
Vision Transformers (ViTs) represent a groundbreaking shift in computer vision, leveraging the self-attention mechanisms that revolutionized natural language processing. Unlike traditional convolutional neural networks (CNNs), which rely on hierarchical feature extraction, ViTs treat images as sequences of smaller patches, enabling them to capture global relationships and long-range dependencies within visual data. This unique approach has demonstrated exceptional performance across tasks like image classification, object detection, and generative modeling, making ViTs a powerful tool for advancing AI-driven image analysis. Their versatility and scalability position them as a key innovation in the evolving landscape of computer vision.
In this article we will look into:
- What are ViTs?
- How Do ViTs Work?
- ViTs vs. CNNs
- Applications of ViTs
- Recent Advancements in the ViT Literature
- Challenges and Limitations of ViTs
What Are Vision Transformers?
Transformers are a powerful deep learning architecture originally developed for natural language processing (NLP) tasks such as machine translation, text summarization, and sentiment analysis. At their core, transformers use an encoder-decoder structure, where the encoder processes an input sequence (like a sentence) and creates a rich, contextual representation, while the decoder generates the output sequence based on this representation.
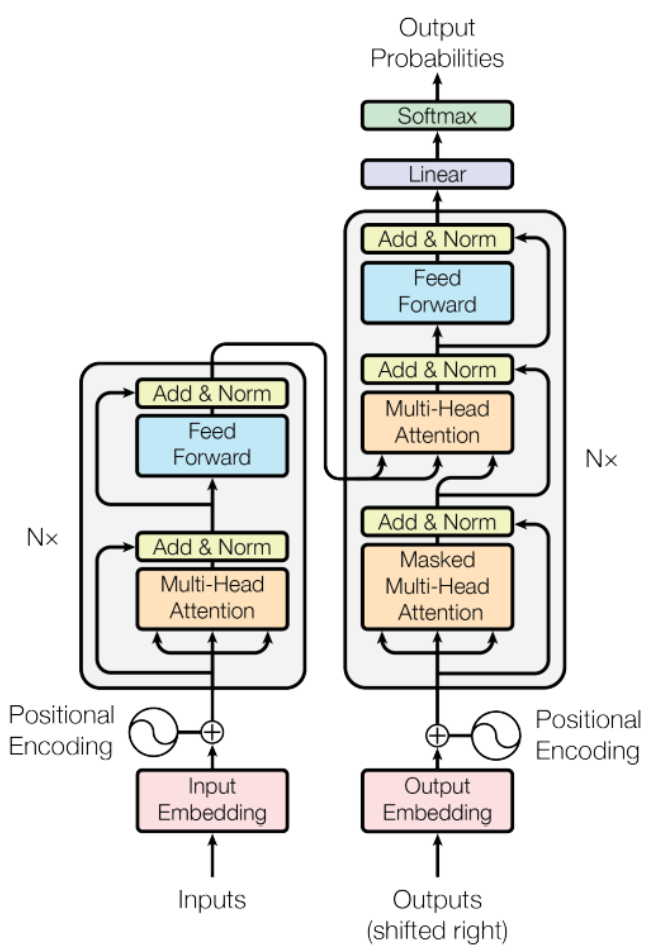
The key innovation behind transformers is the self-attention mechanism, which allows the model to weigh the importance of each element in the sequence relative to others, capturing both local and long-range dependencies without relying on recurrent or convolutional operations. This design enables transformers to process entire sequences in parallel, leading to significant gains in efficiency and performance over previous architectures like RNNs and LSTMs.
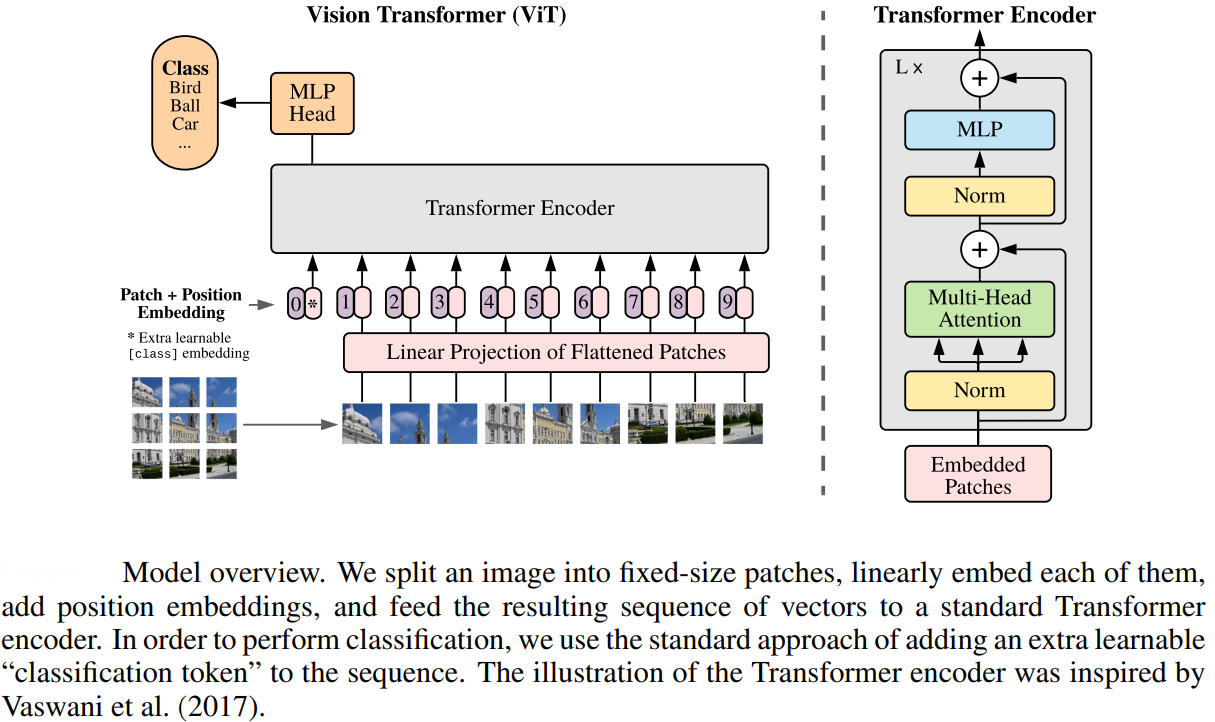
Introduced in 2021 by Google Research with the landmark paper "An Image is Worth 16x16 Words," ViTs adapt this transformative approach from language to visual data. Just as traditional transformers break down sentences into word tokens, ViTs divide an image into fixed-size patches and treat each patch as a “visual token”. These patches are then linearly embedded and supplemented with positional encodings to retain spatial information—mirroring how words are embedded and ordered in NLP transformers.
The sequence of patch embeddings is fed into the transformer encoder, where self-attention mechanisms learn relationships between different regions of the image, much like how they capture dependencies between words in a sentence. A special classification token, analogous to the [CLS] token in NLP models, is used to aggregate information from all patches for image-level tasks. By drawing this parallel, Vision Transformers leverage the same architecture that revolutionized language understanding to achieve state-of-the-art results in image recognition, demonstrating the versatility and power of the transformer framework across different domains.
How Do Vision Transformers Work?
ViTs bring the power of transformer architectures to the world of computer vision by reimagining how images are processed and understood. Instead of relying on convolutions to extract features, ViTs treat images as sequences of patches and use self-attention mechanisms to capture relationships across the entire image. This approach allows them to model both local and global dependencies, leading to impressive performance on a variety of visual tasks.

Here’s a breakdown of the core architecture of any ViT:
- Image Patch creation: The first step in a Vision Transformer is to divide the input image into a grid of small, fixed-size patches (for example, 16x16 pixels each). Each patch is then flattened into a one-dimensional vector, effectively transforming the 2D image into a sequence of patch vectors.
- Linear Embedding of Patches: Each patch vector is passed through a linear layer (a simple neural network layer) to project it into a higher-dimensional space. This process creates a sequence of embeddings, one for each patch, similar to how words in a sentence are embedded in NLP transformers.
- Adding Positional Encodings: Because transformers do not inherently understand the order or position of patches, positional encodings are added to each patch embedding. These encodings inject information about the spatial location of each patch, helping the model retain the structure of the original image.
- Transformer Encoder: The sequence of patch embeddings, now enriched with positional information, is fed into a standard transformer encoder. The encoder consists of multiple layers of multi-head self-attention and feed-forward neural networks. Through self-attention, the model learns how different patches relate to each other, capturing both local and global patterns in the image.
