
CUDA is NVIDIA's parallel computing platform that repurposes GPU hardware, originally designed for graphics rendering, to accelerate the matrix operations that power deep learning and computer vision model training. The post covers CUDA's architecture (Streaming Multiprocessors, memory hierarchy, the thread/block/grid model), the software ecosystem including cuDNN and PyTorch, and walks through a concrete vector-addition kernel to illustrate the programming model. Engineers who do not need to write CUDA kernels directly can use high-level tools like Roboflow Inference to run vision models on CUDA GPUs without managing the underlying infrastructure.
If you’ve ever trained or worked with a deep learning model, chances are you’ve run into CUDA. In this article, we will thoroughly explain NVIDIA CUDA. We’ll explore the full picture including:
- How CUDA came to be and why it matters
- What it means for a GPU to be a “CUDA device”
- The architecture that makes CUDA so powerful
- The programming model behind CUDA
- The CUDA software ecosystem and libraries that power AI frameworks
- How CUDA directly enables training for computer vision models
- The high-level libraries you can use without writing CUDA code yourself
Soon you’ll see why CUDA is the foundation that has powered nearly every breakthrough in computer vision and deep learning.
What Is CUDA?
CUDA is NVIDIA’s platform for unlocking the power of GPUs - hardware originally built for rendering graphics - and applying it to general-purpose computing. Instead of just pushing pixels, GPUs can perform the same linear algebra operations that power 3D graphics, but at a scale that makes them perfect for machine learning. With CUDA and supporting libraries like cuDNN, developers can accelerate deep learning workloads, train vision models faster, and run computations that would be impractical on CPUs alone.
That said, CUDA isn’t without challenges. The ecosystem moves quickly, and different versions of CUDA don’t always work seamlessly together. Engineers often find themselves troubleshooting mismatched dependencies or rebuilding environments when models require a specific release. This complexity is one reason tools like Roboflow and containerized environments (e.g., Docker) are so valuable: they abstract away version headaches, prepackage dependencies, and let you focus on building computer vision solutions instead of wrestling with infrastructure.
CUDA: The Parallel Compute Platform
CUDA is most often associated with Graphics Processing Units (GPUs), specifically NVIDIA GPUs. But to really understand the role CUDA plays, we first need to step back and understand the GPU itself.
From Graphics Pipes to GPGPU
In the early days, when computers started adding graphics, it quickly became clear that Central Processing Units (CPUs) wouldn’t be enough to handle the load. A single-core CPU could only perform one task at a time, so rendering an image meant updating pixels one by one, far too slow for anything beyond simple displays.
Even with multicore CPUs, the situation didn’t improve much. Four cores, or even eight, still meant only a handful of pixels could be processed in parallel. That’s when the GPU came in.
Unlike the CPU, the GPU was built with many more cores. These cores were smaller and less powerful individually, but they could run tasks in parallel.

Think about rendering an image: Instead of wasting CPU resources by updating pixels sequentially, the GPU could take on the job and render many pixels at once. This kind of task is what computer scientists call embarrassingly parallel: a workload where thousands or even millions of pieces can be processed independently with almost no need for communication between them.
And it didn’t take long for researchers to realize that embarrassingly parallel problems weren’t limited to graphics. Here is a more humorous way to visualize the difference between a CPU and GPU:
The Birth of CUDA
In the early days of GPGPU, using GPUs for general-purpose tasks wasn’t straightforward. To get anything done, you needed a deep understanding of computer graphics and had to program through graphics APIs like OpenGL or DirectX, even if your real problem had nothing to do with graphics. For scientists, engineers, or researchers outside the graphics world, this was a major barrier.
To solve this, NVIDIA introduced CUDA (Compute Unified Device Architecture) in 2007. CUDA is a parallel computing platform and programming model that gives developers direct access to the GPU’s virtual instruction set and parallel computational elements. In simpler terms, CUDA enabled the writing of C or C++ code that runs on the GPU without requiring direct access to low-level graphics APIs.
This was a breakthrough. Suddenly, programmers and researchers in any domain - physics, biology, finance, machine learning, or engineering - could tap into the massive parallel power of GPUs just by writing CUDA code. The runtime and driver APIs took care of the rest, compiling and executing the code efficiently on the GPU.
CUDA would continue to grow in adoption, but it would not be until 2013 that the machine learning community began to take notice of its potential.
