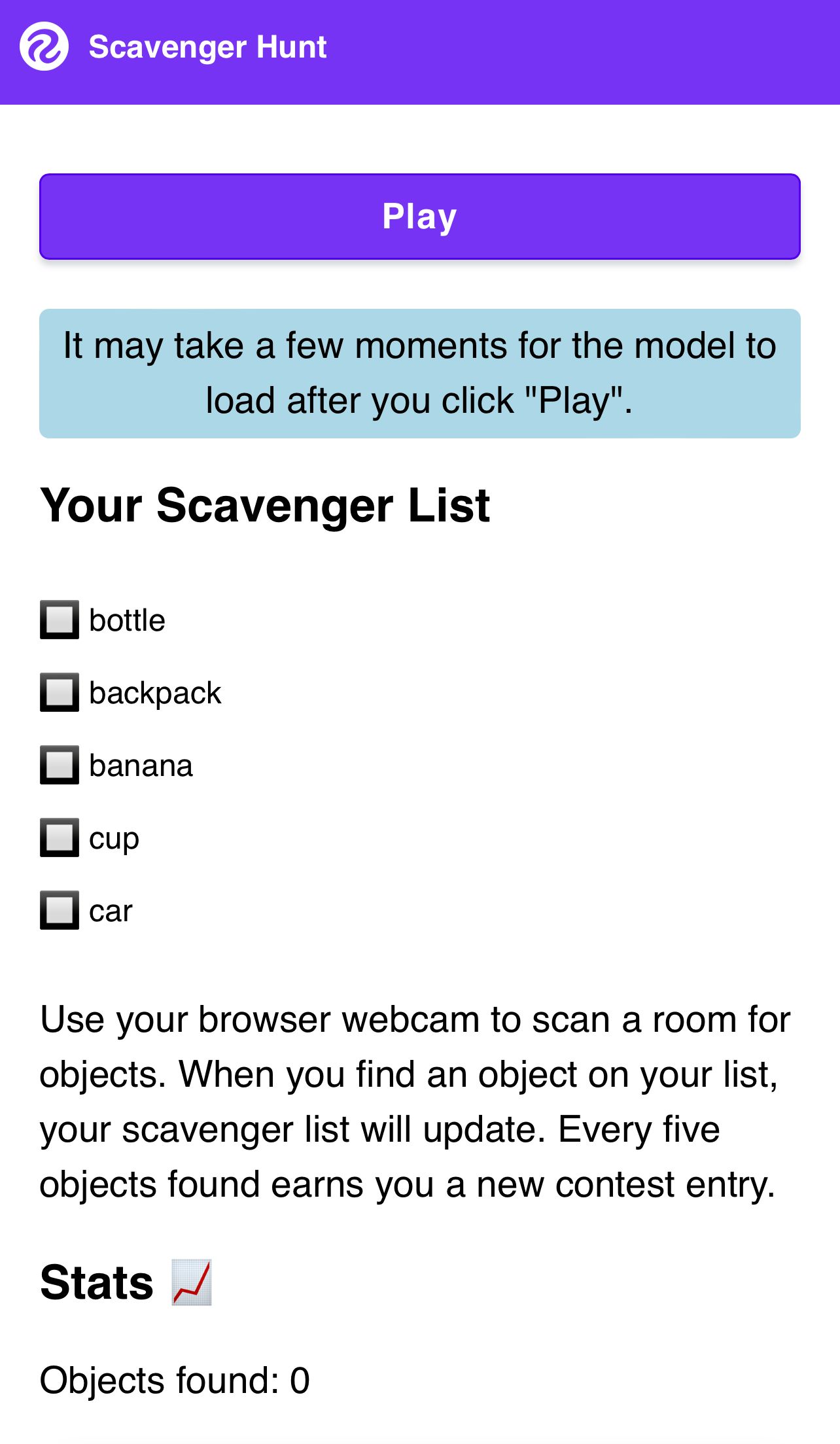
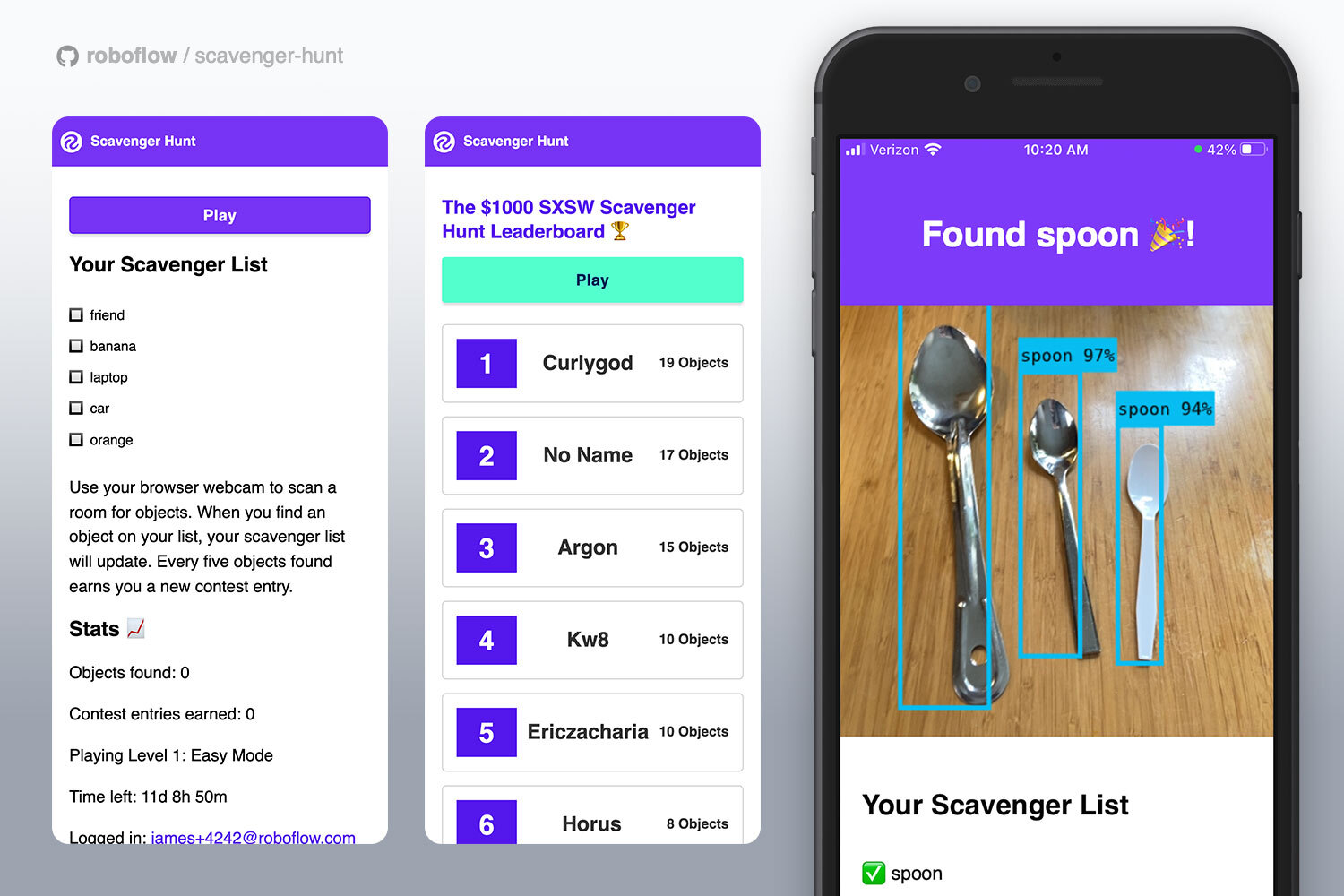
The main page of the application is the gameplay interface. When a user clicks “Play”, they are asked to grant camera access. We show a loading GIF to indicate the model is loading. At first, we loaded the model in the browser when the user clicked “Play”, but we found that experience confusing because it could take up to a minute for the model to load. We changed the page so that the model would load on page load, thus making the experience feel quicker.

