
Computer vision is no longer just about drawing boxes; it’s about having a conversation with your data. A Vision-Language Model (VLM) is the powerhouse at the intersection of pixels and words, allowing you to bridge the gap between computer vision and natural language processing.
Unlike traditional models that only "see" or "read" in isolation, VLMs are native multimodal learners that process images, video, and text simultaneously to understand the world the way we do. Whether you’re building a visual assistant that can "describe what’s happening in this frame" or an agent that searches your video library using natural language, VLMs are the "easy button" for making your vision applications smarter, faster, and more intuitive.
Test and compare multimodal models for free on Roboflow Playground.

How VLMs Actually Work
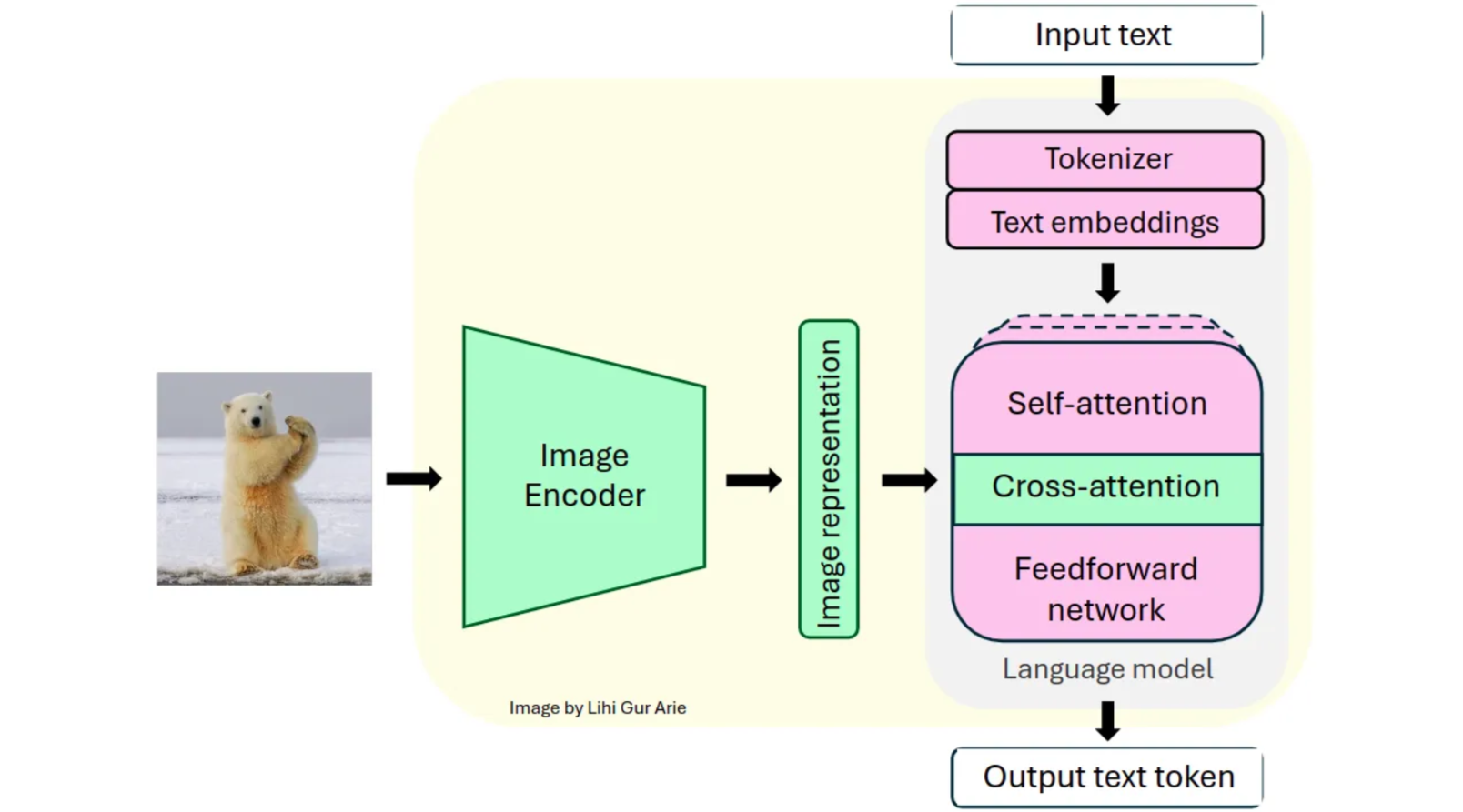
Think of a VLM as a bridge between two different worlds: the grid-like reality of pixels and the sequential logic of language. To make this work, the model has to translate both into a "shared language" it can understand.
Here’s the breakdown of the four main components that make the magic happen:
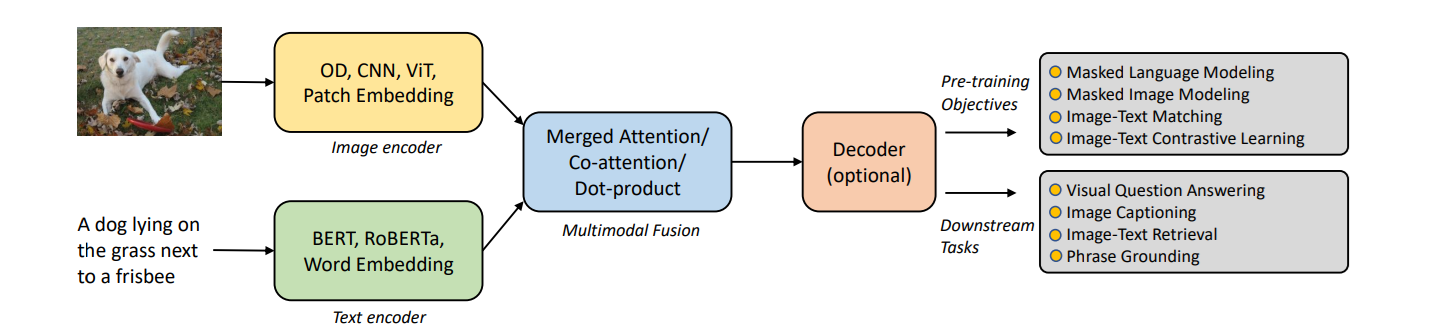
1. Image Encoder
The vision encoder takes raw pixels and compresses them into embeddings - mathematical representations of what’s happening in the frame. We usually see this handled in one of three ways:
Vision Transformers (ViT): ViTs break an image into a sequence of patches (like a grid), allowing the model to understand global context and how distant parts of an image relate to each other.
Object Detector (OD): These focus on "where" and "what" by generating region-based embeddings. This is crucial when the model needs to understand spatial relationships (e.g., "the cup on the table").
Convolutional Neural Networks (CNN): CNNs are the classic backbone. These use layers to extract hierarchical features, moving from simple edges to complex shapes.
2. Text Encoder
The text encoder takes your prompt and turns it into a sequence of vectors. It doesn't just look at words; it captures semantics and context, ensuring the model knows the difference between a "bank" of a river and a "bank" where you keep your money.
Multimodal Fusion
Fusion is where the model finally maps the image embeddings and text embeddings into a single, unified space. It uses these mechanisms to align them:
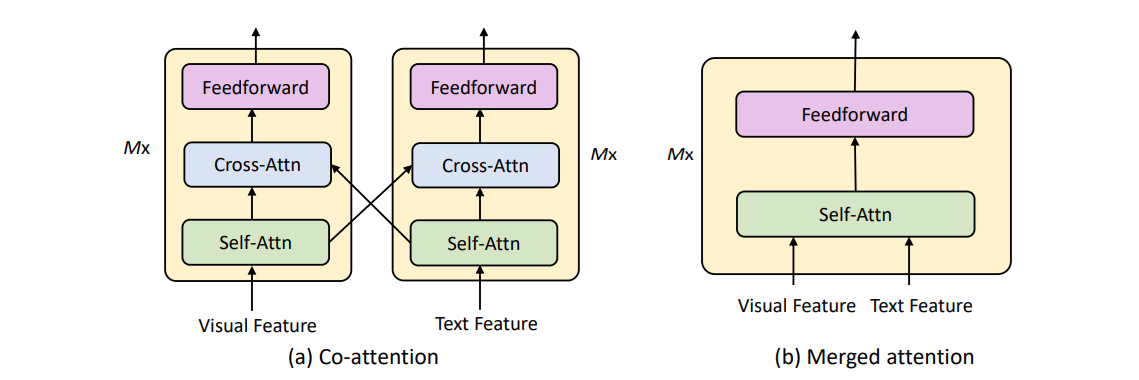
Merged Attention: The model looks at the image and the text simultaneously to find correlations.
Co-Attention: A two-way street where the text influences which part of the image the model focuses on, and vice versa.
Dot-Product: A similarity check often used in models like CLIP to see how well a caption matches an image in a shared "map" of concepts.
4. Decoder
The decoder is the output engine. Once the model has a fused understanding of the visual and textual data, the Decoder takes that "unified thought" and turns it into a final result: whether that’s a text description, a classification label, or coordinates for a bounding box.
Want to see these components in action? Try out our VLM Playground to see how different models interpret your images in real-time.
Explore the Best Vision-Language Models
Here are some of the best VLMs and their key capabilities. See the Roboflow Playground Model Rankings for up to date information.
1. Paligemma-2
By fusing the SigLIP-So400m vision encoder with the powerhouse Gemma 2 language model, Google has created a VLM that is as versatile as it is efficient.