- Classification Token: A special learnable token, often called the “classification token” or [CLS] token, is prepended to the sequence of patch embeddings. After passing through the transformer layers, the output corresponding to this token is used as the overall representation of the image for tasks like classification.
The key components in ViTs are:
- Self-Attention Mechanism: The self-attention mechanism is the heart of the transformer architecture. It allows the model to dynamically weigh the importance of each patch in relation to all others, enabling it to capture complex dependencies and contextual information across the entire image.
- Multi-Head Attention: Instead of relying on a single attention mechanism, ViTs use multiple attention “heads” in parallel. Each head can focus on different aspects or regions of the image, allowing the model to learn a richer and more diverse set of relationships.
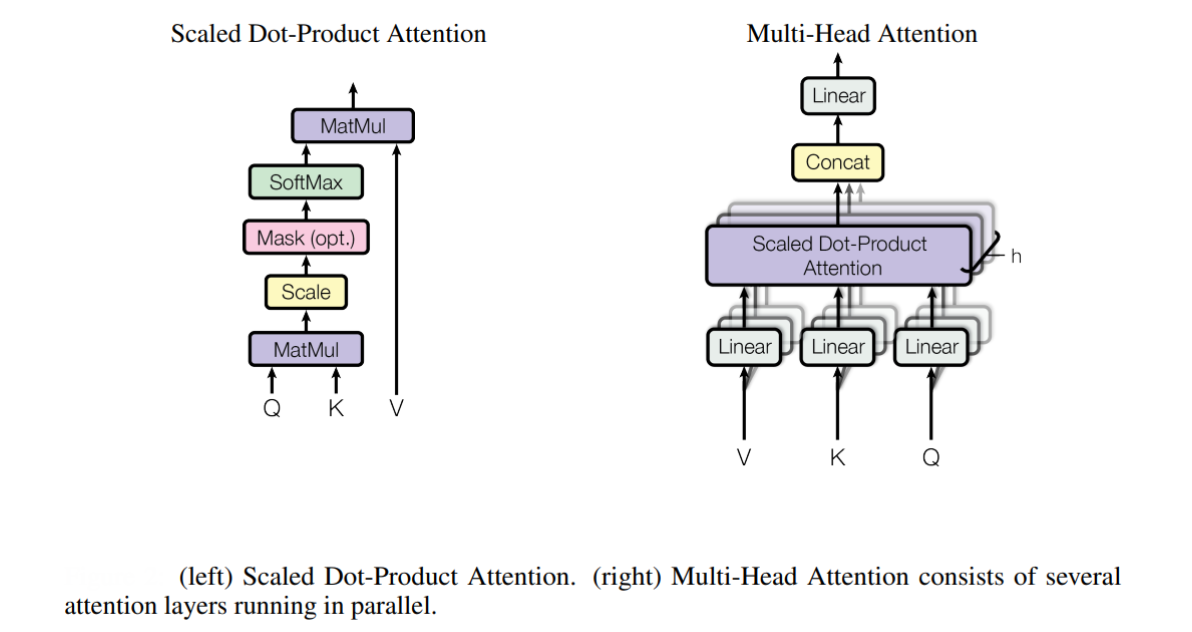
- Feed-Forward Networks: After the self-attention layers, each patch embedding is further processed by a feed-forward neural network. This step helps the model capture more complex patterns and representations.
- Layer Normalization and Residual Connections: To stabilize training and improve performance, each transformer layer uses layer normalization and residual (skip) connections. These techniques help maintain the flow of information and gradients through the deep network.
Vision Transformers vs. CNNs
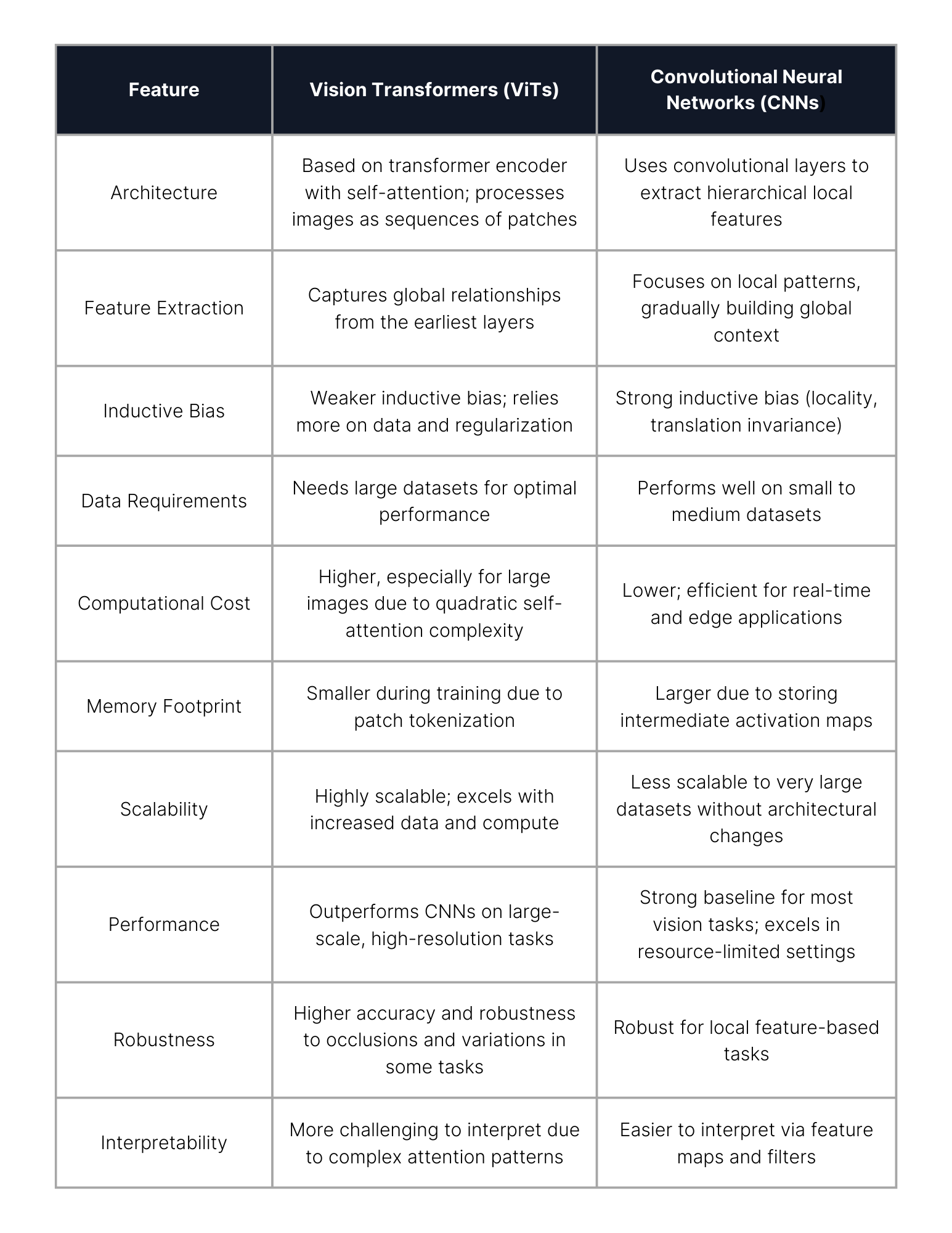
ViTs and CNNs represent two distinct paradigms in computer vision. CNNs have long been the backbone of image analysis, leveraging convolutional layers to extract local features and build hierarchical representations. Their inductive biases—such as locality and translation invariance—make them highly effective for tasks with limited data and computational resources.
In contrast, Vision Transformers use self-attention mechanisms to model global relationships between image patches from the outset, allowing them to capture long-range dependencies and holistic context within an image. This global perspective enables ViTs to outperform CNNs on large-scale datasets and tasks requiring a comprehensive understanding of visual content.
However, ViTs typically require more data for effective training and are generally more computationally intensive, especially at higher resolutions. The table below summarizes the key differences between the two architectures:
Applications of Vision Transformers
ViTs have been successfully applied to several fields from Medical Imaging to Generative AI, revolutionizing the state-of-the-art in these fields. Let us look at some example applications.