The model is loaded fully in the browser so that inference can run at the highest frame rate possible. The video does not need to be streamed into the cloud, so players could interact with the game on potentially low-bandwidth conference WiFi without trouble. Because the webcam is displayed using the video element, it performs at a strong frame rate.
Here is how the app looks when it is running:
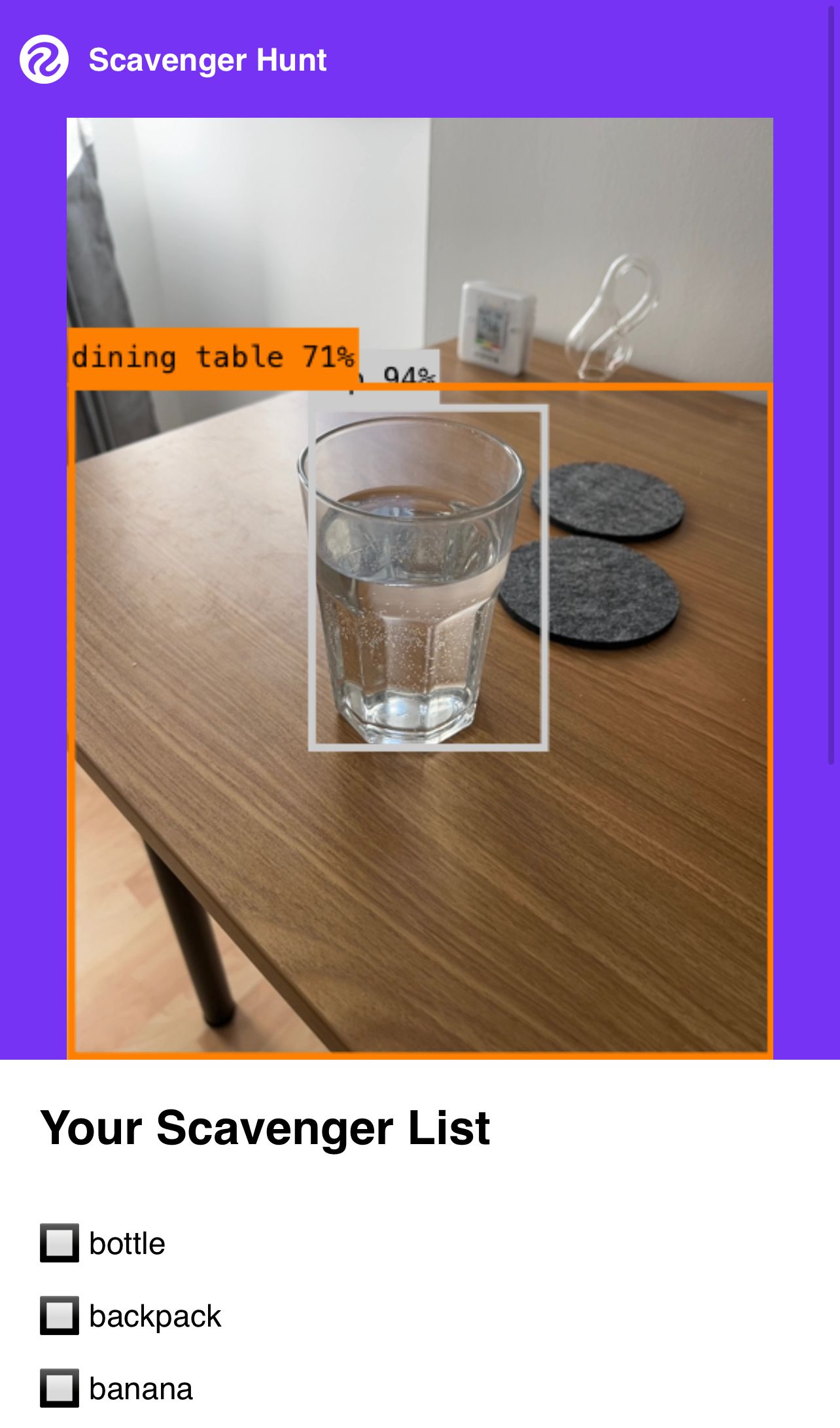
Out of the box, we rendered predictions as they were returned by our model and displayed them onto a canvas. This is the “raw” output of the computer vision model. With that said, rendering predictions in this way does not create the ideal user experience; predictions can sometimes disappear between frames.
