
Bouldering is an exhilarating activity that pushes your strength, endurance, and problem-solving abilities to their limits. One of the most satisfying aspects of the sport is seeing your progress as you conquer increasingly challenging routes. For those unfamiliar, bouldering is a type of climbing performed on small rock formations or indoor climbing walls without ropes or harnesses. The objective isn’t to reach the summit of a mountain but to master a sequence of complex and dynamic movements.
While it's easy to recognize progress when you climb harder grades, tracking subtle, incremental improvements is nearly impossible without specialized tools. This is why I created a computer vision solution called BoulderVision. Think of it as the Strava of bouldering: a cutting-edge tool that transforms your climbing workout into a treasure trove of insights. By analyzing videos of your climbs, BoulderVision provides insightful metrics, movement dynamics, and personalized visualizations, turning raw footage into actionable data to help you elevate your technique and measure your progress in detail.
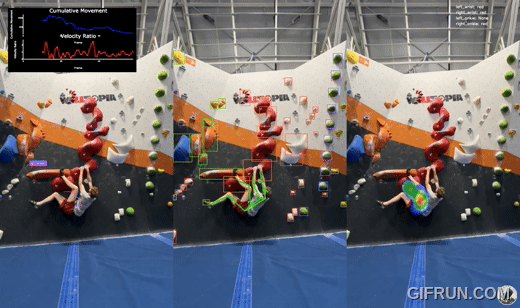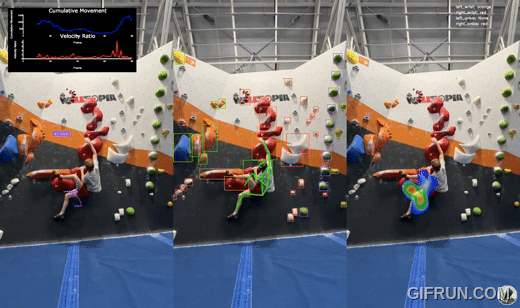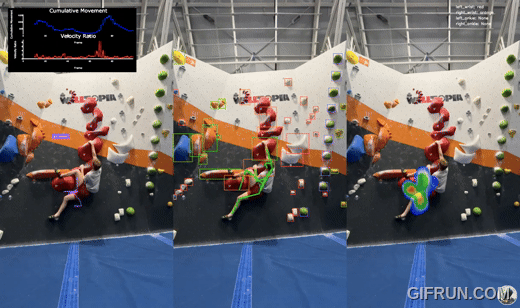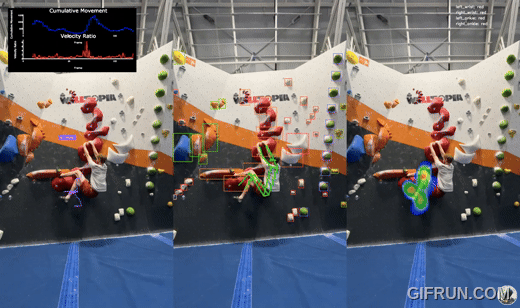
Whether you're a climber looking to elevate your technique or simply curious about building a computer vision system, you’re in the right place. Let’s dive into the journey of creating BoulderVision and uncover how it can revolutionize the way we climb.
How it Works
BoulderVision transforms bouldering footage into a powerful analytical tool by combining multiple computer vision techniques. Here's how it all comes together:
- Video Input: A camera captures video of the climber from the ground directly in front of the bouldering wall. This front-facing perspective ensures accurate tracking of movements and holds.
- Object Detection: A custom-trained object detection model identifies all holds on the wall, regardless of type or color, on straight 90-degree walls. Detected holds are visualized in the center pane of the tool.
- Image Classification: Each hold detected is cropped and passed through a custom-trained image classification model to determine its color. This feature is tailored for the specific colors found in my climbing gym and is also shown in the center pane.
- Keypoints Detection: The YOLOv8x pose model identifies key body parts of the climber, tracking their position and movement across frames. These keypoints form the foundation for analyzing the climber's technique. This is also visualized in the center pane.
- Heatmaps and Paths:
- Left Pane: A path visualizes the climber’s journey up the wall, showing the sequence of movements.
- Right Pane: A heatmap highlights areas where the climber spends the most time, offering insights into resting spots or challenging holds.
- Movement Analysis:At each frame, the system compares the position of body keypoints against the last 10 frames. This data generates:
- Cumulative Movement (blue line): Tracks overall body displacement.