Medical Imaging
The LVM-Med (NeurIPS 2023) framework demonstrates how ViTs excel in medical imaging by addressing critical limitations of traditional CNNs. Unlike CNNs, which rely on hierarchical convolutional layers to extract local features, ViTs process images as sequences of patches, enabling them to model global relationships across an entire medical scan. This capability is particularly advantageous in tasks like tumor detection or organ segmentation, where anomalies may span distant regions.
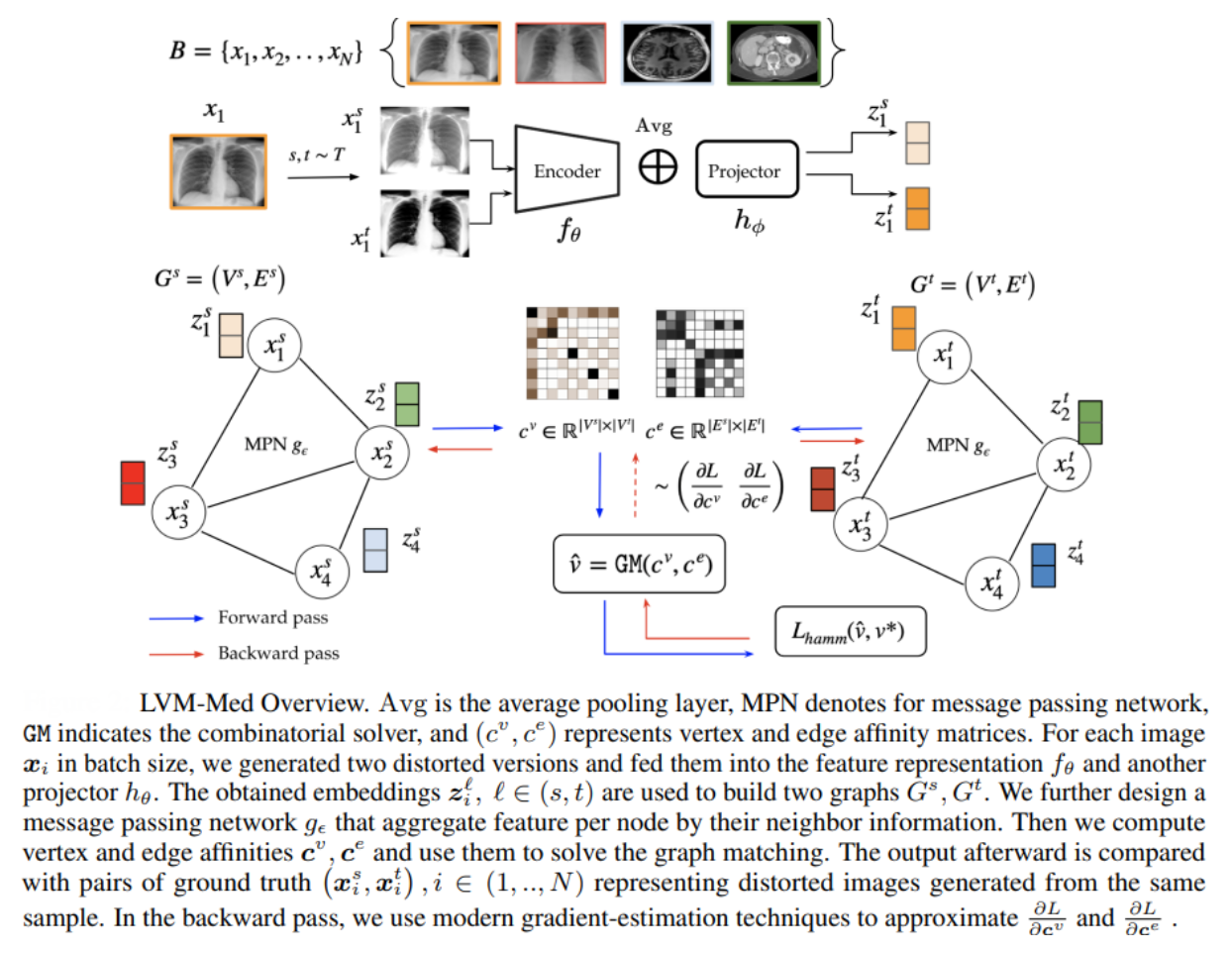
The key innovations of the ViT used in LVM-Med are:
- Global Context Modeling: LVM-Med leverages ViT’s self-attention mechanism to analyze interactions between non-adjacent image patches. For example, in brain MRI segmentation, ViTs capture long-range dependencies between tumor regions and surrounding tissues, outperforming CNNs that focus on local patterns.
- Integration of Local and Global Features: The framework combines patch-level embeddings with positional encodings, preserving spatial information while enabling holistic understanding. This dual focus improves performance in fine-grained tasks like diabetic retinopathy grading, where both microvascular details and global fundus structure matter.
- Scalability with Limited Data: While ViTs typically require large datasets, LVM-Med mitigates this via self-supervised pretraining on 1.3 million medical images across 55 datasets. By treating images as patch sequences, ViTs generalize better than CNNs when fine-tuning on smaller, domain-specific datasets (e.g., rare cancer subtypes).
- Structural Robustness via Graph Matching: LVM-Med introduces a second-order graph-matching objective that aligns feature embeddings of transformed image pairs. This approach, enabled by ViT’s flexible token-based architecture, enforces consistency in both local (e.g., cell nuclei) and global (e.g., organ boundaries) structures.
The ViTs in LVM-Med consistently outperformed the ResNet-50 CNN based approach. Here are some quantitative juxtapositions:
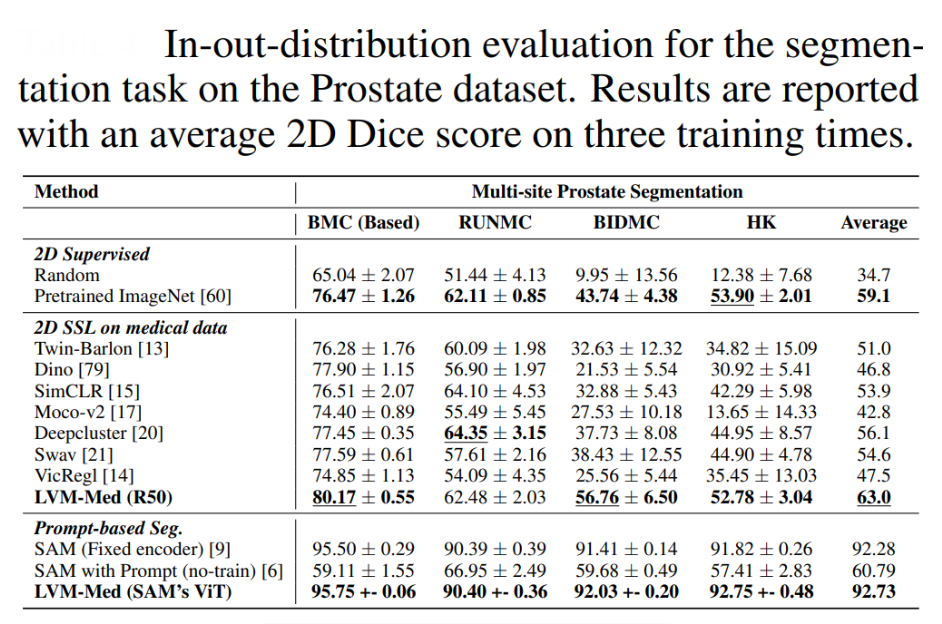
Segmentation: On the BMC prostate segmentation dataset, LVM-Med’s ViT achieved a 95.75% Dice score, surpassing CNN-based methods by ~15%. ViTs’ ability to model global tumor margins reduced false positives in irregularly shaped lesions.
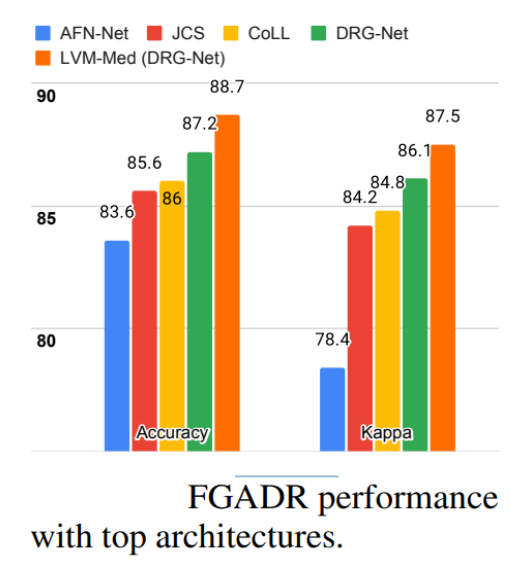
Classification: For diabetic retinopathy grading, ViTs improved accuracy over state-of-the-art models, showcasing superior adaptation to medical domain shifts.