To solve this problem, we wrote logic to ensure that predictions persisted between frames so as to ensure that if a prediction was missed in one frame (which happens with raw model outputs), the prediction would persist on the screen for a certain period of time. We created a buffer of predictions found in each frame. If an object appeared a certain number of times in the last 10 frames, the prediction would persist. This buffer was cleared regularly for performance reasons.
When the model and camera have loaded, two HTML elements are populated: a video, which shows the webcam streaming in real-time, and a canvas element, to which we paint all predictions. For each frame, we run inference using roboflow.js, and then show all the predictions on the canvas.
We use the requestAnimationFrame() function to get video frames, then run them through the model. This function lets us execute a callback when we want to repaint the video frame. In our callback function, we process prediction results and paint them on the canvas above the image. This lets us run inference at a speed determined by the browser, rather than setting an arbitrary number of milliseconds after which point inference begins again.
We first implemented inference using setTimeout(), but we noticed sluggish performance and our application would eventually run out of memory because we were trying to run inference too quickly.
Gameplay Mechanics and Assigning Objects
Below the gameplay interface, we show a scavenger hunt list, like this:

This list went through several iterations. At first, players would be given items to find one-by-one. We realized this may make the game more difficult and less fun. If a user gets “tennis racket” as their first item, they may stop playing.
After several discussions, we decided on a few changes.
First, we decided that players should be given items in batches of five. When a player signs up, they are given four items at random, as well as a class called “friend”. This class maps to “person” in COCO. Players need to identify all five objects in their batch before being given another five. Because items were assigned at random, there was no guarantee players would get exactly the same classes as their friend.
Second, we decided that we should divide the classes in COCO into three tiers: easy, medium, and hard. Players were assigned objects at random from the easy tier first, and progressively moved on to the harder tiers. We showed the level on which a user was playing on their account:

By now, you may be wondering: how did you decide on the classes used in the game? Did you use all of the classes in COCO? Let’s answer these questions.
Using COCO in Production
Earlier, we noted that we knew from the beginning there would be limitations with using a model trained on the Microsoft COCO dataset in our application. With that said, COCO was an appropriate choice for our use case. We were building an application quickly and we wanted to give users a lot of common objects to identify. What dataset contains a lot of common objects? Microsoft COCO.
During development and testing, we found two big issues. Our model trained on the COCO dataset:
- Struggled to identify a lot of objects, even with low confidence levels set and after scanning an object from different angles and;
- Commonly mis-identified objects (the lead developer, for instance, was identified as a “cat” when wearing a housecoat; we saw a lot of false positives for the “cat” class).
There are a few reasons why we believe we encountered these issues. We're capturing video frames from a cell phone camera. With that said, the COCO dataset is largely composed of traditional photographs composed by a photographer. Aspect ratio is likely different, too, since the underlying COCO dataset contains more landscape photos than portrait photos like one would take with a modern smartphone camera.
If players were given objects that the model could not identify, that would add significant friction and frustration to the gameplay process. We decided to manually go through the classes in COCO and remove any classes that did not reliably identify objects. Some classes are not identified reliably because they are: underrepresented in the dataset; the real-world instances are not similar to the ones on which the model was trained; the environment is different or; they look like another object, among other reasons.
This left us with 25 objects, pictured below:

By limiting the application to these 25 objects, we significantly reduced the likelihood a player would get an object that a YOLOv8 model trained using the COCO dataset could not easily identify. This helped reduce the problem, but in some cases you would need to scan an object from multiple angles to get a positive identification. One example of this was the “cell phone” class. The COCO model was trained on many photos of old cell phones, so sometimes the model doesn’t perform well on the class.
Mitigating the second issue was harder. To reduce the chance the model mis-identified objects, we used a high confidence level, which further reinforced the need to limit the objects on the scavenger hunt. If we used a high confidence level and an object could not be identified, that would again lead to a frustrating experience. There were still false positives, but changing this would require improving the underlying COCO dataset. That gave us an idea: how could we improve COCO? More on that later in the post.