AlexNet Moment
In 2012, graduate student Alex Krizhevsky entered the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) while working with his advisor Geoffrey Hinton and collaborator Ilya Sutskever. Their model, later known as AlexNet, was a deep convolutional neural network unlike anything seen before at that scale.
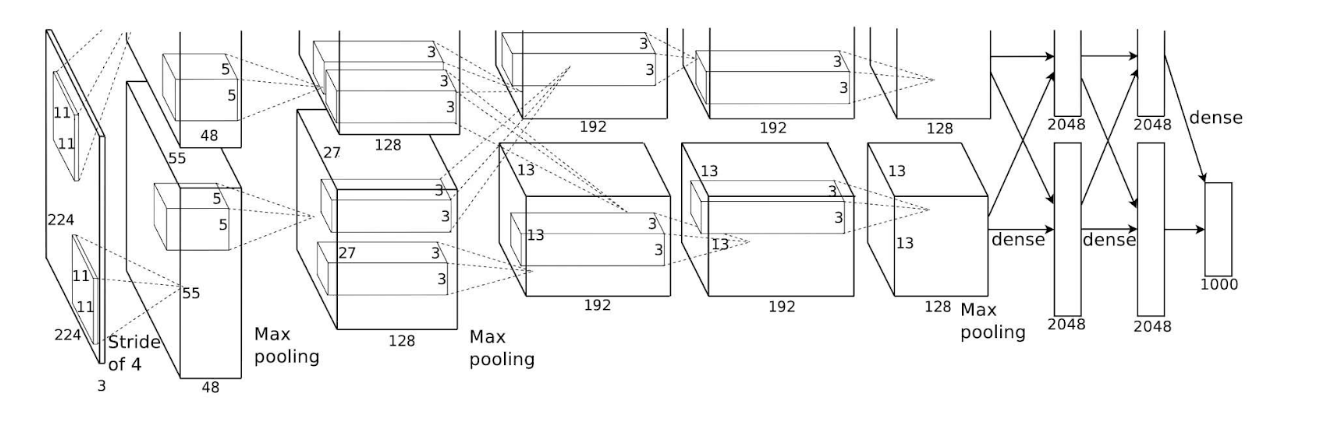
To train it, Krizhevsky turned to consumer hardware: two NVIDIA GeForce GTX 580 GPUs, each with 3 GB of memory. The network was too large to fit on a single GPU, so he split the architecture across both devices. The layers, mostly convolutions, max-pooling operations, and fully connected layers, were a perfect fit for CUDA’s ability to accelerate embarrassingly parallel tasks.
The results were historic. AlexNet outperformed the competition, significantly reducing the classification error rate compared to previous models. While convolutional neural networks (CNNs) had existed for decades, with pioneers like Yann LeCun demonstrating their potential on smaller problems, they had never been shown to scale effectively on CPUs. AlexNet proved that with the right algorithm and the computing power of CUDA-enabled GPUs, deep learning could leap far beyond traditional methods.
Both the machine learning community and NVIDIA took notice. For researchers, CUDA became the key to unlocking breakthroughs in AI. For NVIDIA, it was the moment their GPUs were no longer just for graphics but had become synonymous with the future of artificial intelligence.
The CUDA Mental Model
To really understand CUDA, it helps to think of it as a computing platform made up of two parts:
- Hardware architecture: the actual NVIDIA GPU that provides thousands of parallel cores.
- Software API: the C and C++ extensions that let developers write programs that run directly on that hardware.
Over the years, NVIDIA has released many generations of GPUs, each one continuing to support the CUDA platform. At this point, every modern NVIDIA GPU is CUDA-capable, which is why CUDA is often treated as if it were synonymous with the GPU itself.
So when someone says “CUDA,” they might be referring to the hardware, the API, or the platform as a whole. To make sense of this, let’s dive deeper into each piece.
CUDA Device Architecture
Over the years, NVIDIA has introduced several GPU architectures, each with its own improvements in speed, efficiency, and specialized compute units. Despite these differences, all CUDA-capable GPUs share three fundamental building blocks:
- Cores
- Streaming Multiprocessors (SMs)
- Memory hierarchy
Since the Fermi architecture (2010), these components have formed the backbone of every NVIDIA GPU, only becoming more powerful and efficient with each generation.
Cores
Like CPUs, NVIDIA GPUs are made up of cores. In the CUDA programming model, these are known as CUDA cores, and they handle the bulk of arithmetic and floating-point operations in parallel.
