
DINOv2 is a self-supervised training method from Meta Research that learns rich visual features directly from images without requiring any labels, removing one of the most time-consuming bottlenecks in building computer vision models. Pre-trained checkpoints support depth estimation, semantic segmentation, image classification, and instance retrieval, and the architecture produces dense embeddings that can underpin a wide range of downstream applications. The post covers how the method works, what tasks it supports out of the box, and how to get started with the available weights ranging from 84 MB to 4.2 GB.
DINOv2, created by Meta Research, is a new method of training computer vision models that uses self-supervised learning. This approach of training does not require labels.
Labeling images is one of the most time consuming parts of training a computer vision model: each object you want to identify needs to be labeled precisely. This is not only a limitation for subject matter-specific models, but also large general models that strive for high performance across a wider range of classes.
For instance, CLIP, OpenAI’s model to “predict the most relevant text snippet given an image” is immensely useful. But, the model was trained on 400 million pairs of text to image to train; a large number of annotations.
This comes with limitations, both in terms of time to gather and label data and the preciseness of the labels compared to the rich contents of images. DINOv2 is a breakthrough advancement and worth researching how it can improve your computer vision pipeline.
The field of NLP has had rich featurization available in the form of vector embeddings for years, from Word2Vec to BERT. These foundational embeddings paved the way for a large range of applications. In kind, new image embedding models will form the basis of new computer vision applications.
In this guide, we’re going to talk through:
- What is DINOv2?
- How does DINOv2 work?
- What can you do with DINOv2?
- How can you get started with DINOv2?
Without further ado, let’s get started!
What is DINOv2?
DINOv2 is a self-supervised method for training computer vision models developed by Meta Research and released in April 2023. Because DINOv2 is self-supervised, the input data does not require labels, which means models based on this architecture can learn richer information about the contents of an image.
Meta Research has open-sourced the code behind DINOv2 and models showing the architecture in use for various task types, including:
- Depth estimation;
- Semantic segmentation, and;
- Instance retrieval.
The DINOv2 training approach is documented in the accompanying project paper released by Meta Research, DINOv2: Learning Robust Visual Features without Supervision.
How Does DINOv2 Work?
DINOv2 leverages a technique called self-supervised learning, where a model is trained using images without labels. There are two major benefits of a model not requiring labels.
First, a model can be trained without investing the significant time and resources to label data. Second, the model can derive more meaningful and rich representations of the image input data since the model is trained directly on the image.
By training a model directly on the images, the model can learn all the context in the image. Consider the following image of solar panels:

We could assign this image a label such as “an aerial photograph of solar panels” but this misses out on a lot of the information in the image; documenting deeper knowledge for a large dataset is difficult. But, DINOv2 shows that labels are not necessary for many tasks such as classification: instead, you can train on the unlabelled images directly.
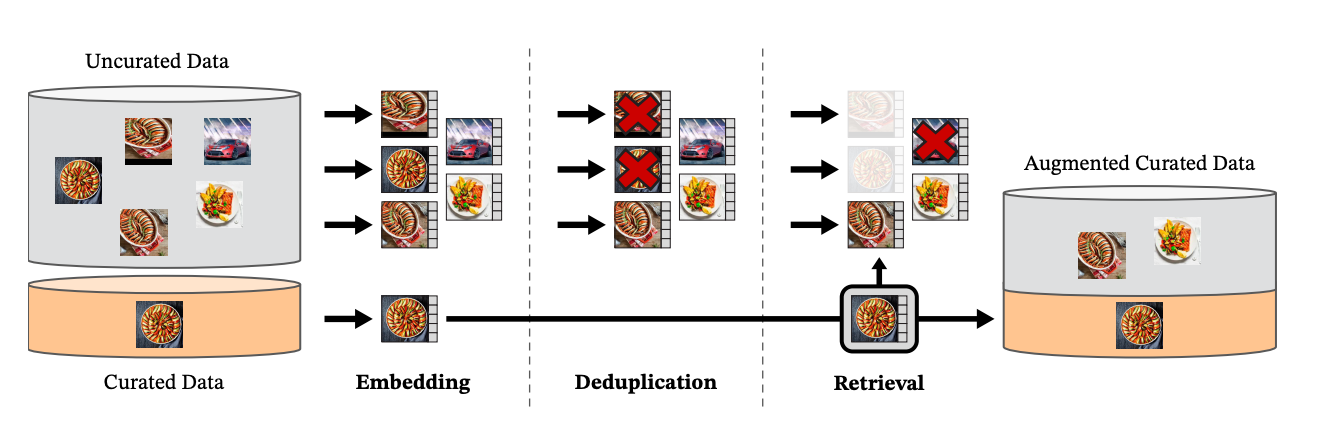
To prepare data for the model, Meta researchers used data from curated and uncurated data sources. These images were then embedded. The uncurated images were deduplicated, then the deduplicated images were combined with the curated images to create the initial dataset used for training the model.