Leaderboard Mechanics
From day one, we were curious about leaderboard dynamics in this application. We wanted people to play with friends and compete to get to the top. We decided to implement a leaderboard, accessible to all users, that showed how many objects each user had identified.
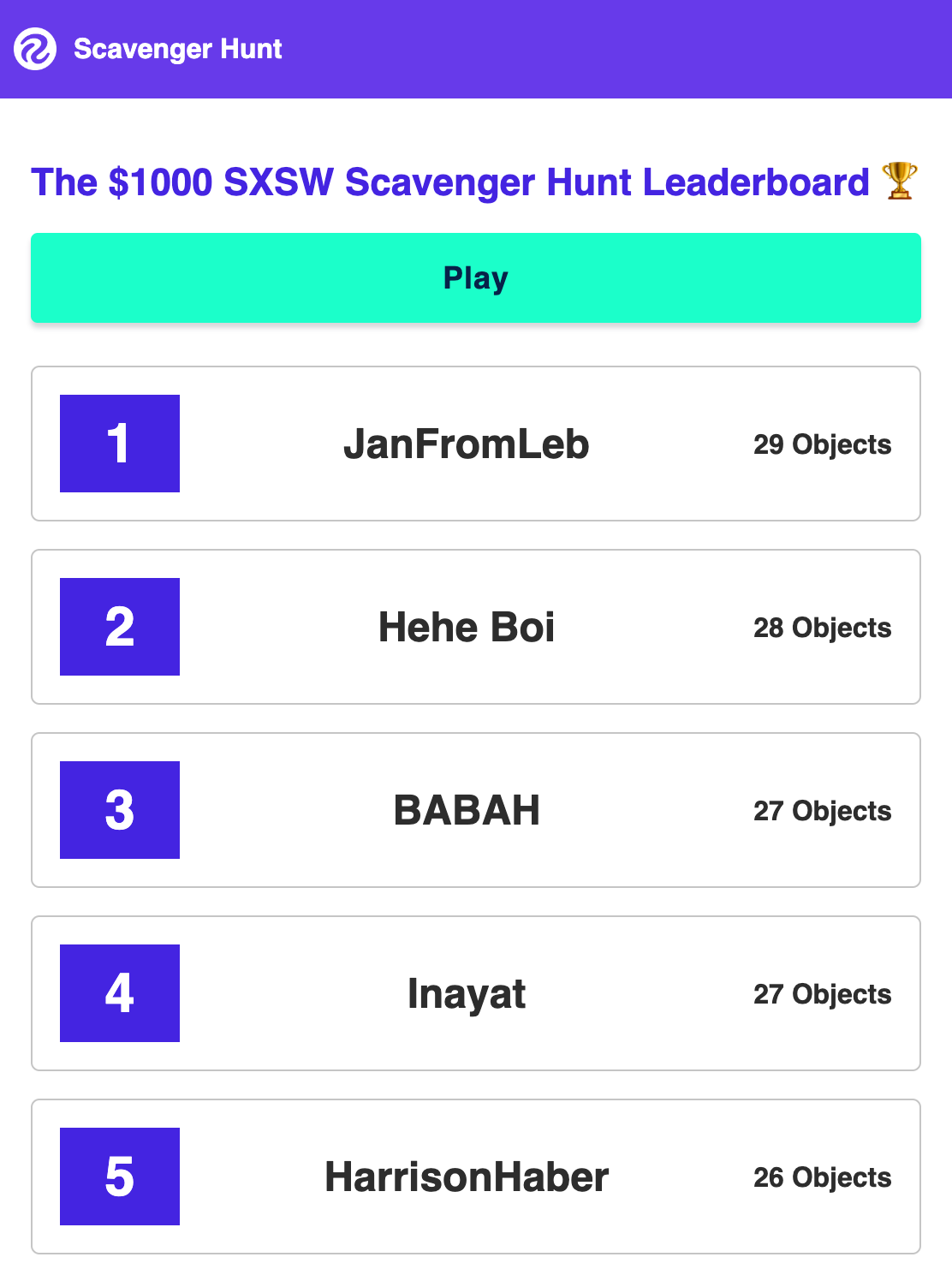
When a player identifies their first five objects, they are invited to set a username for their account. If set, the username will show up on a leaderboard; otherwise, “No Name” was set. Players were given an opportunity to set a username every five objects identified if one had not been set.
