
On February 18th, 2025, YOLOv12 was released by a team of academic researchers. This model achieves both lower latency than previous YOLO models and higher accuracy when validated on the Microsoft COCO dataset. See the object detection model leaderboard for more details.
Starting today, you can train YOLOv12 models on Roboflow and deploy your trained models with the Roboflow Hosted Serverless API.
In this guide, we will walk through how to train and deploy YOLOv12 models with Roboflow.
Label Data for YOLOv12 Models with Roboflow
YOLOv12 uses the same data format as YOLOv8: YOLOv8 PyTorch TXT. You can both import and export data in that format required for training using Roboflow.
You can also convert data between formats. For example, if you have a COCO JSON dataset, you can convert it to the required format for YOLOv12 object detection.
You can see a full list of supported formats on the Roboflow Formats list.
If you don’t already have labeled data, or need to label more data for a project, Roboflow has an extensive suite of annotation tools to help speed up your labeling process, including SAM-powered annotation and auto-label.
Here is an example showing AI-powered labeling, where you can hover over an object and click on it to draw a polygon annotation:
Once you have labeled your dataset, you can apply augmentations and preprocessing steps to prepare your dataset for training.
Train YOLOv12 Models with Roboflow
You can train YOLOv12 models on the Roboflow hosted platform, Roboflow Train.
To train a model, first create a project on Roboflow and generate a dataset version. Then, click “Custom Train” on your dataset version dashboard:
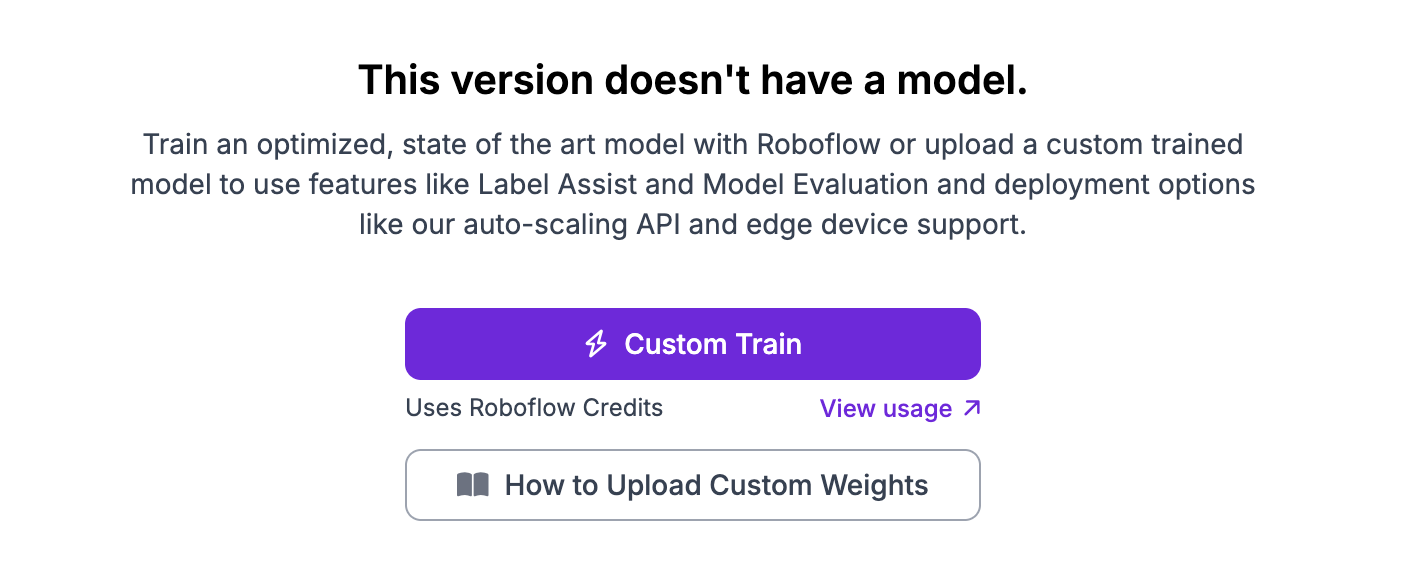
A window will appear from which you can choose the type of model you want to train. Select “YOLO12”:
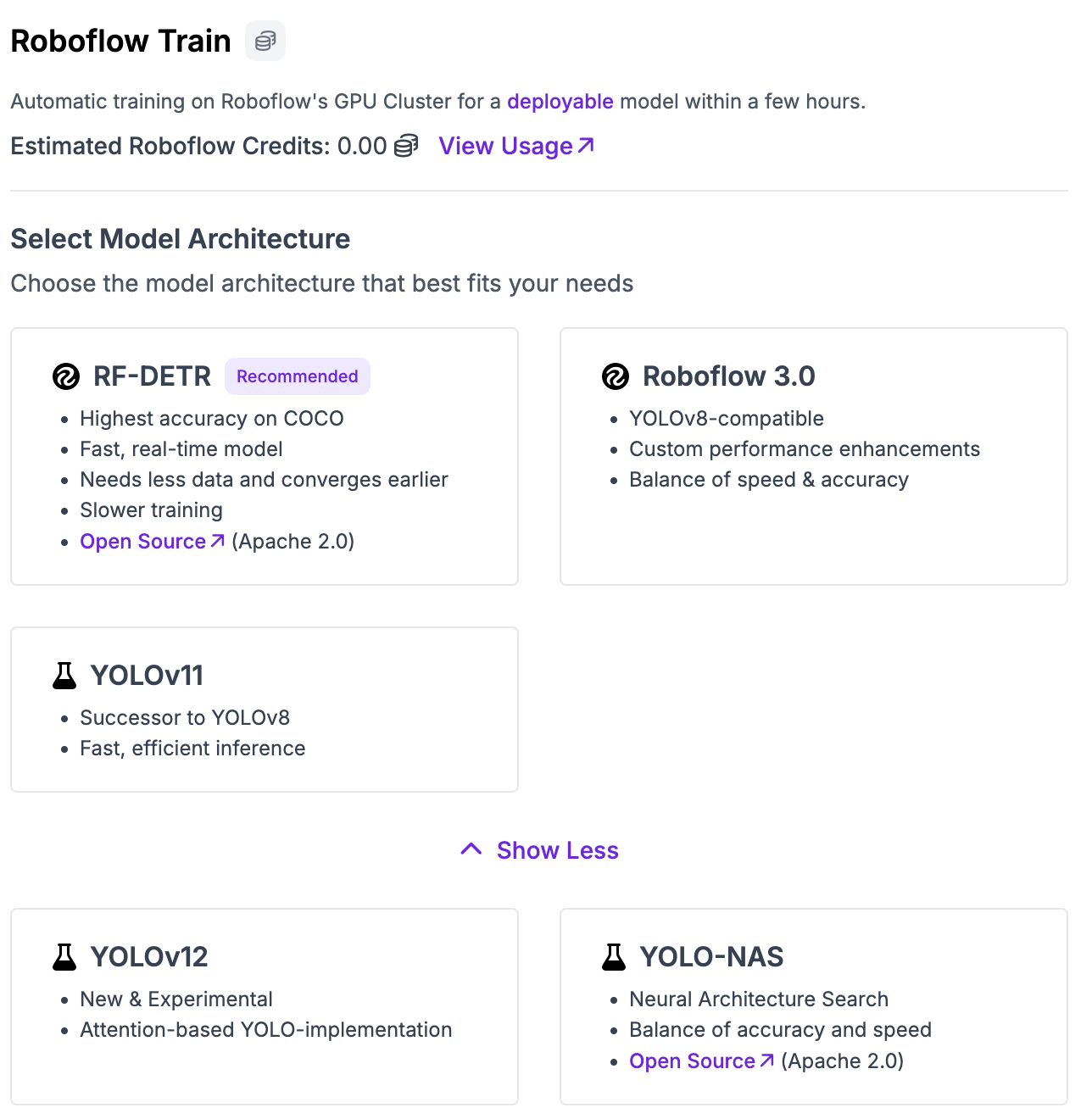
Then, click “Continue”. You will then be asked whether you want to train a Fast, Accurate, or Extra Large model. For testing, we recommend training a Fast model. For production use cases where accuracy is essential, we recommend training Accurate models.