Data Efficiency: ViTs pretrained on LVM-Med’s dataset outperformed CNNs (by ~11%) in low-data scenarios, e.g., achieving 89.69% Dice on breast ultrasound segmentation with only 647 training samples.
ViTs work better for medical imaging as demonstrated by LVM-Med because:
- Reduced Inductive Bias: Unlike CNNs, ViTs lack built-in assumptions about local spatial hierarchies, making them more adaptable to diverse medical modalities (e.g., 3D MRI vs. 2D X-ray).
- Multi-Scale Attention: ViTs dynamically weigh relationships between patches at varying scales, crucial for detecting lesions of different sizes in tasks like lung nodule detection.
Autonomous Driving
HM-ViT (ICCV 2023) addresses a crucial challenge in autonomous driving: enabling robust, scalable, and flexible perception in dynamic, real-world traffic where vehicles may be equipped with different types of sensors (e.g., LiDAR or cameras). Unlike traditional approaches that assume all vehicles use the same sensor modality, HM-ViT introduces a unified framework that allows heterogeneous agents to share and fuse information, dramatically improving perception capabilities—especially in scenarios with occlusions or limited individual sensor coverage.

At the core of HM-ViT is a novel heterogeneous 3D graph transformer architecture. Each vehicle, regardless of its sensor type, first extracts bird's-eye view (BEV) features using modality-specific encoders. These features are compressed, transmitted to neighboring vehicles, and then decompressed for fusion. The fusion process is performed by the HM-ViT module, which uses specialized local and global attention mechanisms (heterogeneous 3D graph attention) to jointly reason about inter-agent and intra-agent interactions. This design allows the model to capture both fine-grained object details (local attention) and broader environmental context (global attention), all while maintaining the distinct characteristics of each sensor modality throughout the process.
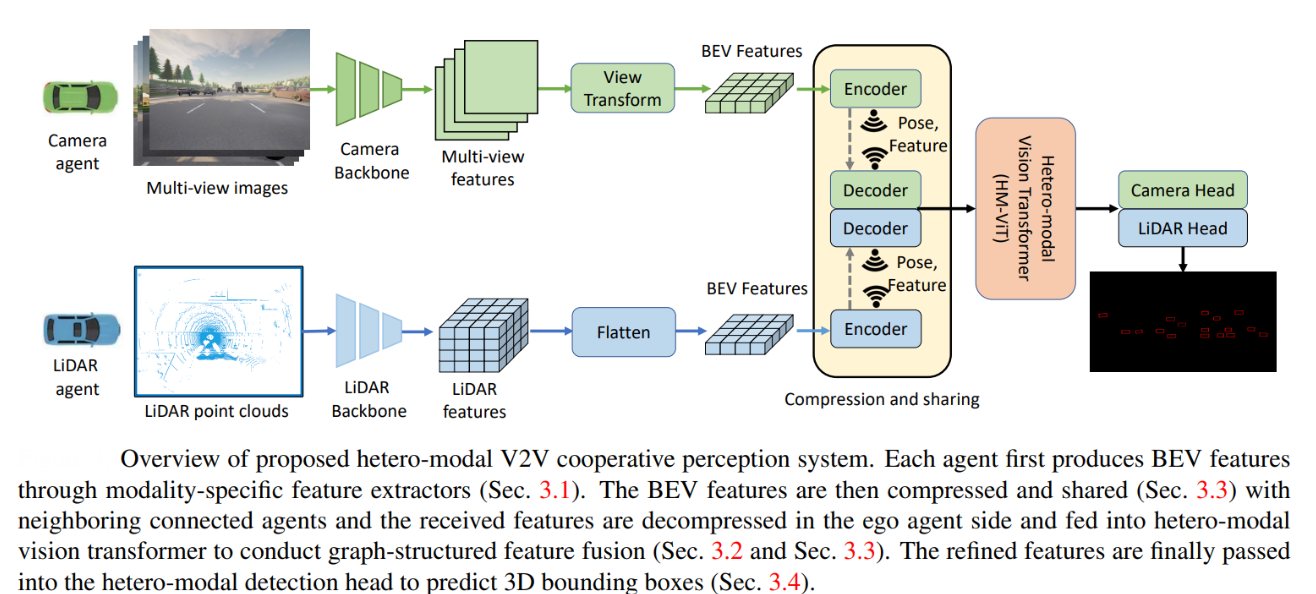
The power of ViTs in this context lies in their ability to flexibly model relationships across a dynamic and heterogeneous collaboration graph, something CNN-based or fixed-structure fusion methods struggle with. HM-ViT’s attention-based architecture dynamically adapts to varying numbers and types of agents, handling spatial misalignments and semantic discrepancies between camera and LiDAR data. Extensive experiments on the OPV2V dataset show that HM-ViT outperforms state-of-the-art cooperative perception methods by a significant margin, particularly boosting the performance of camera-only vehicles when collaborating with LiDAR-equipped agents (e.g., improving AP@0.7 from 2.1% to 53.2% for camera agents with LiDAR collaborators). This demonstrates that ViTs are not only effective but also crucial for building reliable, cost-efficient, and scalable perception systems in heterogeneous autonomous driving environments, setting a new standard for multi-agent cooperation beyond the limitations of CNN-based approaches.

3D Vision
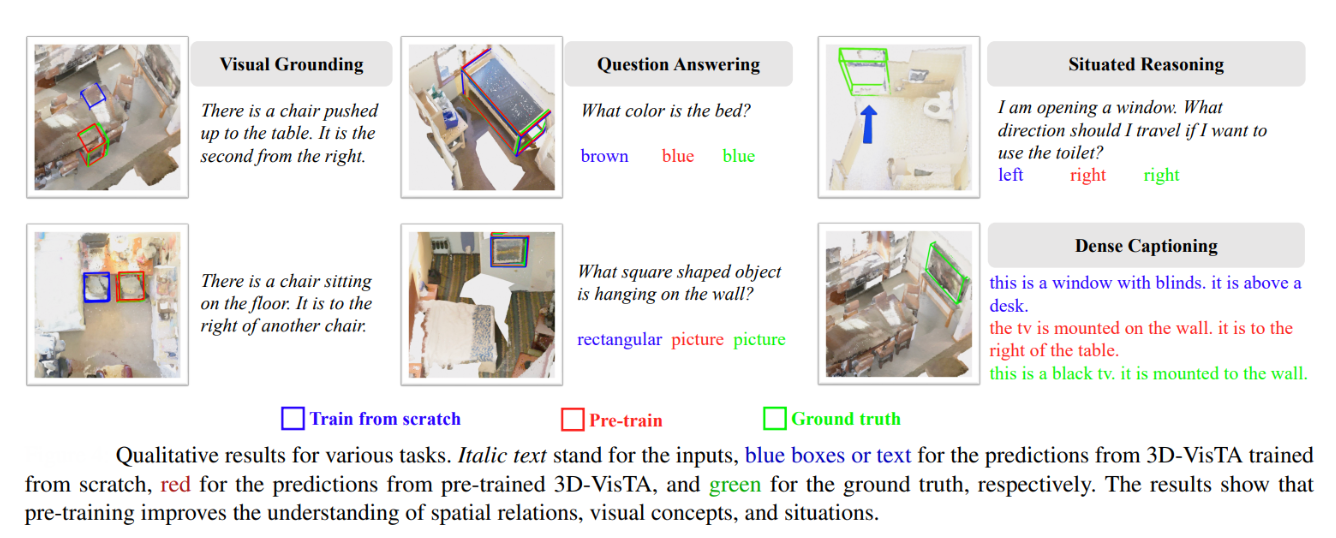
3D-VisTA or 3D Vision and Text Alignment (ICCV 2023) shows how Vision Transformers can greatly simplify and improve 3D vision-language tasks. Unlike earlier 3D vision-language models that rely on complex, task-specific modules and extra losses, 3D-VisTA uses a unified Transformer architecture with self-attention for both 3D scene and text modeling, as well as their fusion. This makes the approach much simpler and more generalizable.