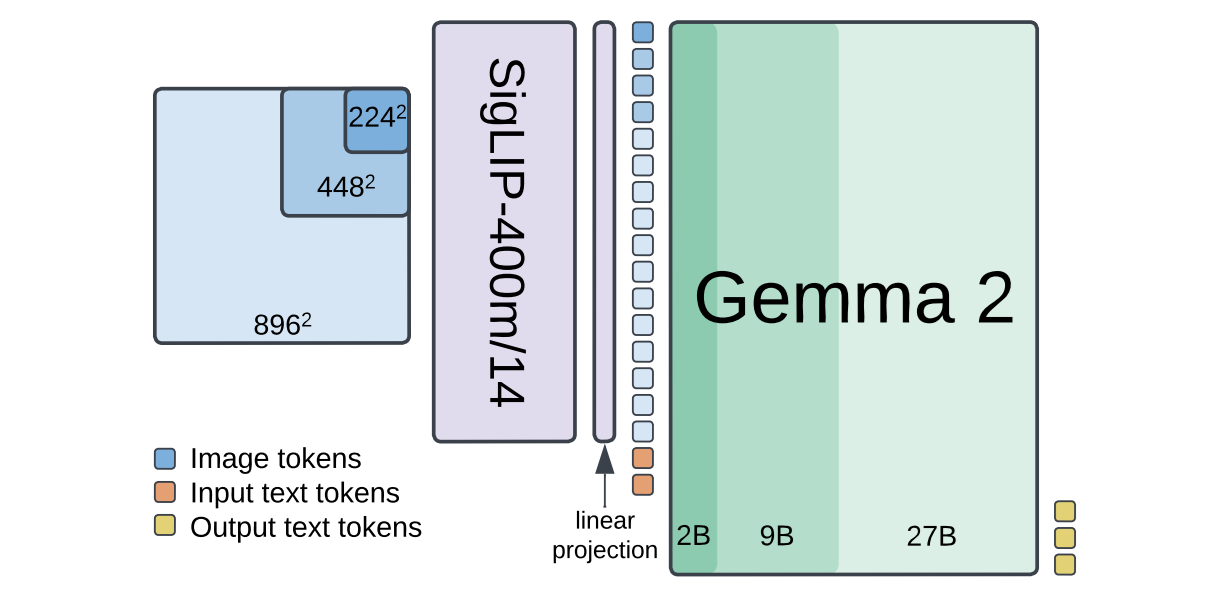
The following are the key capabilities of PaliGemma-2:
- Zero-Shot Detection & Segmentation: Want to find objects without training a custom model from scratch? PaliGemma 2 can detect and even perform instance segmentation right out of the box.
- VQA & Detailed Captioning: Ask it "What is the condition of the cargo in this image?" and get a reasoned, context-aware answer, not just a generic label.
- Specialized Domain Performance: It’s already crushing benchmarks in niche areas like chemical formula recognition, reading music scores, and even generating chest X-ray reports.
- Fine-Tuning Ready: The best part? You can fine-tune PaliGemma 2 on your own custom datasets. Whether you're working on a specific industrial inspection task or a unique retail use case, you can adapt this model to your specific downstream needs.
Ready to see PaliGemma 2 in action? Check out our PaliGemma Fine-Tuning Guide to start running it on your own data today.
2. Florence-2
Florence-2 is a vision foundation model developed by Microsoft, and built on a single, unified prompt-based architecture. Instead of switching between five different models for detection, captioning, and OCR, Florence-2 handles it all through a simple text interface.

The following are the key capabilities of Florence-2:
- Unified Prompting: Want a caption? Ask for it. Florence-2 treats vision tasks like a conversation, making it incredibly easy to integrate into automated workflows.
- Precision Object Detection: It doesn’t just see "things" - it localizes them with high-accuracy bounding boxes and labels, perfect for building quick prototypes or cleaning up datasets.
- Visual Grounding: Florence-2 can link specific phrases in a text prompt to exact regions in an image, allowing it to "point" at the objects you're describing.
- Pixel-Perfect Segmentation: Beyond just boxes, Florence-2 can outline objects down to the pixel level, providing high-fidelity masks for complex shapes.
- Deep Captioning & OCR: From summarizing a high-level scene to reading the fine print on a label, Florence-2 captures the "what" and the "why" of your visual data.
Want to see how it compares to other foundation models? Head over to the Roboflow Model Playground to compare.
3. CogVLM
CogVLM is an open-source visual language foundation model. Instead of just stitching a vision encoder onto a language model, CogVLM uses a trainable visual expert module baked directly into the transformer layers. This "deep fusion" approach means the model doesn't just see pixels, it deeply understands them without losing the power of its language backbone.
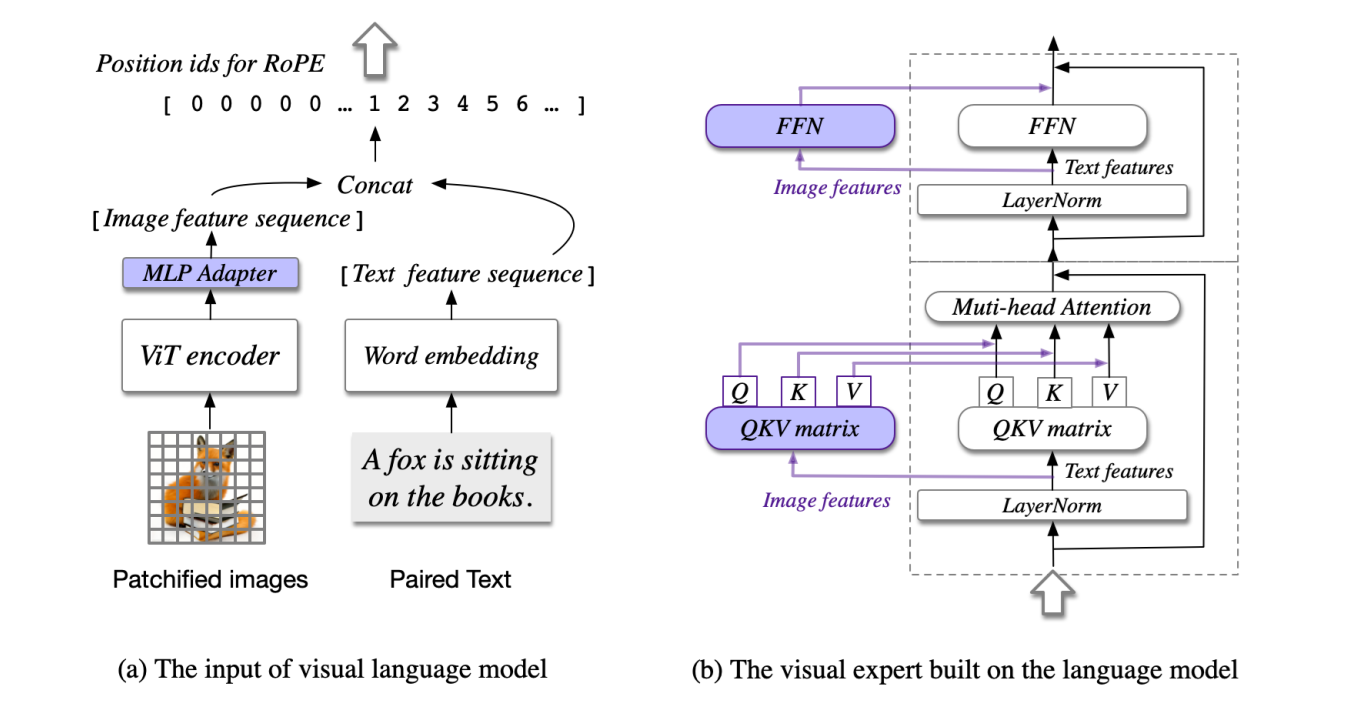
The following are the key capabilities of CogVLM.
- Visual Grounding & Coordinates: CogVLM is a pro at "pointing." It doesn't just tell you there's a person in the frame; it can provide the exact coordinates for specific attributes, like the color of a jacket or the position of a tool.
- OCR-Free Reasoning: Most models need a separate step to "read" text before they can understand it. CogVLM skips the middleman, performing reasoning directly on the visual text it sees in the image.
- Programming with Visual Input: You can show CogVLM a handwritten diagram of a linked list or a data structure, and it can generate the actual code to implement it in your language of choice.
- Chart & Math Interpretation: CogVLM can look at complex charts, mathematical notations, and data visualizations to provide logical reasoning and summaries.
- Grounding VQA: It bridges the gap between "what" and "where." If you ask, "What color is the car on the left?", it grounds the specific object before answering, ensuring way higher accuracy than standard chat models.
4. Llama 3.2-Vision
Llama3.2-Vision is a multimodal extension of Meta’s Llama family of models. By plugging a dedicated image encoder directly into the Llama backbone, Meta has created a model that can "see" without losing an ounce of its reasoning capabilities.
The following are the key capabilities of Llama3.2-Vision.
- Visual Reasoning & Scene Analysis: It understands the story in the frame. Whether you're analyzing a complex industrial site or a busy retail floor, Llama 3.2-Vision can interpret context and spatial relationships with ease.
- Master of OCR & Handwriting: From digitizing handwritten notes to transcribing printed text in high-glare photographs, this model is a powerhouse for document AI and information extraction.
- Chart & Table Interpretation: Llama 3.2-Vision can look at a complex graph or a dense table and give you a summarized, actionable report of the data.
