
YOLOv10, released in May 2024, is a new advancement in the field of real-time object detection. This model, building upon the innovations introduced in YOLOv9, addresses critical challenges such as reliance on non-maximum suppression (NMS) and computational redundancy, which have previously hampered the efficiency and performance of YOLO models.
The YOLOv10 architecture introduces a novel approach called consistent dual assignments, which enables NMS-free training and significantly reduces inference latency while maintaining competitive performance. Additionally, YOLOv10 incorporates an efficiency-accuracy driven design strategy, which involves optimizing various components of the model to minimize computational overhead and enhance performance.
In this blog post, we will explore the mechanics of YOLOv10, exploring its groundbreaking innovations and examining its transformative impact on computer vision and object detection.
You can try a YOLOv10 model trained on COCO with the following Workflow:
What Is YOLOv10?
YOLOv10 is a cutting-edge computer vision architecture designed for real-time object detection, building upon the advancements of its predecessors. The YOLOv10 model achieves a higher mean Average Precision (mAP) compared to earlier YOLO models such as YOLOv9, YOLOv8, and YOLOv7 when benchmarked against the MS COCO dataset.
YOLOv10 introduces several strategies to tackle the limitations of previous models, particularly addressing the reliance on non-maximum suppression (NMS) for post-processing and the resulting inefficiencies. To solve these inefficiencies, YOLOv10 leverages a consistent dual assignments strategy, eliminating the need for NMS during inference and significantly reducing latency while maintaining competitive performance.
Furthermore, YOLOv10 adopts a holistic efficiency-accuracy driven model design strategy. This approach includes several key innovations aimed at enhancing both performance and efficiency.
The lightweight classification head is designed to reduce computational redundancy, ensuring that the model operates more efficiently. Spatial-channel decoupled downsampling is employed to optimize feature extraction, making the process more efficient. The rank-guided block design further streamlines the architecture, enhancing overall efficiency. Large-kernel convolution is utilized to improve the model’s capability to capture detailed features, and the effective partial self-attention module boosts accuracy with minimal computational cost.
These combined enhancements allow YOLOv10 to achieve remarkable performance while maintaining high efficiency. These enhancements ensure YOLOv10 achieves a remarkable balance between accuracy and efficiency.
How YOLOv10 Works
YOLOv10 introduces significant advancements in object detection through a novel training strategy and architectural enhancements. Let’s discuss the main components of how YOLOv10 works.
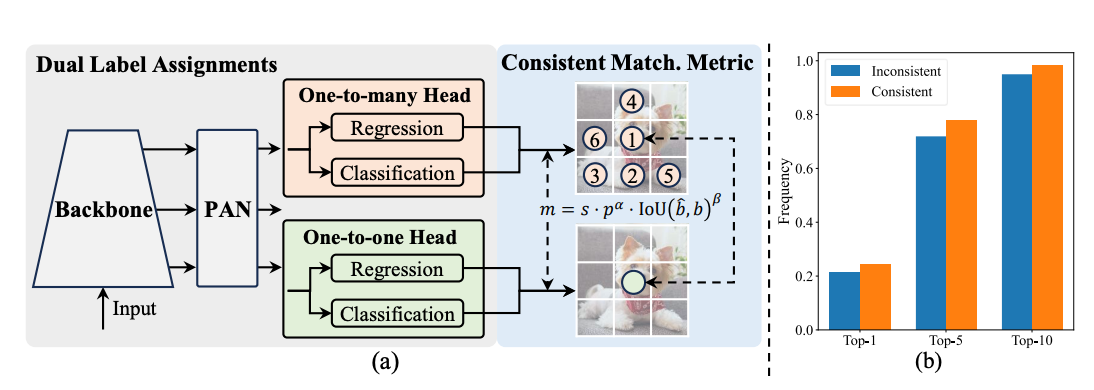
NMS-Free Training Strategy with Dual Label Assignments
Traditionally, YOLO models employ a one-to-many assignment strategy during training, which allocates multiple positive samples for each ground truth instance. This method, known as Task-Aware Learning (TAL), provides abundant supervisory signals that enhance optimization and overall performance. However, it also necessitates the use of Non-Maximum Suppression (NMS) during inference to filter out redundant predictions, leading to inefficiencies and increased inference latency.
To overcome this, YOLOv10 adopts a dual label assignment strategy that integrates both one-to-many and one-to-one matching approaches:
- One-to-One Matching: Assigns a single prediction to each ground truth instance, eliminating the need for NMS and enabling end-to-end deployment. This approach typically results in weaker supervision, causing suboptimal accuracy and slower convergence.
- One-to-Many Assignment: Provides richer supervisory signals but requires NMS for inference.
