
Readers can face trouble when encountering new, unfamiliar words. With advancements in computer vision, we can develop innovative solutions that can aid readers in overcoming these hurdles.
In this article, we cover how to use object detection and optical character recognition (OCR) models to create an interactive reading assistant that detects specific words in an image and reads them aloud using GPT-4. Readers will be able to hear the word which helps with knowing what the word may be as well as with pronunciation.
Step 1. Build a Model
First, sign up for Roboflow and create an account.
Next, go to workspaces and create a project. Customize the project name and annotation group to your choice. Make sure to create an object detection project.
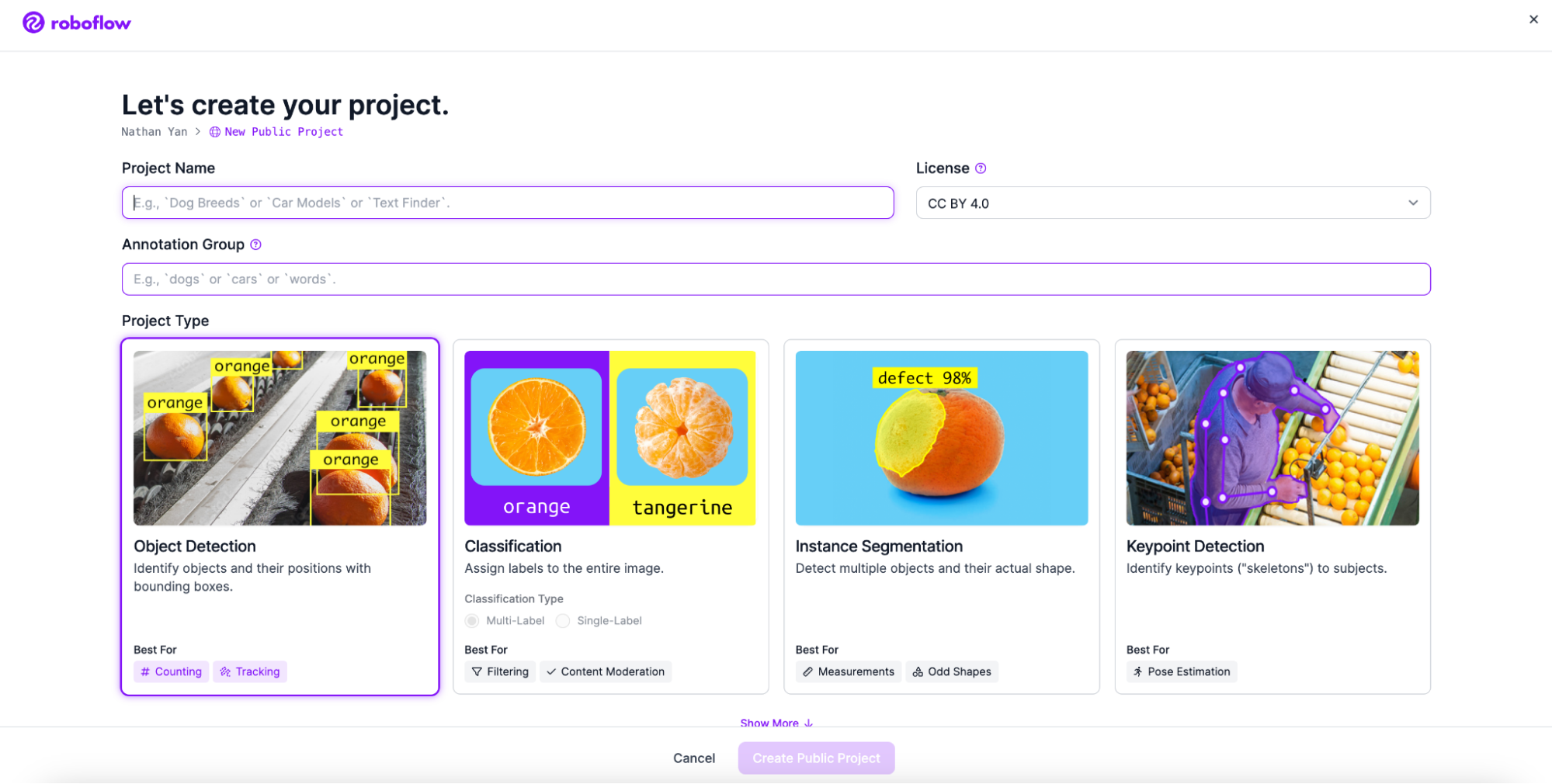
Next, add your images. The images I used are downloadable through this link. Make sure to download the dataset and have the files saved somewhere.