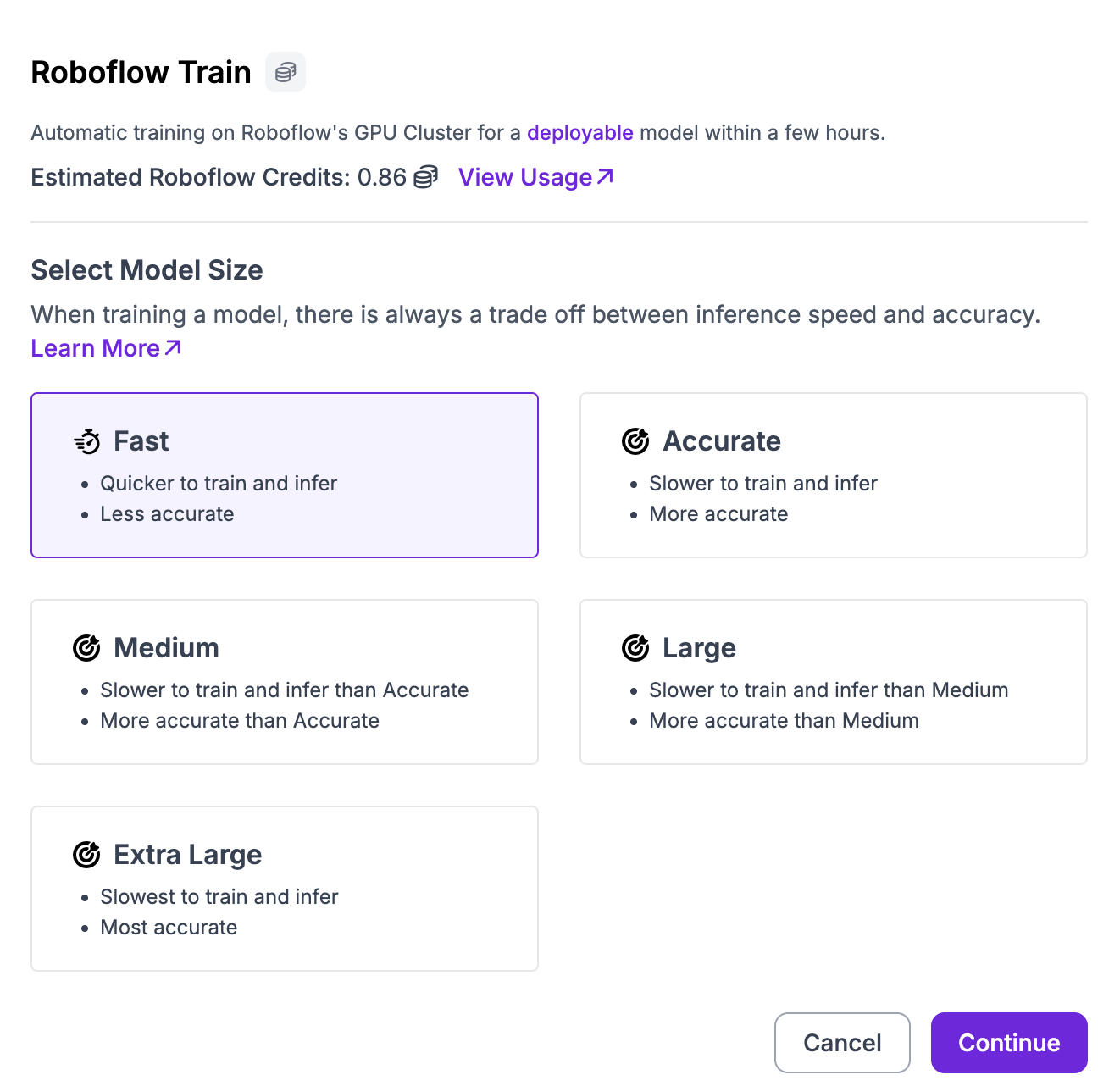
You will then be asked from what training checkpoint you want to start training. By default, we recommend training from our YOLOv12 COCO Checkpoint. If you have already trained a YOLOv12 model on a previous version of your dataset, you can use the model as a checkpoint. This may help you achieve higher accuracy.