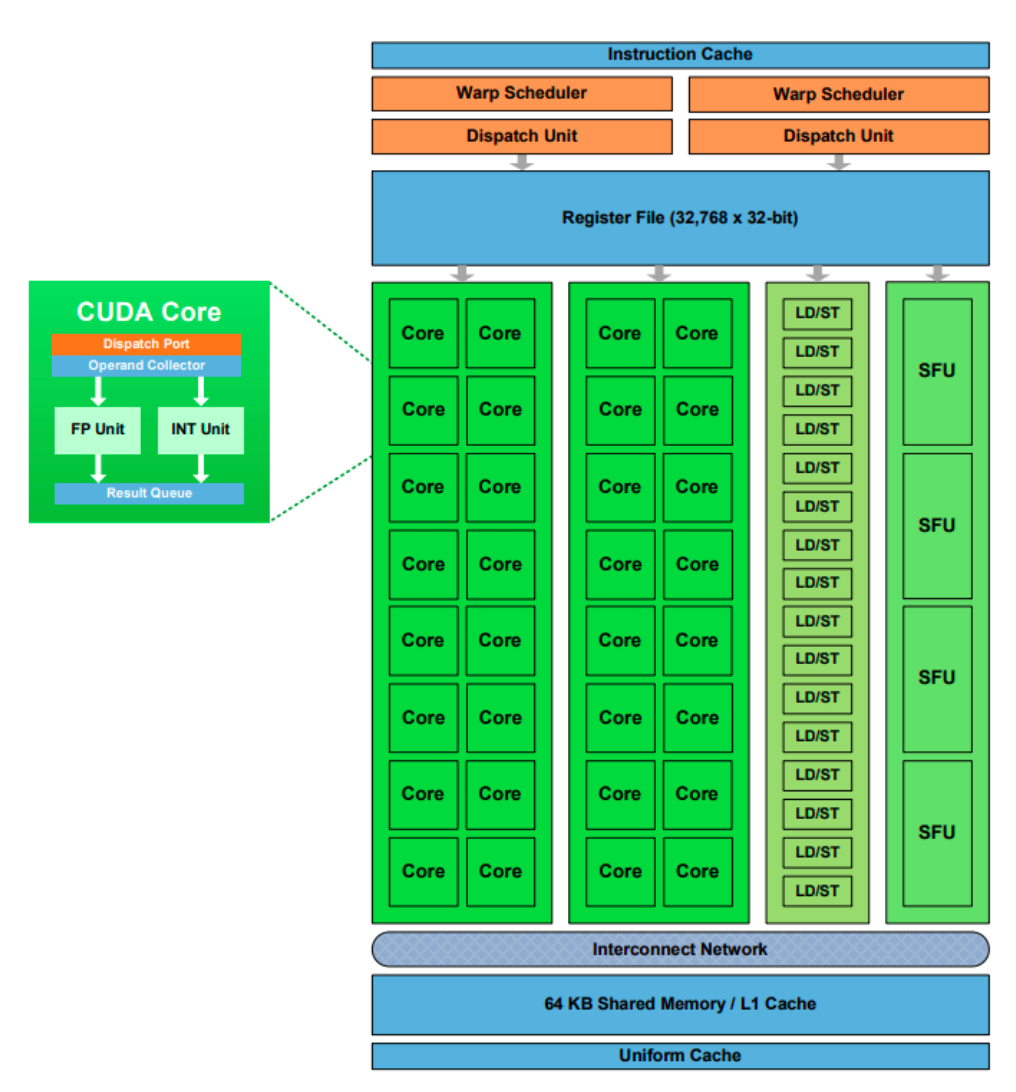
But CUDA cores are not the only compute units inside a GPU:
- Load/Store Units (LD/ST) handle memory operations such as reading from or writing to memory.
- Special Function Units (SFUs) are designed for mathematical functions like sine, cosine, reciprocal, or square root.
- Tensor Cores, introduced with the Volta architecture, accelerate matrix multiplications at the heart of deep learning. They deliver massive performance boosts for neural networks, making them a cornerstone of modern AI acceleration.
Streaming Multiprocessors (SMs)
NVIDIA GPUs group cores and supporting units into larger clusters called Streaming Multiprocessors (SMs). Each SM contains:
- A collection of CUDA cores, LD/ST units, SFUs, and (in newer architectures) tensor cores.
- Control logic for scheduling and managing execution.
