
The success of your machine learning model starts well before you ever begin training. Ensuring you have representative images, high quality labels, appropriate preprocessing steps, and augmentations to guard against overfitting all affect deep learning model performance well before you begin training.
And this is where Roboflow Organize comes in to help. Recently, we had a user describe us in a succinct, compelling sentiment:
"Roboflow is like the 'print preview' for your computer vision image input pipeline."
But, alas, once we're ready to train our model, how do we know what architecture to use? Engineers have even come to accept the vast number of models available for a given problem as "the model zoo!"
Know the Problem Type
There are a wide array of problem types in computer vision, ranging from simple image classification (considering the whole image and assigning it to a category) to semantic segmentation (determining exactly what a group of irregularly arranged pixels is).
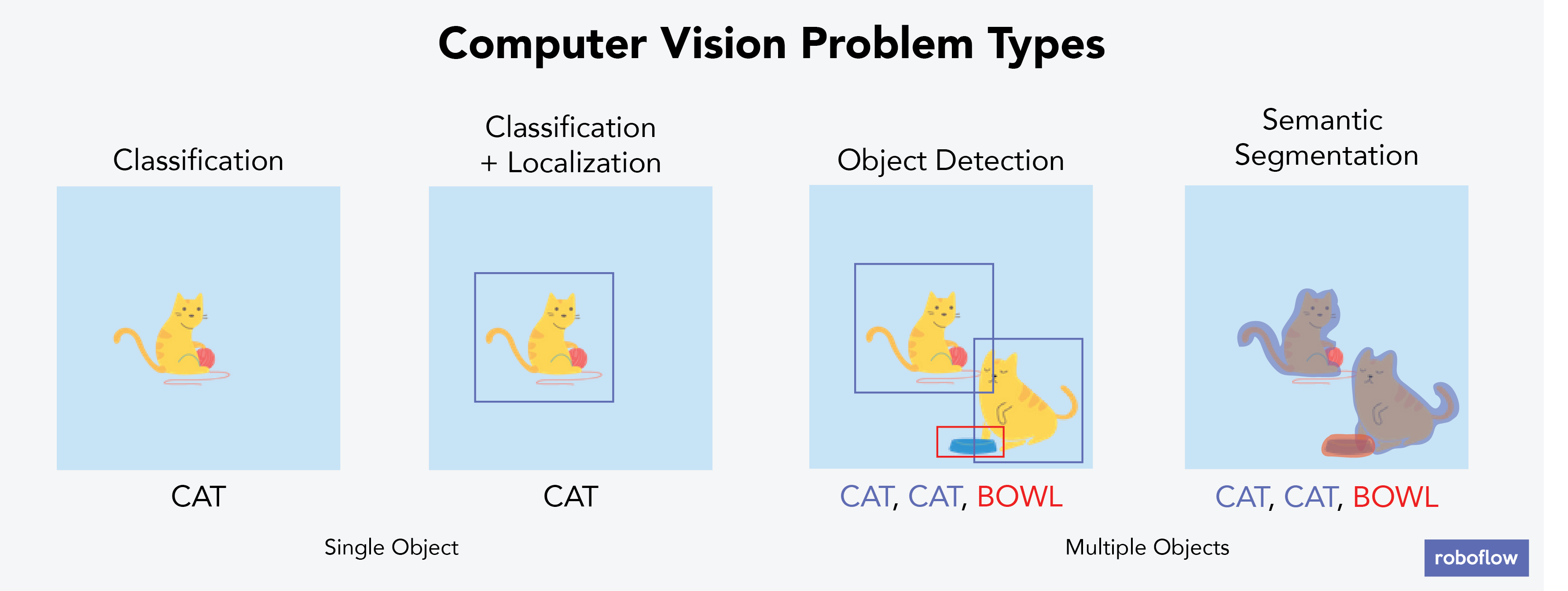
Classification problems are ones wherein a model determines a category (or tag) for the contents of an entire image. We may have single class problems (where there can only be one tag per image) or multi-class problems (where one image can be ascribed to multiple tags).