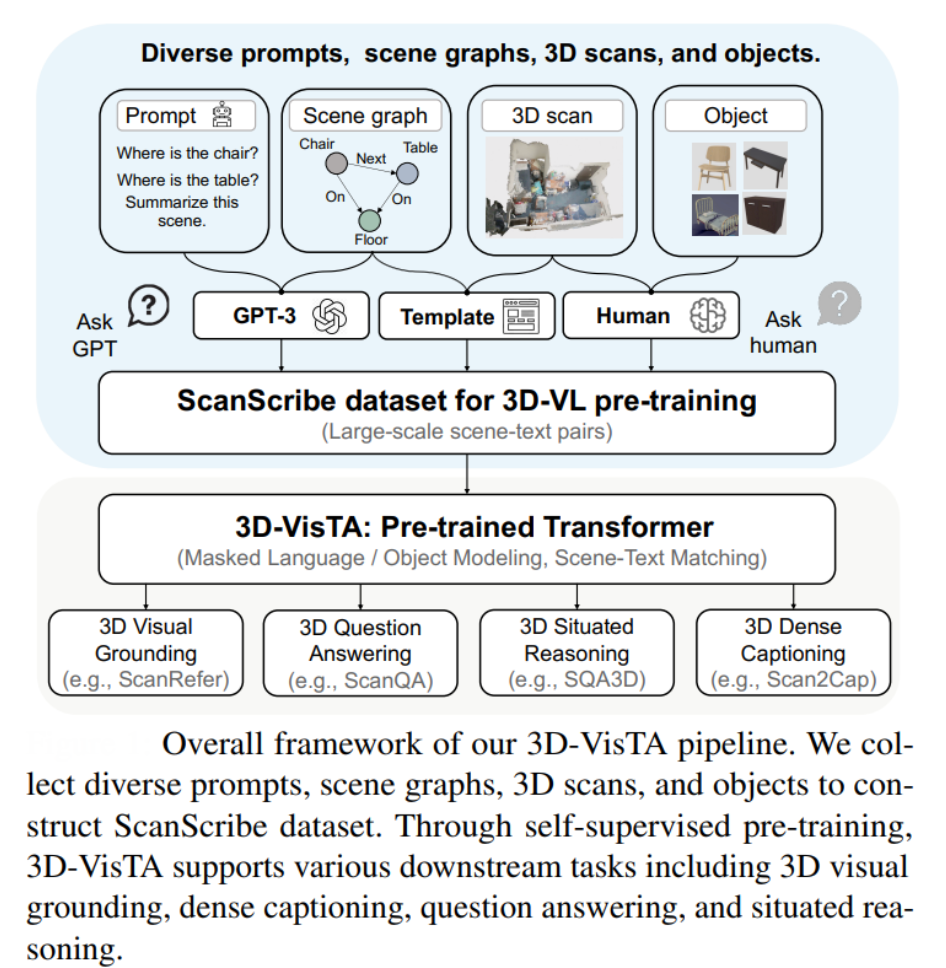
The model is pre-trained on ScanScribe, a large-scale dataset of 3D scenes paired with text, using self-supervised objectives like masked language modeling, masked object modeling, and scene-text matching. This pre-training enables 3D-VisTA to learn strong 3D-text alignment, leading to state-of-the-art results on a range of tasks including 3D visual grounding, dense captioning, question answering, and situated reasoning.
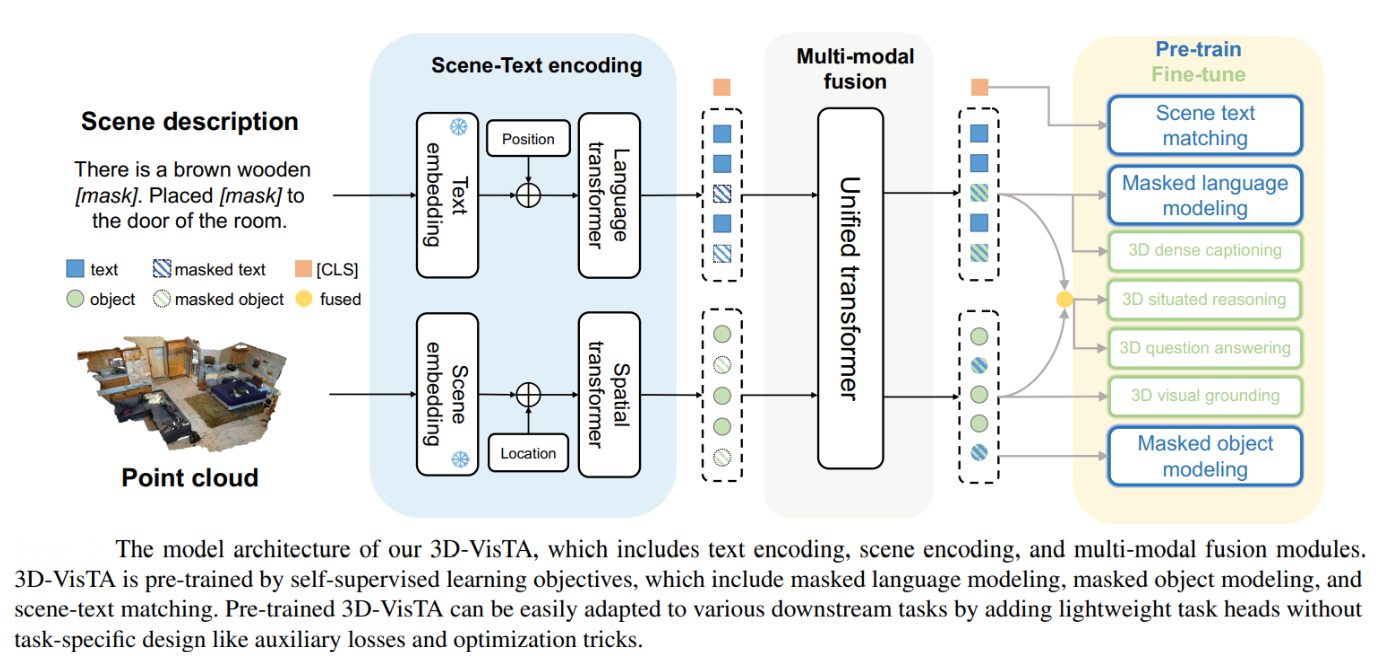
Key advantages of using ViTs in 3D-VisTA:
- Unified, simple architecture: No need for handcrafted modules or auxiliary losses—just self-attention.
- Flexible multi-task learning: The same model adapts easily to various 3D vision-language tasks.
- Data efficiency: Pre-training makes the model robust, even with limited task-specific data.
- Superior performance: 3D-VisTA achieves top results across multiple benchmarks, demonstrating the power of ViTs as foundation models for 3D vision.
Generative AI
Before Diffusion models, ViTs had revolutionized generative AI models like MAGVIT and Latte by addressing the inherent complexity of spatio-temporal data.
MAGVIT: Masked Generative Video Transformer

The core mechanisms in the MAGVIT model are:
- 3D Tokenization: MAGVIT quantizes videos into discrete spatial-temporal tokens using a 3D-VQ encoder, treating videos as sequences of patches (e.g., 16×16×16 voxels). This aligns with ViTs' strength in processing sequential data.
- Masked Token Modeling (MTM): Inspired by BERT, MAGVIT trains a bidirectional transformer to predict masked tokens in the latent space. The COMMIT method embeds task-specific conditions (e.g., partial frames) into the mask, enabling multi-task learning (frame prediction, inpainting, etc.).
- Non-Autoregressive Decoding: Generates videos in parallel (12 steps), achieving 60× faster inference than autoregressive models. ViTs' parallel processing avoids the sequential bottleneck of RNNs/CNNs.
Contributions of the ViT backbone:
- Global Context: Self-attention captures long-range dependencies across frames and pixels, critical for coherent motion synthesis.
- Scalability: Handles high-resolution videos (128×128) efficiently by reducing token sequence length via 3D compression.
- Multi-Task Flexibility: A single ViT backbone supports 10+ tasks by dynamically masking/refining tokens based on conditions.



Latte: Latent Diffusion Transformer
The core mechanisms in the Latte model are:
- Spatio-Temporal Tokenization: Uses a pre-trained VAE to encode videos into latent tokens, then applies ViT blocks to model diffusion in latent space.
