
Let’s dive in and explore how AI image analysis turns pictures into smart decisions. But first, some quick background: It’s a busy Saturday morning at the supermarket. The store manager heads to aisle five, expecting the snack shelves to be fully stocked for the weekend crowd. But before he even gets there, his tablet buzzes with a message: “Chips shelf empty – Row 3, Section B.” He opens the notification and sees a live image from a camera above the aisle. A red box highlights the exact spot where the chips are missing. He doesn’t need to walk the aisle or wait for a staff member to notice, it has already been taken care of.
That’s because an AI system is constantly watching the shelves. It can tell when something runs out, matches it against the store’s layout, and even figures out how long the space has been empty. In the past, restock delays meant customers walked away disappointed and sales were lost. Now, thanks to AI image analysis, the system helps keep shelves full and operations smooth.
Cameras are not just recording anymore, they are analyzing, comparing, and making decisions. In retail, this kind of AI can track stock levels, map customer movement, and even detect unusual behavior. But how does it all work? How can a computer tell when something is missing from a shelf?
What Is AI Image Analysis?
AI Image Analysis refers to the process of using artificial intelligence (AI) to automatically interpret and extract meaningful information from digital images. This enables machines to "see" and understand visual data in a way that mimics or even surpasses human visual comprehension in specific tasks. In other words, AI Image Analysis refers to the use of artificial intelligence, particularly machine learning and deep learning, to automatically process and understand images. It enables systems to:
- Detect and classify objects (e.g., people, cars, animals)
- Recognize faces and emotions
- Identify patterns, anomalies, or defects
- Read and extract text (OCR)
- Segment different regions of an image (e.g., tumor vs. healthy tissue)
- Generate captions or summaries of what’s in an image
Is there an AI that can analyze images?
Yes, modern AI has advanced to the point where it can not only view images but also understand, interpret, and analyze them much like a human would, and in some cases, even better. This capability is known as AI image analysis, and it is powered by deep learning models specifically trained to process visual data.
These AI systems can perform a wide range of tasks on images, such as:
- Identifying objects (e.g., cats, cars, tumors)
- Classifying scenes (e.g., beach, forest, supermarket)
- Segmenting regions (e.g., separating a dog from the background)
- Detecting anomalies or defects (e.g., cracks in machinery)
- Understanding text within images (OCR)
- Answering questions about an image (e.g., “How many people are in this photo?”)
We can categorize such AI into the following:
- Computer Vision Foundation Models
- Vision Language Models
- Multimodal Models
- LLM with Vision Capabilities
Computer Vision Foundation Models
These models are trained only on image data and are primarily built using Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs). These are state-of-the-art computer vision model architectures, immediately usable for training with your custom dataset. They are designed to solve specific vision tasks like classification, detection, segmentation, and 3D understanding. These models are sub-categorized into following based on the task it can perform:
Image Classification Models
Image classification models are used to assign a single label to an entire image. E.g. Resnet-50.

Object Detection Models
Object detection models can locate and classify multiple objects with bounding boxes.
Example: RF-DETR.

Image Segmentation Models
Image segmentation models assign a label to each pixel (semantic or instance segmentation).
Example: YOLOv8 Instance Segmentation.

Keypoint Detection/Pose Estimation Models
These models detects keypoints like joints or facial landmarks to analyze body movements.
Example: YOLO NAS Pose, YOLOv8 Pose Estimation.

Vision-Language Model (VLM)
A VLM is a pretrained model specifically designed to process both images and language jointly. It serves as a base model for fine-tuning across a wide range of downstream tasks like captioning, visual Q&A, and image-text retrieval. VLMs are trained on large-scale image-text pairs and are often used as a backbone in multimodal AI systems.
Example: PaliGemma, Florence-2
Multimodal Model
A Multimodal Model is an AI system that can reason across across multiple data modalities, such as text, images, audio, and video. Since these models understand image, it can be used for AI image analysis.
Example: GPT-4o, Google Gemini
LLM with Vision Capabilities
This refers to large language models (LLMs) like GPT or Claude that have been extended to accept images as input and analyze and reason about visual content in natural language. It has language-first architecture with added vision interface and is trained or fine-tuned with image-text-pair datasets.
Is There an AI that Describes Images?
Yes, there are AI capable of describing images. Describing an image is a key part of AI-powered image analysis, and it falls under a category known as Image Captioning or Vision-Language Understanding. In describing the image, AI automatically generates textual descriptions for the given images by understanding what is in the image. These AI systems integrate computer vision to interpret images and natural language processing to describe image, enabling machines to interpret visual data and explain it in a human-readable format. It is done in following steps:
- Step #1: Analyze the image to identify objects, people, scenes, actions, and spatial relationships.
- Step #2: Understand the context (e.g., what’s happening, who is doing what).
- Step #3: Generate a coherent sentence that reflects this understanding.
It involves the following:
- Object detection: What things are present?
- Action recognition: What are they doing?
- Scene understanding: Where is this taking place?
- Visual relationships: How do objects relate to each other?
So, describing an image is not just a language task, it is deeply rooted in visual analysis.
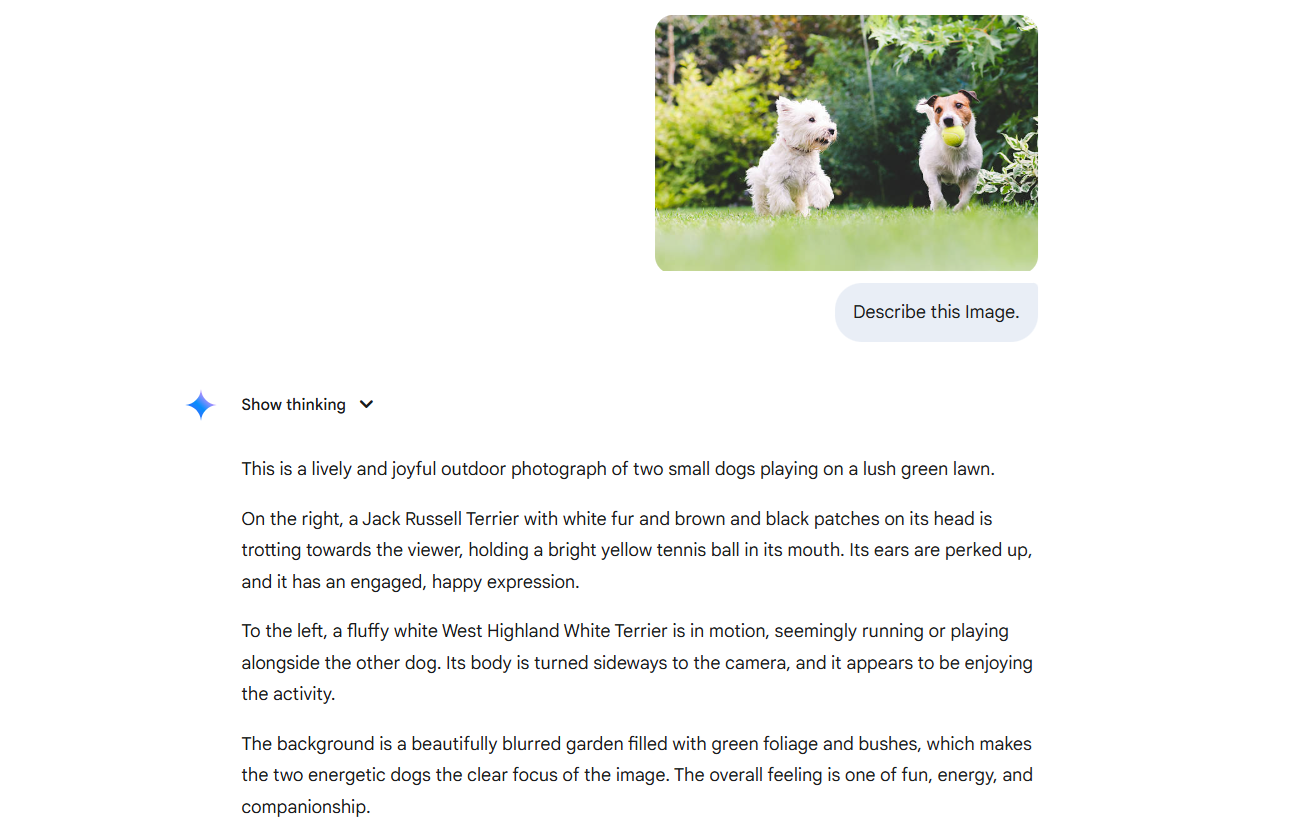
How Does AI Describing an Image Works?