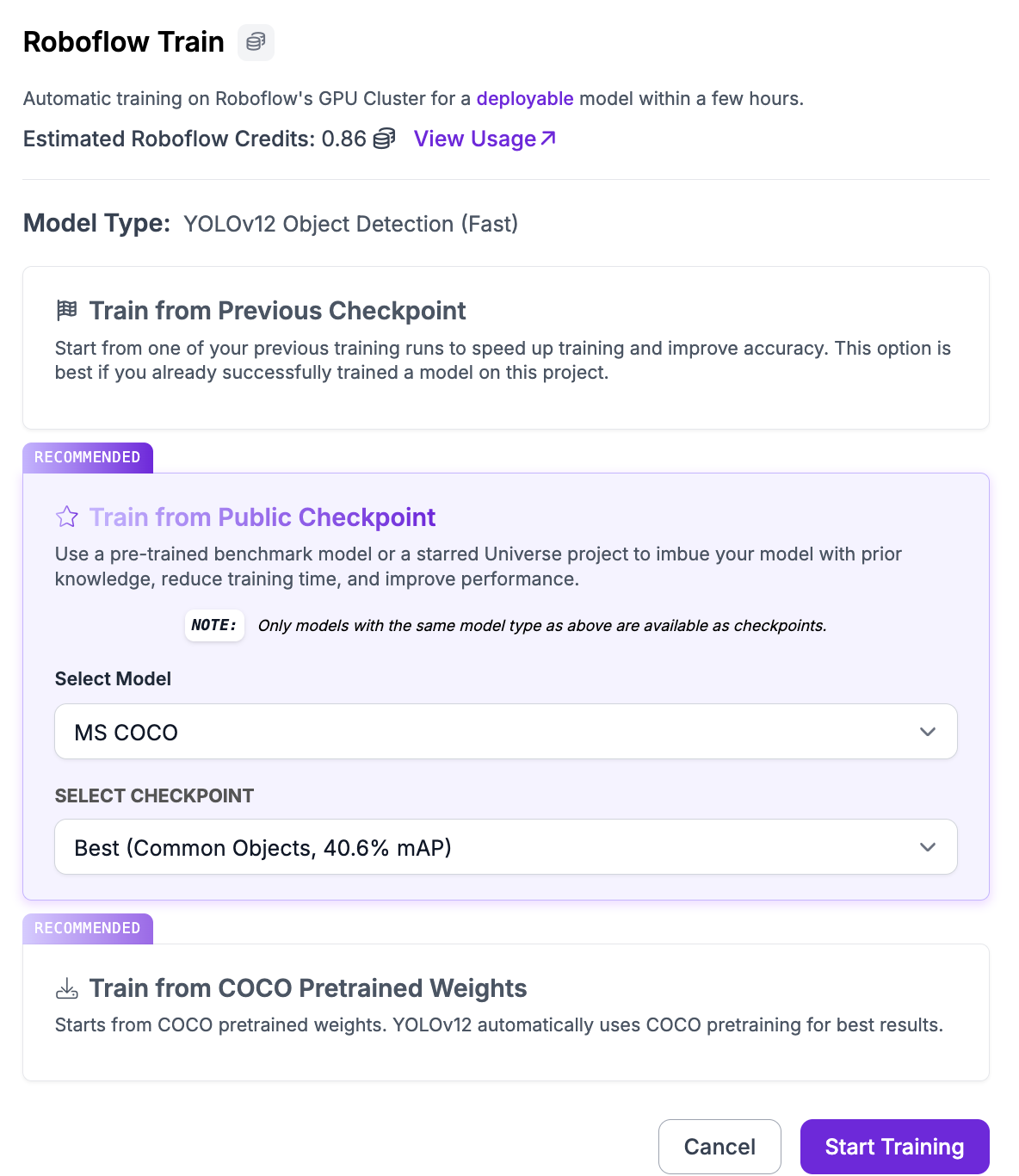
Click “Start Training” to start training your model.
You will receive an estimate for how long we expect the training job to take.
The amount of time your training job will take will vary depending on the number of images in your dataset and several other factors.
Deploy YOLOv12 Models with Roboflow
You can deploy your YOLOv12 models using the Roboflow Serverless Hosted API, our serverless cloud API offering, and Roboflow Workflows, our vision application building tool.
Deploy with Workflows
You can use YOLOv12 object detection models in Roboflow Workflows.