- Context-Aware VQA: Ask it, "Why is the machine on the left showing a red light?" and it will combine visual detection with its deep knowledge base to provide an intelligent answer.
- High-Fidelity Captioning: Generate detailed, accurate descriptions for massive image datasets, perfect for searchability or accessibility at scale.
5. Qwen-VL
Qwen-VL is a large-scale vision-language model developed by Alibaba Cloud. Building upon the Qwen-LM foundation, it integrates visual capabilities through a meticulously designed architecture and training pipeline. There are different specialized variants of Qwen-VL, such as Qwen-VL, Qwen-VL-Chat, and Qwen-VL-Max.
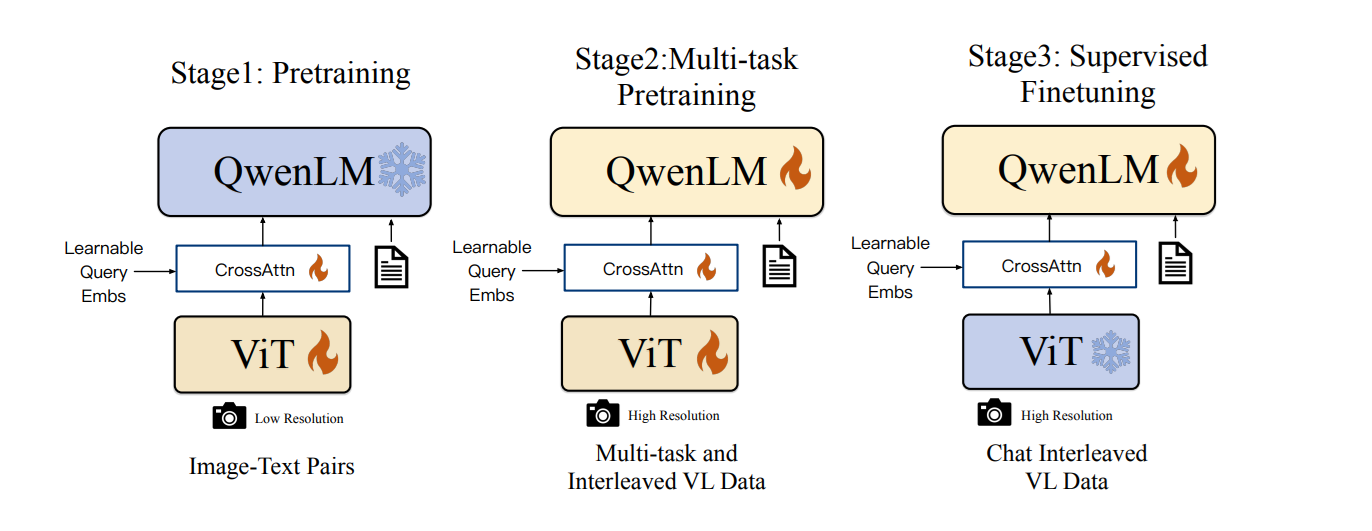
The following are the key capabilities of Qwen-VL:
- Precision Visual Grounding: You can pass it a text phrase, and it will return the exact bounding box and label for that object.
- Next-Gen OCR & Document AI: Qwen-VL understands text layout. It can extract data from dense tables, complex documents, and multi-step flowcharts with ease.
- Native Multilingual Support: Built with a global mindset, Qwen-VL handles English, Chinese, and bilingual text within a single image. It’s a game-changer for international logistics and document processing.
- Advanced Logic & Symbolic Reasoning: Show it a mathematical formula, a circuit diagram, or a symbolic system, and Qwen-VL will solve the problem.
- Scene & Landmark Intel: From identifying common household objects to recognizing celebrities and global landmarks, the model’s broad internal knowledge makes it an incredible tool for content moderation and search.
Vision Language Model Use Cases
Let's explore the different computer vision tasks VLMs can complete. We will use two popular VLMs: Meta Llama 3.2V and Google Gemini and Roboflow Workflows.
Image Classification Example
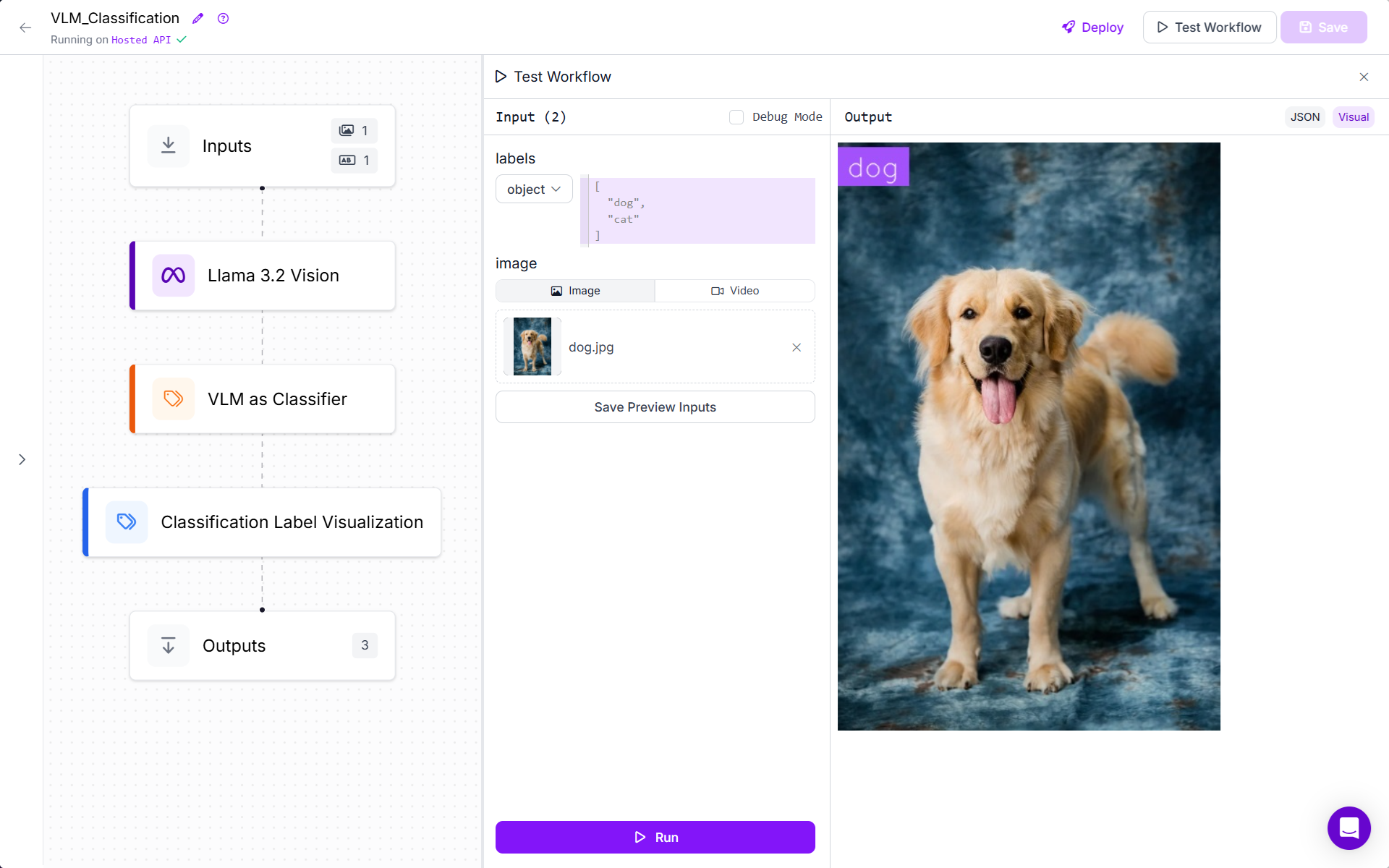
Image classification is the fundamental task in computer vision. It is like giving model a photo and asking "What is this?" The model analyzes the image and assigns it to one or more predefined categories. For example, when shown a photo of a golden retriever, the model would classify it as "dog" or more specifically "golden retriever." This is a basic task and forms the basis for more complex visual understanding tasks. We can build an image classification application with Roboflow Workflow without writing code.