Classification and localization problems are ones where we not only identify what tag is best for an image, but a general box around the pixels that led us to that classification decision. Critically, we are limited to creating a bounding box for a single object per image
Object detection problems are ones wherein we are identifying bounding boxes (or a box "fence") around pixels of interest, and assigning pixels in that box to a single class. Notably, we can search a single image for multiple boxes of different classes in object detection problems.
Semantic segmentation problems are when we seek to isolate the outline of pixels – in any potential shape – that describe an object of interest. Similar to object detection, we are not limited to describing a single class for a group of pixels per object.
Upon inspection of these problems, you may wonder why we do not frame every problem as semantic segmentation: it's the most specific, and if we can assign any organic shape of pixels to a class, we've solved every other simpler task (object detection, localization and classification).
In some ways, for the same reason we do not store all integers as floats, we do not select the most complicated model for our problem. Semantic segmentation is quite challenging, the models are slower at inference, and the data labeling requirements are much more time intensive (and, therefore, costly). We should frame problem in the simplest terms for our solution.
Consider the Deployment Environment
When we train a model, we intend for it to run inference somewhere! That "where" matters significantly for our model selection purposes.
For example, imagine we are training a model to help make diagnoses of patient scans. The patient does not necessarily need a diagnosis just-in-time, and the model does not need to run in an offline environment. In other words, our model can run inference in the cloud with high performance computers and not be too-time pressed.
Contrast this with a self-driving car in a remote area. The model must be prepared to run in an offline environment (we are not assuming, say, 100 percent satellite internet coverage) and the model must inference run just-in-time – many times per second to make sense of live video feeds. In this example, we need a model that can run exceptionally quickly and with a high degree of accuracy on an embedded device.
A final example may be an on-device deployment on a mobile phone. We could run all inference on the phone's hardware (which is significantly less powerful than the cloud but getting better; especially on high end devices adding hardware machine learning accelerators like the iPhone's Neural Engine and Google's edge-TPUs) and, if it's a mobile app, chances are getting model inference in real-time is very important, too. And, potentially we are working on an app for, say, identifying if a tennis ball is inbounds or not. Accuracy certainly matters – but not as much as navigating a 60 MPH car in real-time.
Each of these contexts call for different tradeoffs between the computation resources we have available, the time to inference, and the accuracy of our model.
Applying Our Learnings to Object Detection Models
Let's zoom in on just object detection models and consider three possible models. For a deeper dive into the metrics, dive deeper in this post.
YOLOv3
YOLOv3 is the third iteration of "You Only Look Once" models – an architecture created by PJ Reddie. Fundamentally, the YOLOv3 architecture dramatically emphasizes speed and small compute requirements – handling 60+ FPS in many instances. However, YOLOv3 is less accurate than other model architectures like RetinaNet and Faster R-CNN.
MobileNet
Like YOLOv3, MobileNet is a single shot detector (SSD), making a single pass across input images. MobileNet is slightly slower (roughly 20 percent) but also slightly more performant on some tasks, particularly those detecting small objects. As a bonus, TensorFlow has many pre-trained examples of MobileNet in the object detection model zoo.
Faster R-CNN
Despite having "Faster" in the name, Faster R-CNN is the slowest inference model we're comparing here! That's because it's a two-stage model: in a first pass, the model identifies objects of interest, and in the second, it classifies them. This result dramatically slows performance (roughly half that of YOLO3), but obtains a ~15 mAP lift in performance.
Try Them Yourself
The Roboflow Model Library contains pre built notebooks for each of these models – and you can test each of them just by changing a single line of code in a Colab notebook that pulls in your data from Roboflow.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Feb 27, 2020). How to Select the Right Computer Vision Model Architecture. Roboflow Blog: https://blog.roboflow.com/yolov3-vs-mobilenet-vs-faster-rcnn/