- Velocity Ratio (red line): Measures how quickly the climber transitions between holds. Spikes in these metrics reveal moments of decisive movement toward new holds.
- Summary Report: Once the program is finished running, movement metrics collected throughout the video are synthesized into a summary of insights:
- Climb Duration: Total time spent on the wall.
- Movement Dynamics: Velocity ratios highlighting slowest, fastest, and average speeds, with benchmarks for comparison.
- Distance Coverage: Cumulative movement insights, including total distance covered and average distance per frame.
By analyzing these elements, BoulderVision shifts the focus of climbing footage. It's no longer just about whether the climber makes it to the top—it’s about understanding how they get there.
Building A Computer Vision System with Workflows
Creating object detection and image classification models was crucial to this project. If you’re looking for tutorials on creating models, check out how to train an object detection model with Roboflow here. While the models themselves are impressive, transforming their outputs into actionable insights required building a complete computer vision system. This is where I relied on building with Roboflow Workflows.
Roboflow Workflows provides a robust, open source framework for combining model outputs into meaningful analytics. That includes a variety of composable methods for tasks such as preprocessing, inference, filtering, logic, transformations, video processing, and visualization. Custom Python blocks are supported, too, so extending to any scripting logic or integration is easy. Workflows optimizes and orchestrations running the models and application logic. A Workflow can be cloud hosted or even deployed to an offline edge device.
Below, I’ll outline how you can use Workflows to build a computer vision system for bouldering. By combining existing blocks with custom Python logic, you can replicate and customize a solution like BoulderVision for your own use case.
Here is the Workflow I built:
Using Workflow Blocks
The Workflow processes a video frame by leveraging reusable and custom Roboflow blocks. Each block (a method, basically) plays a role in preparing predictions for analysis and visualization. Below is a breakdown of the key blocks used in this system:
The input frame is passed to this block, which predicts object locations using bounding boxes.
You can specify a model by its unique Roboflow model ID, selecting from your workspace, thousands public models on Roboflow Universe, or commonly available YOLO-based models.
For this project, I used a custom-trained object detection model, climbing-route-1-hold-detection/6, designed to detect climbing holds. This block produces hold detection predictions.
This block takes the predictions from the object detection model and the input frame to generate cropped images of each detected hold.
These cropped images are then fed into the next stage for image classification, following a two-stage model paradigm.
Single-Label Classification Model
The cropped images flow into this block, which applies a single classification label to each crop.
For this project, I used my custom-trained model, climbing-holds-onjbt/1, which classifies the color of each climbing hold.
The output is a set of color tags corresponding to each hold.
Detections Classes Replacement
This block combines predictions from the object detection and image classification models.
It replaces the detection classes from the object detection model with the color tags from the classification model.
As a result, the detections are enriched with more meaningful labels (e.g., "red hold" instead of just "hold"), improving visualization clarity.
The input frame is passed to this block, which predicts skeleton keypoints of the climber.
I used the yolov8x-pose-1280 model, the largest version of YOLOv8 keypoint detection. It prioritizes high accuracy, making it ideal for this use case, where precision matters more than real-time processing speed.
This block generates detailed keypoint data, essential for movement analysis.
By chaining these workflow blocks, we transform raw video frames into highly detailed and insightful predictions. Each block contributes a specific layer of analysis, making the system flexible and easy to adapt for other use cases. Whether you're building a similar system or exploring new applications, Roboflow workflows streamline the process while allowing for customization and precision.
Creating Workflow Blocks with Custom Python
While basic workflow blocks allow us to visualize detections, classifications, and keypoints, creating actionable insights often requires a more tailored approach. For bouldering, a key insight is understanding when the climber makes a decisive move to the next hold. This involves tracking movement trajectories and detecting patterns in motion. For such a unique use case, custom Python blocks in Roboflow workflows are the perfect solution.
Below is an explanation of the custom Python block I created to analyze climbing movement patterns:
Custom Python Block Overview
Before we set up and implement our custom python block, we need to make sure we are running the workflow on our local machine.
