
YOLOv9, released in April 2024, is an open source computer vision model that uses the YOLOv9 architecture. The model was created by Chien-Yao Wang and his team.
YOLOv9 introduces some techniques like Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) to effectively tackle issues concerning data loss and computational efficiency in computer vision problems. These breakthroughs ensure that YOLOv9 achieves outstanding real-time object detection performance, establishing a new benchmark for precision and speed in this domain.
In this blog post, we will dissect the mechanics of YOLOv9 and examine its transformative impact on object detection and computer vision.
Here is an example Workflow with which you can test a YOLOv9 model trained on COCO with any image that you upload:
What is YOLOv9?
YOLOv9 is a computer vision architecture that supports object detection and image segmentation. According to the YOLOv9 research team, the YOLOv9 model architecture achieves a higher mAP than existing popular YOLO models such as YOLOv8, YOLOv7, and YOLOv5, when benchmarked against the MS COCO dataset.
Evolving from its predecessors, YOLOv9 introduces groundbreaking concepts like Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) to elevate the efficiency and precision of object detection tasks.
Through the integration of PGI, YOLOv9 effectively addresses the issue of data loss in deep networks, ensuring the retention of crucial features and the generation of reliable gradients for optimal training results. The use of GELAN yields a network architecture that maximizes parameter utilization and computational efficacy, rendering YOLOv9 adaptable and high-performing across a diverse array of applications.

Focused on real-time object detection, YOLOv9 advances cutting-edge methodologies like CSPNet, and ELAN, and enhanced feature integration techniques to achieve superior performance across various computer vision tasks. By leveraging the capabilities of PGI for gradient information programming and GELAN for efficient layer aggregation, YOLOv9 establishes a new benchmark for object detection systems, outperforming existing real-time detectors in accuracy, speed, and parameter utilization.
How YOLOv9 Works
The YOLOv9 framework presents a novel method for tackling fundamental hurdles in object detection using deep learning, with an emphasis on combating information loss and enhancing network efficiency.
In the section below, we are going to explore four key components of YOLOv9: The Information Bottleneck Principle, which is necessary background, then the three methods of addressing information bottlenecks: Reversible Functions, PGI and GELAN.
Background: The Information Bottleneck Principle
The Information Bottleneck Principle explains the process of information loss as data transforms within a neural network. Encapsulated in the equation of the Information Bottleneck, this principle quantifies the reduction in mutual information between the original and transformed data as it traverses through the layers of the deep network.
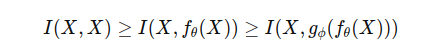
In this equation, I represent mutual information, where f and g denote transformation functions with parameters θ and ϕ, respectively. As data X traverses through the layers (fθ and gϕ) of a deep neural network, it undergoes a loss of crucial information necessary for precise predictions. This loss may result in unstable gradients and hindered model convergence.
A common remedy involves enlarging the model to bolster its capacity for data transformation, thereby preserving more information. However, this strategy fails to resolve the problem of erratic gradients in exceedingly deep networks. The subsequent section explores how reversible functions offer a more viable solution.
YOLOv9 uses reversible functions, PGI, and GELAN to address information bottlenecks.
Reversible Functions
The theoretical antidote to combat the Information Bottleneck is the Reversible Function. Embedded within neural networks, reversible functions guarantee zero loss of information throughout data transformation processes. By enabling the reversal of data transformations, these functions ensure the original input data can be precisely reconstructed from the network's outputs.
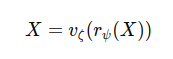
In the equation above, r and v symbolize the forward and reverse transformations, respectively, with ψ and ζ as their corresponding parameters. Leveraging reversible functions allows networks to retain the entirety of input information across all layers, resulting in more dependable gradient computations for model refinement.
Presenting numerous advantages, reversible functions present a departure from the conventional understanding of deep networks, particularly when confronting intricate problems with models not inherently designed to be deep.
Programmable Gradient Information (PGI)
Given the introduction of reversible functions, there arises a need for a new deep neural network training, one that not only produces dependable gradients for model updates but also accommodates shallow and lightweight neural networks.