- Factorized Attention: Four model variants decompose spatial and temporal attention (e.g., interleaving spatial/temporal blocks or splitting attention heads), optimizing computational efficiency.
- Adaptive Conditioning: Scalable Adaptive Layer Normalization (S-AdaLN) injects timestep/class info via scale/shift parameters in layer normalization, a technique refined for ViTs in diffusion models.
The contributions of the ViT in Latte are:
- Efficient Long-Context Modeling: ViTs process all tokens simultaneously, avoiding the memory bottlenecks of 3D convolutions in U-Nets.
- High-Fidelity Synthesis: Achieves state-of-the-art FVD scores on FaceForensics (27.08) and UCF101 (333.61) by leveraging ViTs' ability to model intricate spatio-temporal relationships.
- Scalability: Larger ViT architectures (e.g., Latte-XL with 673M params) show linear quality improvements, a hallmark of transformer scalability.

Recent Advancements in ViTs
ViTs have rapidly evolved over the past few years, with research focusing on making them more efficient, lightweight, and adaptable through innovative self-supervised learning techniques.
Modern ViTs are increasingly integrated into multimodal systems, combining vision, language, and audio for tasks like visual question answering and interactive image generation. Adaptive architectures now dynamically allocate computational resources based on the complexity of different image regions, optimizing both efficiency and effectiveness.
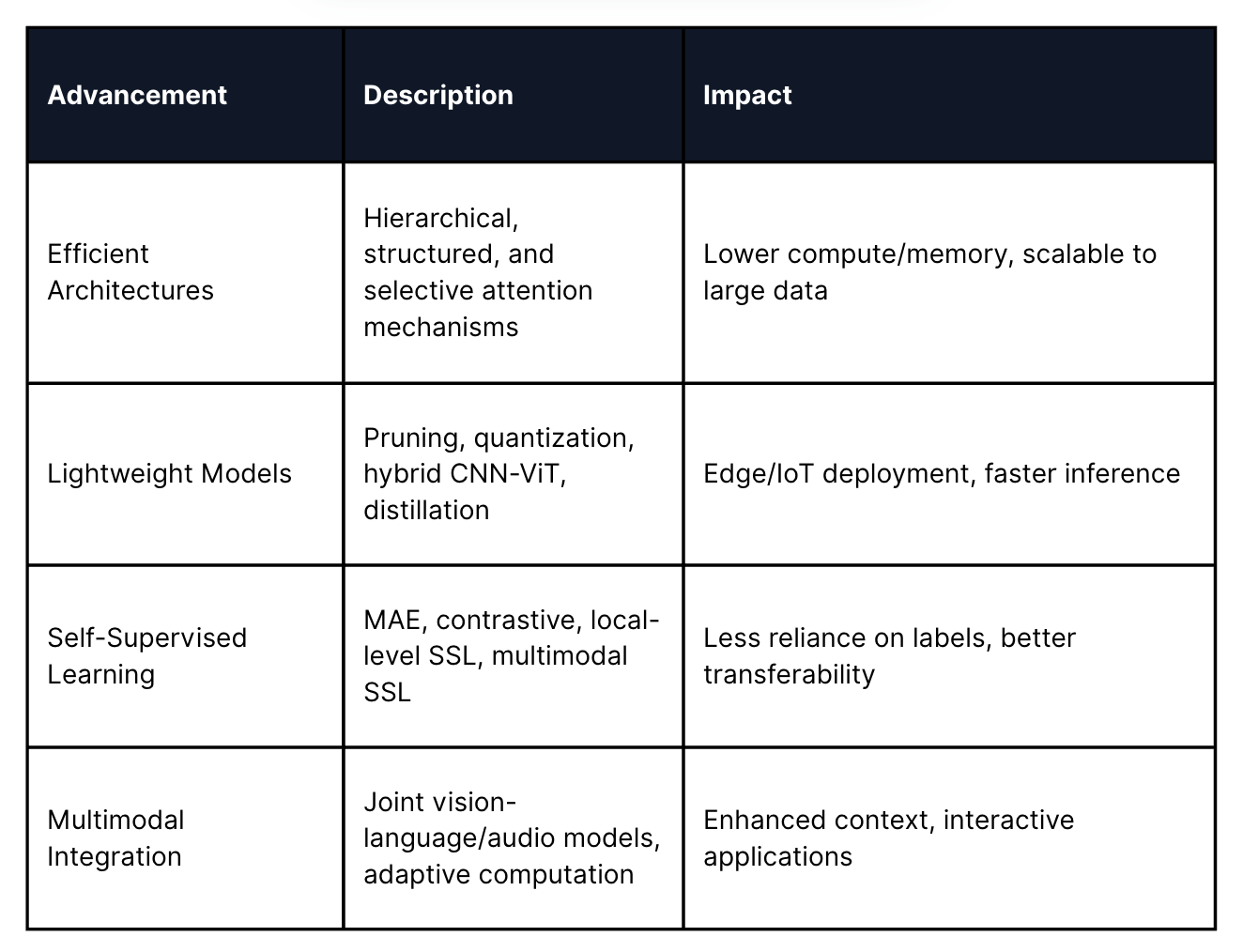
Here’s a look at the most significant advancements shaping the ViT landscape.
Efficient Architectures
The original ViT models were computationally intensive and required vast datasets for pre-training. Recent years have seen a surge in efficient architectures like Swin Transformer, which introduced a hierarchical structure and shifted windows to reduce computational cost while maintaining strong performance on dense prediction tasks such as object detection and segmentation.
Newer models have incorporated structured state-space models and selective attention mechanisms, further reducing memory and compute requirements. These advancements allow ViTs to process high-resolution images and videos more effectively, making them practical for real-world applications that demand both speed and accuracy.
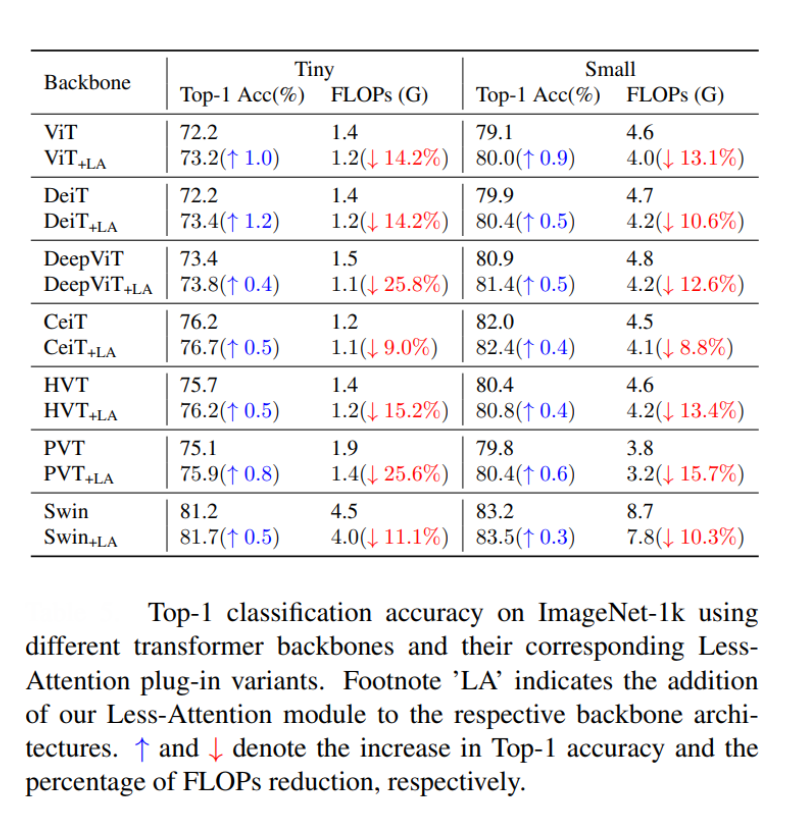
For example, LaViT (CVPR 2024), instead of computing full self-attention at every layer—a process that is computationally expensive due to its quadratic complexity, calculates self-attention only in a few initial layers at each stage. Subsequent layers reuse and transform the previously computed attention scores through lightweight linear operations, significantly reducing the computational burden. Additionally, LaViT includes mechanisms to prevent attention saturation (where attention maps become redundant in deeper layers) and uses a specialized loss function to preserve the meaningful structure of attention matrices.