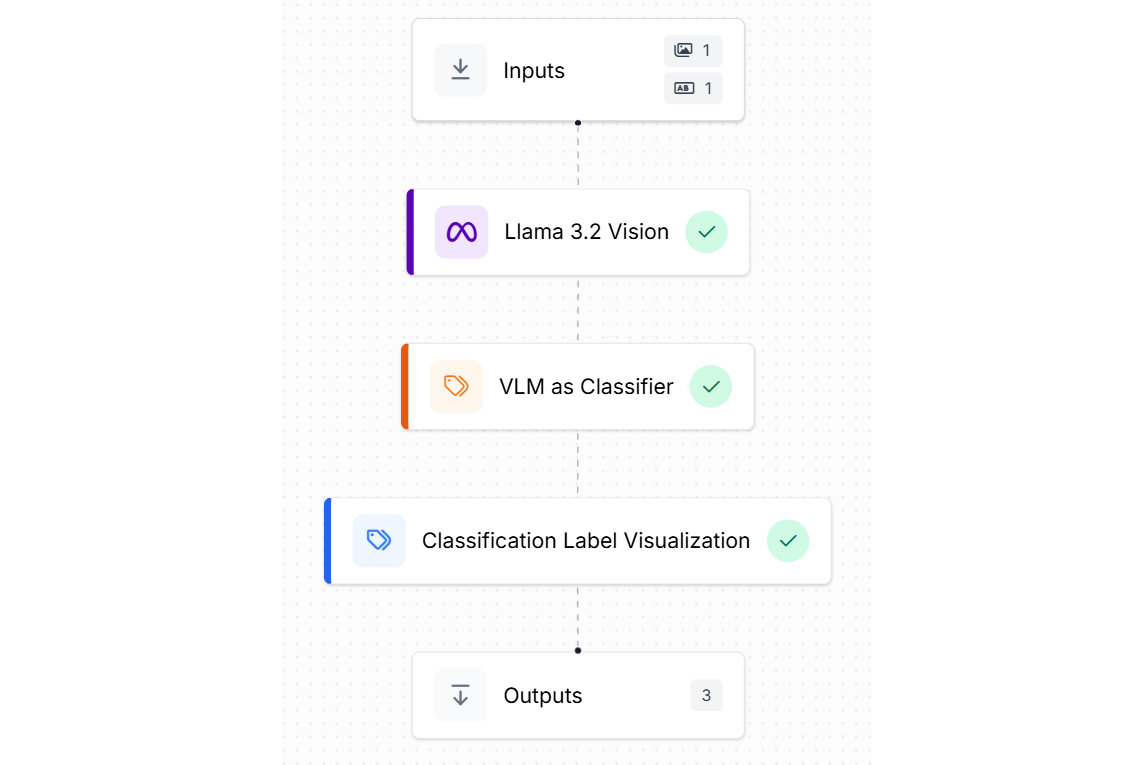
To do this create a new workflow, and add Llama 3.2 Vision, VLM as Classifier and Classification Label Visualization Blocks to it as shown below.
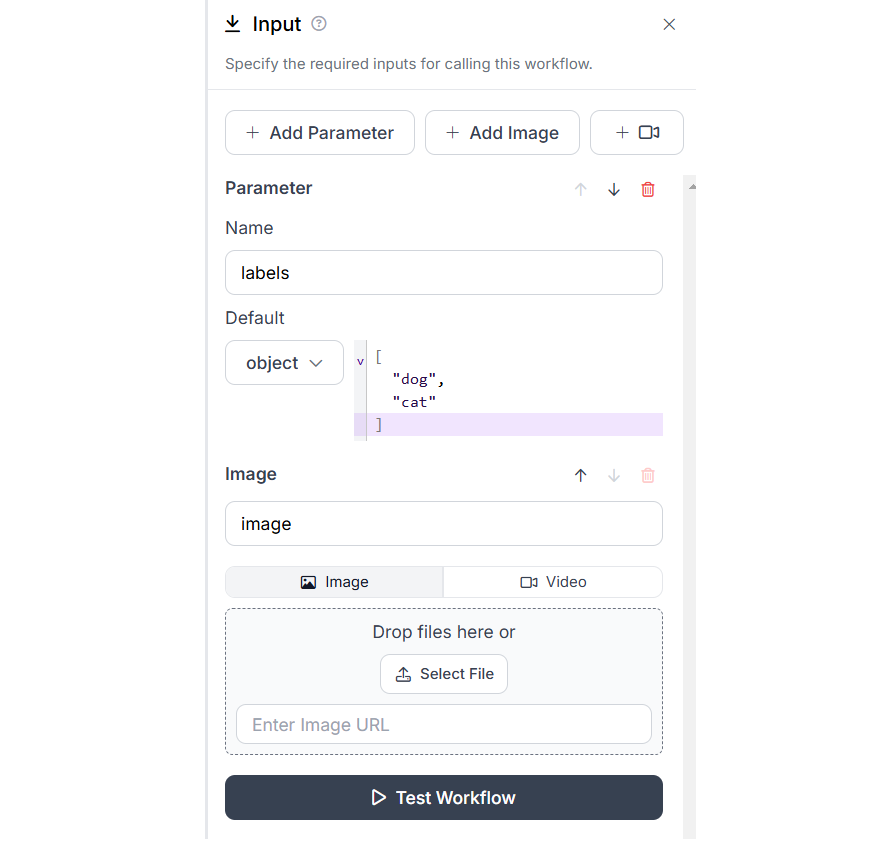
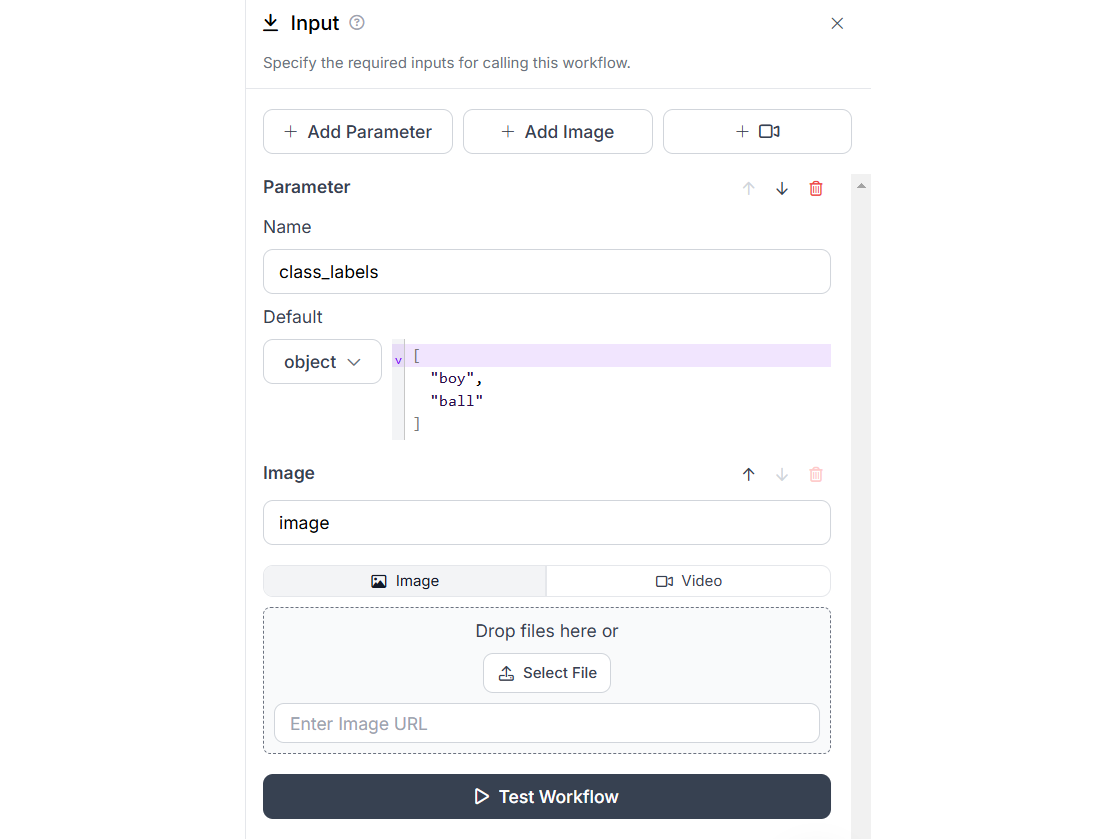
Now we will see the configurations for each blocks. The Input block should be configured to accept class labels in the “labels” parameter and image in the “image”. I have also specified the two default classes in my “labels” parameter as a python List object.
Next you need to configure Llama 3.2 Vision block. In this block specify task type as “Single-Label Classification”, the classes field should be bind with “labels” parameter that we have specified in the input block in above step. Specify you Llama Vision API key obtained from OpenRouter. The Llama 3.2 Vision block must look like following.
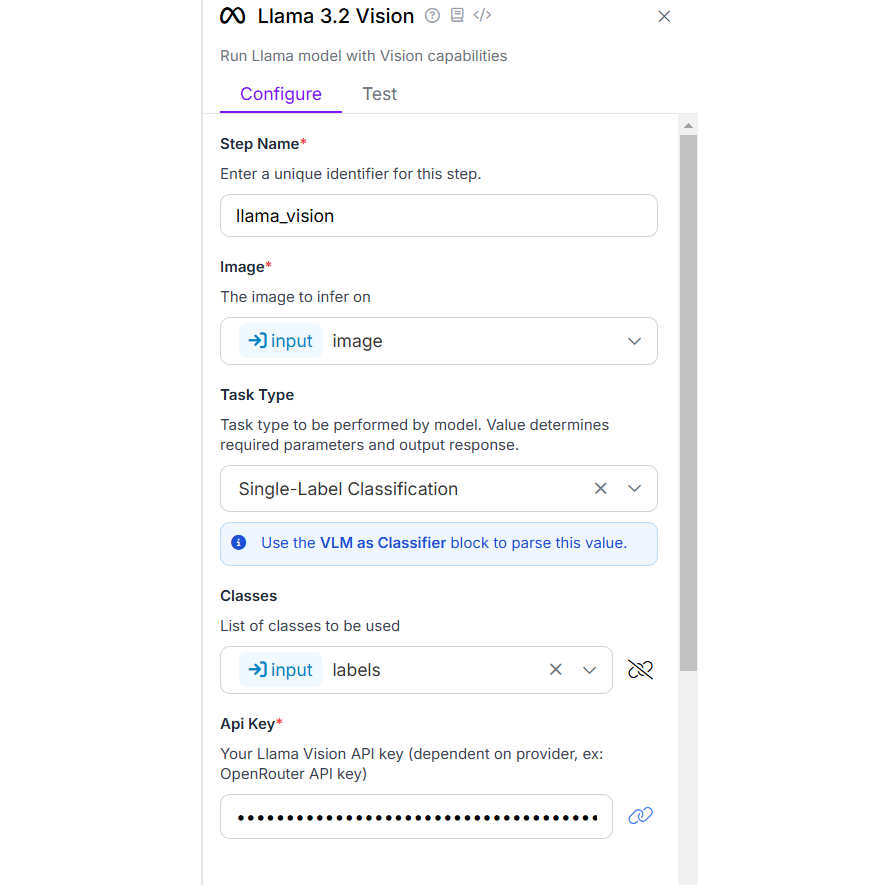
The next block is VLM as Classifier block. This block gets string input from our Llama 3.2 Vision block. Input is then parsed to classification prediction and returned as block output. Following is the configuration for this block.