Programmable Gradient Information emerges as a solution encompassing a primary branch for inference, an auxiliary reversible branch for precise gradient computation, and multi-level auxiliary information to effectively address deep supervision challenges without imposing additional inference overheads.
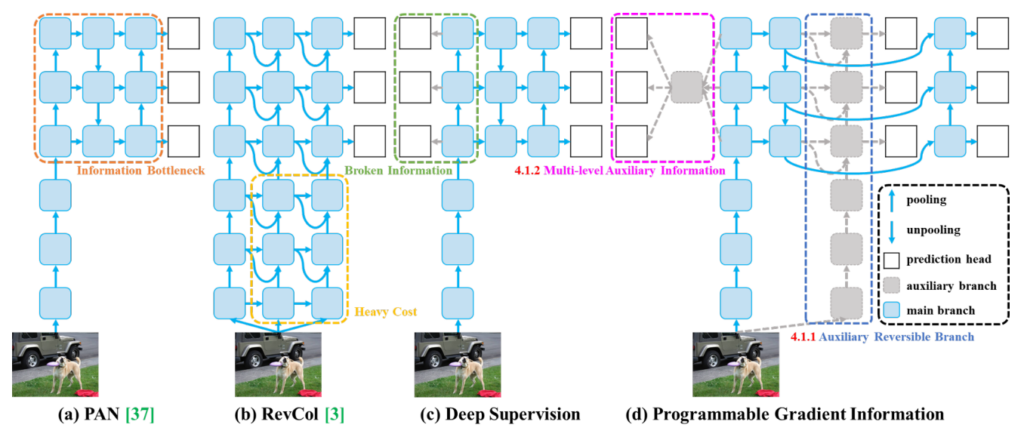
Exploring Programmable Gradient Information within the YOLOv9 framework reveals its intricate design aimed at augmenting model training and efficiency. PGI incorporates an auxiliary supervision node tailored to counteract the information bottleneck in deep neural networks, prioritizing precise and efficient gradient backpropagation. PGI evolves through the integration of three components, each fulfilling a unique yet interconnected role within the model's architecture.
- Main Branch: Optimized for inference, the main branch ensures the model maintains a streamlined and efficient operation during critical phases. Engineered to eliminate the necessity for auxiliary components during inference, it sustains high performance without imposing additional computational burdens.
- Auxiliary Reversible Branch: The auxiliary branch guarantees the generation of dependable gradients and facilitates accurate parameter updates. Leveraging reversible architecture, it mitigates the inherent information loss within deep network layers, preserving and harnessing complete data for learning. This branch's flexible design enables seamless integration or removal, ensuring that model depth and complexity do not compromise inference speed.
- Multi-Level Auxiliary Information: This methodology employs specialized networks to combine gradient information across the model's layers. It addresses the challenge of information loss in deep supervision models, ensuring the data is fully comprehended by the model. This technique enhances predictive accuracy for objects of varying sizes.
Generalized Efficient Layer Aggregation Network (GELAN)
Following the implementation of PGI in YOLOv9, there arises a clear demand for an even more refined architecture to achieve maximal accuracy. This is where the Generalized Efficient Layer Aggregation Network (GELAN) steps in.
GELAN introduces a distinctive design tailored to complement the PGI framework, thereby enhancing the model's capacity to process and learn insights from data more adeptly. While PGI tackles the challenge of preserving vital information throughout deep neural networks, GELAN further advances this groundwork by furnishing a versatile and efficient structure capable of accommodating diverse computational blocks.