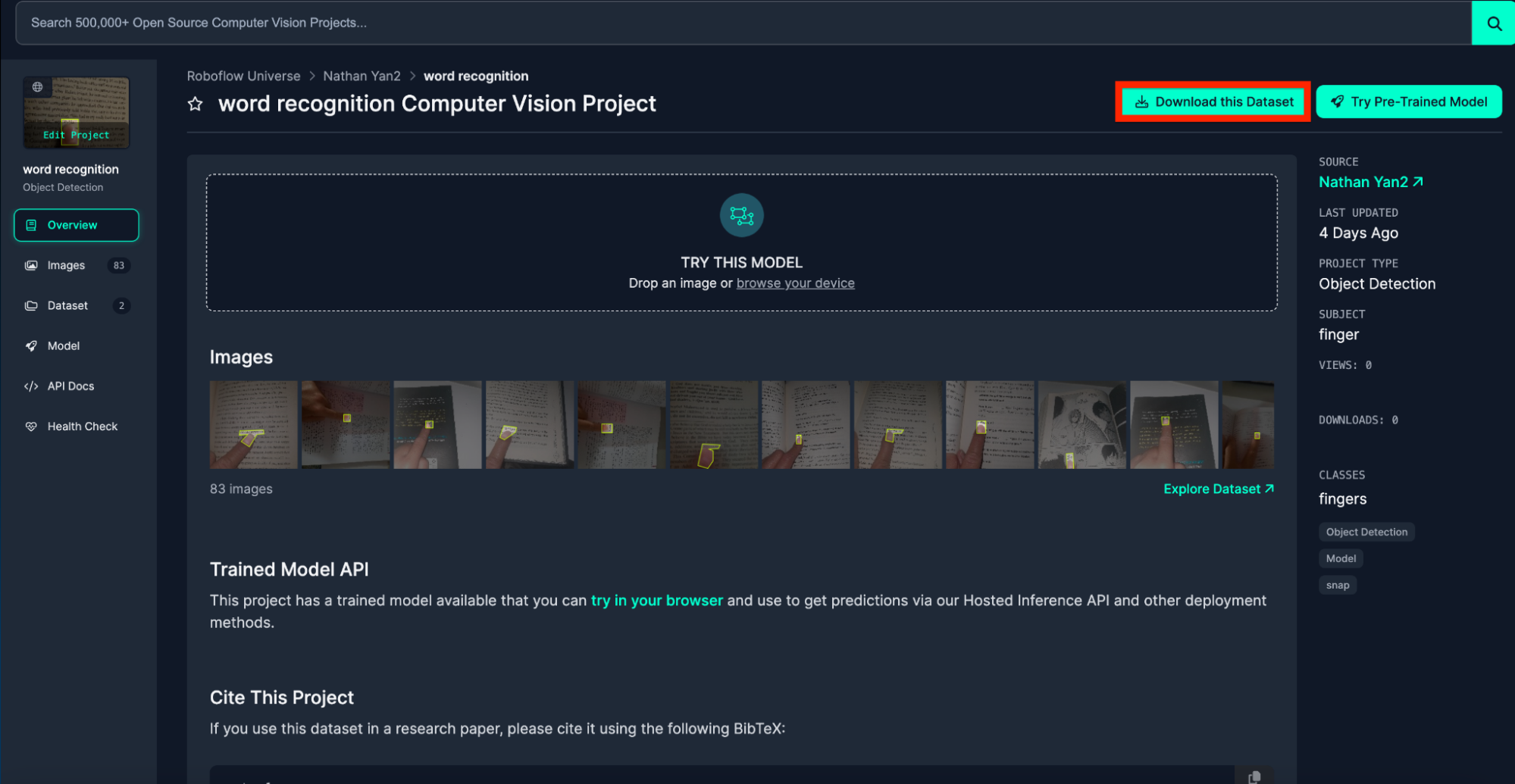
Add the downloaded images to the dataset and continue.