Let’s understand how the AI that describes image works with an example of PaliGemma, a vision language model (VLM) by Google that has multimodal capabilities. Due to it’s multimodal capabilities, it can be used to describe images.
The diagram illustrates how PaliGemma processes an image and a text prompt to generate a natural language response, showcasing its multimodal reasoning capability, particularly for tasks like visual question answering (VQA).
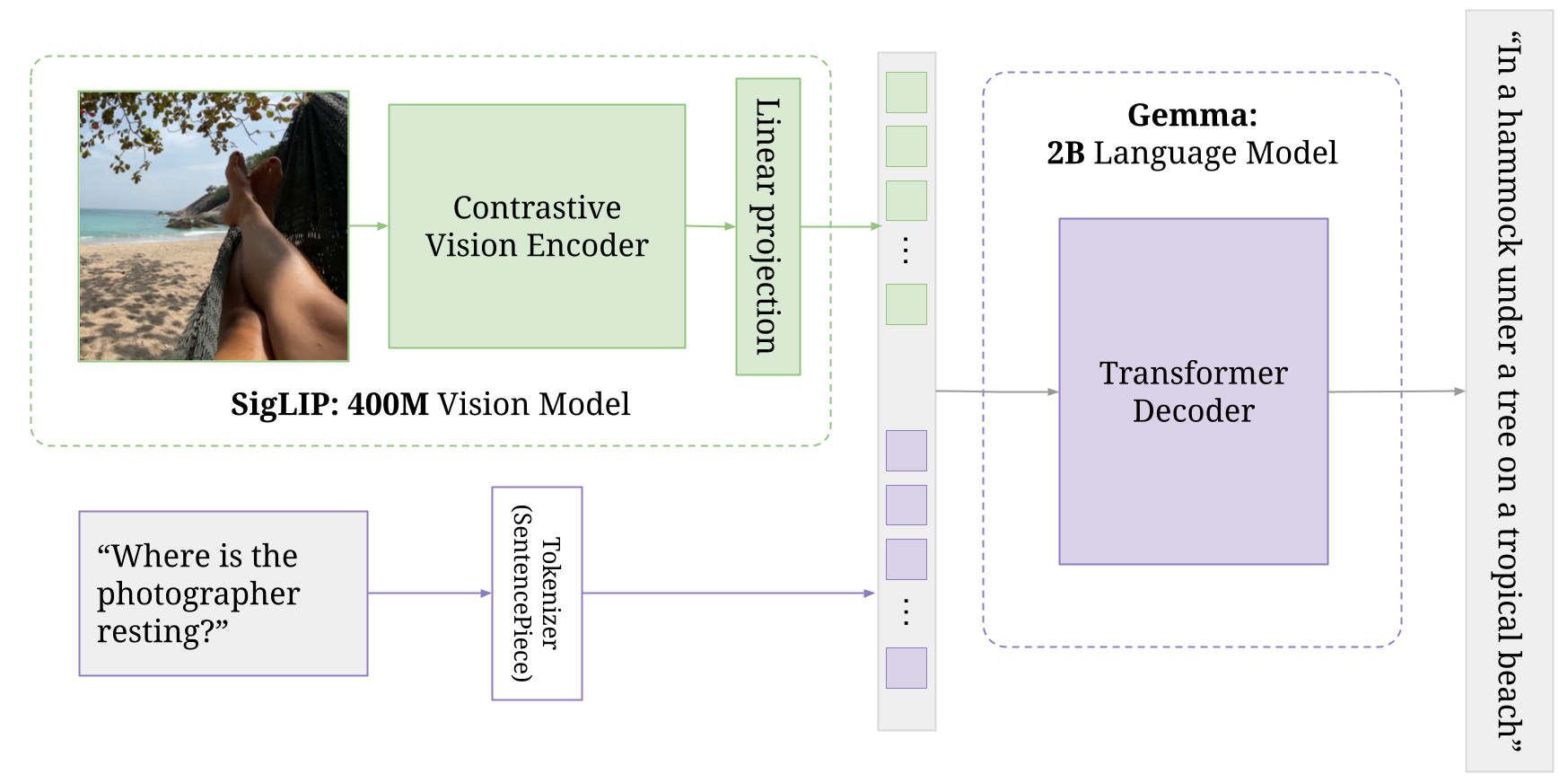
The workflow illustrated in the image above demonstrates how PaliGemma processes an image along with a natural language question to generate an intelligent, grounded response. The input consists of a photo showing someone resting in a hammock on a tropical beach, and a text prompt asking, “Where is the photographer resting?” This image is first passed through a contrastive vision encoder called SigLIP, a compact vision model with 400 million parameters. SigLIP extracts high-level visual features from the image (such as the hammock, tree, feet, and beach) and converts them into dense numerical representations. These visual embeddings are then transformed through a linear projection to match the input format expected by the decoder, enabling alignment between visual and textual information.
Meanwhile, the question is tokenized using SentencePiece, a subword tokenizer that breaks down the sentence into tokens that the model can understand. Both the visual features and the tokenized question are fed into the Gemma language model, a 2-billion parameter transformer decoder. Gemma uses this multimodal context, combining what it sees and what it’s asked, to generate a coherent, contextually accurate answer. Finally, the model produces the response, “in a hammock under a tree on a tropical beach.”. This illustrates how PaliGemma performs multimodal reasoning, effectively interpreting and connecting visual content with natural language to provide detailed answers, rather than simply identifying objects or generating generic captions.
What Is the Role of Computer Vision in AI Image Analysis?
Computer vision serves as the foundational technology behind AI-powered image analysis, enabling machines to perceive and understand the content of visual data such as images and videos. At its core, computer vision enables converting raw pixel values into meaningful representations that an AI system can interpret and act upon. This is achieved through advanced algorithms and deep learning models (e.g., CNNs, Vision Transformers) that are capable of identifying patterns, shapes, edges, textures, and colors within an image. These learned visual features are essential for downstream tasks such as object recognition, segmentation, and scene understanding.
One of the primary roles of computer vision is object detection and recognition, which allows AI systems to identify and locate various objects in an image (such as people, vehicles, animals, or tools) by drawing bounding boxes around them and labeling each one with a class name. Beyond detection, computer vision also enables semantic and instance segmentation, which involve classifying each pixel in an image according to its object class (e.g., sky, road, car) or distinguishing between multiple instances of the same object class.
Computer vision also plays a pivotal role in specialized analysis tasks. In optical character recognition (OCR), it allows AI to detect and extract text from images, enabling document digitization and language translation. In pose estimation, it helps identify and track key points on the human body, which is useful in fitness apps, gesture recognition, and human-computer interaction.
Computer vision also powers multimodal AI systems, where visual information is combined with text or audio inputs to perform more complex tasks. For example, in models like PaliGemma, computer vision is what allows the model to "see" the image. Specifically, a vision encoder like SigLIP processes the input image, for example, someone resting in a hammock on a beach, and extracting high-level features such as the hammock, tree, and sand. With the help of computer vision, the model does not just recognize objects, but it also understands the scene and provides context-aware responses. The computer vision provides the visual understanding foundation that powers intelligent, multimodal reasoning in image description tasks like those performed by PaliGemma.
As described in the paper, the SigLIP architecture is built upon the foundation laid by CLIP. The SigLIP architecture consists of image encoder, text encoder and sigmoid-based loss function. SigLIP uses a Vision Transformer (ViT) as the image encoder. The ViT processes images by dividing them into fixed-size patches, which are then linearly embedded and fed into a transformer encoder. This allows the model to capture both local and global dependencies within the image.