Prior to DINOv2, a common method of building general computer vision models that embed semantics of an entire image has been using a pre-training step with image-text pairs. For example, OpenAI’s CLIP model, which can work on tasks from image retrieval to classification, was trained on 400 million image-text pairs.
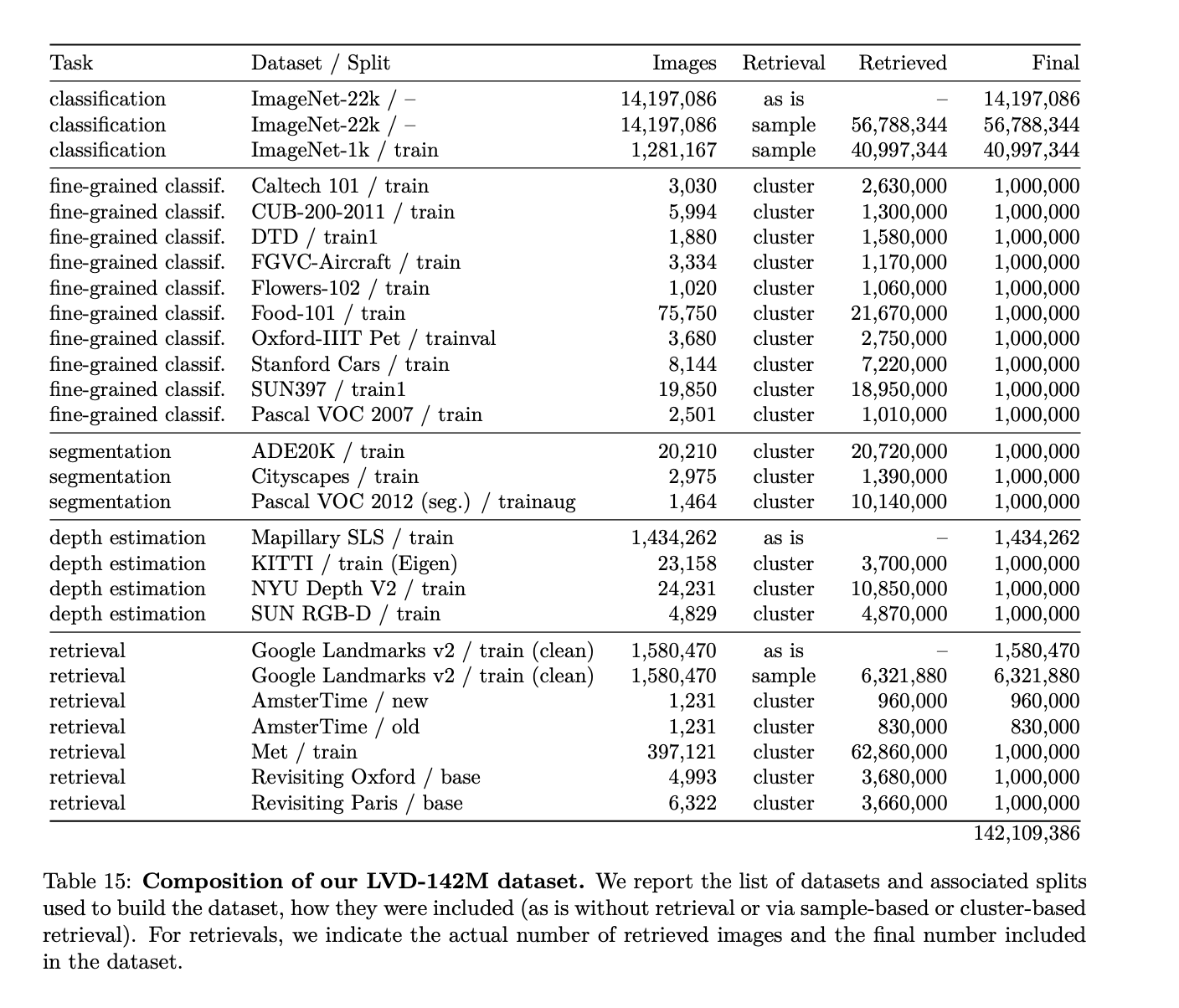
CLIP learned semantic information about the contents of images based on the text pairs. DINOv2, in contrast, was trained on 142,109,386 images. The table below, featured in the DINOv2 paper, shows how the data was sourced for the dataset:
DINOv2 circumvents the requirement to have these labels, enabling researchers and practitioners to build large models without requiring a labeling phase.
What Can You Do With DINOv2?
As a result of the increased information DINOv2 learns by training directly on images, the model has been found to perform effectively on many image tasks, including depth estimation, a task for which separate models are usually employed.
Meta AI researchers wrote custom model heads to accomplish depth estimation, image classification (using linear classification and KNN), image segmentation, and instance retrieval. There are no out-of-the-box heads available for depth estimation or segmentation, which means one would need to write a custom head to use them.
Let’s talk through a few of the use cases of the DINOv2 model.
Depth Estimation