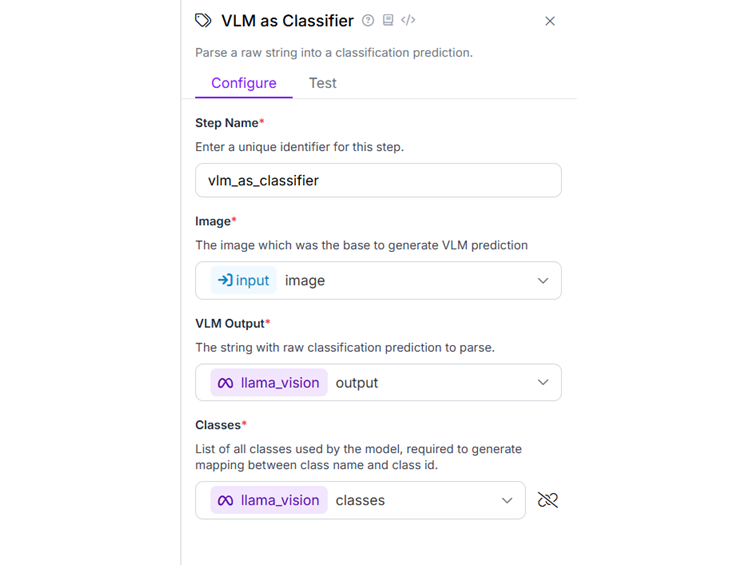
Now, configure the Classification Label Visualization block. This block visualize both single-label and multi-label classification predictions with customizable display options. Use following configurations and keep other default.
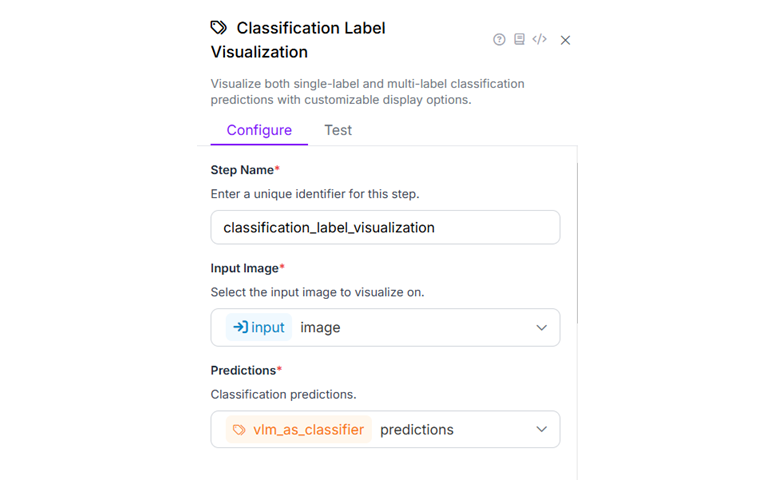
Finally, the Output block should look like following.
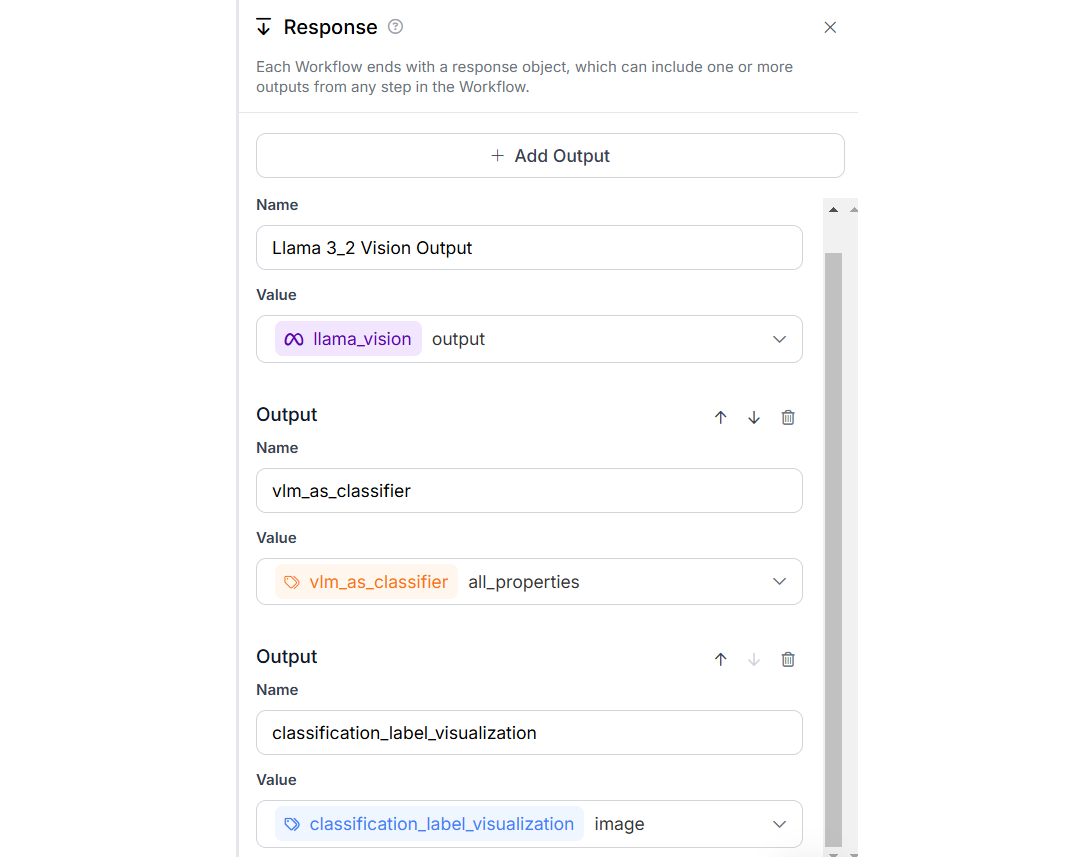
Here is the output after running Workflow. I have uploaded image of a “dog” and it was classified as “dog” with high confidence. You can try with any other image and specifying the new class labels. In the output from this Workflow, you will see image with classification label.
Object Detection Example
Object detection takes classification a step further by not only identifying what objects are present but also locating them within the image. The model draws bounding boxes around the detected objects and also provides labels to each detection.
To showcase object detection using a VLM, we will use the Google Gemini model with Roboflow Workflows, as such:
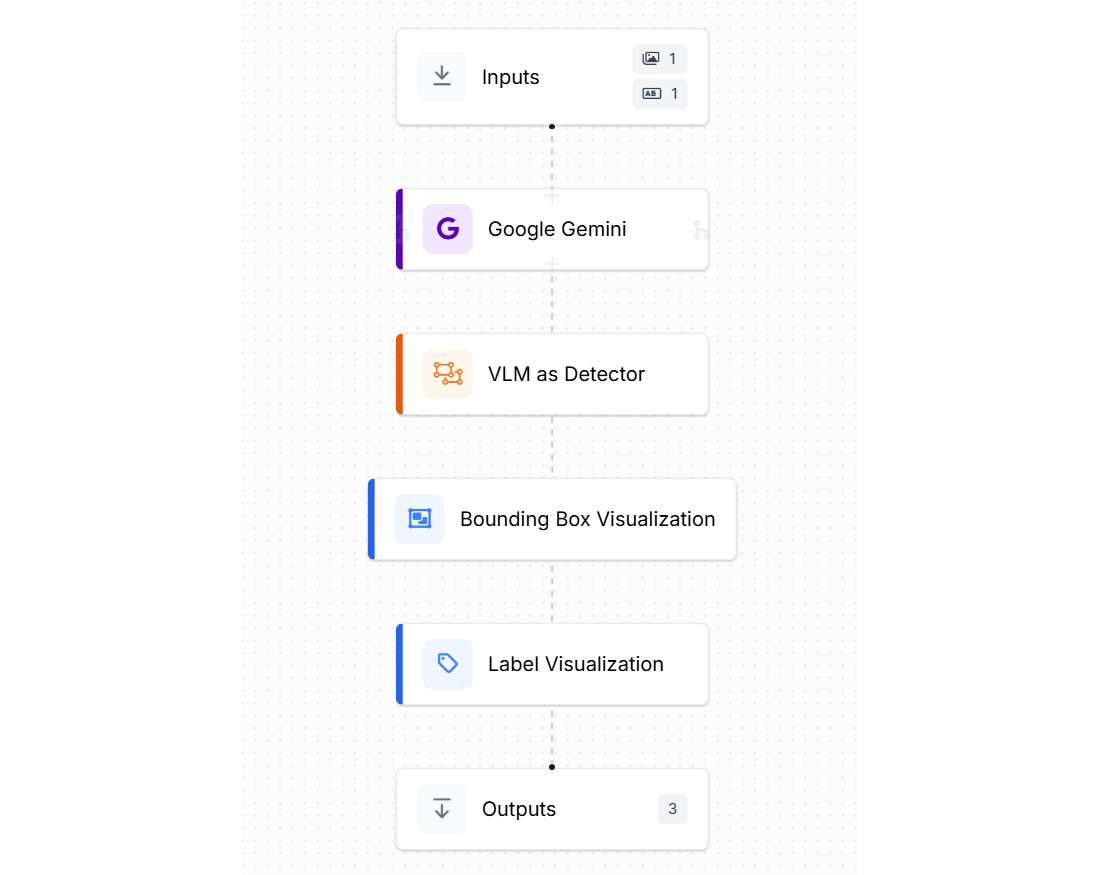
The input block is similar to the above example with class labels and image upload.