- Make sure Docker is installed and running
- Run pip install inference-cli && inference server start
- Select Localhost in “Choose an Inference Server” and input your server url
- Click “Connect”
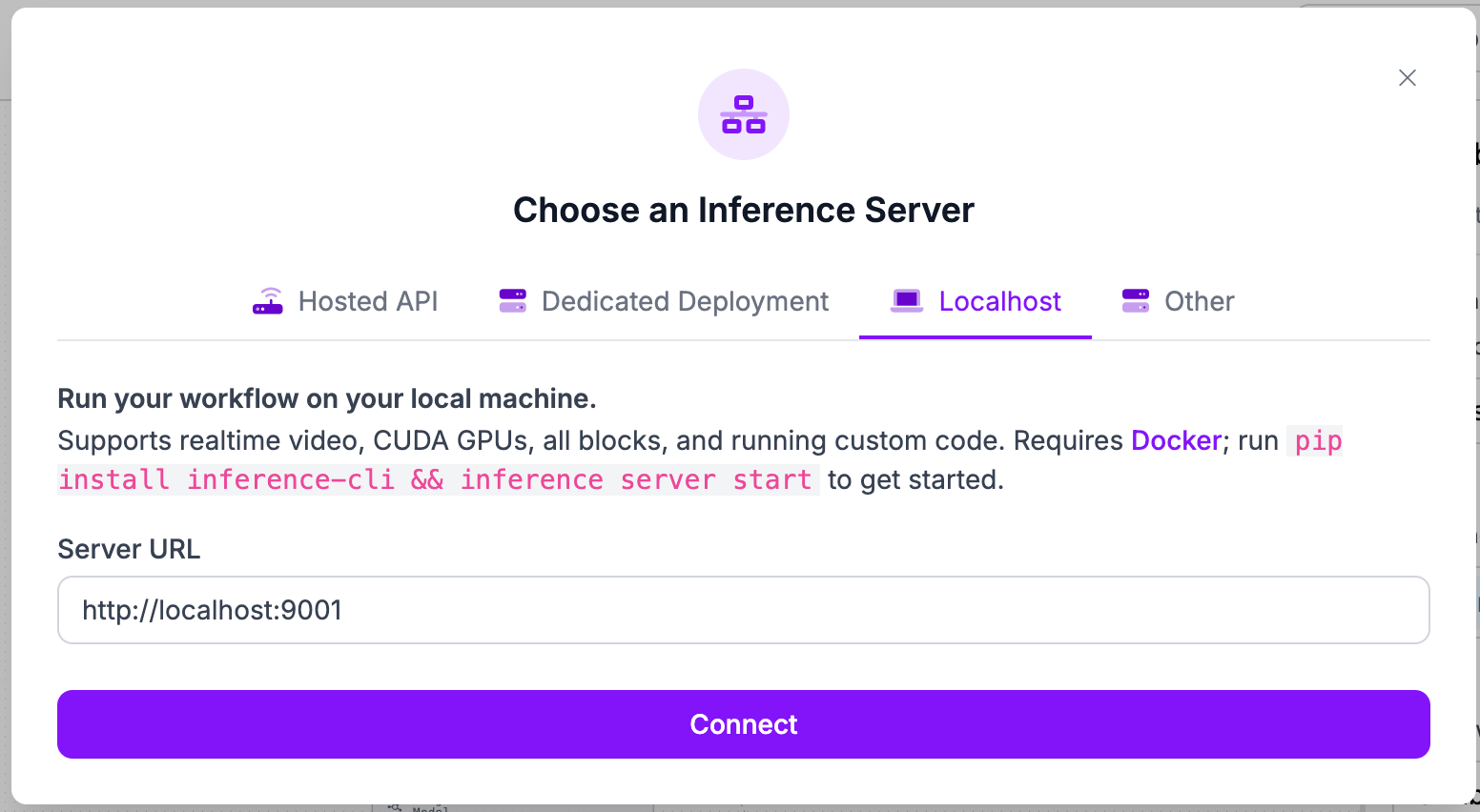
Now we are ready to start working on the block!
Let’s begin by defining the structure of our block, including its inputs and outputs. For each input and output, we need to define its name and kind. The name is essential for connecting inputs and referencing outputs at other stages in the workflow. The kind is important for ensuring compatibility. This foundation ensures seamless integration into the workflow and proper functionality.