YOLOv10 cleverly combines these strategies by introducing an additional one-to-one head, mirroring the original one-to-many branch's structure and optimization objectives. During training, both heads are jointly optimized, leveraging the rich supervision from the one-to-many assignments. During inference, the model utilizes only the one-to-one head, thus bypassing the need for NMS and achieving high efficiency without additional inference cost.
Consistent Matching Metric
A key component of the dual label assignment strategy is the consistent matching metric used to evaluate the concordance between predictions and ground truth instances. This metric incorporates both the classification score and the Intersection over Union (IoU) between predicted and actual bounding boxes, defined as:
This uniform metric, applied to both the one-to-many and one-to-one branches, ensures harmonized supervision across the dual heads. By aligning the one-to-one head's supervision with that of the one-to-many head, YOLOv10 enhances the quality of predictions during inference, leading to superior performance.
Classification Head, Decoupled Downsampling, Rank-Guided Block Design
The components of YOLO models consist of the stem, downsampling layers, stages with basic building blocks, and the head. The stem incurs minimal computational cost. YOLOv10 thus focuses on optimizing the other three parts to enhance efficiency:
- Lightweight Classification Head: Traditionally, the classification and regression heads in YOLO models share the same architecture, despite significant differences in their computational overhead. For instance, in YOLOv8-S, the classification head has 2.5 times the FLOPs and 2.4 times the parameter count of the regression head. However, analysis reveals that the regression head is more crucial for performance. Consequently, YOLOv10 adopts a lightweight architecture for the classification head, consisting of two depthwise separable convolutions with a kernel size of 3×3, followed by a 1×1 convolution. This change reduces computational redundancy without significantly impacting performance.
- Spatial-Channel Decoupled Downsampling: Standard YOLO models typically use 3×3 convolutions with a stride of 2 for simultaneous spatial downsampling and channel transformation. This approach introduces considerable computational and parameter overhead. YOLOv10 decouples these operations by first using pointwise convolution to adjust the channel dimension, followed by depthwise convolution for spatial downsampling. This method significantly reduces the computational cost and parameter count while retaining more information, leading to a competitive performance with reduced latency.
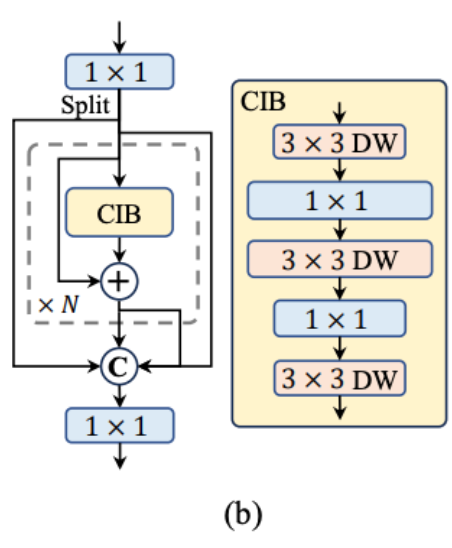
- Rank-Guided Block Design: YOLO models often employ the same basic building block across all stages, which can result in redundancy, particularly in deeper stages and larger models. YOLOv10 utilizes intrinsic rank analysis to identify and address redundancy. By calculating the numerical rank of the last convolution in each stage, it becomes evident that a homogeneous block design is suboptimal. YOLOv10 introduces a compact inverted block (CIB) structure, using depthwise convolutions for spatial mixing and cost-effective pointwise convolutions for channel mixing. This structure, embedded in the Efficient Layer Aggregation Network (ELAN), optimizes the architecture for higher efficiency. The rank-guided block allocation strategy ensures that the most redundant stages are replaced with more compact designs without compromising performance.
Kernel Convolution and Self-Attention
YOLOv10 also incorporates large-kernel convolution and self-attention mechanisms to enhance accuracy with minimal computational cost:
- Large-Kernel Convolution: Employing large-kernel depthwise convolution effectively enlarges the receptive field and enhances the model's capability. However, using them in all stages can contaminate shallow features needed for detecting small objects and introduce significant I/O overhead and latency in high-resolution stages.
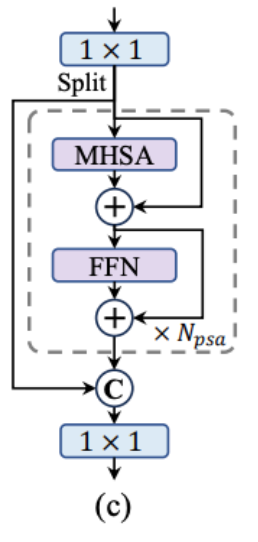
YOLOv10 strategically incorporates large-kernel depthwise convolutions in the deep stages of the CIB, increasing the kernel size of the second 3×3 depthwise convolution to 7×7. Structural reparameterization techniques are also used to alleviate optimization issues without increasing inference overhead. Since the benefit of large-kernel convolutions diminishes as model size increases, they are only applied to smaller model scales. - Partial Self-Attention (PSA): Self-attention is known for its global modeling capability but comes with high computational complexity and memory footprint. YOLOv10 introduces an efficient partial self-attention (PSA) module to mitigate these issues. After a 1×1 convolution, the features are evenly partitioned across channels into two parts.