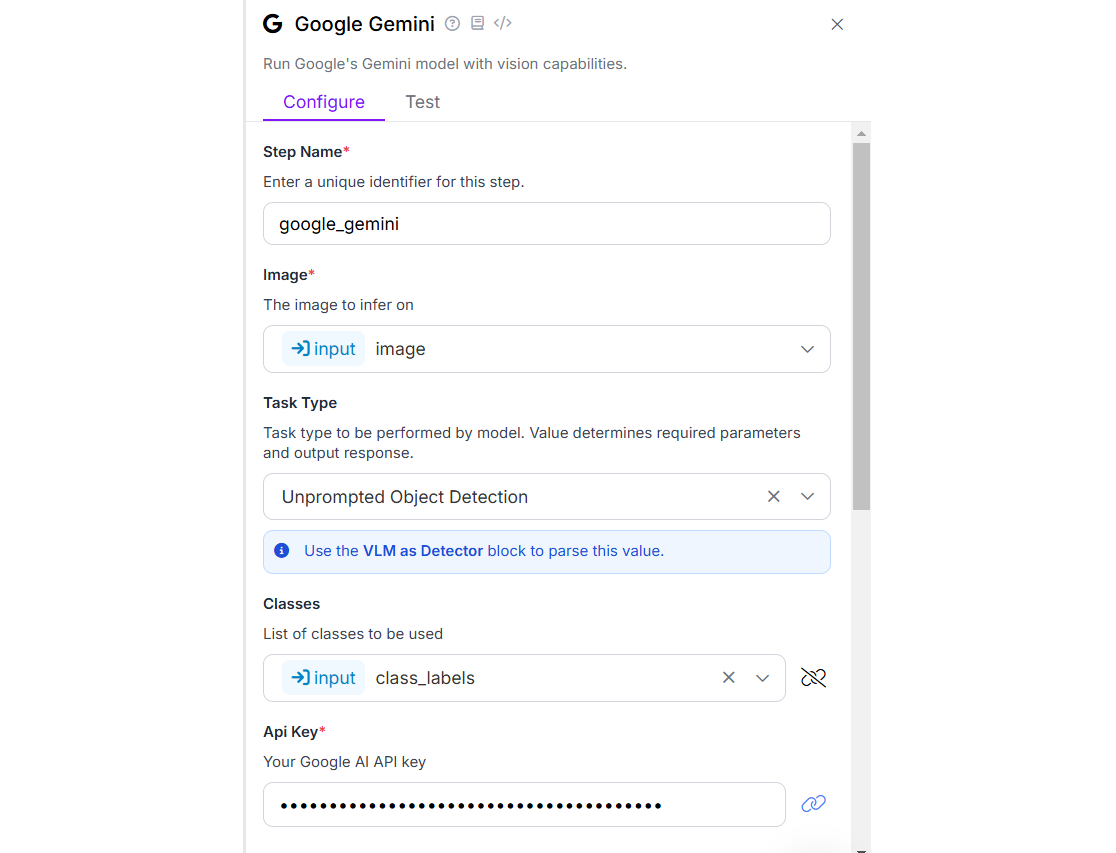
Add the Google Gemini, VLM as Detector and Label Visualization and Bounding Box Visualization blocks to your workflow. We will use Google Gemini for the task type “Unprompted Object Detection” as we want to detect the object by specifying class labels only in input block. Here is the configuration for Google Gemini block.
Now configure Bounding Box Visualization block as shown below.
Also configure Label Visualization block after that to display labels with bounding boxes in the output image.
Finally, the output block should look like following.
When you run this workflow, you will see following output.
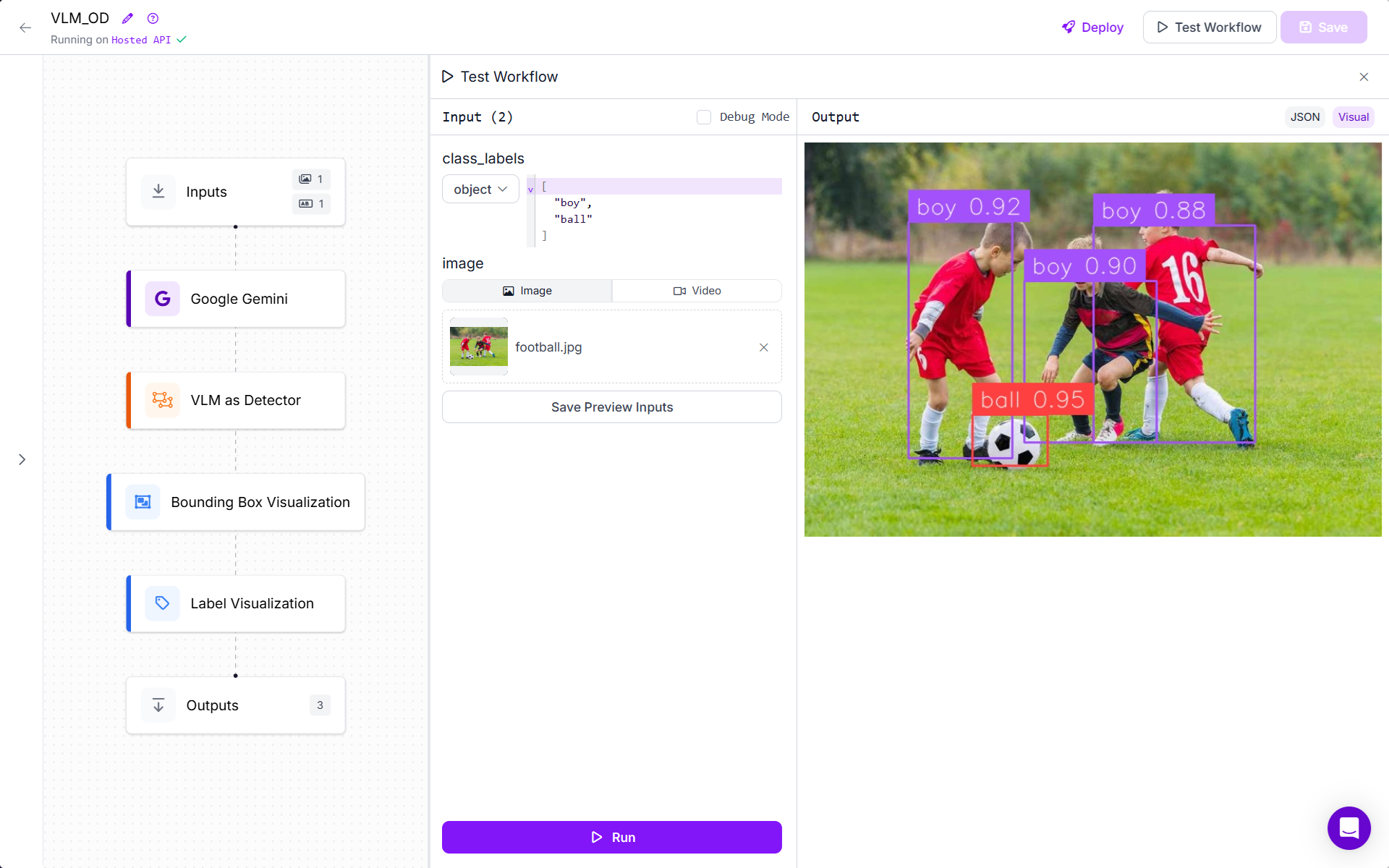
Image Captioning Example
Image captioning is the task of generating a textual description of an image. The model generates a descriptive sentence about what it sees in an image. For example, given a park photo, it might generate "A young family is having a picnic under a large oak tree on a sunny day." This requires not just identifying objects but understanding their relationships and context to create coherent, meaningful descriptions.
For our example we will create image captioning workflow using Llama 3.2 Vision block. Configure “Task Type” as “Captioning (Short)” or “Captioning” in the Llama 3.2 Vision block. When you run the workflow, you will see the following output.

Visual Question Answering (VQA)
Visual Question Answering (VQA) represents a more interactive form of image understanding. The model must answer specific questions about an image, requiring it to understand both the visual content and natural language queries. For instance, given an image of a kitchen and the question "What color is the refrigerator?", the model needs to locate the refrigerator, identify its color, and formulate an answer. This demonstrates a deeper level of image comprehension and reasoning.
For our example we will create a VAQ Workflow using Llama 3.2 Vision block. First configure the input block with parameter “question” and image input.