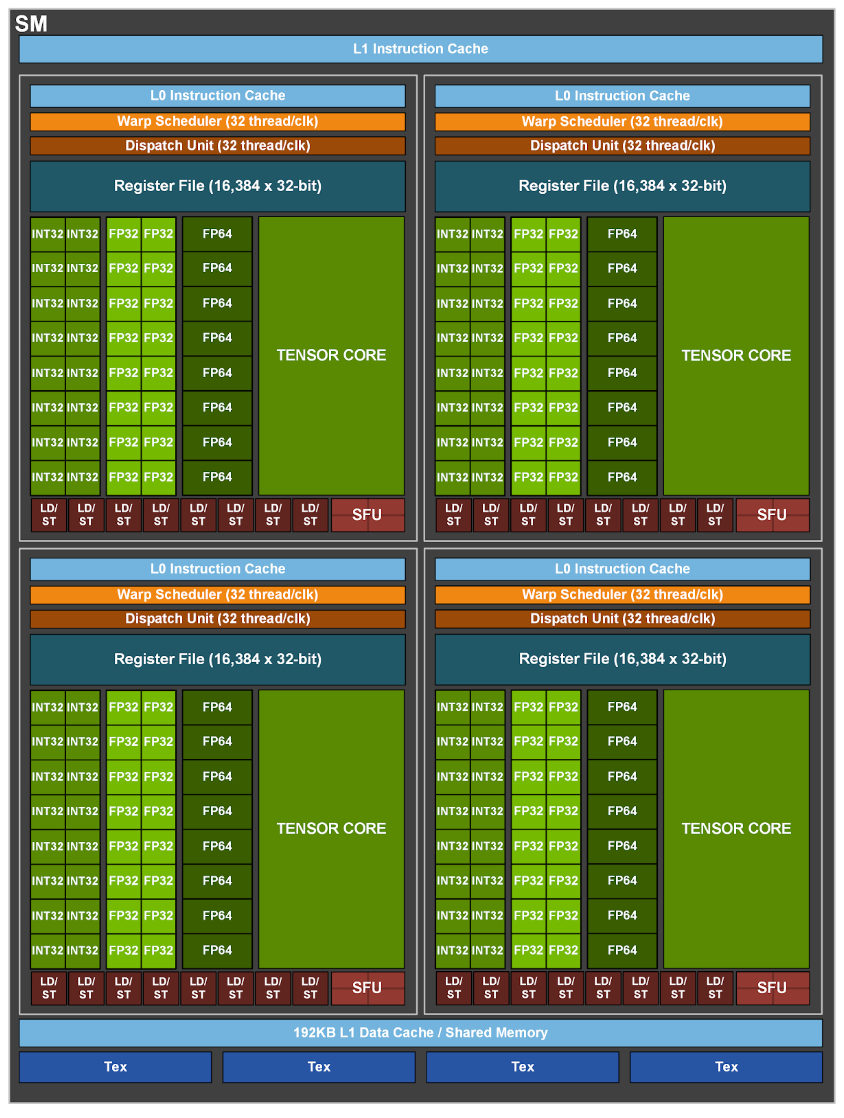
Work is executed on GPUs in groups of 32 threads, known as a warp. Each SM can run multiple warps, with a warp scheduler deciding which warp to execute at any given time. This SIMT (Single Instruction, Multiple Threads) model is what allows GPUs to scale parallel workloads efficiently across thousands of threads.
Memory Hierarchy
Efficient memory access is critical for GPU performance. CUDA organizes memory into a hierarchy, with different scopes and speeds:
- Registers: Private to each thread, the fastest form of memory.
- Shared Memory / L1 Cache: Shared among threads in the same block, located inside an SM.
- L2 Cache: Shared across the entire GPU device.
- Global Memory (VRAM): Accessible by all threads but slower, since it resides outside the SMs.
- Host Memory: CPU memory, accessed by the GPU over PCIe or NVLink, much slower compared to device memory.
This hierarchy ensures that most operations can be handled by fast, local memory, while still providing access to larger memory pools when needed.
CUDA Programming Model
Now that we’ve seen the CUDA device architecture, let’s look at the programming model that maps directly onto the hardware.
On a CPU, processes run on cores, and the operating system manages how those processes are scheduled. When we write multithreaded programs, we work with threads, which are units of execution that the operating system maps onto cores.
For example, a CPU might have four cores but can run eight threads at once, with each thread sharing the available core resources.
The same mental model applies to CUDA, but at a much larger scale. In CUDA, a thread is also the smallest unit of execution, defined by the programmer. These threads are mapped to the GPU’s CUDA cores and other compute units.