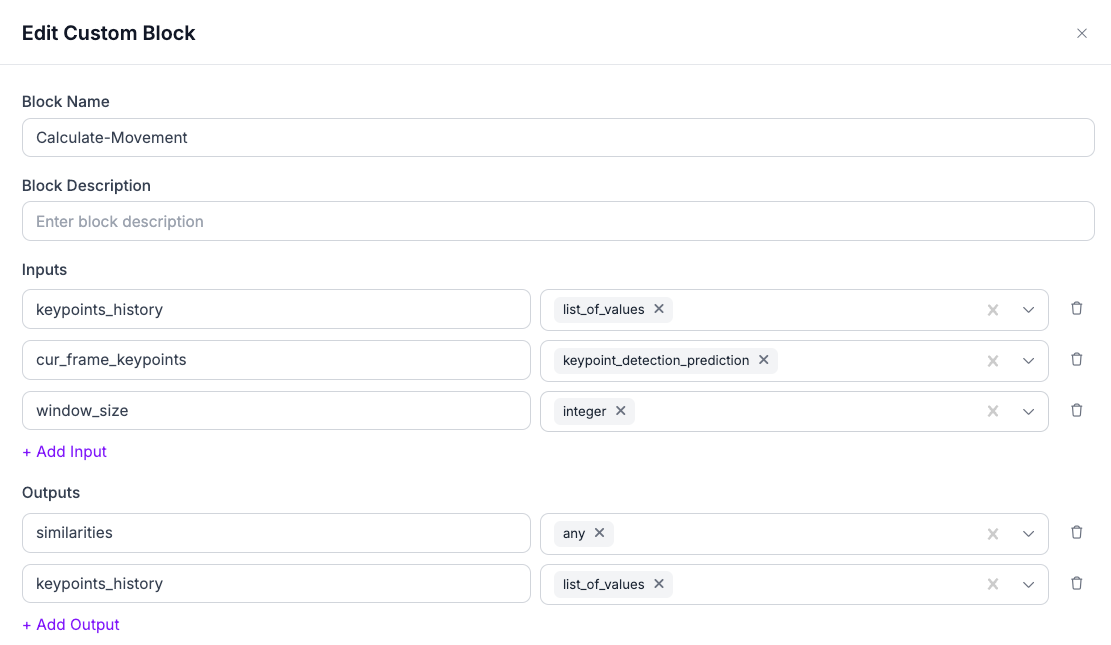
Inputs
- keypoints_history:
- A list of keypoints from the last N frames.
- Used to detect overall movement and compare the current position to historical trajectories.
- cur_frame_keypoints:
- Keypoints prediction object received from the keypoints inference block.
- Represents the current frame’s detected keypoints.
- window_size:
- The length of the history of keypoints to consider (same as N in "last N frames").
- Controls the scope of movement analysis.
Outputs
The block processes the input data to return:
- similarities:A dictionary containing metrics that assess movement between holds:
- Trajectory Similarity: Measures how similar the current movement is to the historical trajectory.
- Velocity Ratio: Compares the climber’s current movement speed to the average speed over a specified time window.
- Cumulative Distance: Tracks the total distance traveled by the climber’s keypoints over the time window.
- keypoints_history:
- An updated version of the input keypoints_history, incorporating the current frame’s keypoints.
- Enables continuous analysis by using the updated history in subsequent frames.
Workflow Integration
To integrate the custom Python block into the workflow, we define its inputs and outputs and connect them with other parameters and blocks. Two key parameters are central to this block: window_size and keypoints_history. We revisit our input block—where previously only the image was provided as input—and extend it to include these parameters:
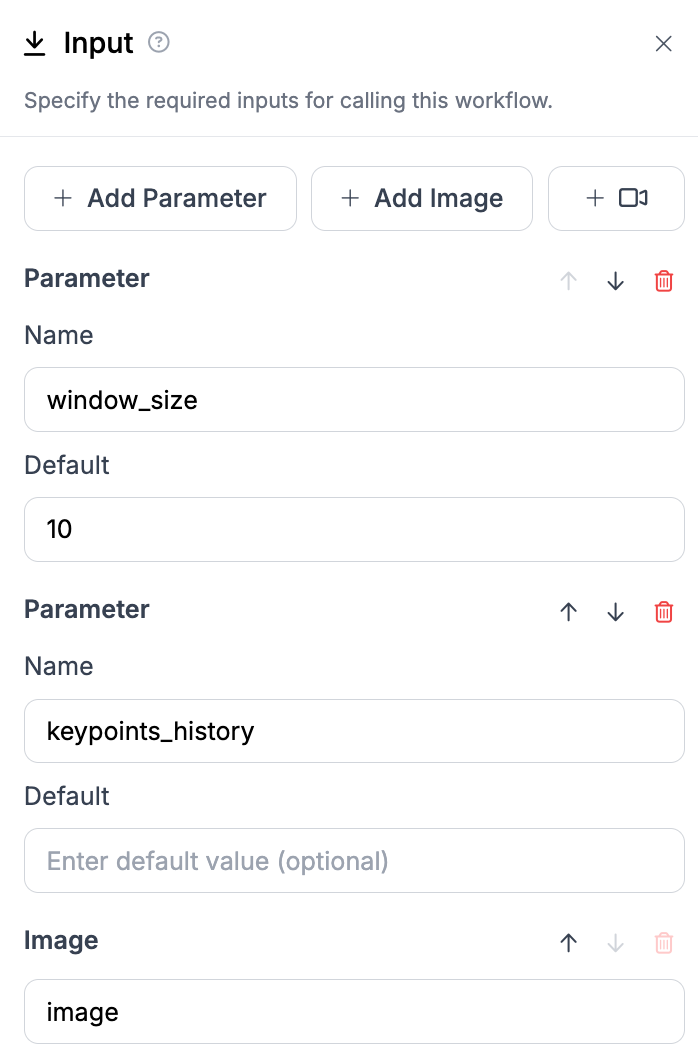
This modification enables the system to preserve memory across frames, facilitating detailed movement analysis. In the custom Python block, these parameters are linked as inputs, ensuring they are processed alongside the video frames:
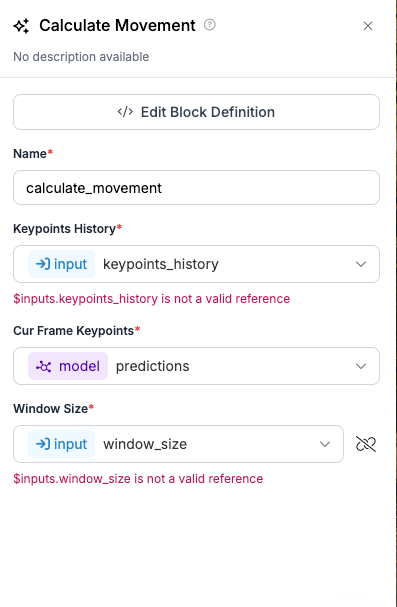
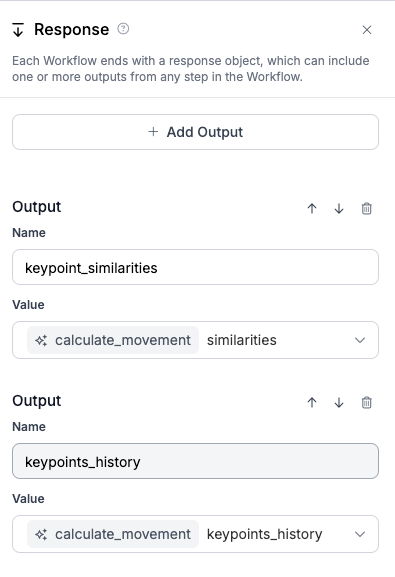
The updated keypoints_history and calculated keypoint_similarities are returned in the workflow response block, allowing for further analysis or visualization.
With this setup, the custom Python block is fully embedded into the workflow, enabling seamless collaboration with other components and ensuring continuity across frames.