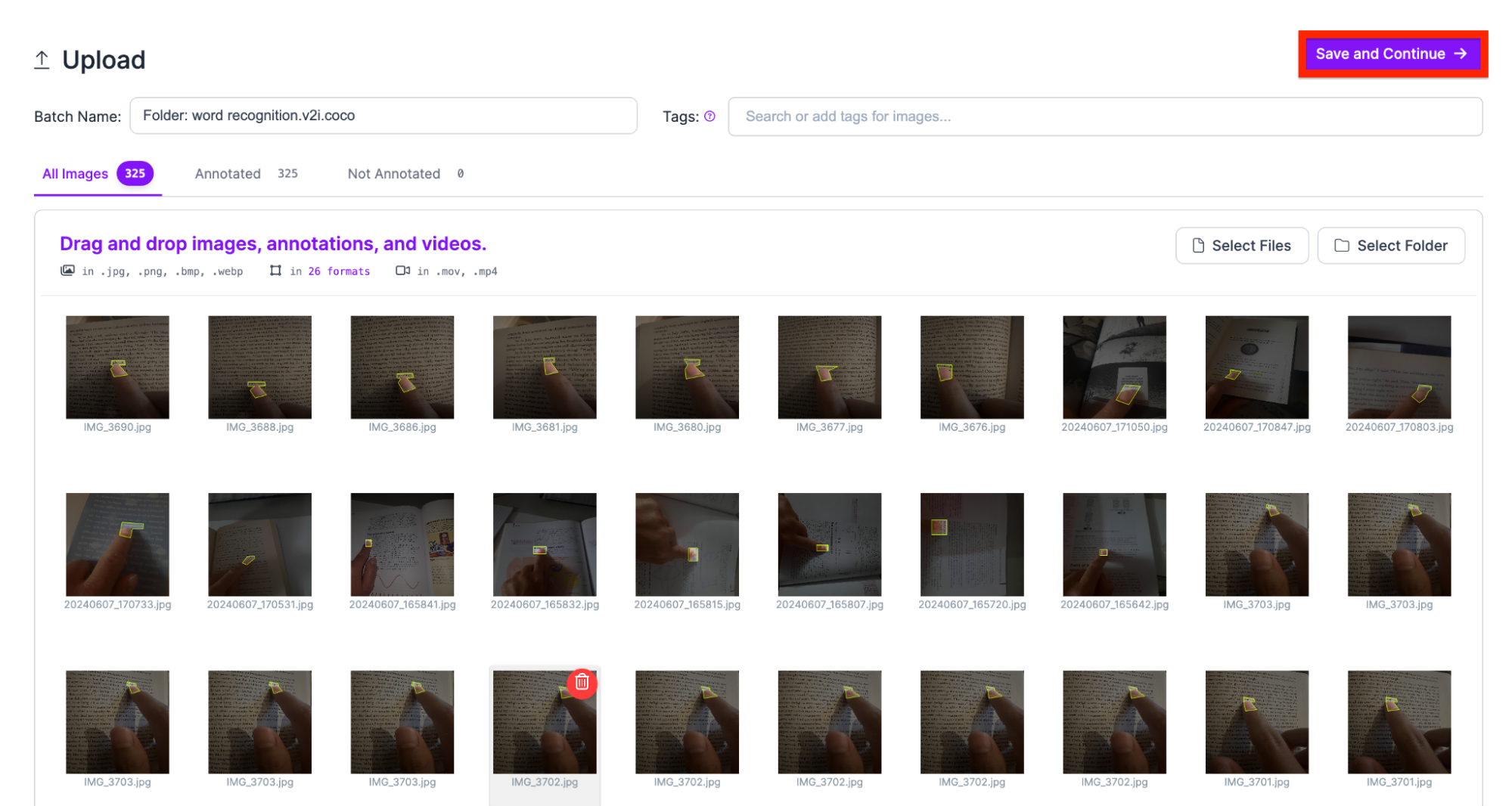
Then, add the classes you want your model to detect. For our use case, we only need one class.