To get started, create a new Workflow or open an existing one, then add an Object Detection block:
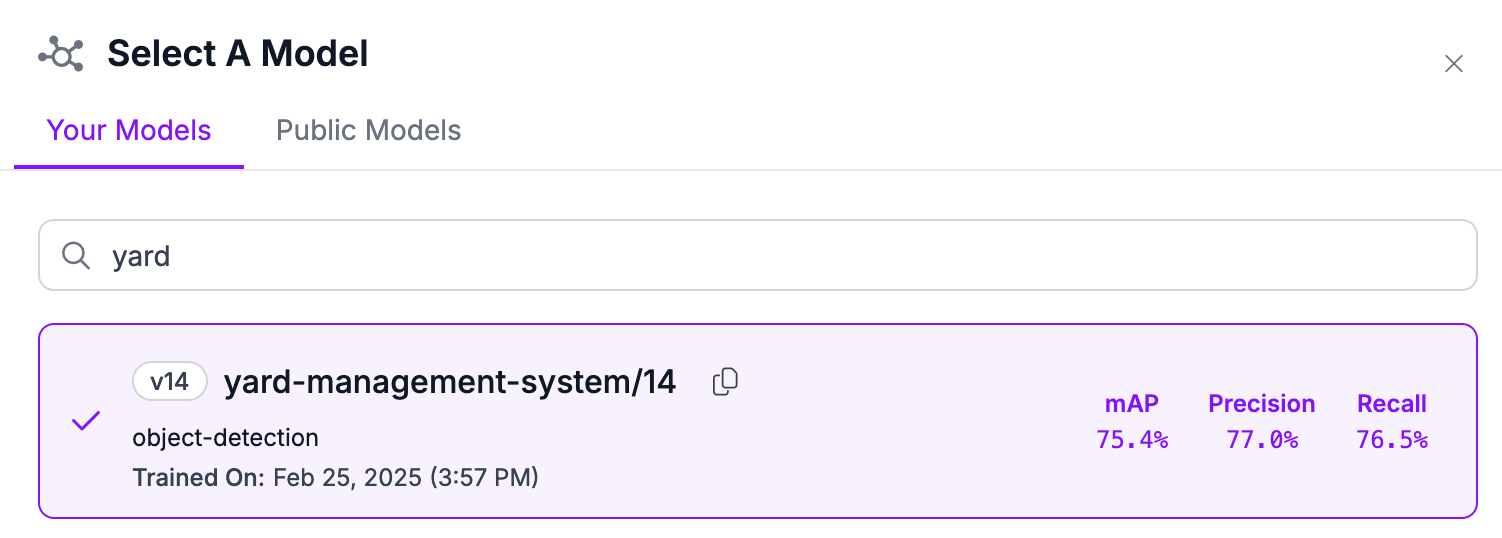
Then, choose any model you have trained in your workspace that uses the YOLOv12 architecture:
You can run your Workflow to see results from your model:
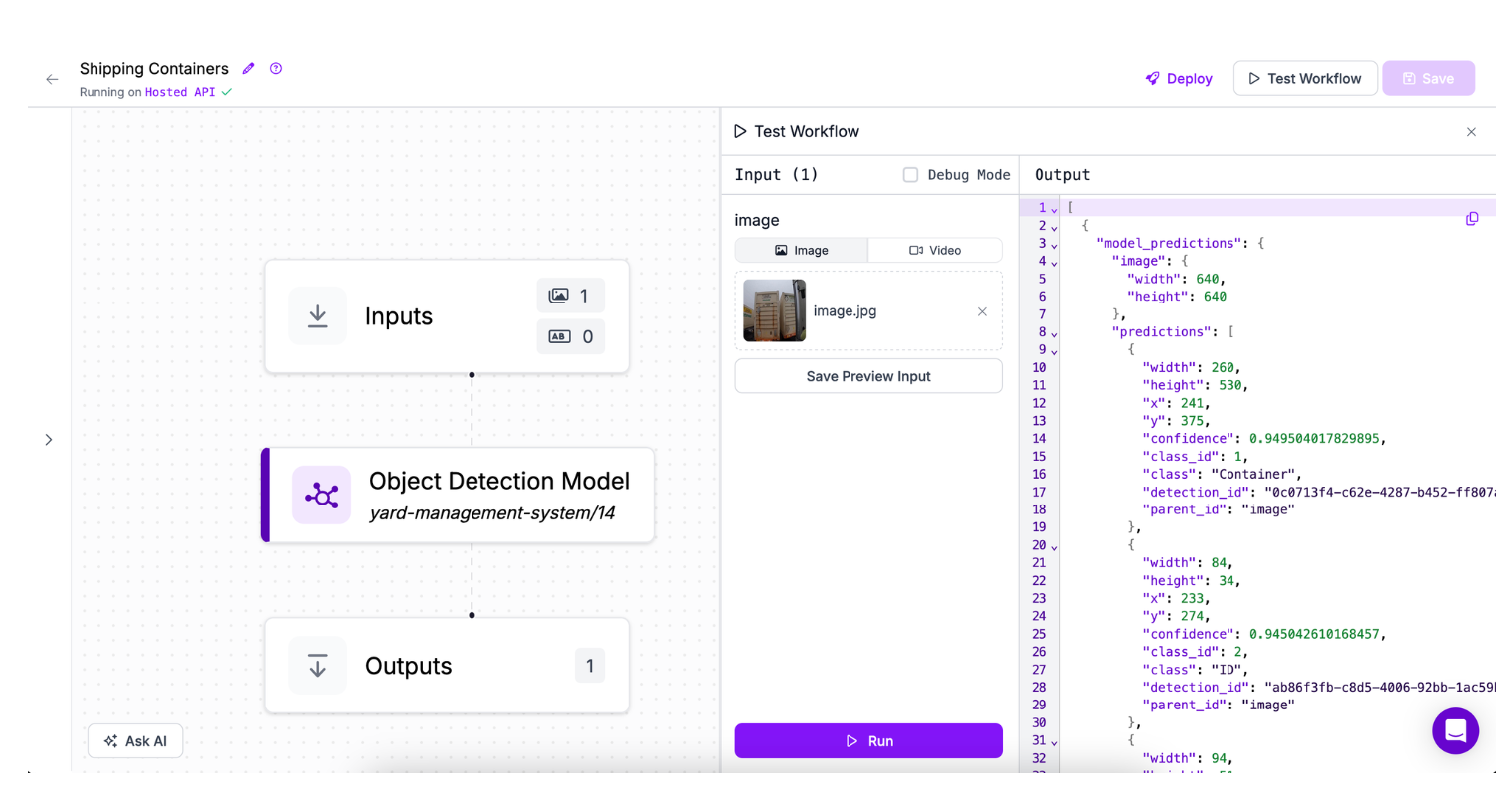
You can add a wide range of other functionalities to your Workflow using any of the 50+ blocks supported in Workflows, from filtering detections to annotating bounding boxes to sending messages to platforms like Slack or via SMS.
Deploy with Inference
You can deploy on both CPU and GPU devices. If you deploy on a device that supports a CUDA GPU – for example, an NVIDIA Jetson – the GPU will be used to accelerate inference.
To deploy a YOLOv12 model on your own hardware, first install Inference:
pip install inferenceYou can run Inference in two ways:
- In a Docker container, or;
- Using our Python SDK.
For this guide, we are going to deploy with the Python SDK.
Create a new Python file and add the following code:
from inference import get_model
import supervision as sv
import cv2
# define the image url to use for inference
image_file = "YOUR_IMAGE.jpg"
image = cv2.imread(image_file)
# load a pre-trained model
model = get_model(model_id="your-model-id/version")
# run inference on our chosen image, image can be a url, a numpy array, a PIL image, etc.
results = model.infer(image)[0]
# load the results into the supervision Detections api
detections = sv.Detections.from_inference(results)
# create supervision annotators
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
# annotate the image with our inference results
annotated_image = bounding_box_annotator.annotate(
scene=image, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections)