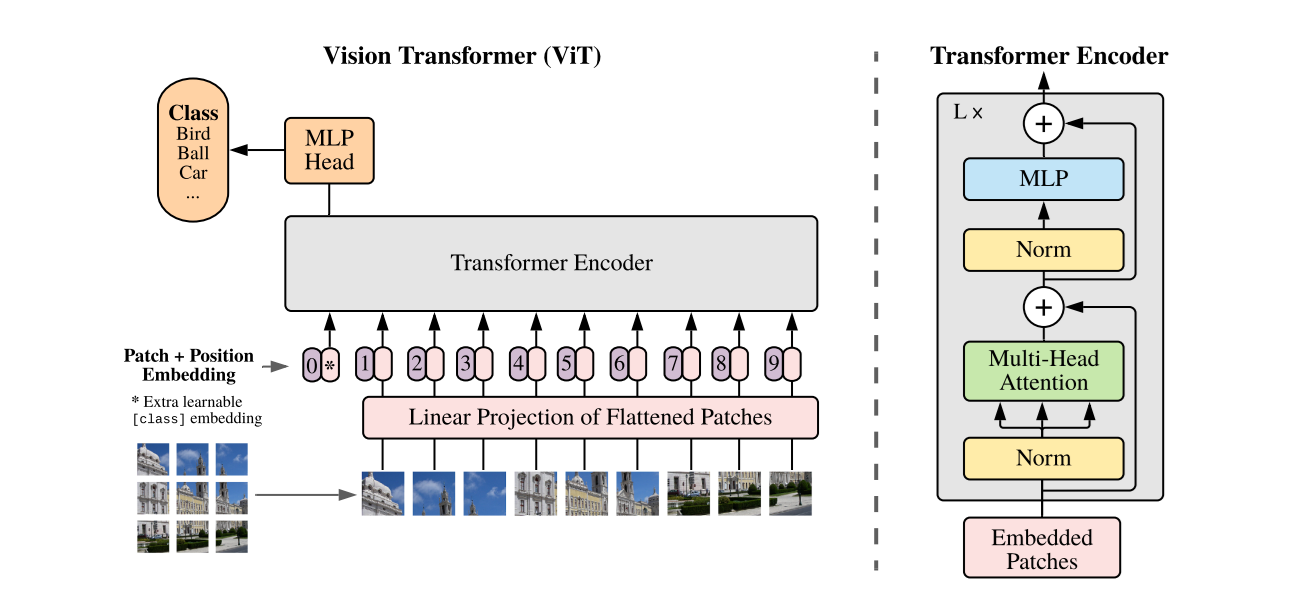
Thus ViT, a model architecture that uses the Transformer architecture for image processing tasks in computer vision, serves as a foundational component for understanding images in SigLIP.
Examples of Analyzing Images Using AI
Analyzing images using AI involves extracting meaningful information from visual data. The following are the common AI-powered image analysis tasks. We utilize Roboflow Workflows for our examples in this section.
Read Text from Images (Optical Character Recognition – OCR)
Reading text from images involves detecting and extracting printed or handwritten characters from visual content. This task requires identifying regions in the image that contain text, recognizing the individual characters, and converting them into machine-readable text. OCR systems are trained to handle different fonts, sizes, orientations, and even noisy or low-quality images. The process often includes text detection, text recognition, and post-processing for formatting.
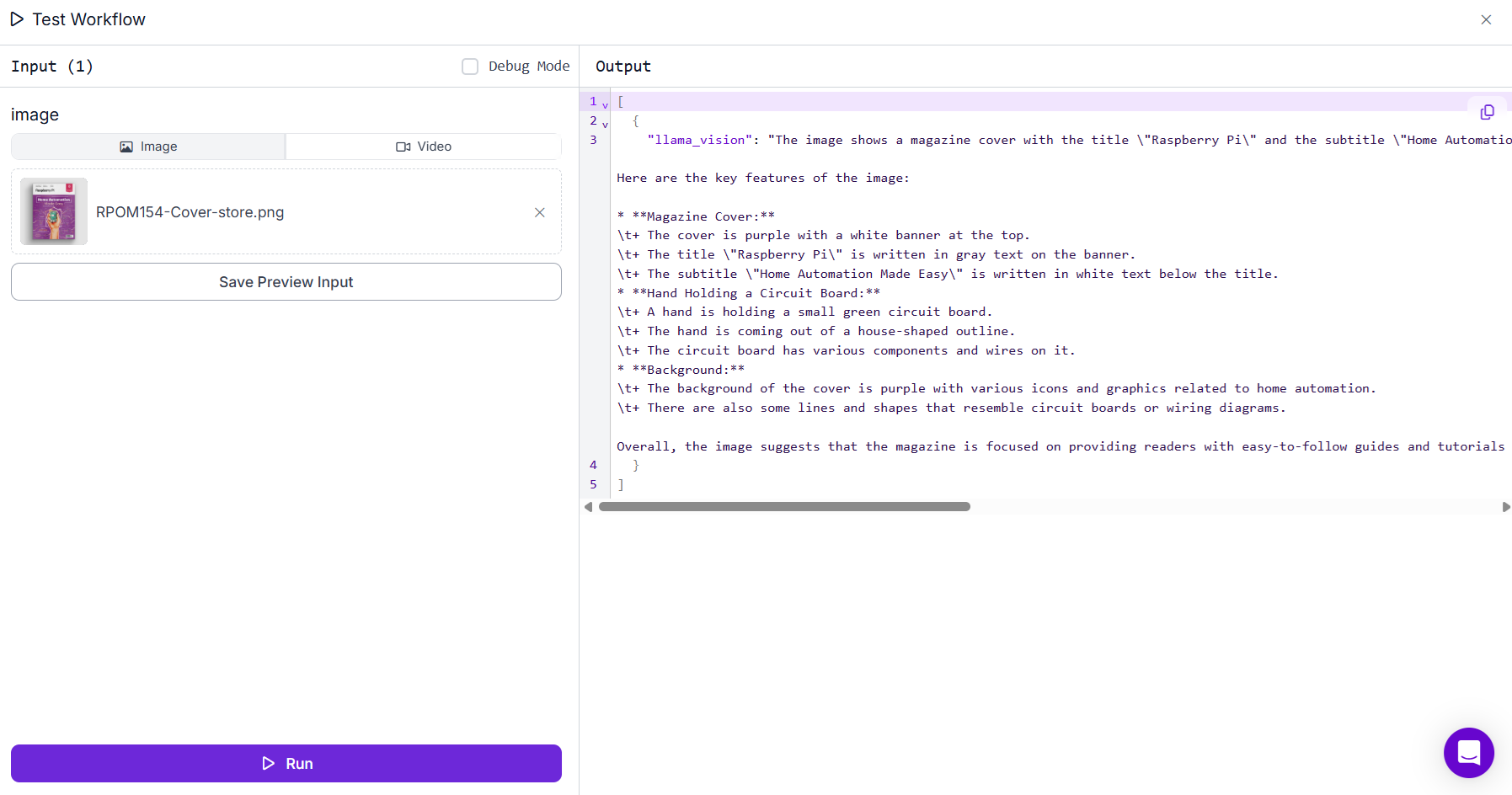
For this example we will use Llana 3.2 Vision model to extract text from images. Following the workflow with Llama 3.2 Vision configuration.