What makes CUDA unique is how it organizes and schedules massive numbers of threads across the GPU’s parallel hardware.
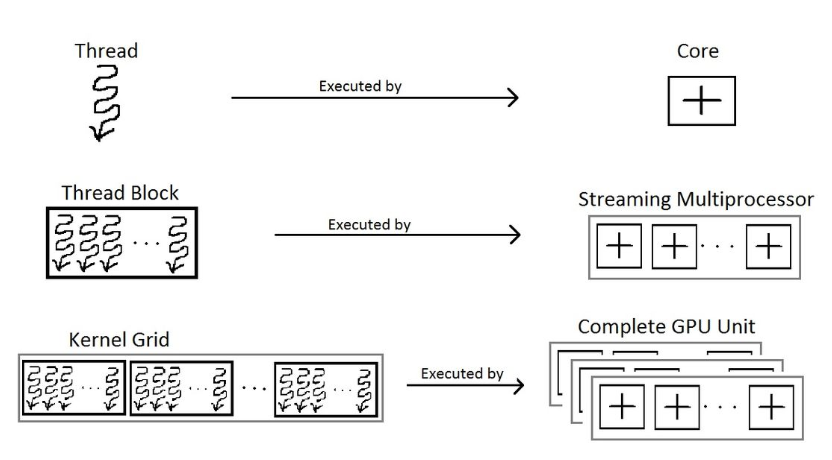
Here’s how the CUDA programming model corresponds to GPU hardware:
- Threads: The smallest unit of execution. Each thread maps to a CUDA core (or another compute unit) and executes a portion of the work.
- Thread Blocks: Groups of threads that run together on a single Streaming Multiprocessor (SM) and share memory.
- Grids: Collections of thread blocks. Grids enable CUDA to scale execution across all available SMs on the GPU.
- Kernels: Programmer-defined functions launched on the GPU. When launching a kernel, the programmer specifies the number of threads, blocks, and grids that define how the computation is distributed.
A Simple CUDA Example: Vector Addition
Let’s start by looking at how we would normally add two vectors in plain C on the CPU:
void vectorAddCPU(float *A, float *B, float *C, int N) {
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}
Here, the CPU executes the loop sequentially, one element at a time. Now let’s see the CUDA equivalent:
__global__ void vectorAddGPU(float *A, float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
Notice the difference: there’s no explicit loop here. Instead, we launch the kernel with enough threads to cover all N elements. Each thread figures out its own index and then performs the addition for its assigned element.
The index is computed as:
int idx = blockIdx.x * blockDim.x + threadIdx.x;
Here’s what each part means:
- blockIdx.x: the block’s index within the grid.
- blockDim.x: the number of threads in each block.
- threadIdx.x: the thread’s index within its block.
By multiplying the block index by the block size and adding the thread index, we get a globally unique thread ID. This maps each software thread in our kernel to a hardware CUDA core (or other compute unit) on the GPU.
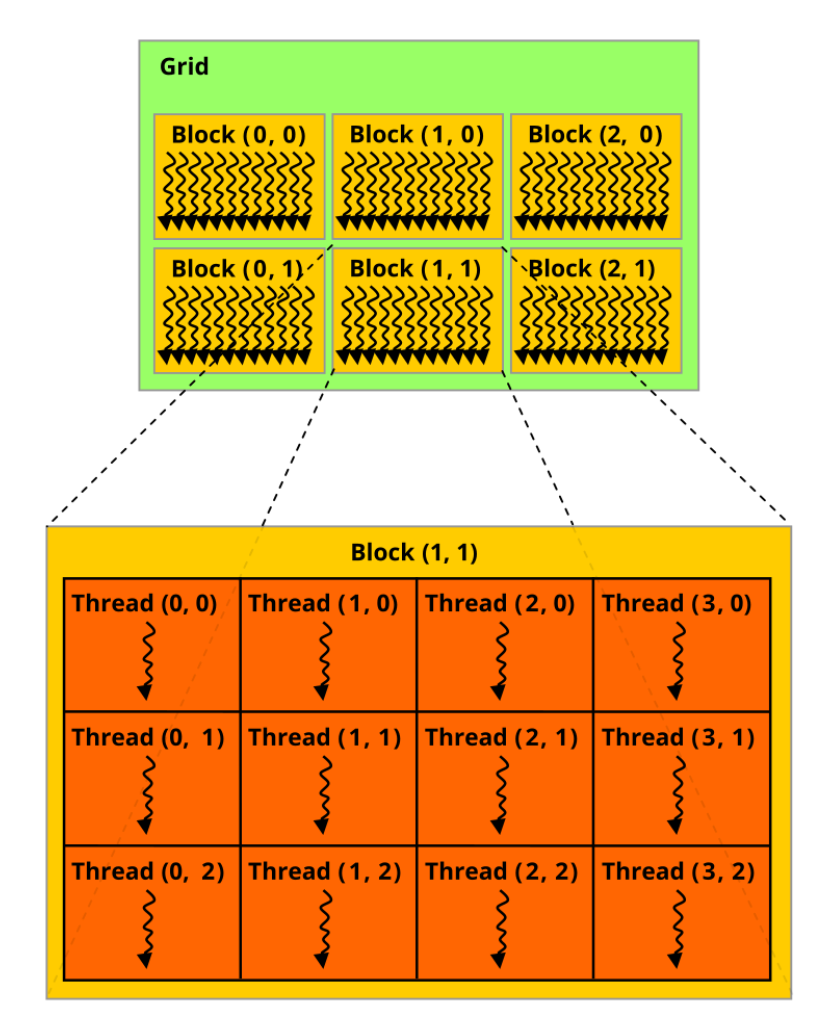
The above example shows 1D indexing, which works well for vectors or arrays. CUDA also supports 2D and 3D indexing, which are commonly used for images, matrices, or volumetric data. In those cases, you use blockIdx.y, blockIdx.z, threadIdx.y, and threadIdx.z along with their corresponding blockDim values to calculate global thread positions in higher dimensions.
Setting Up and Validating CUDA
To run CUDA, you need a NVIDIA GPU. This could be a consumer-grade GPU (like a GeForce card) or a data center GPU (such as Tesla or A100).