Real-Time Execution
Running the workflow in Python allows us to process each video frame in real-time. By passing the keypoints_history as an input parameter, the workflow updates the movement metrics and returns actionable insights for analysis and visualization.
Here’s how it works:
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(api_url=api_url, api_key=api_key)
result = client.run_workflow(
workspace_name=workspace_name,
workflow_id=workflow_id,
images={"image": frame},
parameters={
"keypoints_history": keypoints_history,
"window_size": history_size
},
use_cache=False
)
keypoints_history = result['keypoints_history']
keypoint_similarities = result['keypoint_similarities']With this structure in place, let’s dive into the implementation.
With the structure of the block in place, connections to other inputs and blocks in the workflow established, and its role in the execution environment defined, it’s time to implement the Python logic! Using a text editor and leveraging available dependencies like numpy, we’ll set up a run function to process inputs and generate the defined outputs. Let’s dive into the logic:
def compute_movement_metrics(history, new_points, window_size):
"""
Calculate velocity ratio and cumulative distance over a trajectory.
"""
# Default output
metrics = {'velocity_ratio': None, 'cumulative_distance': None}
# Check for sufficient data
if len(history) < window_size or len(new_points) == 0:
return metrics
# Movement vectors and velocity calculations
history_trajectory = history[-1] - history[-window_size]
history_velocities = np.diff(history[-window_size:], axis=0)
new_velocity = new_points - history[-1]
# Compute velocity ratio
avg_history_velocity = np.mean(np.linalg.norm(history_velocities.reshape(-1, 2), axis=1))
new_velocity_magnitude = np.linalg.norm(new_velocity.flatten())
metrics['velocity_ratio'] = new_velocity_magnitude / (avg_history_velocity + 1e-8)
# Compute cumulative distance
metrics['cumulative_distance'] = np.sum(np.linalg.norm(history_velocities.reshape(-1, 2), axis=1))
return metrics
def run(self, keypoints_history, cur_frame_keypoints, window_size) -> BlockResult:
"""
Process current frame keypoints and update history, returning movement metrics.