DINOv2 can be used for predicting the depth of each pixel in an image, achieving state-of-the-art performance when evaluated on the NYU Depth and SUN RGB-D depth estimation benchmark datasets. Meta Research created a depth estimation model with a DPT decoder for use in their repository, although this is not open source. Thus, it is necessary to write the code that uses the model backbone to construct a depth estimation model.

The depth estimation capabilities of DINOv2 are useful for solving many problems. For instance, consider a scenario where you want to understand how close a forklift is to a parking dock. You could position a camera on the dock and use DINOv2 to estimate how close the forklift is to the dock. This could then be added to an alarm to notify someone that they are about to get too close to the end of the parking dock and hit a wall.
Image Segmentation
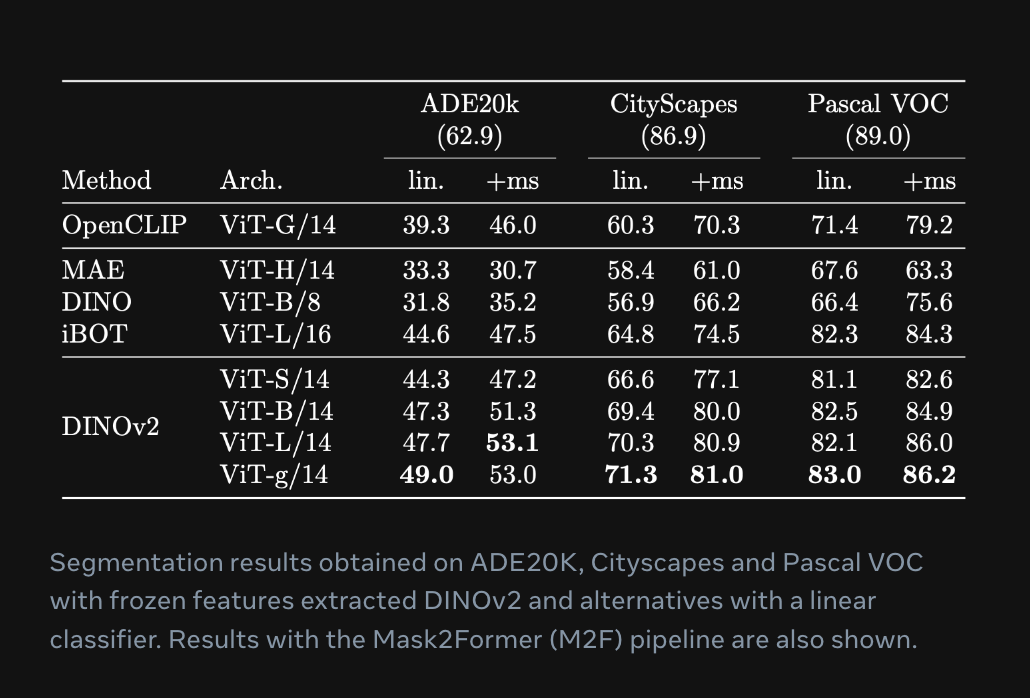
DINOv2 is capable of segmenting objects in an image. Meta Research evaluated DINOv2 against the ADE20K and Cityscapes benchmarks and achieved “competitive results” without any fine-tuning when compared to other relevant models, according to the instance segmentation example in the model playground. There is no official image segmentation head that accompanies the repository.
Such code would need to be written manually in order to use DINOv2 for segmentation tasks.
Classification
DINOv2 is suitable for use in image classification tasks. According to Meta Research, the performance of DINOv2 is “competitive or better than the performance of text-image models such as CLIP and OpenCLIP on a wide array of tasks”.