Once you have a supported GPU, the next step is to install the NVIDIA drivers and the CUDA Toolkit. The toolkit can be downloaded from the official NVIDIA CUDA Toolkit page. It includes everything you need to develop and run CUDA programs, such as the compiler, runtime libraries, and sample code.
After installation, you can verify that your GPU is properly recognized and the driver is working by running the NVIDIA System Management Interface command:
nvidia-smiA successful output looks something like this:

This tells you the driver version, CUDA version, available GPUs, their memory usage, and current processes.
Another key tool installed with the CUDA Toolkit is nvcc, the NVIDIA CUDA Compiler. This is used to compile C and C++ code to run on the GPU:
nvcc --versionThis command will print the installed CUDA version, confirming that the compiler is set up correctly.
Finally, the CUDA Toolkit also ships with a wide range of libraries (for linear algebra, deep learning, image processing, etc.) that make it much easier to develop GPU-accelerated applications. We’ll explore these libraries in the next section.
CUDA Software Ecosystem
Working directly with the CUDA API can be challenging. Writing kernels means dealing with threads, thread blocks, and grids. This level of detail would make developing machine learning models quite daunting.
To simplify this, NVIDIA provides a rich set of libraries that abstract away much of the complexity and accelerate common operations:
- cuDNN: Optimized primitives for deep neural networks.
- cuBLAS: High-performance linear algebra routines.
- TensorRT: Inference optimization and deployment.
- NCCL: Communication primitives for multi-GPU and distributed training.
- Thrust/RAPIDS: GPU-accelerated data science and analytics.
While these libraries greatly reduce the need to manage low-level CUDA details, they are still closer to the hardware than most developers typically work.
In practice, machine learning practitioners use higher-level deep learning frameworks like PyTorch and TensorFlow, which build on top of these CUDA libraries to provide user-friendly APIs.
🛠️ See Also: Build a PyTorch Custom Dataset
Train a Vision Model with PyTorch + CUDA
So far, we’ve discussed CUDA in theory. But now let’s see its benefits in practice. One of the most impactful use cases of CUDA is accelerating deep learning training.
To demonstrate this, we’ll train a simple convolutional neural network (CNN) on the CIFAR-10 dataset using both the CPU and GPU, and then compare training times.
We’ll run this experiment in Google Colab, which conveniently provides free access to NVIDIA GPUs.