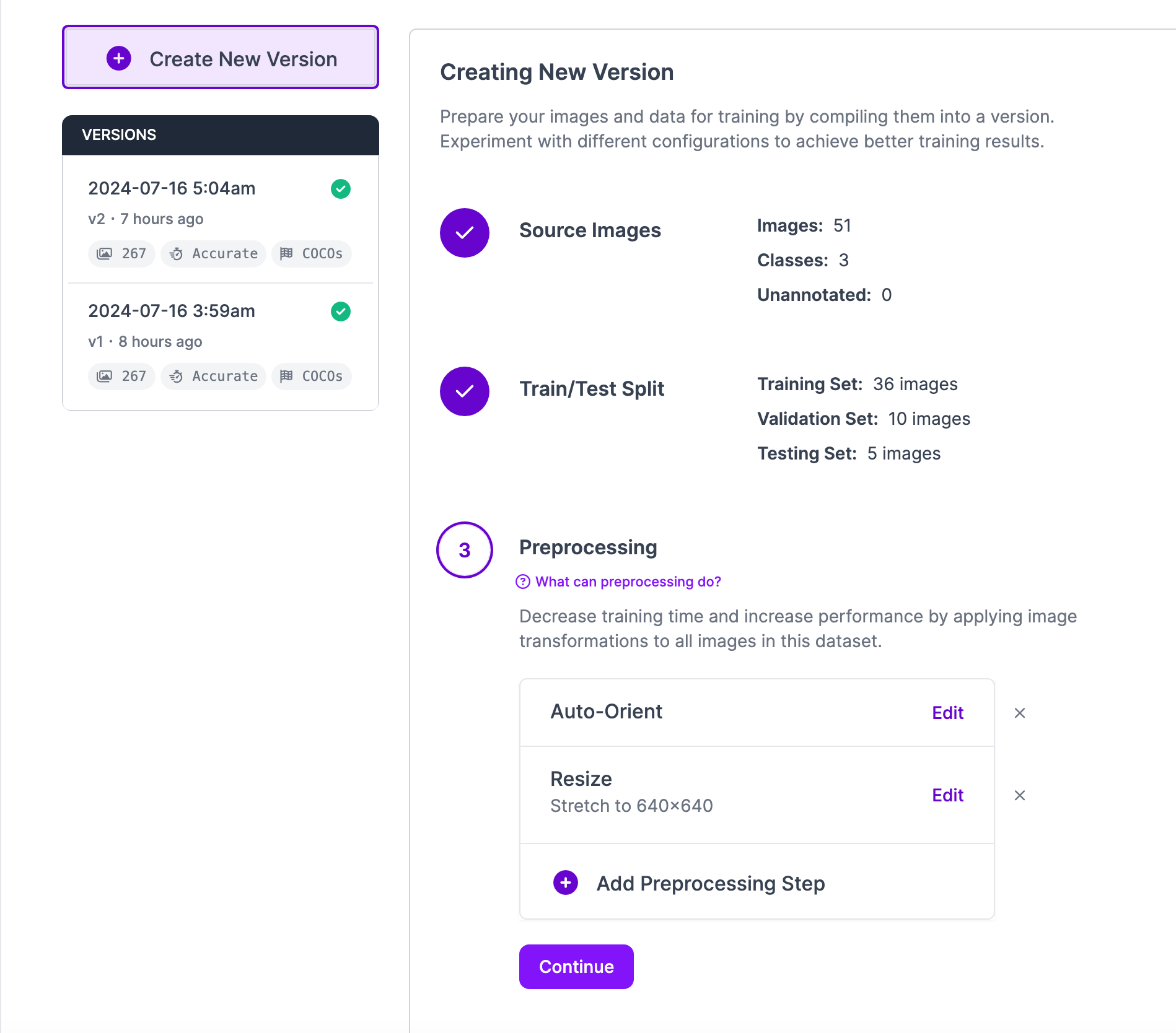
Now that we have our annotations and images, we can generate a dataset version of your labeled images. Each version is unique and associated with a trained model so you can iterate on augmentation and data experiments.