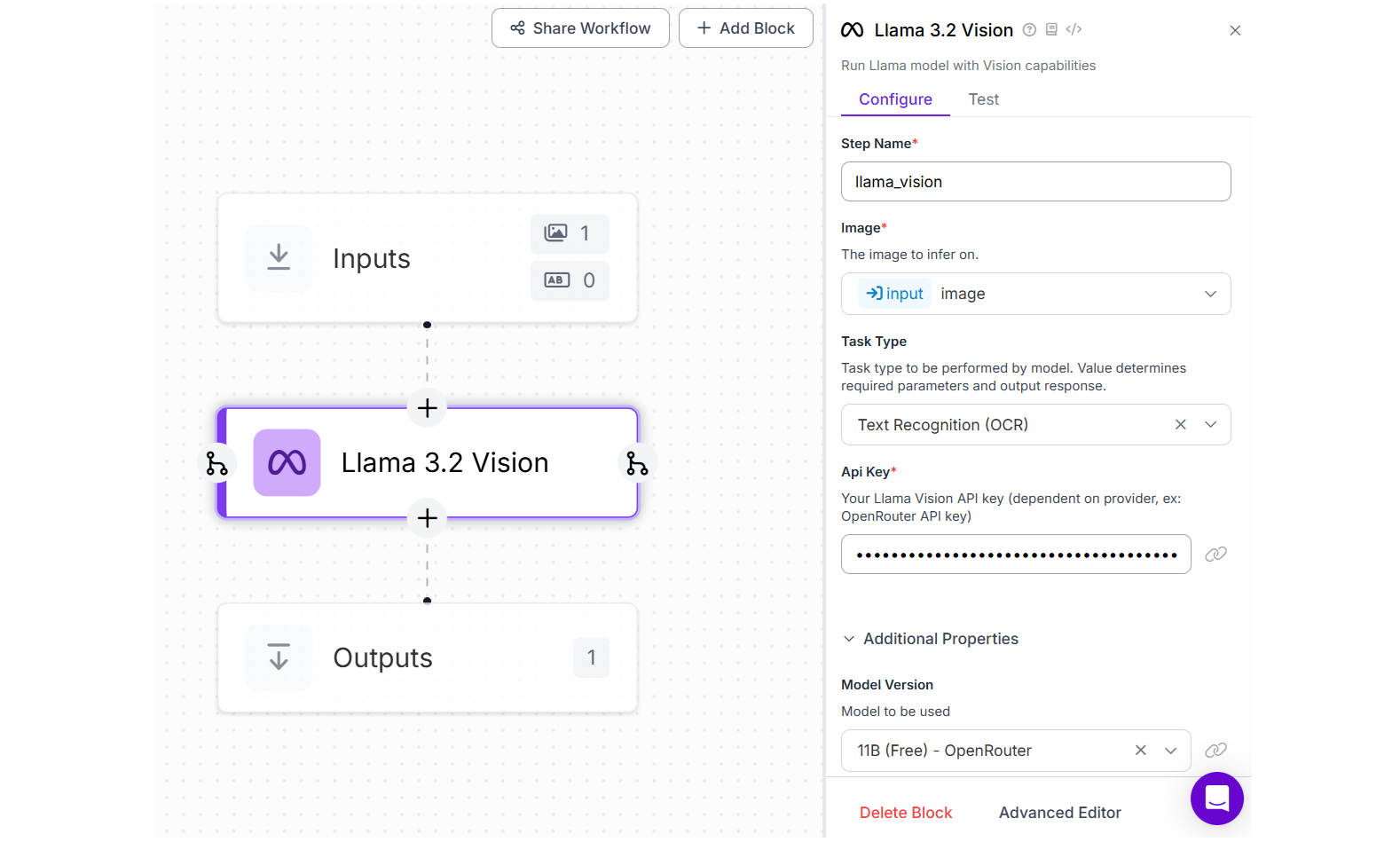
When run the Workflow and upload any image with text, you should see output like following.
Detect People in Images
Detecting people in images involves locating and identifying human figures within a visual scene. The task uses object detection techniques to draw bounding boxes around individuals and classify them as "person." It may also include counting, tracking movement, or analyzing poses. Models are trained on varied datasets to handle different angles, lighting, clothing, and occlusions. This is commonly used in surveillance, crowd analytics, and autonomous systems.
For this example we will use People Detection model from Roboflow. Create a Roboflow workflow as following with the object detection block configured with people detection model and class filter as “person”. Also add Bounding Box Visualization and Label Visualization blocks. Your Workflow should look like following.
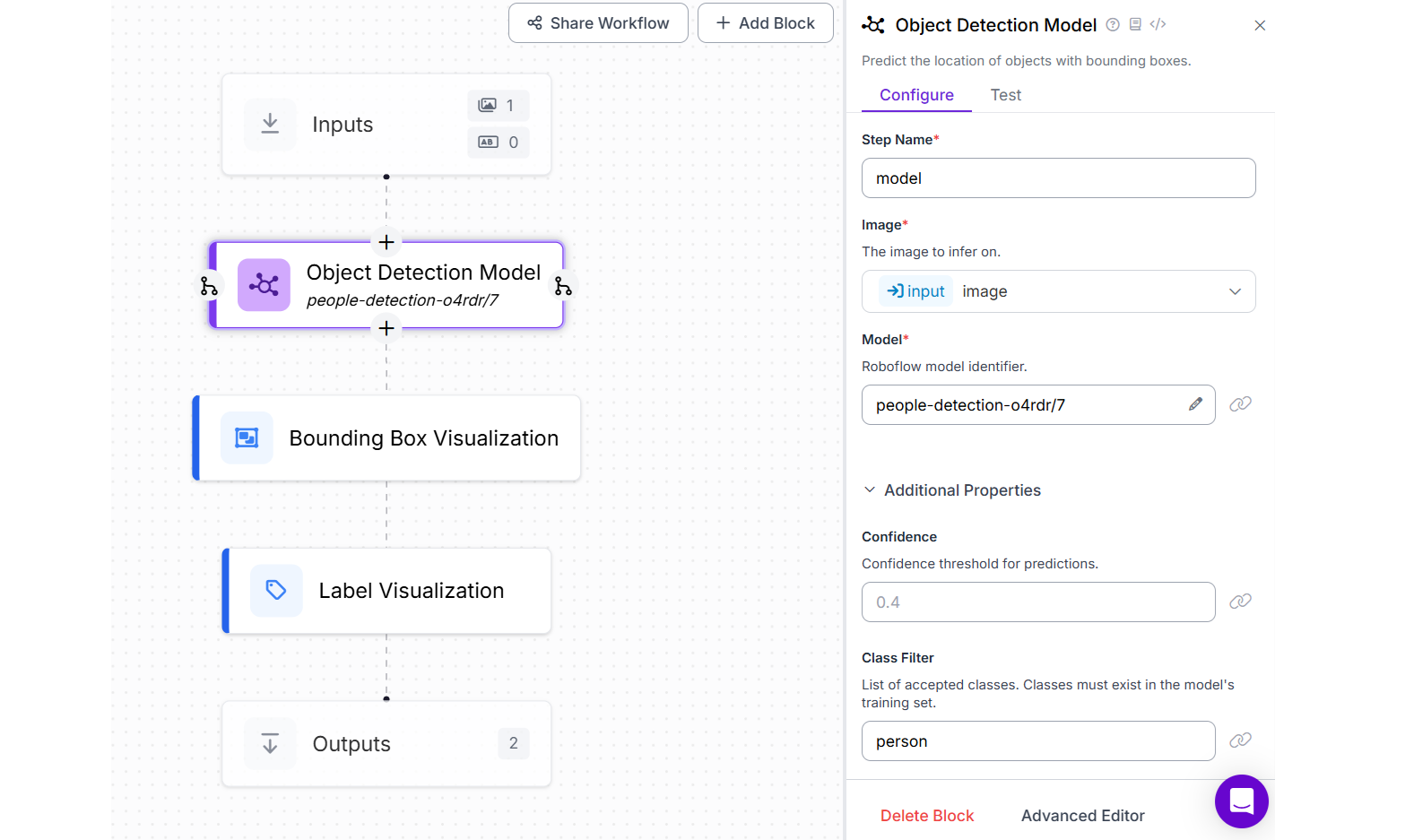
Running the workflow will produce output similar to following.

Detect Objects in Images
Object detection involves identifying and localizing multiple objects within an image, each with a bounding box and label. The task includes recognizing different classes of objects (like cars, people, animals, tools) and determining their positions. Unlike image classification, which assigns one label to the entire image, object detection outputs multiple detections per image. It is widely used in robotics, retail, manufacturing, and autonomous vehicles.
For this example we will utilize the same Workflow as above. Just change model to RF-DETR Base and set the class filter to “football” as this time we are detecting an object instead of people.