Step 1: Import dependencies
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
import matplotlib.pyplot as pltStep 2: Define a simple CNN model
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return xStep 3: Load the CIFAR-10 dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=2)
Step 4: Define the training loop
def train(device, epochs=10):
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epoch_times = []
for epoch in range(epochs):
start_time = time.time()
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
end_time = time.time()
epoch_times.append(end_time - start_time)
print(f"Device: {device}, Epoch {epoch+1}, "
f"Loss: {running_loss / len(trainloader):.3f}, "
f"Time: {epoch_times[-1]:.2f} sec")
return epoch_times
Step 5: Train on CPU and GPU
print("Training on CPU...")
cpu_times = train(torch.device("cpu"), epochs=10)
gpu_times = []
if torch.cuda.is_available():
print("\nTraining on GPU...")
gpu_times = train(torch.device("cuda"), epochs=10)
Step 6: Visualize results
plt.figure(figsize=(10,5))
epochs = range(1, 11)
if gpu_times:
plt.plot(epochs, cpu_times, label="CPU", marker="o")
plt.plot(epochs, gpu_times, label="GPU", marker="o")
else:
plt.plot(epochs, cpu_times, label="CPU", marker="o")
plt.xlabel("Epoch")
plt.ylabel("Time (seconds)")
plt.title("CPU vs GPU Training Time on CIFAR-10")
plt.legend()
plt.grid(True)
plt.show()
Here’s how CPU vs GPU training time on CIFAR-10:
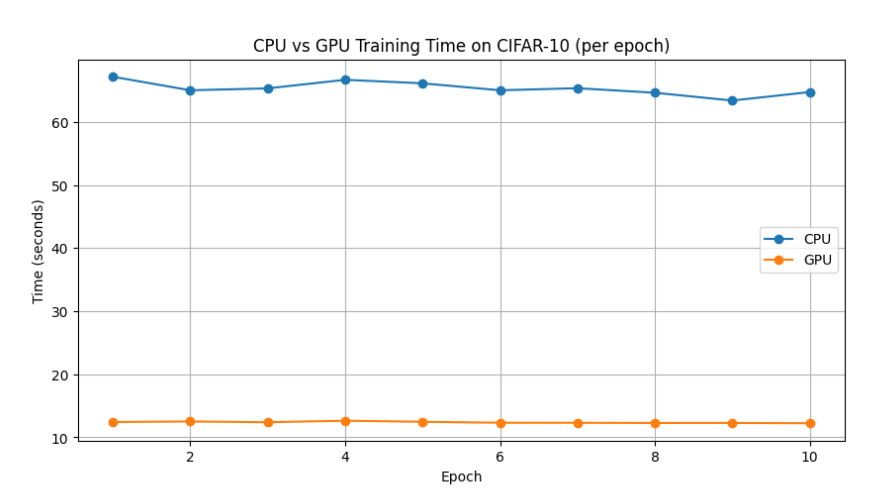
Once training is complete, the plot will show that for every epoch, the GPU consistently outperforms the CPU.
This demonstrates the massive acceleration CUDA provides for deep learning workloads, turning training that would take hours on a CPU into just minutes on a GPU.
NVIDIA GPU Architectures Supporting CUDA
CUDA has evolved hand in hand with NVIDIA’s GPU architectures, each generation introducing features that make GPU programming more powerful and efficient:
- Tesla → Fermi → Kepler: The early CUDA-enabled GPUs expanded raw compute capabilities and parallelism, laying the foundation for large-scale scientific and vision workloads.
- Maxwell → Pascal: Focused on efficiency and higher throughput, these generations improved memory handling and performance per watt, making deep learning training more practical.
- Volta: A major leap with the introduction of Tensor Cores, specialized units for matrix operations that dramatically accelerated neural network training.
- Turing → Ampere → Hopper → Blackwell: Designed with AI in mind, these architectures scaled Tensor Cores, introduced sparsity acceleration, and enabled massive parallelism across thousands of cores, which is essential for today’s computer vision and generative AI models.
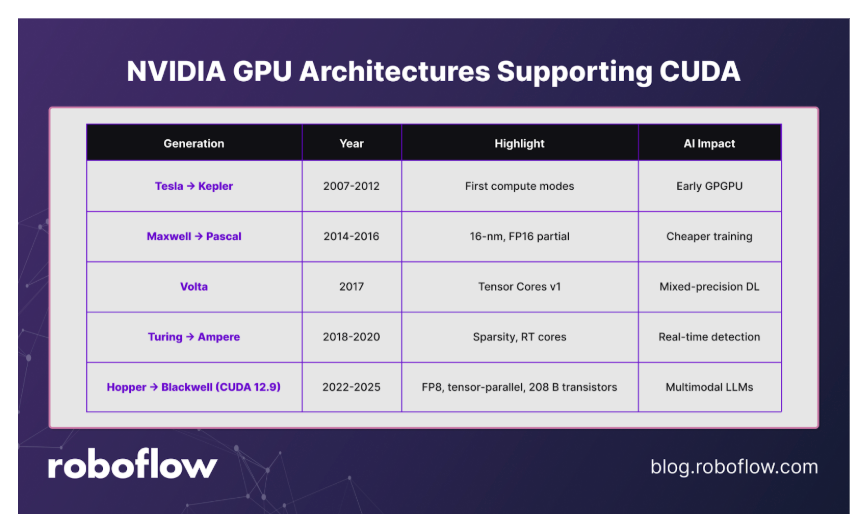
Each architectural leap has not only increased raw performance, but also simplified CUDA programming for computer vision tasks.