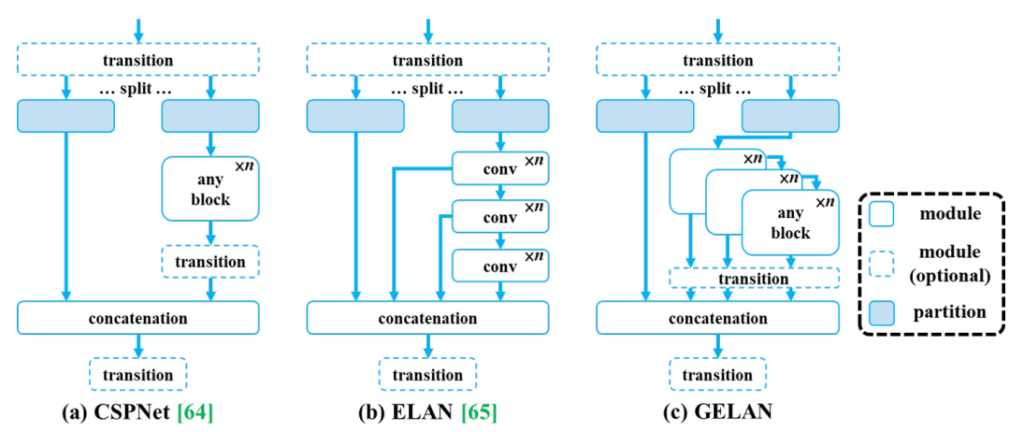
In YOLOv9, the GELAN combines the finest qualities of CSPNet's gradient path planning and ELAN's speed optimizations during inference. This versatile architecture seamlessly integrates these characteristics, elevating the YOLO family's hallmark real-time inference prowess. GELAN stands as a lightweight framework that emphasizes swift inference while upholding accuracy, thereby broadening the utility of computational blocks.
YOLOv9 Performance Comparison
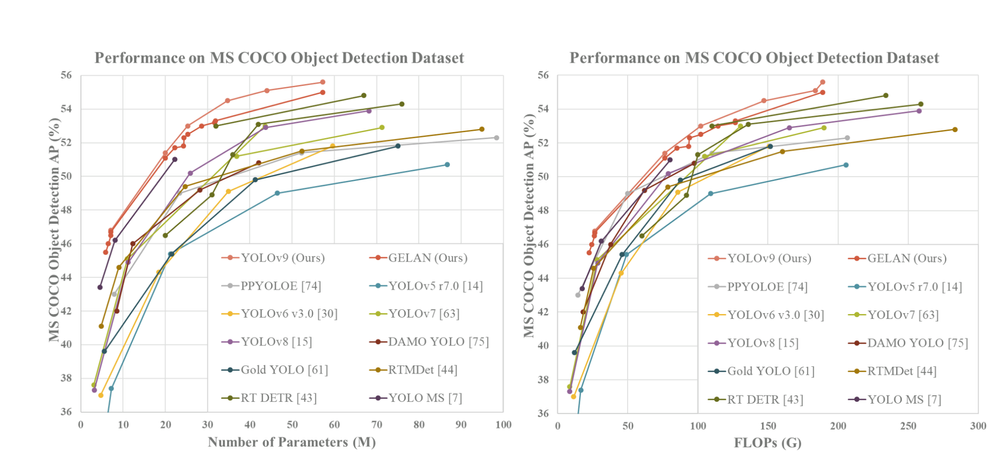
Among existing methods, the most effective ones encompass YOLO MS-S for lightweight models, YOLO MS for medium models, YOLOv7 AF for general models, and YOLOv8-X for large models.
In comparison to YOLO MS for lightweight and medium models, YOLOv9 boasts around 10% fewer parameters and necessitates 5-15% fewer computations, while still demonstrating a 0.4-0.6% enhancement in Average Precision (AP).
Contrasted with YOLOv7 AF, YOLOv9-C exhibits a reduction of 42% in parameters and 22% in computations while achieving a similar AP (53%). Lastly, compared with YOLOv8-X, YOLOv9-E showcases a decrease of 16% in parameters, 27% in computations, and a notable improvement of 1.7% in AP.
Conclusion
YOLOv9 marks an advancement in real-time object detection performance over prior YOLO models, delivering substantial enhancements in efficiency, accuracy, and versatility. Through groundbreaking approaches such as PGI and GELAN, YOLOv9 not only tackles key challenges but also establishes a fresh standard for future endeavors in the domain.
If you are interested in learning more about YOLOv9, Roboflow has several resources to help:
- How to Train YOLOv9 on a Custom Dataset (blog post)
- YOLOv9 training guide (video)
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (May 20, 2024). What is New in YOLOv9? An Architecture Deep Dive.. Roboflow Blog: https://blog.roboflow.com/yolov9-deep-dive/