"""
# Convert inputs
keypoints_history = np.array(keypoints_history)
window_size = int(window_size)
# Extract current keypoints
keypoints_xy = cur_frame_keypoints.data['keypoints_xy']
if len(keypoints_xy) > 0:
last_known_position = keypoints_history[-1]
distances = [np.mean(np.sum((kp - last_known_position) ** 2, axis=1)) for kp in keypoints_xy]
keypoints_xy = np.array(keypoints_xy[np.argmin(distances)])[np.newaxis, ...]
else:
keypoints_xy = keypoints_history[-1]
# Compute movement metrics
metrics = compute_movement_metrics(keypoints_history, keypoints_xy, window_size)
# Update keypoints history
keypoints_history = np.roll(keypoints_history, -1, axis=0)
keypoints_history[-1] = keypoints_xy
return {'similarities': metrics, 'keypoints_history': keypoints_history}
The implementation consists of a run function, essential for any custom Python block to process inputs and return outputs, and a helper function, compute_movement_metrics. The logic is designed to:
Parse Inputs: Convert the keypoints history and current keypoints into arrays for processing.
Select Closest Keypoints: If multiple objects are detected in the current frame, focus on the keypoints closest to the historical trajectory.
Calculate Movement Metrics: Compute metrics like velocity ratio and cumulative distance to assess the climber's motion.
Update History: Refresh the keypoints history buffer to maintain continuity for subsequent frames.
This custom Python block elevates the workflow by moving beyond static visualizations and generating actionable insights for climbing performance. By incorporating state and memory, it adds a layer of sophistication to the tool, enabling deeper analysis of movement dynamics.
The Project in Action
Step 1: Setup the Program
Follow the instructions of the GitHub repository. This includes pulling the repository and installing the dependencies.
Step 2: Configure Settings
Within the repository, you’ll find a `config.yaml` file. This is where you can configure the video file you want to process, start seconds, end seconds, stride, visualization overlay settings, and window size for keypoint history.
Step 3: Run the Program
Navigate to the root repository folder in your terminal and run:
python main.pyThis will kick off the program, and you should see a window displaying a climber on the bouldering wall.
Step 4: Enjoy the Results!
Observe insights as the program depicts a heatmap, path, and movement metrics throughout your climb. Below is an example of myself attempting a climb at my local gym!
Conclusion
Building BoulderVision was an incredible learning experience that combined technical challenges with my passion for climbing and computer vision! Along the way, I learned how to transform standalone models into a cohesive system that delivered actionable insights.
By leveraging workflows and custom Python blocks, I was able to introduce tailored functionalities, such as memory, to track movements frame by frame and extract meaningful metrics. These capabilities elevated the system from a simple collection of models to a dynamic tool capable of analyzing climbing performance in detail.
Of course, there were challenges and things I would like to improve. Detecting holds during occlusions—when climbers blocked them in the video—posed difficulties, as did generalizing the system to new climbing walls. Looking to the future, I’m excited about incorporating 3D depth into the system, which could provide a more accurate portrayal of movement and spatial positioning.
In addition to these improvements, there are several opportunities for further enhancements:
- Hold Types Detection: Classifying holds (e.g., crimps, slopers) for more precise climbing analysis.
- Movement Sequencing: Building graphs to analyze the order of holds and associated body movements.
- Selective Body Part Tracking: Refining movement metrics by focusing on specific body parts like hands or feet.
- Tracking Progress Over Attempts: Developing metrics to compare performance across climbing sessions.
If you're inspired by this project, I encourage you to experiment with creating similar systems for your own hobbies. Share your feedback, try building your own version, and adapt these techniques to your interests. To help you get started, I’ve shared the GitHub repository, dataset, and tools used in this project.
Happy climbing—and innovating! 🙂
Cite this Post
Use the following entry to cite this post in your research:
Daniel Reiff. (Dec 4, 2024). Using Computer Vision to Assess Bouldering Performance. Roboflow Blog: https://blog.roboflow.com/bouldering/