For instance, consider a scenario where you want to classify images of vehicles on a construction site. You could use DINOv2 to classify vehicles into specified classes using a nearest neighbor approach or linear classification.
With that said, a custom classifier head is needed to work with the DINOv2 embeddings.
Instance Retrieval
DINOv2 can be used as part of an image information retrieval system that accepts images and returns related images. To do so, one would embed all of the images in a dataset. For each search, the provided image would be embedded and then images with a high cosine similarity to the embedded query image would be returned.
In the Meta Research playground accompanying DINOv2, there is a system that retrieves images related to landmarks. This is used to find art pieces that are similar to an image.
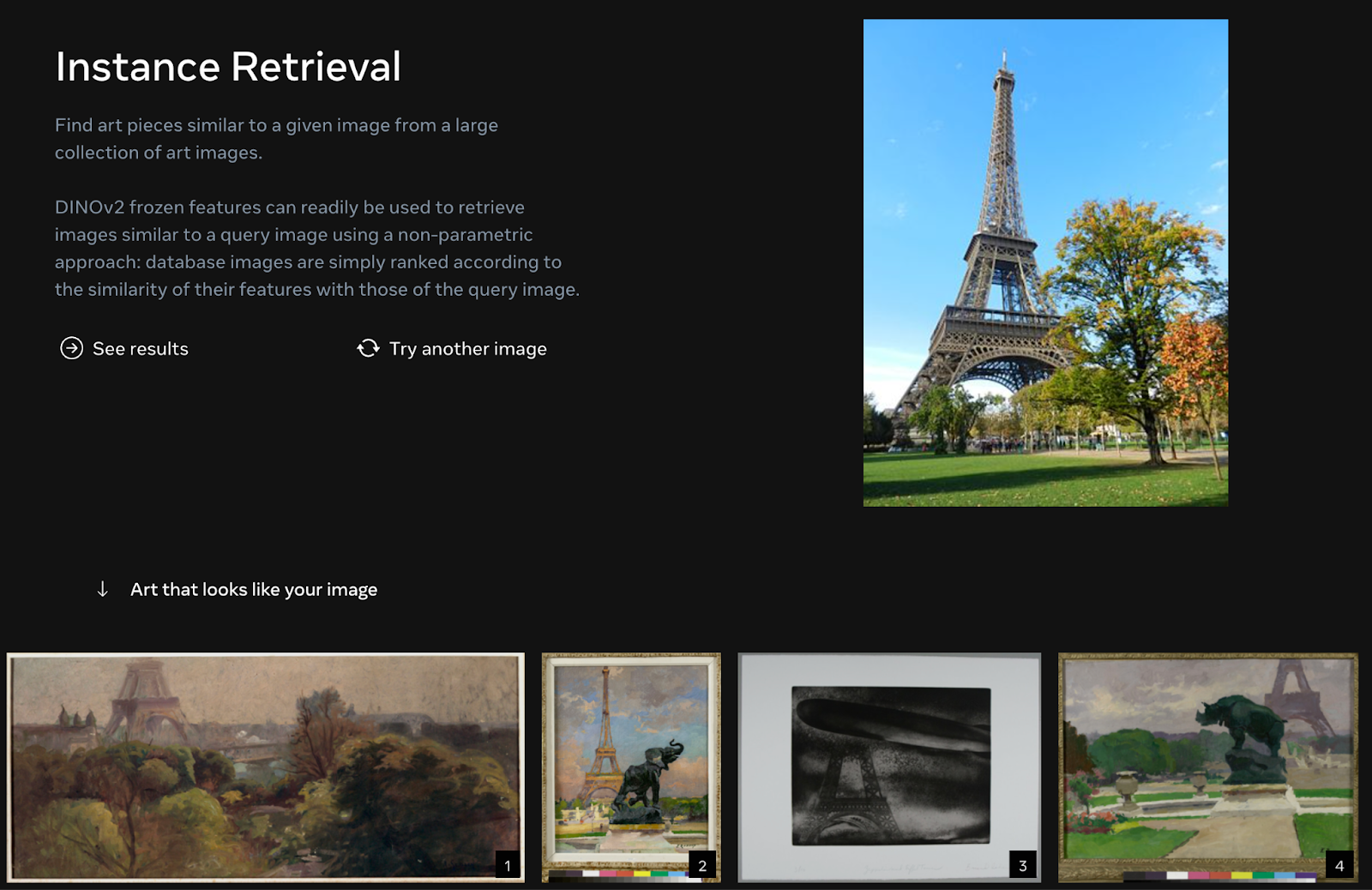
You could build an image-to-image instance retrieval system using the out-of-the-box code for loading the model and encoding images using the model. Then, you could use a vector store like faiss to store embeddings for a repository of images and a distance measure such as cosine measure to find images related to another image. See our guide on using CLIP to build a semantic image search engine for an example use case of this type of functionality.
How to Get Started
The code behind the DINOv2 paper is available on GitHub. Four checkpoints accompany the code, ranging in size from 84 MB for the smallest model to 4.2 GB for the largest model. There are also training scripts that you can use to train the model on different datasets.
The DINOv2 repository is licensed under a Creative Commons Attribution-NonCommercial 4.0 International license.
Conclusion
DINOv2 is a new training method for computer vision models, leveraging self-supervised learning to allow for a model training process that does not require labels. DINOv2 learns directly from images without text pairs, allowing the model to learn more information about the input image that can be used for various tasks.
The DINOv2 method was used by Meta Research to train a model capable of depth estimation, classification, instance retrieval, and semantic segmentation. Pre-trained checkpoints are available for use with the model so you can build your own applications leveraging DINOv2.
Frequently Asked Questions
What task types does DINOv2 support out of the box?
DINOv2 has a Vision Transformer (ViT) head that you can use to compute embeddings out of the box for image-to-image retrieval and classification tasks. Meta Research has not released segmentation and depth estimation heads, which means you need to write these components yourself to use DINOv2 for those tasks.
What size are the DINOv2 weights?
The pre-trained DINOv2 weights range from 84.2 MB for the smallest model to 4.2 GB for the largest model.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (May 24, 2023). What is DINOv2? A Deep Dive. Roboflow Blog: https://blog.roboflow.com/what-is-dinov2/