Within a few days, we noticed that there were people already getting close to the top of the leaderboard; people were claiming usernames to show off their position. We were inspired by old-school video games: set a username after you have completed a round or a game so that you can show to other players how well you did.
Reaching the top of the leaderboard did not mean you won the grand prize; it meant you had hit the maximum number of entries in the contest.
Some users identified between 26 and 29 objects after an early bug in the game.
Progressive Web Features
We had roughly two weeks to bring this application into fruition. We opted to build for the web both in the interests of time but also to showcase how you can run computer vision models in your browser.
Indeed, you can run a computer vision model in a mobile web browser. We’re excited by the applications for this, particularly for active learning. We envision an app that lets you use a model in the browser to collect data, send those predictions and image data elsewhere, and build a pipeline where you fix poor predictions. (Stay tuned in this area!)
Because we were building for mobile devices, we decided to make our experience mobile-first from day one. If a player opened the app on desktop, a big QR code appeared inviting them to play the game on mobile. Desktop gameplay was enabled, but we didn’t optimize for this application; carrying your phone on a scavenger hunt is easier than carrying your laptop.

We followed best practices to turn our application into a progressive web application (PWA). We created a Web Manifest file that specified application icons, an app name, an app color, and other metadata required. By building a PWA, we could make our application installable from both iOS Safari and on Android devices (although the iOS Safari download experience is a bit hidden).

For users who installed the website as a PWA, playing the game was a tap away from your home screen.
Building the Roboflow Research Feature
Earlier in this post, we asked a bold question “how could we improve COCO?” To do so, we would need more images. Given that we were already using COCO in this project, we saw an opportunity to build an active learning pipeline.
In the last three days of the project, we launched the Roboflow Research feature. Roboflow Research was an invitation for users to share the images of each prediction with us for use in a larger dataset. We only collected images where a positive identification for a class in COCO was made, and where no person was identified anywhere in the image to ensure the privacy of players was preserved.