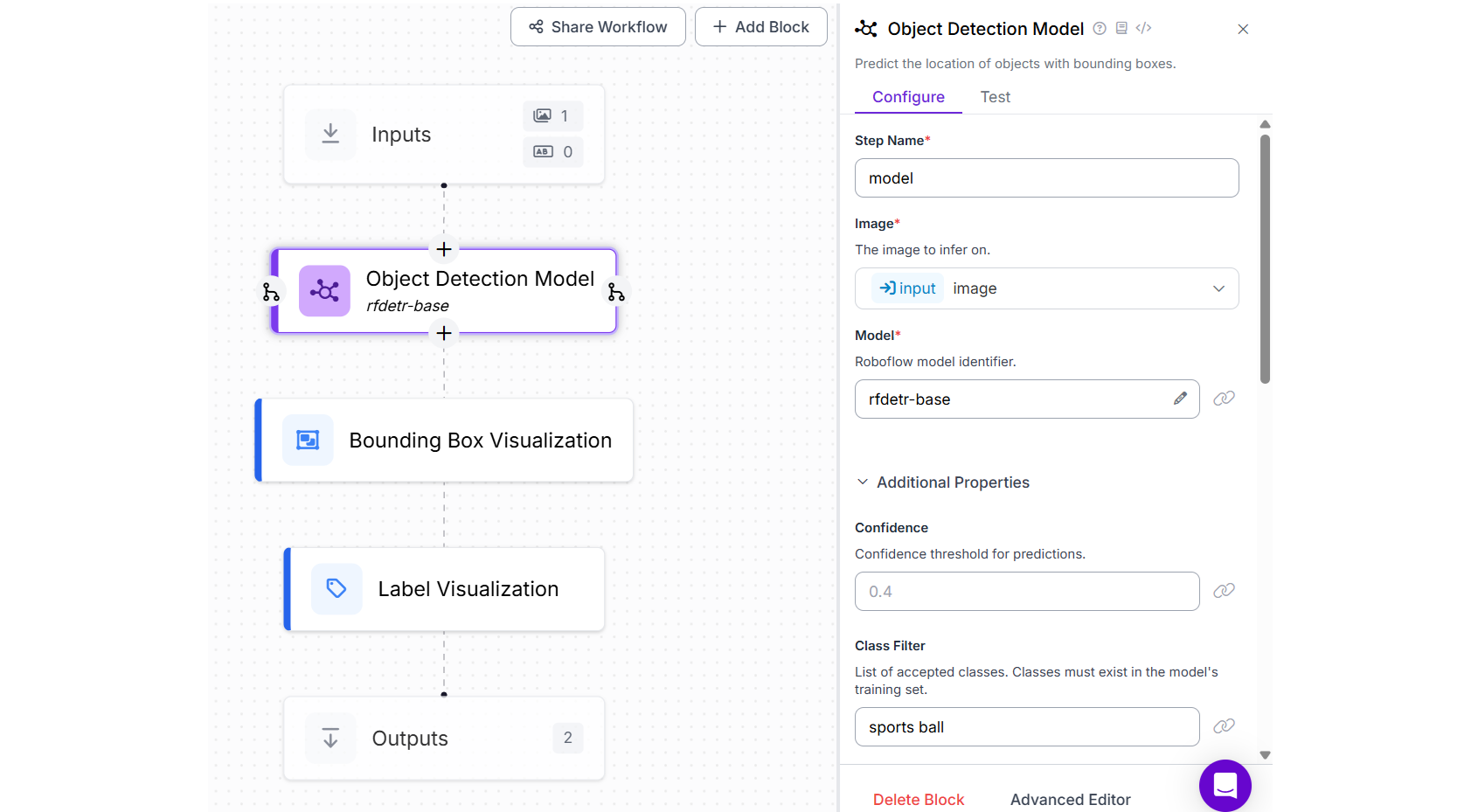
You will see output similar to the following.

Detect Keypoints in Images (Pose Estimation / Landmark Detection)
Keypoint detection involves identifying specific, meaningful points on an object or a person in an image, such as joints (elbows, knees) in human pose estimation or facial landmarks (eyes, nose, mouth). These points are used to understand the posture, orientation, or structure of the object. Keypoint detection is widely used in human activity recognition, fitness tracking, facial recognition, gesture control, and animation.
For this example, create a Workflow and add Keypoint Detection Block configured with YOLOv8 Nano Pose model from the available public models. After that add Keypoint Visualization Block and set the Annotator Type property to “vertex_label”.
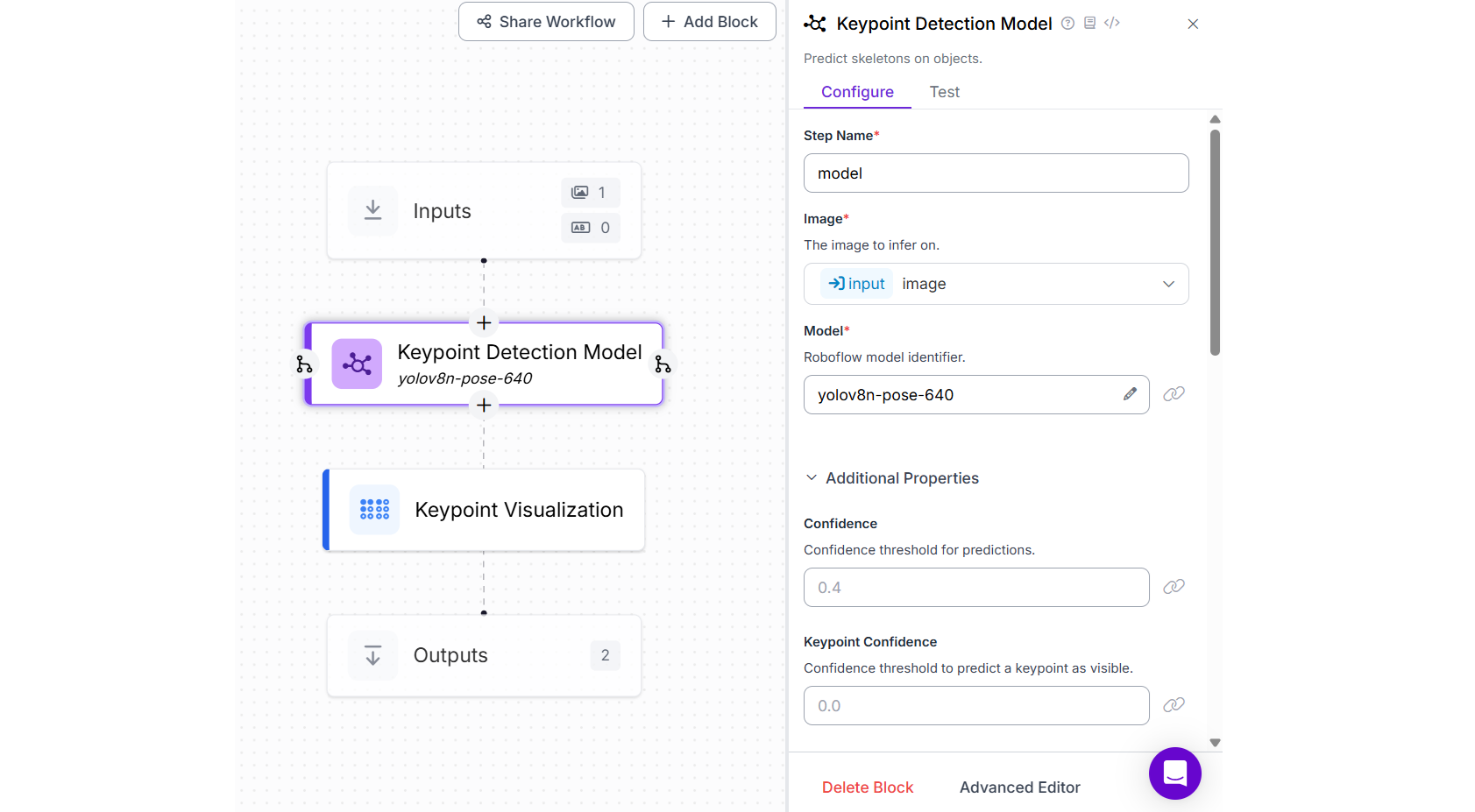
When you run the Workflow, you should see the output as follows.

Segment Objects in Images (Image Segmentation)
Object segmentation involves dividing an image into distinct regions by labeling each pixel according to the object it belongs to. There are two main types:
- Semantic segmentation: Labels each pixel by object class (e.g., “car”, “tree”).
- Instance segmentation: Distinguishes between different instances of the same object class (e.g., two separate “persons”).
Segmentation provides much finer-grained understanding than bounding boxes and is critical for medical imaging, autonomous vehicles, agriculture, and robotics.
For this example, create a Roboflow Workflow by adding Instance Segmentation Block and choosing the YOLOv8 Nano Segmentation model from the available public models. Set the Class filter property of this block to class name “sports ball” as we will be segmenting the detected sports ball in the image. For visualizing the segmentation mask, add Mask Visualization block.