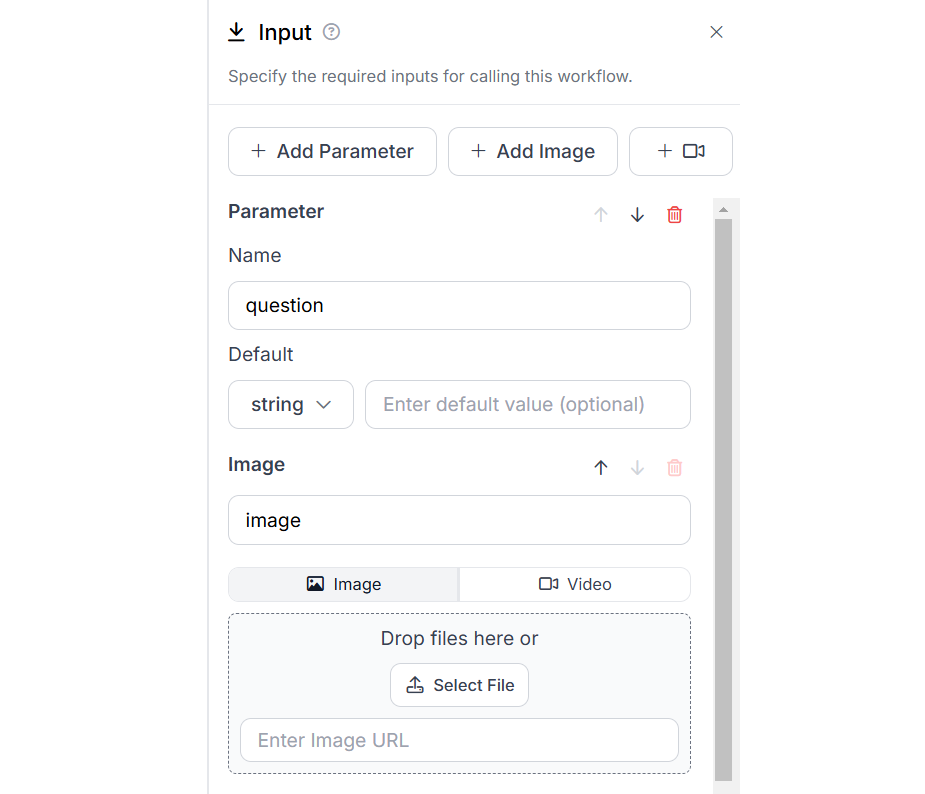
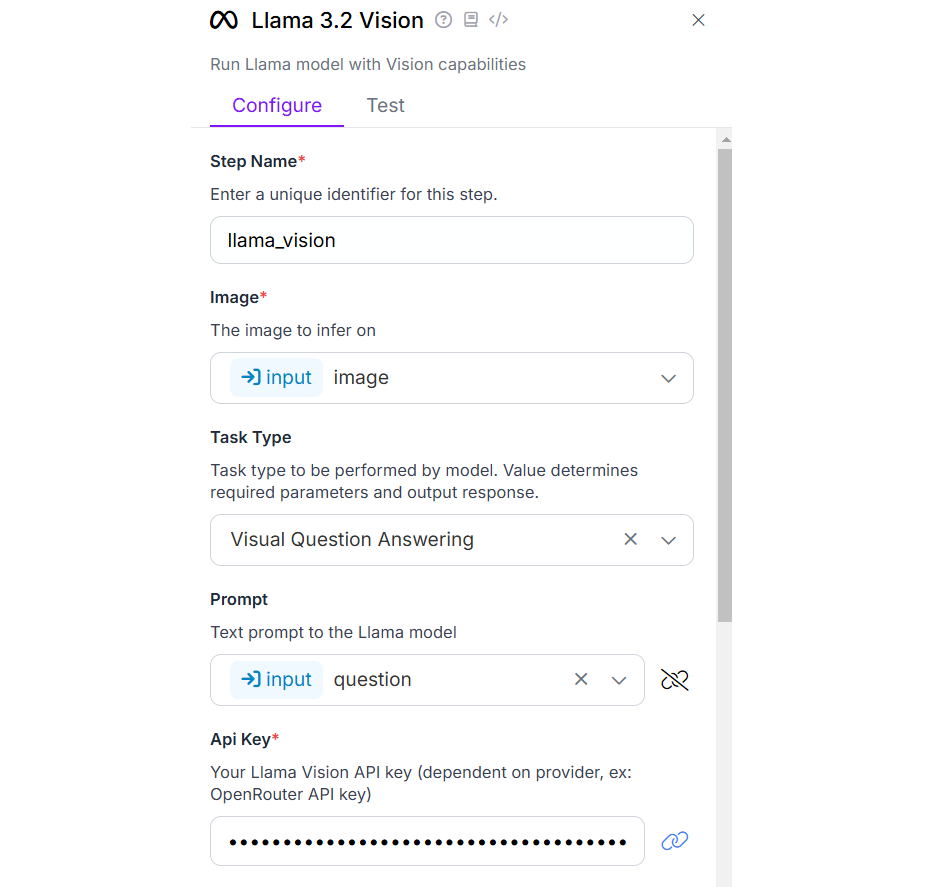
Then add Llama 3.2 Vision block and configure it with task type as “Visual Question Answering” and bind the prompt field with the “question” parameter.
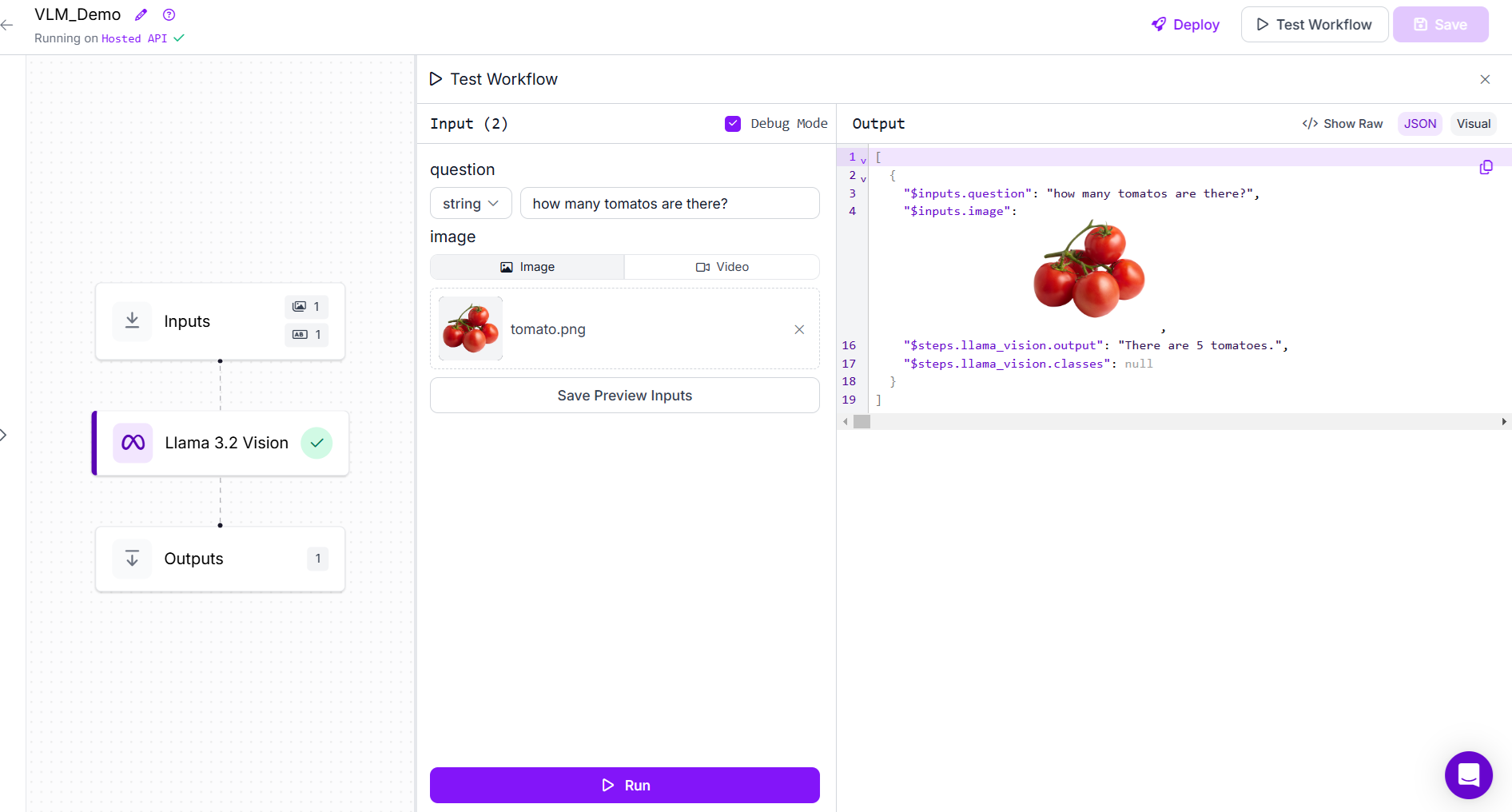
Run the Workflow, add question and upload the image. You will see the following output.
Text Recognition (OCR)
Text Recognition, often called Optical Character Recognition (OCR), is the process of detecting and converting text within images into machine-readable text. Read the blog What is OCR Data Extraction? to learn how to extract text from image using VLM.
