
DETR stands out from traditional object detection models due to its unique architecture and approach. Unlike other models that rely on anchor boxes or region proposal networks, DETR formulates object detection as a direct set prediction problem. It combines a transformer-based backbone with a set prediction head, allowing it to handle object detection as a sequence-to-sequence task. This design eliminates the need for anchor boxes and enables end-to-end training.
DETR is effective in applications such as autonomous driving, retail (inventory management, shelf monitoring, and loss prevention), industrial automation (quality control and defect detection), and security and surveillance (real-time detection and tracking of suspicious activities or objects).

To explore a comprehensive guide on training DETR on Custom Dataset, refer to this video. It provides step-by-step instructions and demonstrations for training, evaluating, and utilizing the DETR model.
Key Technical Features of DETR:
- Transformer Architecture: Unlike traditional object detection models, which use CNNs as the backbone, DETR employs a transformer encoder-decoder architecture. This architecture enables capturing global context information efficiently and allows for end-to-end training.
- Set Prediction: DETR formulates object detection as a set prediction problem. By treating object detection as a set, it eliminates the need for anchor boxes and non-maximum suppression during inference, simplifying the pipeline and improving efficiency.
- Attention Mechanism: Transformers utilize self-attention mechanisms, allowing them to capture dependencies between all elements in a sequence simultaneously. DETR leverages self-attention to capture both local and global dependencies within the image, enhancing its ability to understand object relationships and improve detection accuracy.
- Training Approach: DETR employs a bipartite matching loss during training to establish associations between predicted and ground truth bounding boxes. This approach allows DETR to handle cases with varying numbers of objects and avoids the need for anchor matching.
Utilizing the Jupyter Notebook
To showcase the usage of DETR, we provide a Jupyter notebook that guides users through the entire process of training, evaluating, and utilizing the DETR model. Here is an overview of the notebook:

1) Model Setup: We install the required dependencies and set up the DETR model. We load the pre-trained DETR model, specifying the checkpoint ('facebook/detr-resnet-50') and other configuration parameters.
2) Download Custom Dataset: This section shows how to download a custom dataset in COCO format using Roboflow. The COCO format is commonly used for object detection tasks.
3) Create COCO Data Loaders: We illustrate how to create COCO data loaders for training, validation, and testing using the torchvision library.
4) Train Model with PyTorch Lightning: Here, the notebook demonstrates how to train the DETR model using PyTorch Lightning.
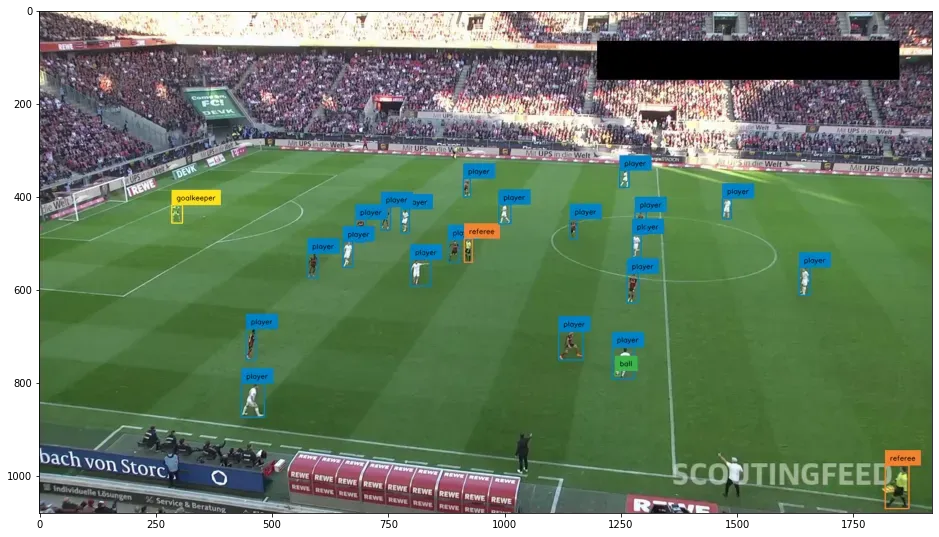
5) Inference on Test Dataset: After training, we run inference on a random image from the test dataset. The image is loaded, preprocessed, and passed through the trained model to obtain object detections.
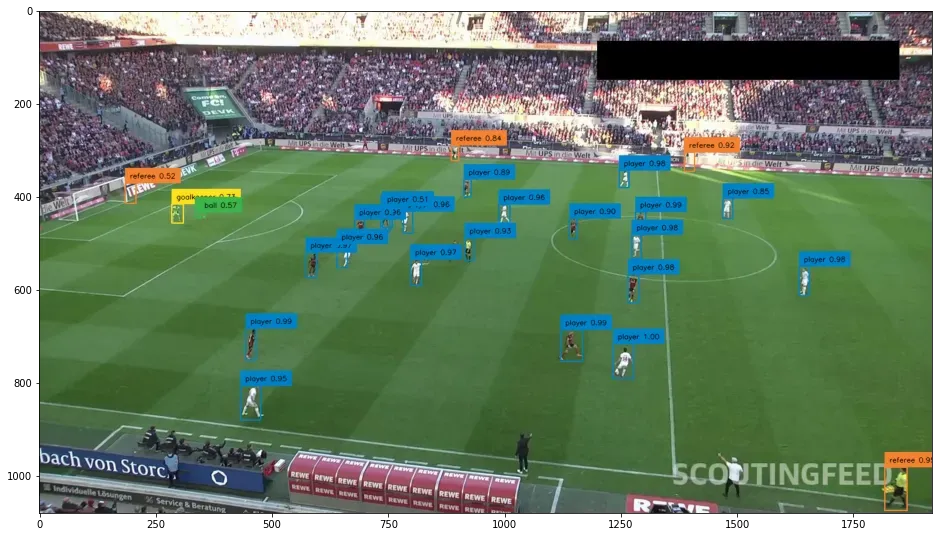
6) Evaluation on Test Dataset: The trained model is evaluated on the test dataset using the CocoEvaluator class, which measures performance metrics such as precision, recall, and average precision. The evaluator summarizes the results of the evaluation.
7) Save and Load Model: Finally, the trained model is saved to disk for future use. The model can be loaded later using the DetrForObjectDetection class and used for inference or further training.
By following the steps in the notebook, you can gain a comprehensive understanding of the DETR model. Remember to consider the unique requirements of your dataset and fine-tune the training parameters accordingly. Happy Engineering!
Cite this Post
Use the following entry to cite this post in your research:
Arty Ariuntuya. (Jun 19, 2023). How to Train DETR on a Custom Dataset. Roboflow Blog: https://blog.roboflow.com/train-detr-on-custom-dataset/