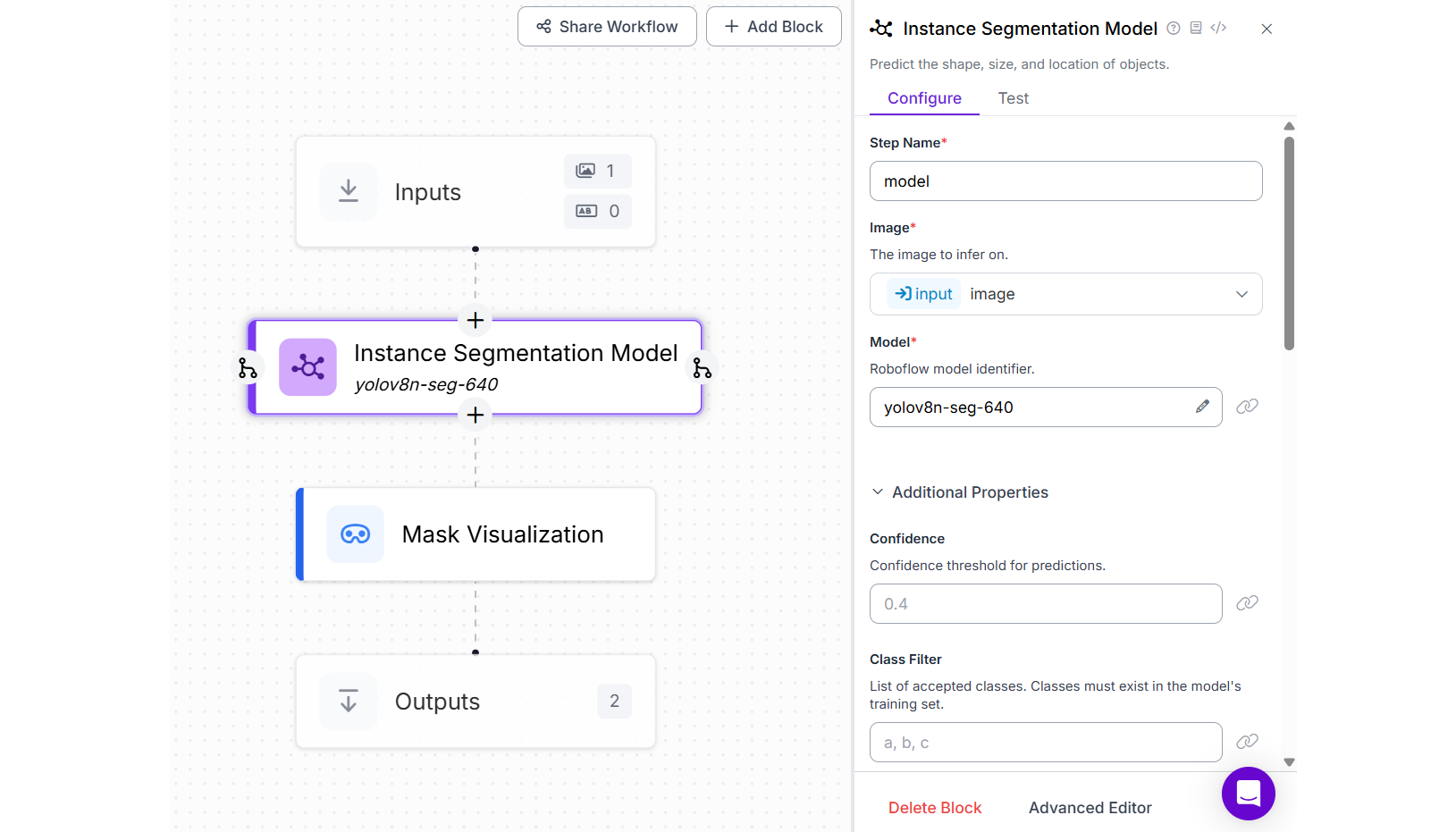
When you run this Workflow you should see output similar to the image below displaying the segmented object.

Document AI
Document AI involves the intelligent analysis of structured and unstructured documents to extract relevant information. It combines OCR, layout analysis, and natural language processing (NLP) to understand forms, tables, invoices, and reports. The system identifies sections like headers, key-value pairs, tables, and handwritten annotations. It’s used to automate workflows like invoice processing, contract analysis, and identity verification.
For this example, create a Roboflow Workflow and add Object Detection Model block. Then configure the Object Detection Model with publicly available Table and Figure Identification model from Roboflow Universe. Now add a Dynamic Crop block the will detect and crop the predicted table and/or figure. Finally add OpenAI block and select model type as “gpt-4o”. This OpenAI block takes cropped image as input from Dynamic Crop block and describe the table and figure within the document.
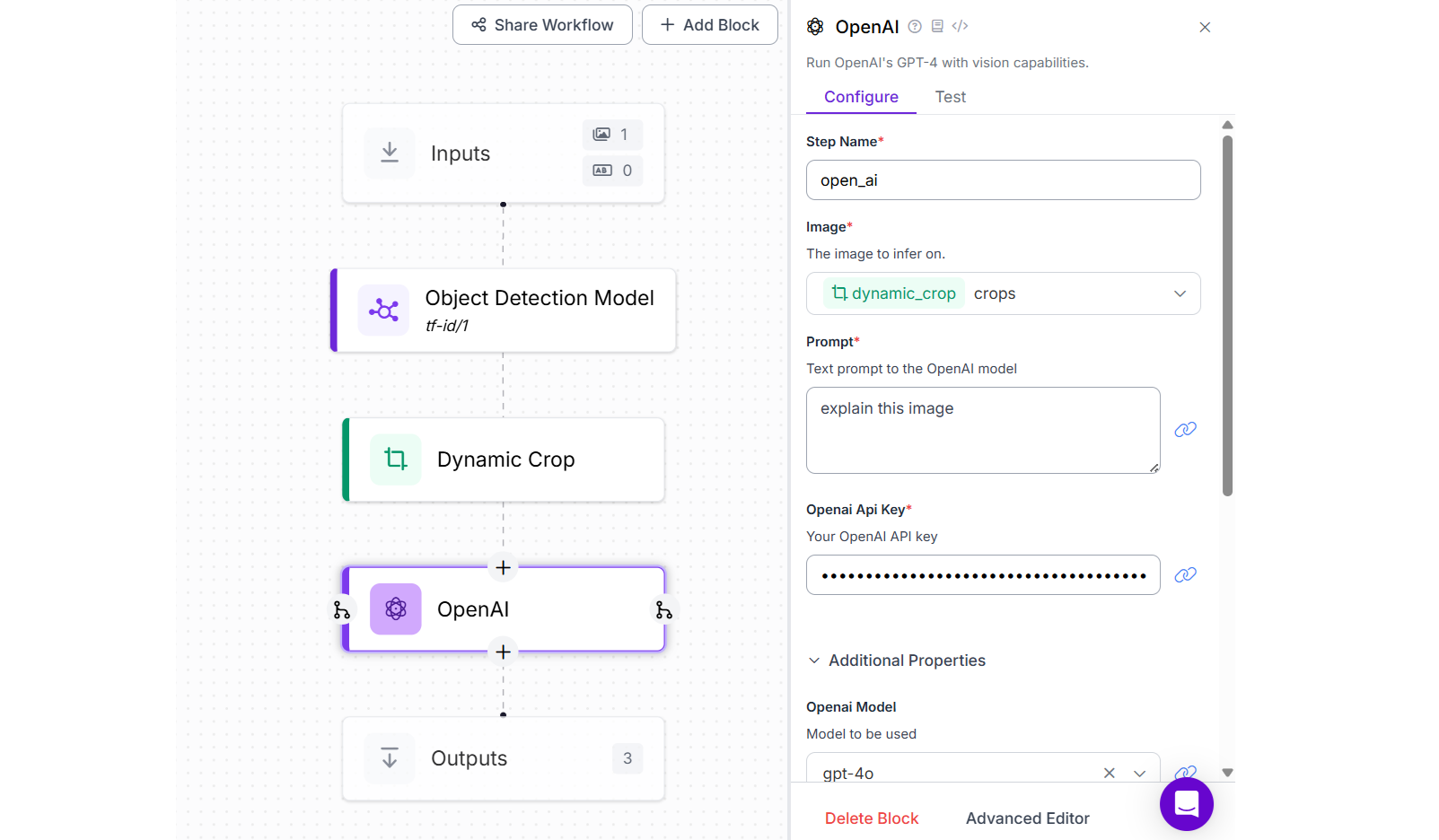