If a person was in the image, a frame would not be captured. We also committed to running all images through a face detection model and to apply blurs to all faces to ensure that any images that did contain faces (i.e. because COCO did not identify the face, or because the prediction was not present in the collected frame) would be blurred.
When a user first played the game, a pop up would appear inviting them to choose their preferences for sharing research data with us. A player could change their settings at any time on the gameplay page by checking or unchecking the permissions box.
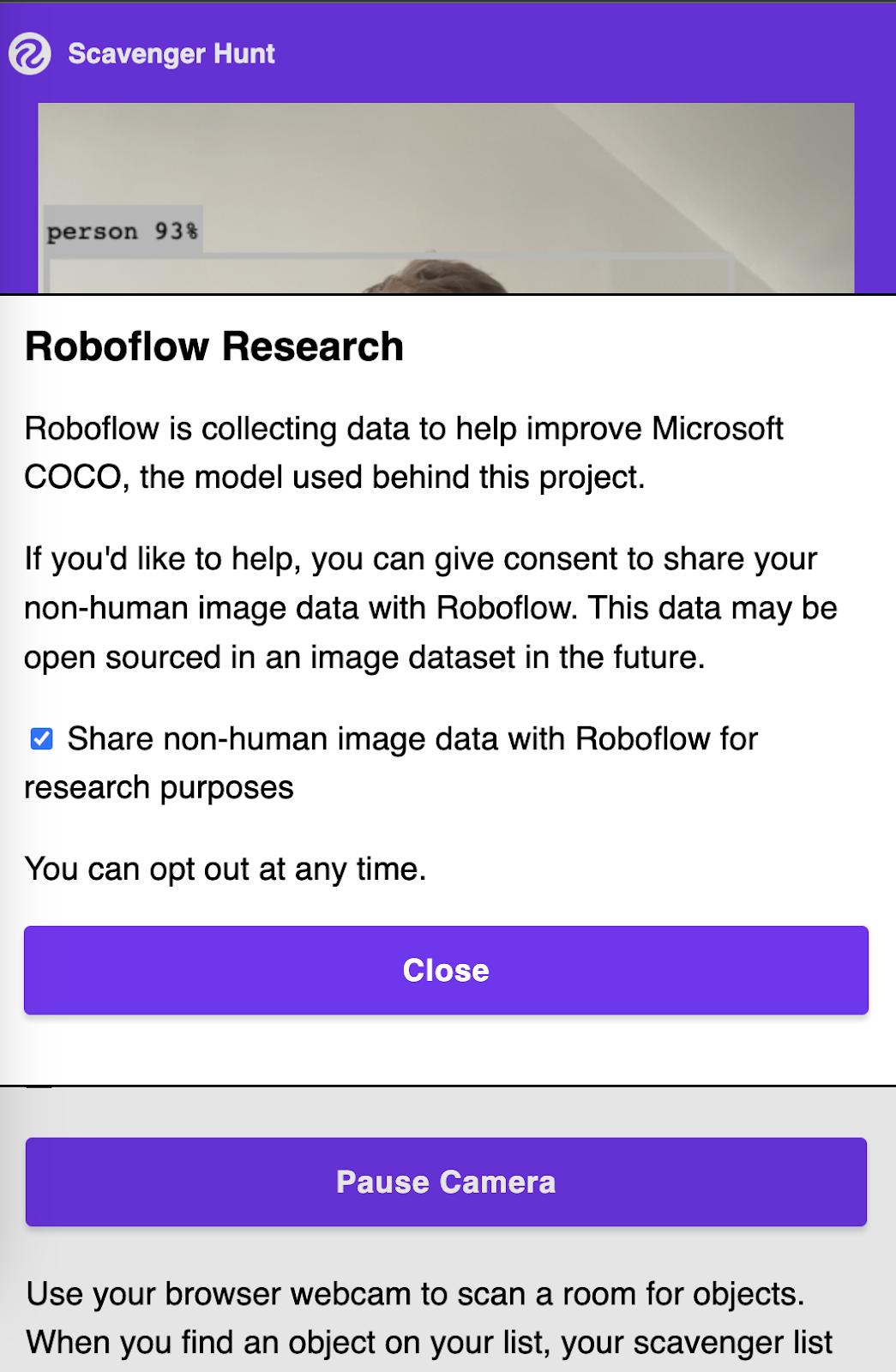
We collected around 100 images in the three days this was running, from backpacks to bananas, that will contribute to our larger efforts to help expand and update the COCO dataset.
What We Learned (and Open-Sourcing the App)
The Roboflow SXSW Scavenger Hunt application was an incredible experience. Team members from all disciplines around Roboflow – engineering, design, marketing, sales, and more – contributed to bringing this idea to fruition.
We introduced computer vision to hundreds of new people as part of a game. We created a leaderboard to encourage people to battle to get to the top. It all came from the question “What could we do to promote computer vision at SXSW?”
Although the competition may be over, the code for the scavenger hunt game is open-source. We learned a lot about implementing computer vision applications in the browser as part of this project. In the app, you will find code that runs inference on roboflow.js, paints a canvas on top of a video element, encodes webcam frames in base64, and more helper functions that may be useful when you are building computer vision applications.
We’re not done with this project, however! Next, we will be working on:
- Adding images to create an extended COCO dataset and re-training a new and improved version of the model to be made available publicly;
- Letting people try out a modified version of the game (coming soon);
- Adapting it for future conferences that we attend;
- Adapting the face blurring feature as an option into Roboflow's active learning flow and;
- Adding prediction post-processing to Supervision and roboflow.js.
We are excited at being able to bring computer vision into the hands of more people. Indeed, computer vision technologies are sufficiently advanced to allow for running inference in the browser. This opens up the opportunity to build a whole range of vision-powered mobile experiences.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Mar 27, 2023). From Idea to Reality: Building a Computer Vision Scavenger Hunt for SXSW. Roboflow Blog: https://blog.roboflow.com/sxsw-scavenger-hunt-review/