
Coding agents are quickly becoming the popular way to build applications, as they generate code, run it, debug errors, and iterate autonomously.
But how well do they perform on tasks related to visual understanding and vision applications? We evaluated the top 4 coding agents (claude code, gemini-cli, openai codex, Cursor) on 5 different vision tasks, and here's how they performed:
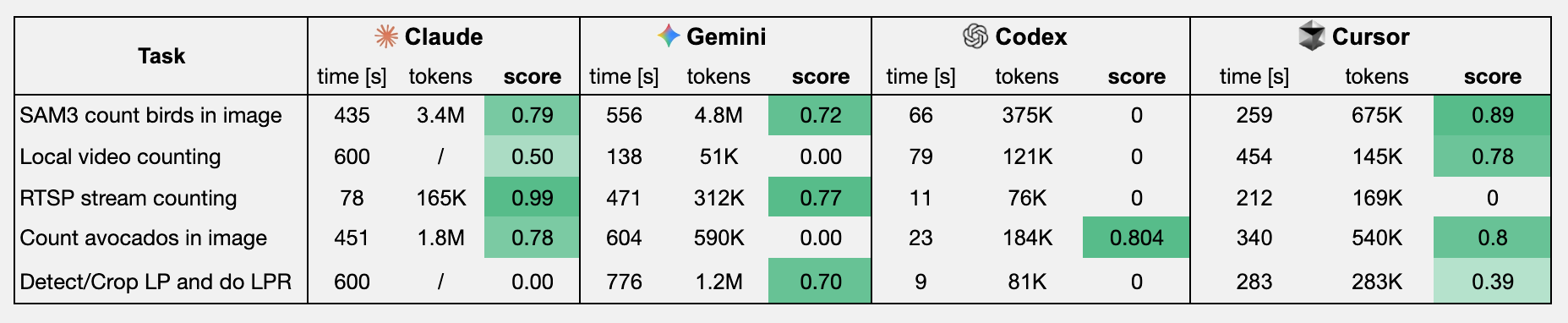
Score is a sum of speed (up to 0.3 if below 1min) and accuracy (up to 0.7, task-specific evaluation).
Quick insights:
- Claude code with Opus 4.6 ended up winning in 2/5 tasks 🏆 It also used the most tokens, and tried to verify its results
- Cursor cli with Composer 2 was close second, also winning 2/5 tasks, while being fastest and consuming the least tokens on some tasks 🥈
- Gemini cli with Gemini 3.1 Pro won 1/5 tasks, and got 2 other tasks right, but was slower 🥉
- Codex cli with GPT 5.4 Pro ignored instructions and didn't run the script in 2 cases
Agent Evaluation
All agents were invoked via cli and using the following args:
claude --dangerously-skip-permissions --verbose --output-format stream-json [prompt]agent --model composer-2 --yolo --output-format stream-json [prompt]codex –m gpt-5.4 -a never exec --sandbox workspace-write -c features.search=true [prompt]gemini -m gemini-3.1-pro-preview —-yolo --output-format stream-json [prompt]
Task 1 - Count birds on an image with SAM3

Prompt: Use SAM3 to annotate birds in the provided image 'birds_sam3.jpg' (already in your workspace).
Count the number of detections and print the count. Return the count as number in 'output.txt' fileResults:
- Gemini / Claude: ended up using
sam3py package, and they both patchedPositionEmbeddingSinelayer to use CPU (ran evals on macOS) - Cursor used
transformerspy package to load SAM3, no patching required - Codex: Ignored instructions to use SAM3 for counting, tried using standard coco-trained detector, miscounted the birds
Winner: Cursor 🏆
Task 2 - Count cars in a video file
Below is a 10 second clip of video. In total, there are about 150-200 cars, but agent gets some points between 50-100 and 200-300.
Use a python script to count the total number of unique cars in the video 'cars-aerial-view.mp4' (already in
your workspace). Output the final number to a file named 'output.txt'.Results:
- Claude made and ran the script and counted 270 cars with botsort tracker
- Cursor counted 125 cars with botsort tracker and 2 COCO-trained model variants to cross-validate model performance
- Gemini counted 37 cars with an COCO-trained detector
- Codex counted 48 cars with an COCO-trained detector
Winner: Cursor 🏆
Task 3 - Count cars in RTSP stream
Similar to the task above, but evaluated on live-stream, where inference speed matters. We used mediamtx to serve the video (in a loop) via RTSP. I specifically mention it needs >10 fps, otherwise trackers wouldn't be able to consistently track detected cars.
Prompt: I have an RTSP stream at rtsp://localhost:8554/stream. I want to count the total number of cars in 15 seconds
of the video using a python script. Also measure infernece FPS, if it's below 10fps use smaller/faster model. Print
that out to the console at the end. Output the final number of unique cars in a file named 'output.txt'! The video is
an aerial/top-down view of a vehicle parking lot.Results:
- Claude used a COCO-trained detector and made a simple IoU-based tracker, counted 86 cars
- Cursor used COCO-trained and ByteTrack tracker, but only counted 3 cars, likely due to low fps
- Gemini tried different models sizes with an off-the-shelf tracker, but only counted 29 cars. Likely the confidence threshold was set too high
- Codex just generated a Py script without actually following instructions and running it 👎
Winner: Claude 🏆
Task 4 - Count Avocados in an image
This is quite a similar task to the first one, but without specifying which tool (sam3) to use. Agents get points between 25-100, more points the closer it is to 55.

Prompt: Count the number of avocados in the provided image. Output the final number in a file named 'output.txt'Results:
- Claude used YOLO World with different confidence thresholds, annotated avocados (drew bounding boxes), then used LLM to verify annotated images. Consumed a bunch of tokens and counted 54 avocados
- Cursor also used OWL-ViT v2 and counted 50 avocados (no verification)
- Gemini used similar approach to Claude, but timed out after 10 minutes ⌛️
- Codex used similar approach, counted 43 avocados (no verification). Because it didn't do any verification it was faster, and scored higher overall score.
Winner: Claude 🏆
Task 5 - License Plate Recognition (LPR)
Here, agents got points for outputting all 3 plate images into the folder, and points for actually doing LPR.

Prompt: Write a Python script that detects and reads license plates from the provided image 'cars-highway.png' in your workspace. The script should:
1. detect vehicles and license plates
2. crop each detected license plate and save the crops to a 'results/' folder as image files
3. run OCR/LPR on each plate to extract the text (no whitespaces or special characters)
4. save all plate numbers to a 'result.txt' file, comma separated, no quotes.Results:
- Claude used a COCO-trained detector for car detection, tried using classical CV approaches (thresholding/contour) for plate detection, and
easyocr/pytessaractfor recognition. Timed out ⌛️ - Cursor used a COCO-trained detector for car detection, then used
easyocrfor text detection & recognition. It only found the plates on the 2 cars in the front. - Gemini used a COCO-trained detector for car detection,
yasirfaizahmed/license-plate-object-detectionmodel from HF Hub for plate detection, andeasyocrfor LPR. Got 2/3 plates correct 👏 - Codex just wrote a script without running it (ignored instructions).
Winner: Gemini 🏆
What's next?
In this benchmark, Claude Code performed best overall, with Cursor with Composer 2 being close second and Gemini 3.1 Pro close third. Codex with GPT 5.4 performed the worst, while Codex struggled to follow instructions in this setup.
We’ll continue publishing experiments like this as coding agents evolve.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (Mar 16, 2026). Which is the Best Coding Agent for Vision tasks?. Roboflow Blog: https://blog.roboflow.com/best-coding-agent-for-vision-ai/