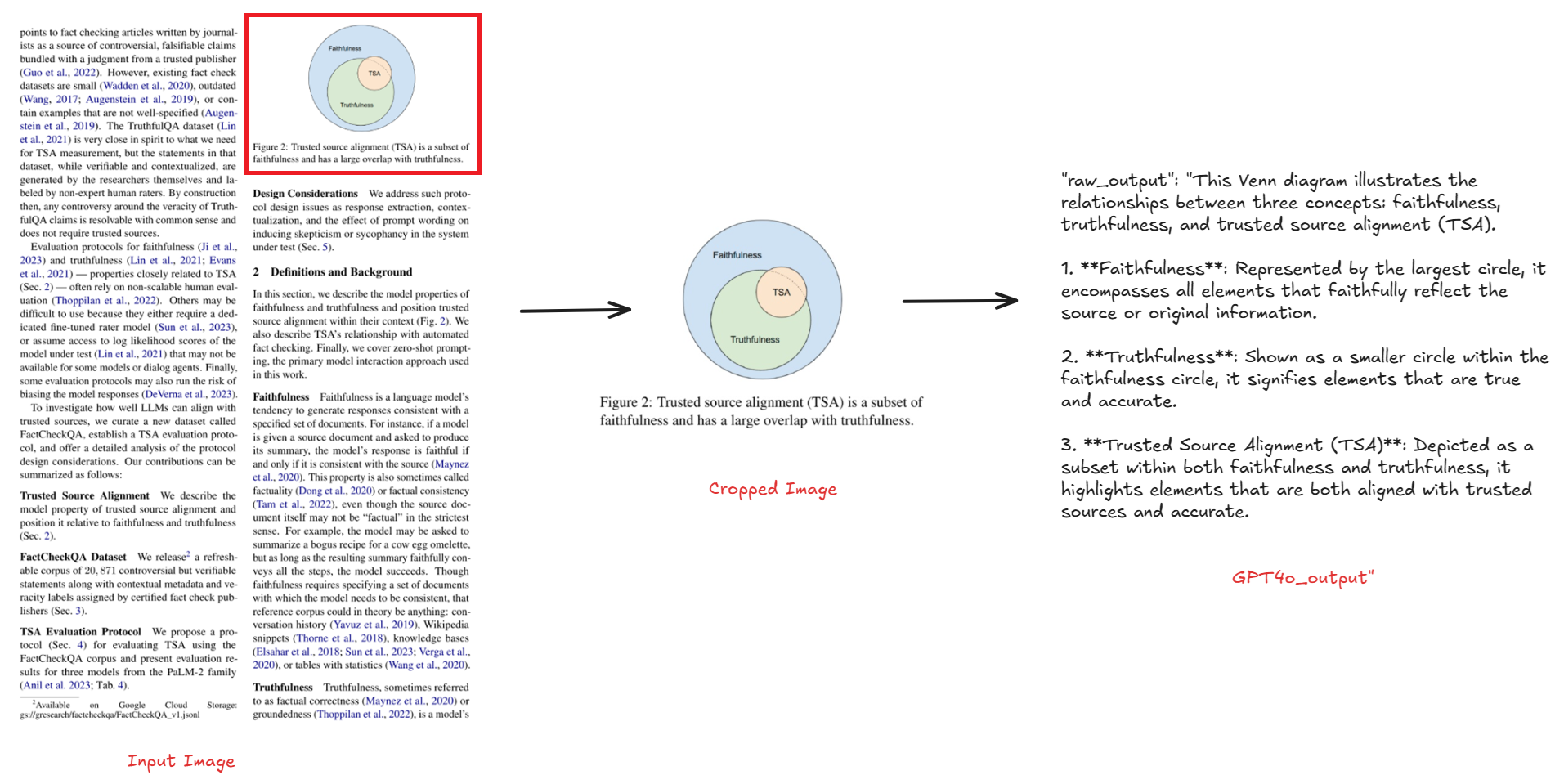
As shown in the image below, when you run the workflow with input image of a page of a document containing figure/table, the detected figure/table will be cropped and explained by “gpt-4o”.
Generate Image Captions (Image Captioning)
Image captioning involves analyzing an image and generating a textual description that captures the key elements and context of the image. This task requires understanding the objects, actions, and relationships depicted in the image and translating them into a coherent sentence. The goal is to generate a natural language sentence that describes the entire image.
For this example, create a Roboflow Workflow by adding OpenAI block and choose the Model Version as “gpt-4o”.
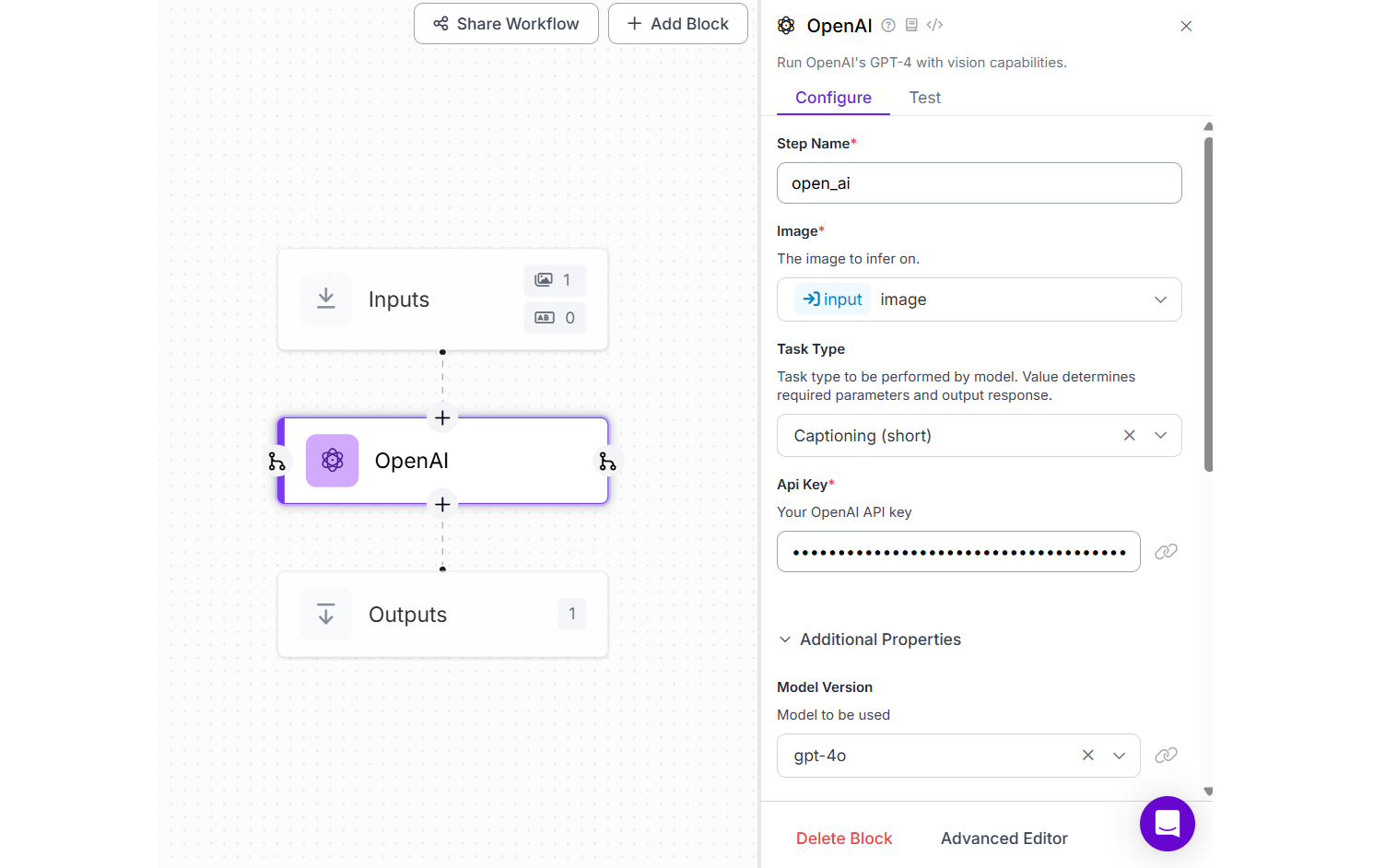
Running the workflow with the following input image,

You should see the following response.

Visual Question Answering (VQA)
VQA involves understanding both the visual content of an image and the textual content of a question, then generating an accurate answer based on the visual clues in the image. The goal is to answer a specific question about an image using visual reasoning.