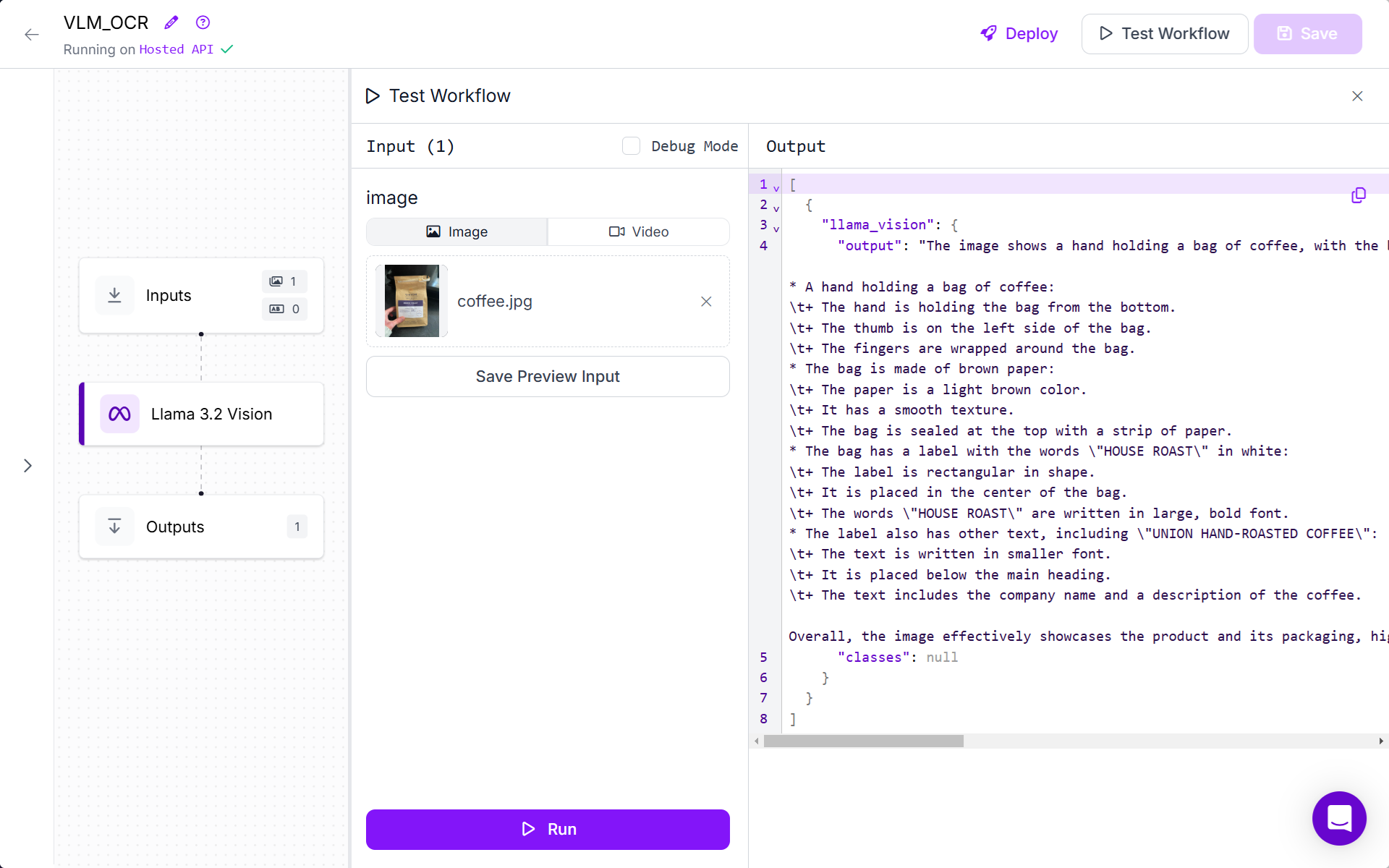
For our example we will create a Text Recognition (OCR) Workflow using Llama 3.2 Vision block. Configure “Task Type” as “Text Recognition (OCR)” in the Llama 3.2 Vision block. When you run the workflow, you will see the following output.
When and Why Should You Fine-Tune a Vision-Language Model?
In the initial phase, known as pre-training, a VLM is trained on large datasets that include both images and text. The goal here is to learn general representations that capture broad relationships between visual and textual data. For example, models like Paligemma-2 learn to align images and their corresponding captions by maximizing similarity between matching pairs.
Fine-tuning a Visual-Language Model (VLM) refers to the process of taking a model that has been pre-trained on large, general datasets and adapting it to perform a specific task or to work well in a particular domain. This process involves training (or “tuning”) the pre-trained model on a smaller, task-specific dataset, allowing the model to adjust its parameters so that it can handle the new task more effectively.
So, after pre-training, the model is further trained on a smaller, task-specific dataset. Fine-tuning adjusts the learned representations to improve some target task, such as image captioning, VQA, or even specialized tasks in specific domains like medical imaging or satellite imagery etc.
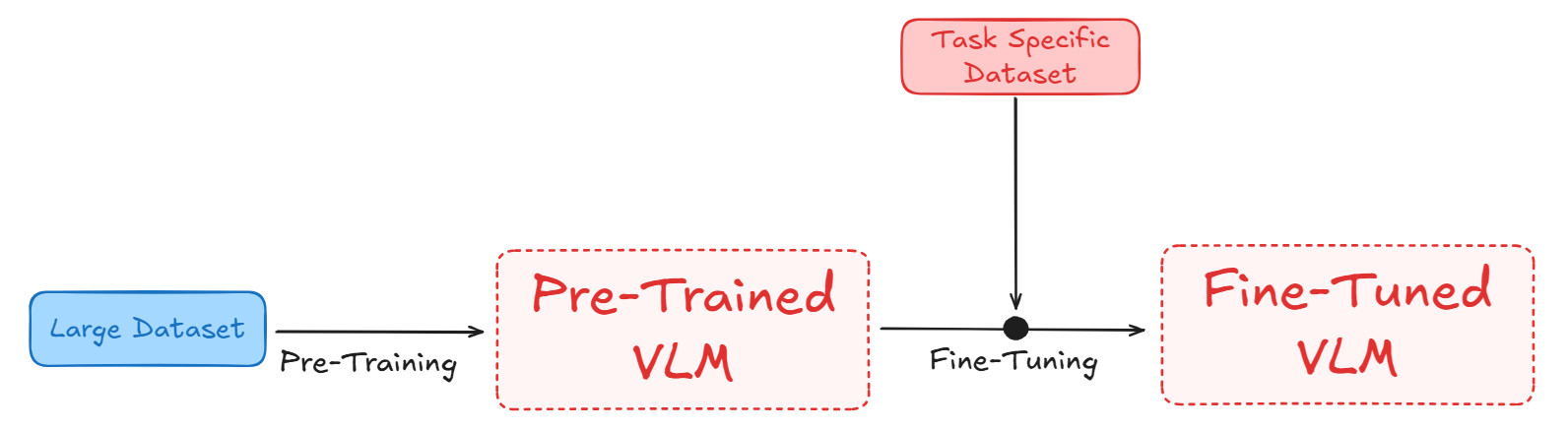
Fine-Tuning VLM may be required for various reasons such as following:
Domain Adaptation
Domain adaptation is about adjusting a pre-trained model to work well in a new, specialized area (domain) where the data is different from what the model was originally trained on. This is important because different domains often have unique characteristics, like specific words, phrases, or visual styles. For example, in industrial settings, a general model may struggle to detect machine defects, but fine-tuning it with factory-specific images improves its detection capabilities.
Task-Specific Performance
Fine-tuning helps a model focus on a specific task by adjusting its general knowledge to fit the requirements. This improves the model’s accuracy and relevance for that particular job. Suppose you have a pre-trained image recognition model that can identify common objects like cats, dogs, and cars. Now, you want to use it to detect defects in manufacturing products (e.g., scratches on metal parts). The model might not perform well initially because it wasn’t trained for this specific task. By fine-tuning it on a dataset of defective and non-defective product images, the model learns to focus on the features that matter for defect detection, like scratches or dents, and becomes much better at this specific job.
Efficiency and Resource Utilization
Fine-tuning is more effective than training a model from scratch because it builds on what the model already knows. This reduces the need for massive datasets and computational power, and the model learns faster. For example, instead of training a self-driving car’s vision system from zero, fine-tuning a general object recognition model with driving-specific images speeds up the process and reduces costs.
Customization and Flexibility
Fine-tuning allows you to adapt a model to new tasks or improve its performance without starting over. This makes the model flexible and customizable for different needs. For example, a chatbot trained on general conversation data may not understand legal terminology. Fine-tuning it with legal documents enables it to provide better responses for law-related queries.
Use the Best Vision-Language Models
The best way to understand these models isn't by reading benchmarks, it's by getting your hands dirty with your own data. The transition from "drawing boxes" to "prompting pixels" is the biggest shift in the industry, and it's never been easier to start building.
Next Steps:
- Test the Models: Head over to the Roboflow Model Playground to try these VLMs on your own images in seconds.
- Deploy at Scale: Use our Inference Pipeline to integrate these models into your production environment.
- Build Your Dataset: Remember, even the best foundation model performs better with a little "fine-tuning." Use Roboflow Annotate to create the high-quality ground truth data that takes your VLM from nice demo to production-ready.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Feb 3, 2025). Comprehensive Guide to Vision-Language Models. Roboflow Blog: https://blog.roboflow.com/what-is-a-vision-language-model/