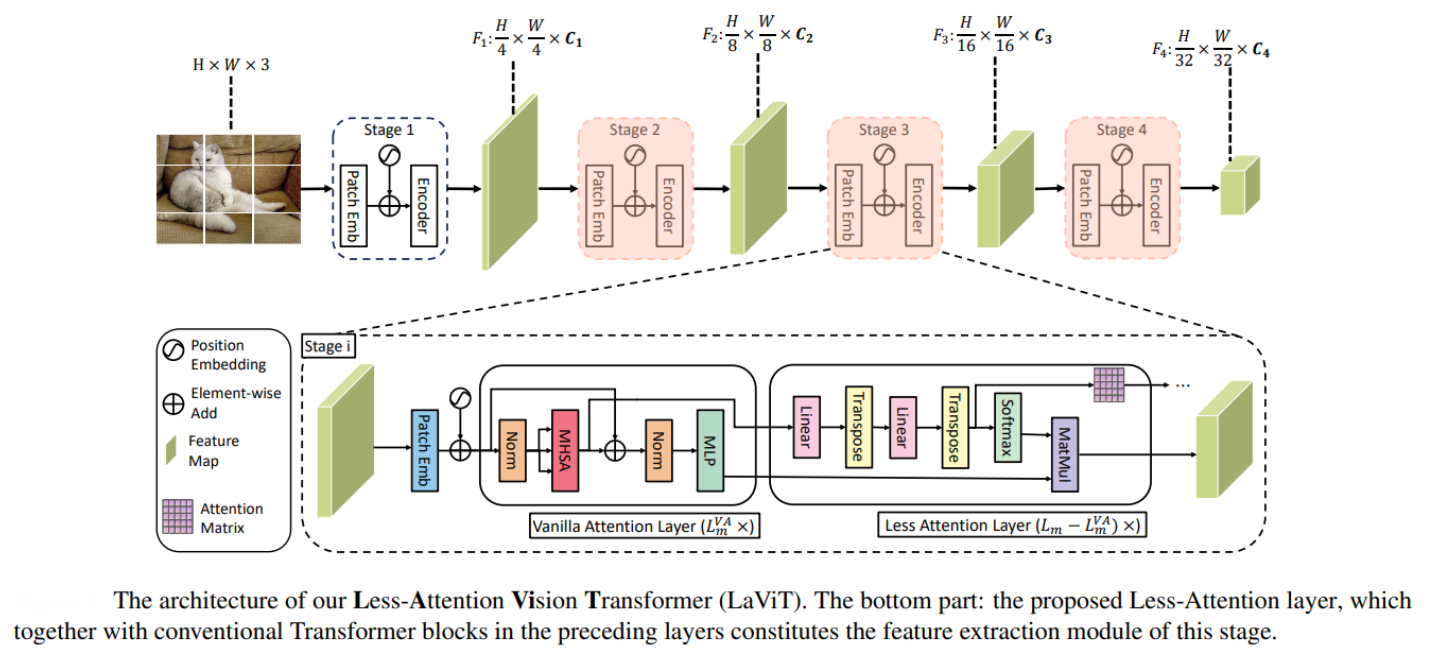
This design achieves state-of-the-art performance on classification, detection, and segmentation tasks, while lowering FLOPs and memory usage compared to standard and other efficient ViTs, making ViTs more practical for real-world applications and deployment on resource-constrained devices.
Lightweight Models
The push for lightweight ViTs has led to the development of models that leverage pruning, quantization, and low-rank approximations. These techniques reduce the number of parameters and computational overhead without sacrificing accuracy, enabling deployment on edge devices and in resource-constrained environments.
Hybrid models that combine the strengths of convolutional layers (for local feature extraction) with ViT’s global reasoning have become increasingly popular. This approach preserves efficiency while enhancing the model’s ability to capture both fine and broad visual patterns. Knowledge distillation and hardware-aware training strategies are also being used to produce compact ViT models suitable for mobile and IoT platforms
DC-AE or Deep Compression Autoencoder (ICLR 2025) developed a framework to make ViTs lightweight particularly in high-resolution diffusion models. DC-AE achieves this by dramatically increasing the spatial compression ratio of the autoencoder—up to 128x—which reduces the number of tokens the ViT must process. This token reduction is crucial because the computational and memory costs of ViTs scale quadratically with the number of tokens, especially for large images.
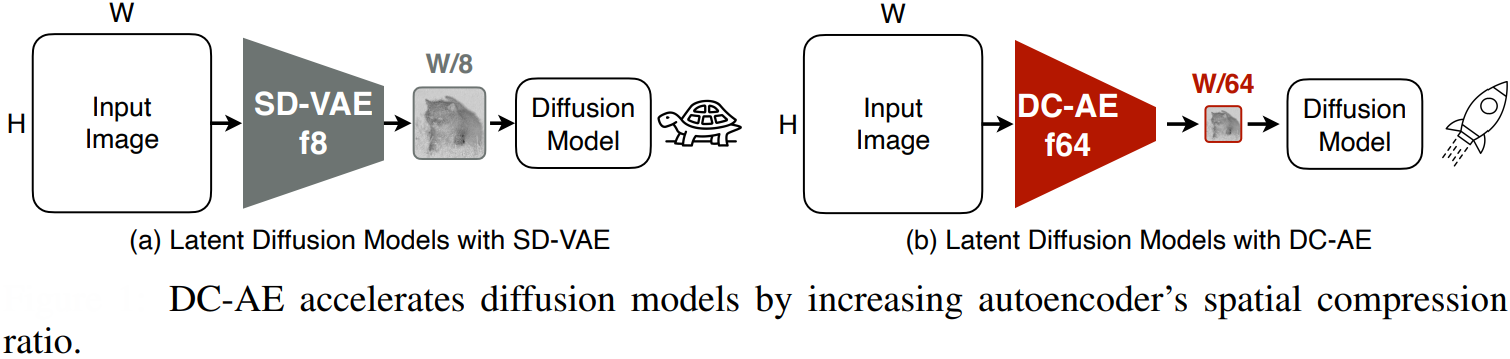
To maintain reconstruction quality at such high compression, the paper proposes two techniques: Residual Autoencoding, which eases optimization by letting the network learn residuals based on space-to-channel transformations, and Decoupled High-Resolution Adaptation, a three-phase training strategy that adapts the model to high-res data without heavy training costs or quality loss.
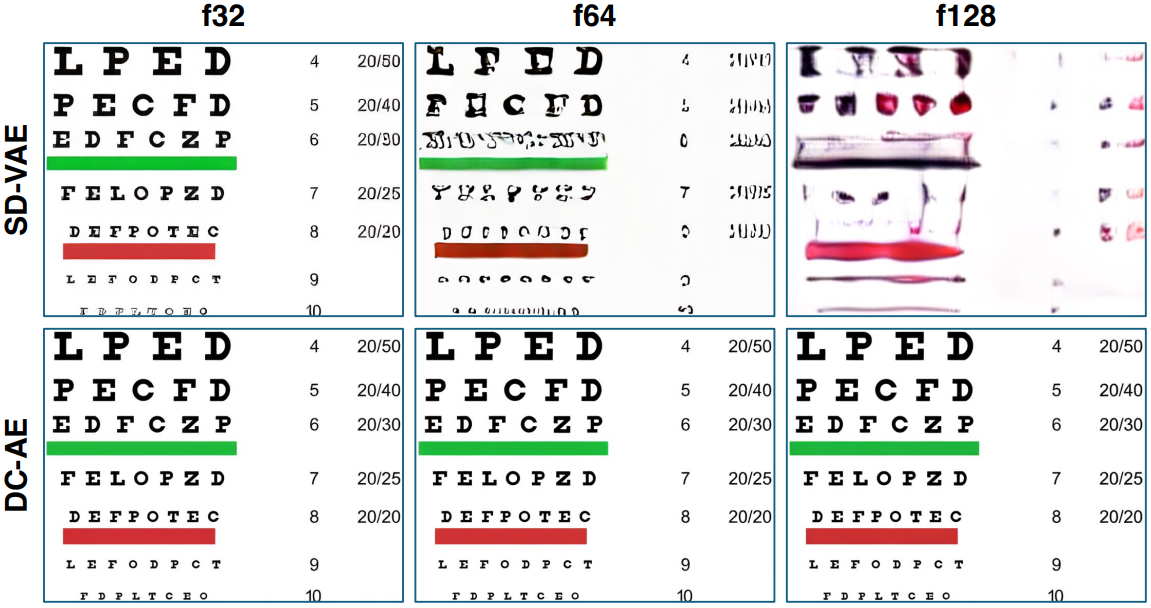
As a result, DC-AE allows ViT-based diffusion models to achieve significant speedups in both training and inference—up to 19× faster—while using much less memory, all without sacrificing image quality. This makes ViTs far more practical for high-resolution and resource-constrained applications.