Only one part is fed into the NPSA blocks, which include multi-head self-attention and a feed-forward network. The two parts are then concatenated and fused by another 1×1 convolution. To enhance efficiency, the dimensions of the query and key are assigned to half of the value dimension, and LayerNorm is replaced with BatchNorm for faster inference. PSA is placed after Stage 4 with the lowest resolution, minimizing the overhead from the quadratic computational complexity of self-attention. This design incorporates global representation learning into YOLOv10 with low computational costs, enhancing the model's capability and improving performance.
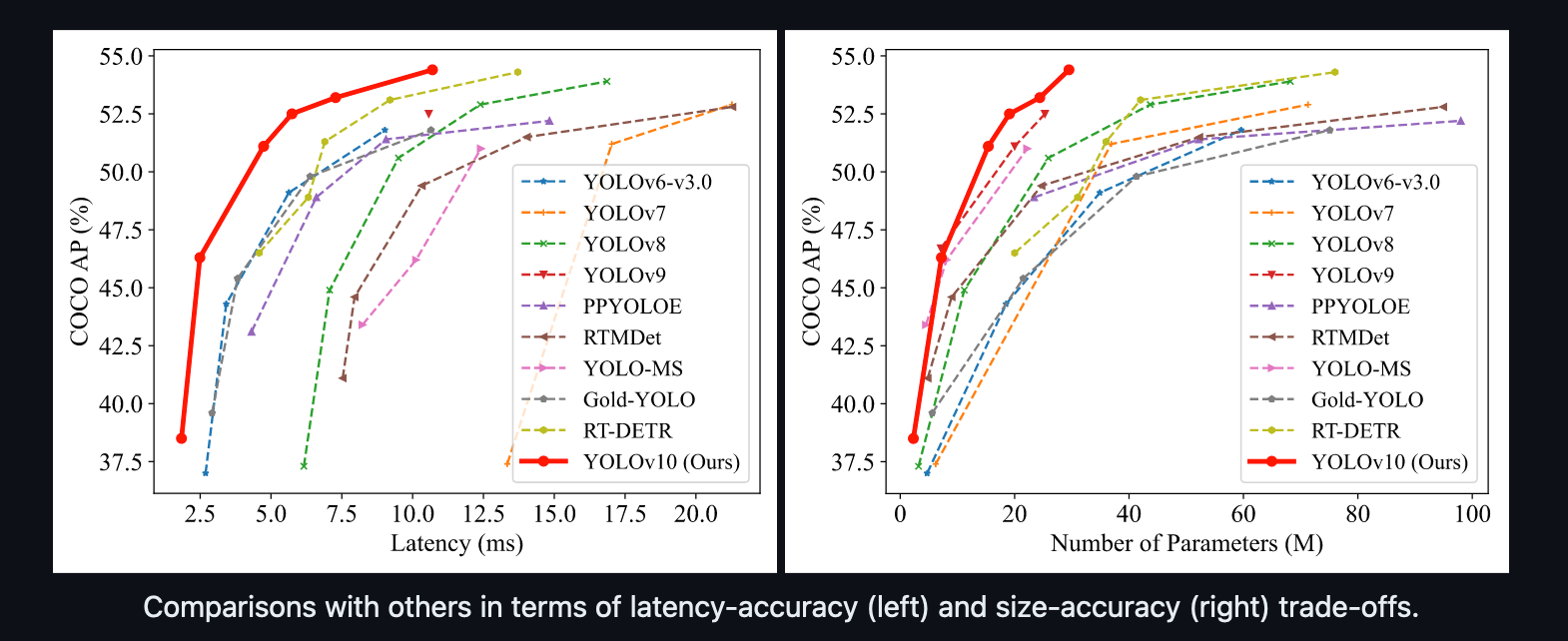
YOLOv10 Performance Comparison
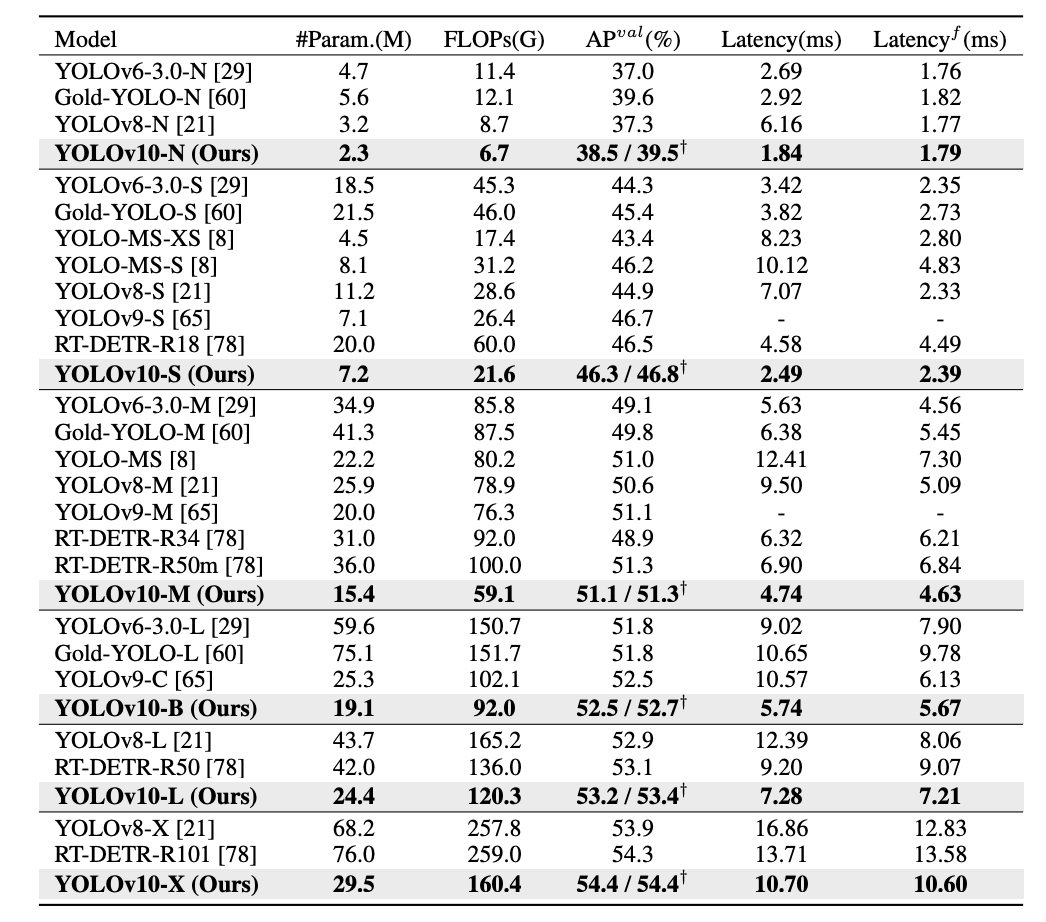
YOLOv10 achieves state-of-the-art performance and end-to-end latency across various model scales. Compared to our baseline models, YOLOv8, YOLOv10 demonstrates improvements of 1.2% / 1.4% / 0.5% / 0.3% / 0.5% in Average Precision (AP) with 28% / 36% / 41% / 44% / 57% fewer parameters, 23% / 24% / 25% / 27% / 38% fewer calculations, and 70% / 65% / 50% / 41% / 37% lower latencies for N / S / M / L / X variants, respectively.