For this example, create a Roboflow Workflow with input block accepting image and a text prompt. Now add the Google Gemini Block and choose Task Type as “Visual Question Answering” and bind the Prompt property with the variable prompt that you specified in the input block.
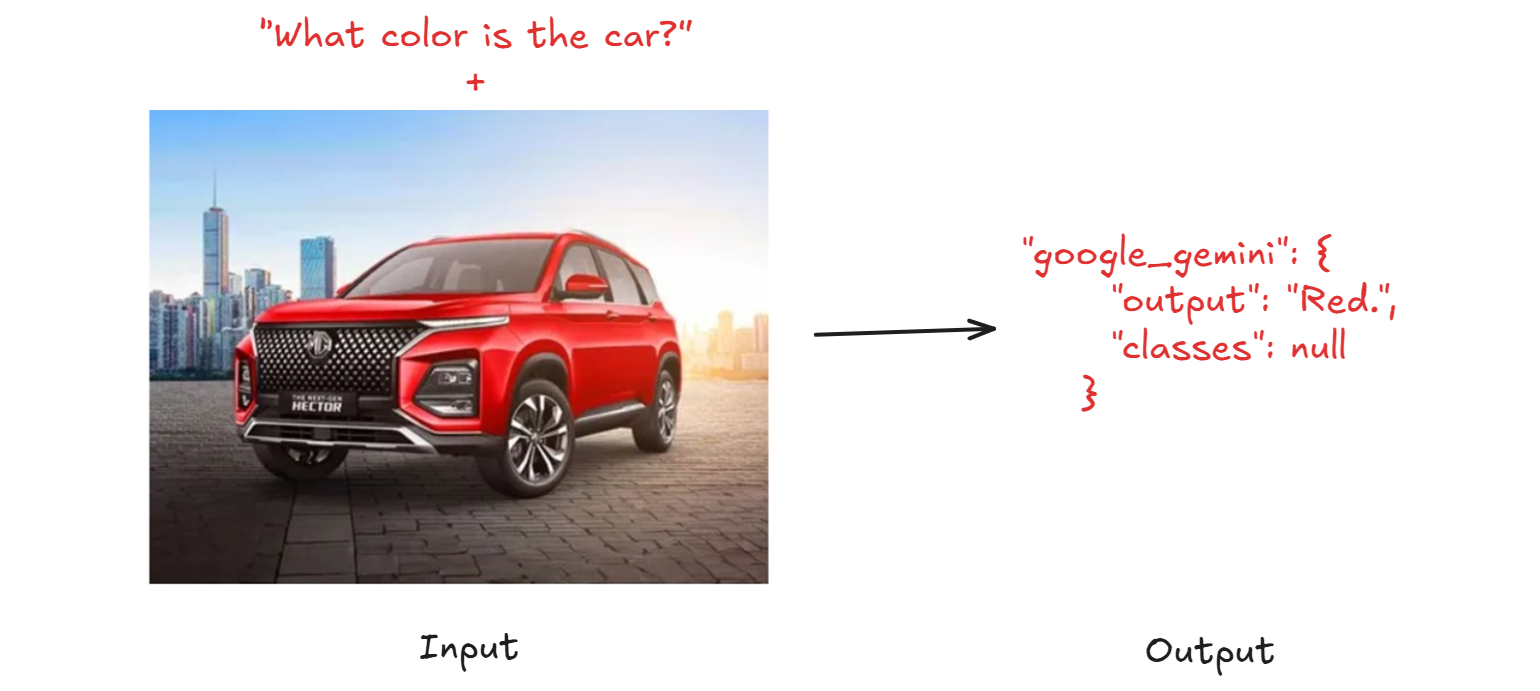
As shown in image below, when you run the workflow with image of a red car and question “What color is the car?” as input, you will see out “car”.
Visual Reasoning / Referring Expression Generation
This task involves identifying and describing specific objects or regions within an image based on contextual cues or questions. It requires understanding the relationships and attributes of objects in the image. The goal is to describe or point to a specific object or region within an image based on context or a question.
For this example, create a Roboflow Workflow with input block accepting image and a text prompt. Now add the Google Gemini Block and choose Task Type as “Open Prompt” and bind the Prompt property with the variable prompt that you specified in the input block.
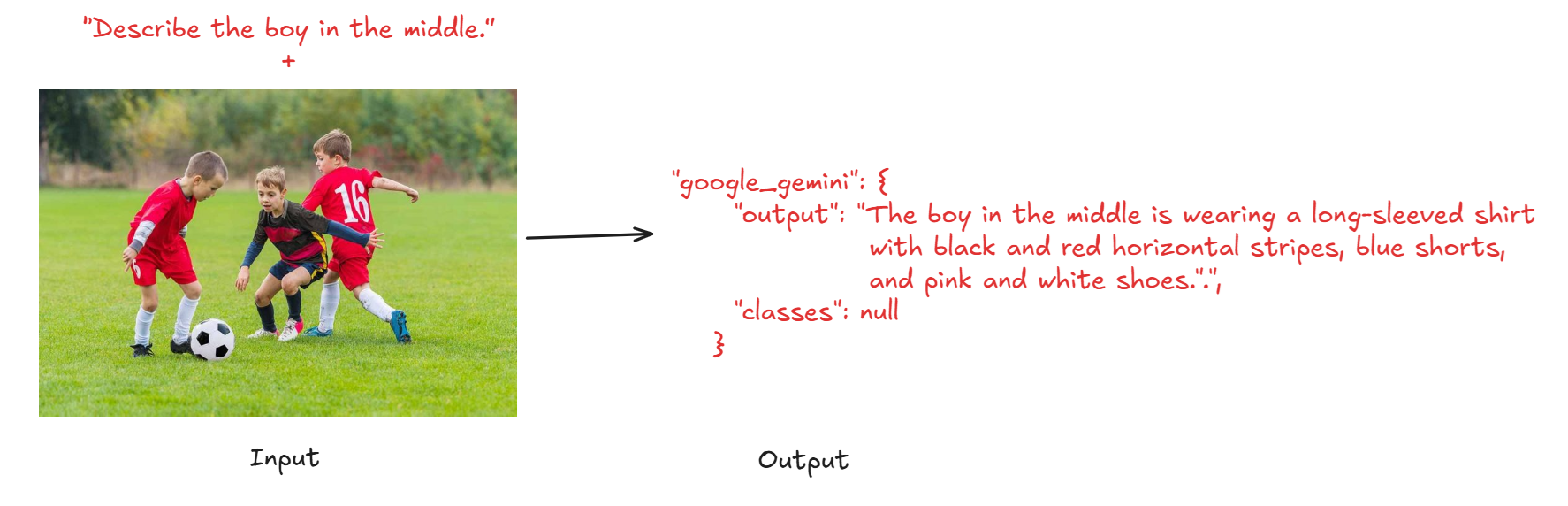
When you run the workflow with input image and a prompt “Describe the boy in the middle.” (left), you will see out “The boy in the middle is wearing a long-sleeved shirt with black and red horizontal stripes, blue shorts, and pink and white shoes.” (right).
In this blog we explored AI Image Analysis, detailing how artificial intelligence enables machines to interpret, understand, and act on image data. From retail shelf monitoring to complex multimodal reasoning models like PaliGemma, it showcases real-world applications and model categories, from core computer vision to advanced vision-language AI.
Key Takeaways: AI Image Analysis
AI is transforming how we interpret images, from recognizing products on store shelves to understanding complex visual scenes through language. Below are the main takeaways that highlight the power and depth of AI image analysis.
- AI-Powered Automation in Visual Tasks: AI can detect missing items, identify objects, read text, and monitor human activity using real-time camera feeds. This helps improving efficiency in domains such as retail, healthcare, manufacturing and security, etc.
- Core to Complex AI Models: AI image analysis models span from classic CNNs and ViTs for classification and detection to advanced Vision-Language Models (e.g., CLIP, PaliGemma) capable of analyzing images, generating captions, answering visual questions and complex reasoning.
- Multimodal Intelligence is the Future: Multimodal AI like PaliGemma combines visual inputs and natural language understanding to generate context-aware answers, pushing beyond simple detection into reasoning and dialogue.
- Roboflow Enables Practical AI Workflows: Using Roboflow workflows you can perform OCR, object detection, segmentation, pose estimation, document analysis, image captioning, and more. Get started free.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (May 30, 2025). AI Image Analysis. Roboflow Blog: https://blog.roboflow.com/ai-image-analysis/