Self-Supervised Learning
Self-supervised learning (SSL) has become a cornerstone of ViT research, allowing models to learn rich visual representations from unlabeled data. Methods like Masked Autoencoders (MAE) have proven especially effective—by masking a large portion of input patches and training the model to reconstruct them, ViTs can learn both global and local features without needing labeled datasets.
Contrastive learning and multi-modal approaches, such as CLIP, have further enhanced ViT’s ability to generalize across tasks and modalities, including vision-language alignment and cross-modal retrieval. Recent SSL techniques focus on local-level feature learning, improving ViT’s transferability to downstream tasks like object detection and segmentation, where fine-grained understanding is crucial.
For example, MAViL by Facebook AI Research (NeurIPS 2023) revolutionizes self-supervised learning by unifying masked autoencoding (MAE), contrastive learning, and self-training to learn robust audio-visual representations. Unlike traditional methods, MAViL processes audio spectrograms and video frames as patch sequences, using a fusion encoder to integrate cross-modal context.
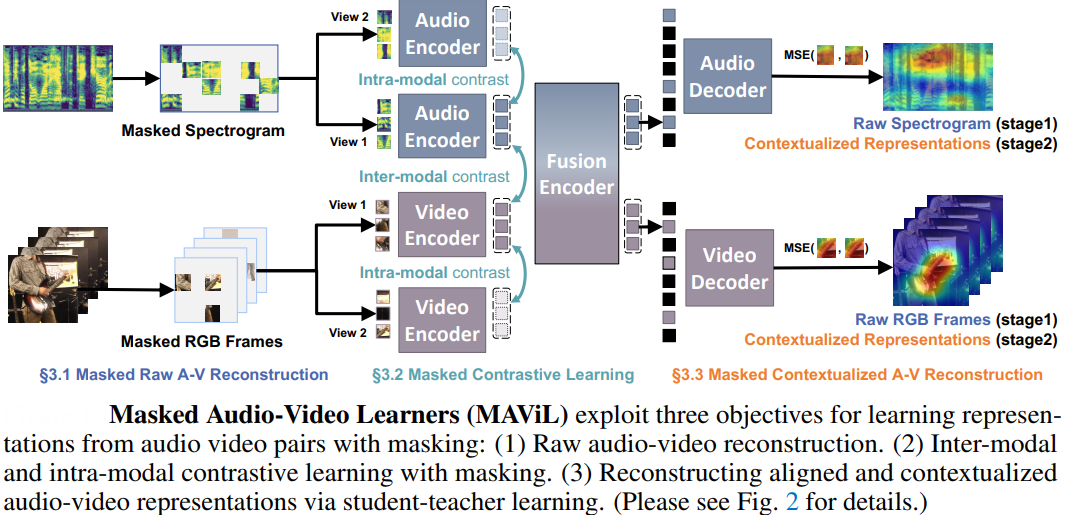
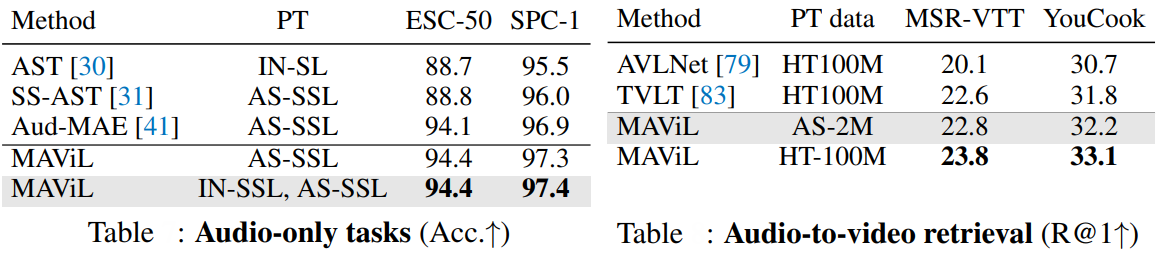
Key innovations include reconstructing aligned, contextualized representations via a two-stage self-training process (where a teacher model guides masked student inputs) and masked contrastive learning that preserves efficiency by operating on 20% visible tokens. This approach captures both local and global dependencies, enabling MAViL to outperform prior models on audio-video classification (53.3 mAP on AudioSet, 67.1% accuracy on VGGSound) and retrieval tasks, while excelling in audio-only scenarios (94.4% accuracy on ESC-50).
Vision Transformers' Challenges and Limitations
While Vision Transformers have opened new horizons in visual understanding, their widespread adoption is tempered by some challenges which researchers are trying to actively address:
- Data Hunger: ViTs are highly data-hungry, often requiring massive datasets—sometimes exceeding 14 million images—for optimal performance. Unlike convolutional neural networks (CNNs), which can generalize well from smaller datasets due to their strong inductive biases, ViTs rely on learning most visual priors directly from data. This makes them prone to overfitting or subpar results when annotated data is limited, especially in specialized domains like medical imaging or remote sensing.
- Interpretability: The interpretability of ViTs remains a significant hurdle. Their decision-making process, governed by complex self-attention mechanisms, is less transparent compared to the feature maps and filters of CNNs. Attention maps in ViTs can be difficult to analyze and do not always offer clear explanations for model predictions, making it challenging to build trust in sensitive applications such as healthcare or autonomous driving.
- Hardware Demands: ViTs are computationally intensive, particularly when handling high-resolution images or long sequences of patches. The self-attention mechanism’s quadratic complexity with respect to the number of tokens leads to high GPU memory usage and increased inference times. This poses challenges for deploying ViTs on resource-constrained devices or in real-time scenarios, often necessitating specialized hardware or algorithmic optimizations to make them practical.
- Sensitivity to Spatial Transformations: ViTs can be less robust to spatial transformations (such as rotation or mirroring) unless explicitly trained for such invariances. Unlike CNNs, which inherently encode translation invariance, ViTs may struggle with out-of-distribution visual changes, impacting their generalization in dynamic environments.
- Local Structure and Texture Representation: While ViTs excel at capturing global context, they may overlook fine-grained local textures and high-frequency details, which are crucial for tasks like medical diagnosis or texture-based classification. This limitation can lead to distorted or less detailed outputs in image generation and restoration tasks.
- Training Complexity and Stability: Training ViTs can be more challenging compared to CNNs, requiring careful tuning of hyperparameters, larger batch sizes, and longer training times to achieve convergence and stability.
Vision Transformers in Computer Vision
ViTs have rapidly transformed the landscape of computer vision, offering a flexible and powerful alternative to traditional convolutional architectures. Their ability to model global dependencies, adapt across modalities, and scale with data has led to breakthroughs in image classification, video synthesis, medical imaging, autonomous driving, and 3D vision. Recent advancements—such as efficient and lightweight architectures, self-supervised learning strategies, and multimodal integration—have further extended their reach, making ViTs practical for both large-scale applications.
However, the journey is not without challenges. ViTs’ appetite for massive datasets, high computational demands, and interpretability hurdles remain active areas of research. Yet, as demonstrated by cutting-edge frameworks like MAViL, which unifies masked auto-encoding and contrastive learning for robust audio-visual representation, the field is innovating rapidly to overcome these barriers. As ViTs continue to evolve, they are poised to become foundational models for visual understanding, powering the next generation of intelligent systems across industries.
With Roboflow’s end-to-end platform, you can upload and preprocess your vision datasets in minutes; train state-of-the-art models (including Vision Transformers) with one click; deploy to the edge, cloud, or browser with flexible, production-ready options; and monitor and improve model performance over time. Whether you’re building a custom classification model, object detector, or segmentation pipeline, Roboflow abstracts the infrastructure so you can focus on results. Try training your first Vision Transformer with Roboflow for free.
Written by Rohit Kundu (he/him/his), a Ph.D. candidate at the University of California, Riverside working in the Vision and Learning Group headed by Prof. Amit K. Roy-Chowdhury, and at Google LLC (YouTube) as a Student Researcher since June 2024 at Mountain View, CA.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Apr 17, 2025). Comprehensive Guide to Vision Transformers. Roboflow Blog: https://blog.roboflow.com/vision-transformers/