# display the image
sv.plot_image(annotated_image)Above, set your Roboflow workspace ID, model ID, and API key, if you want to use a custom model you have trained in your workspace.
Replace YOUR_IMAGE.jpg with the name of the image you want to use.
Here is an example of results from the model, plotted with the supervision code above:

The model successfully detected shipping containers in the image, indicated by the red bounding box surrounding the object of interest, as well as other classes the model was trained to detect.
You can also run inference on a video stream. To learn more about running your model on video streams – from RTSP to webcam feeds – refer to the Inference video guide.
YOLOv12 Hosted API Endpoint
If you want to deploy a model using the Serverless API, go to the “Deployments” tab in your project and click the “Hosted Image Inference” option.
A window will appear with a code snippet you can use to call a serverless API running your model. The code snippet will look like this:
# import the inference-sdk
from inference_sdk import InferenceHTTPClient
# initialize the client
CLIENT = InferenceHTTPClient(
api_url="https://detect.roboflow.com",
api_key="API_KEY"
)
# infer on a local image
result = CLIENT.infer("YOUR_IMAGE.jpg", model_id="model-name/model-id")Conclusion
YOLOv12 is a new YOLO model architecture developed by an independent team of researchers. As of February 20th, 2025, you can train YOLOv12 models on the Roboflow platform and deploy them with the Roboflow Serverless Hosted API.
In this guide, we walked through how to label data for a YOLOv12 model, train a YOLOv12 model on Roboflow, and deploy your trained model either on device or in the cloud.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Feb 20, 2025). Launch: Use YOLOv12 with Roboflow. Roboflow Blog: https://blog.roboflow.com/use-yolov12-with-roboflow/