Operations that once required custom kernels can now be offloaded to optimized CUDA libraries, letting researchers and engineers focus more on model design than low-level GPU management.
Alternatives to CUDA
CUDA is powerful, but it comes with a few drawbacks: it is not open source and is tied exclusively to NVIDIA GPUs. Over the years, other vendors and communities have introduced alternatives to address these limitations:
- OpenCL: An open standard for parallel programming that is vendor-agnostic. It runs across CPUs, GPUs, and FPGAs but generally lacks the same level of optimization, tooling, and ecosystem support as CUDA.
- ROCm (AMD): AMD’s open-source alternative to CUDA, designed primarily for AMD GPUs. It has growing support in machine learning frameworks, though its ecosystem is still smaller compared to CUDA.
- SYCL/oneAPI (Intel): A modern programming model for heterogeneous computing. Built on the SYCL standard, Intel’s oneAPI allows code to run across CPUs, GPUs, and other accelerators, including some NVIDIA and AMD hardware. Its implementation language, DPC++, extends SYCL with additional features.
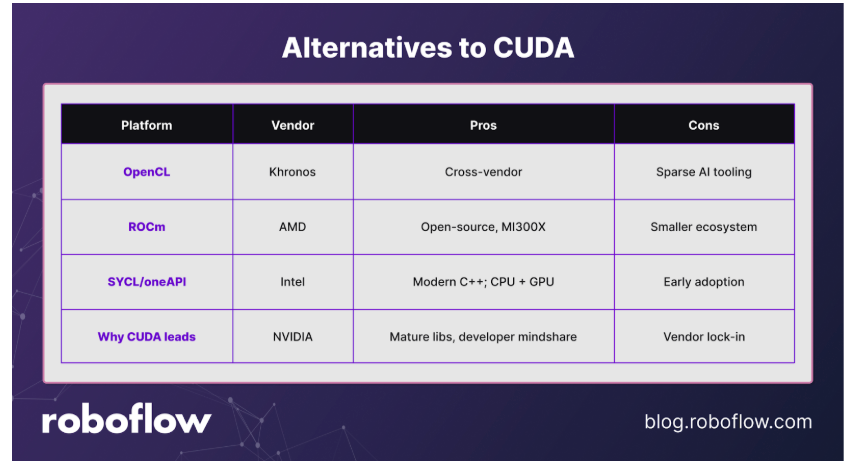
While these alternatives provide strong competition, CUDA remains the dominant choice. Its advantage lies in a mature ecosystem, years of adoption by researchers, robust tooling, and NVIDIA’s early recognition of AI’s potential, factors that competitors are still catching up to.
CUDA Conclusion
CUDA has been the driving force behind computer vision and AI breakthroughs, and for the foreseeable future, it’s not going anywhere. Thanks to CUDA, the GPU, which used to be just the thing gamers bragged about for running the latest AAA title, is now the engine driving the biggest wave of innovation in AI and computer vision.
CUDA’s success isn’t just about hardware; it’s also about software. The programming model fits neatly with the hardware, and over time, an entire ecosystem has grown around it. That’s why today, if you want to train or fine-tune a computer vision model, you don’t need to spend sleepless nights writing CUDA kernels from scratch.
You can lean on high-level libraries like PyTorch or go one step higher with tools like Roboflow Inference, which let you run vision models on CUDA GPUs and enjoy all the benefits without writing training loops and boilerplate.
CUDA turned the GPU from a gaming accessory into the engine of AI innovation, and that’s a pretty wild upgrade.
Check out the computer vision glossary to learn more.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Aug 31, 2025). What Is NVIDIA CUDA? The GPU Language Powering Modern Computer Vision. Roboflow Blog: https://blog.roboflow.com/what-is-cuda/