Additionally, YOLOv10 shows superior trade-offs between accuracy and computational cost compared to other YOLO models. For lightweight and small models (YOLOv10-N / S vs. YOLOv6-3.0-N / S), YOLOv10 achieves improvements of 1.5 AP and 2.0 AP with 51% / 61% fewer parameters and 41% / 52% less computation, respectively. Medium-sized models YOLOv10-B / M also enjoy 46% / 62% lower latency compared to YOLOv9-C / YOLO-MS, with similar or better performance.
For large models, YOLOv10-L outperforms Gold-YOLO-L with 68% fewer parameters, 32% lower latency, and a 1.4% AP improvement. Compared to RT-DETR, YOLOv10-S / X achieves 1.8× and 1.3× faster inference speeds under similar performance.
YOLOv10 Conclusion
YOLOv10 represents a significant leap forward in real-time object detection, achieving state-of-the-art performance in terms of speed and accuracy.
By introducing NMS-free training and a holistic efficiency-accuracy driven model design, YOLOv10 improves accuracy while reducing computational redundancy and latency. Comparative evaluations against baseline models and other detectors demonstrate YOLOv10's superiority in AP, parameter efficiency, and inference speed.
If you are interested in learning how to train a YOLOv10 model, refer to the Roboflow How to Train YOLOv10 Model on a Custom Dataset guide.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jun 14, 2024). What is YOLOv10? An Architecture Deep Dive. Roboflow Blog: https://blog.roboflow.com/what-is-yolov10/