Step 2. Create a Workflow
Workflows is a web-based, interactive computer vision application builder. You can use Workflows to define multi-stage computer vision applications that can be run in the cloud or on your own hardware.
Using Workflows, we are able to:
- Detect the finger on the screen
- Predict the word using object character recognition
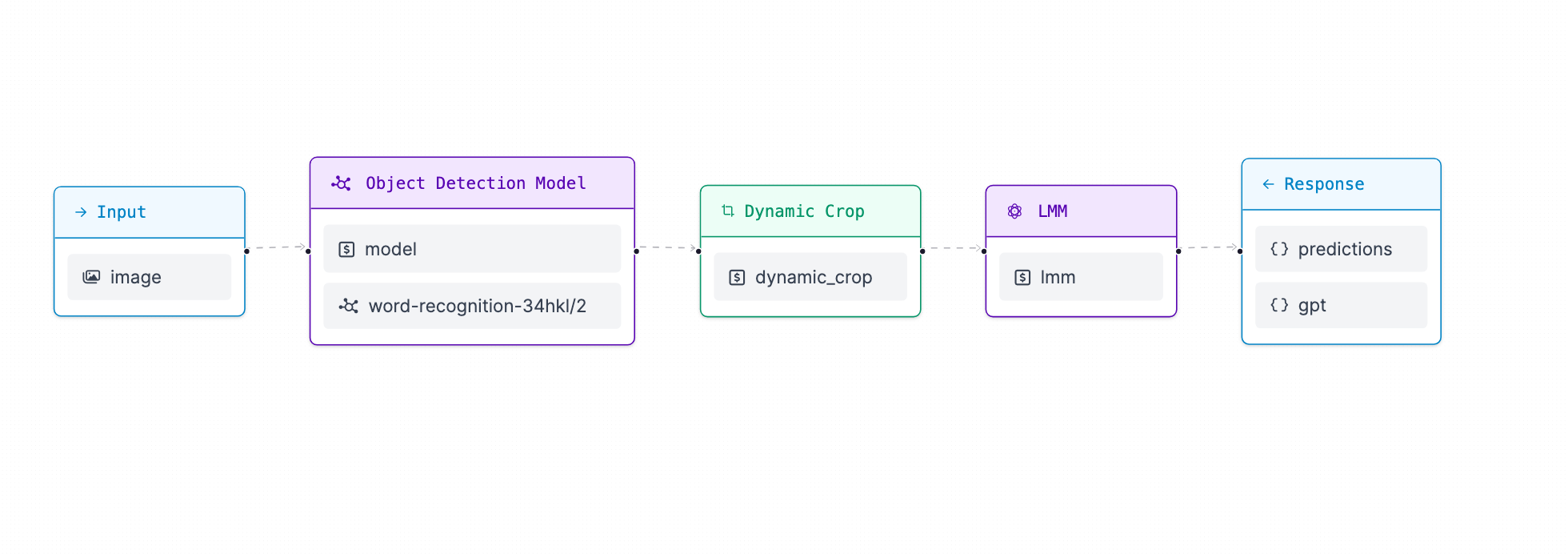
Workflows can also call external vision-capable APIs such as GPT-4o, a feature we will leverage in our application.
To get started, go to Workflows in the Roboflow application:
Then, click on “Create Workflow”.
Next, click “Custom Workflow” and click “Create”:
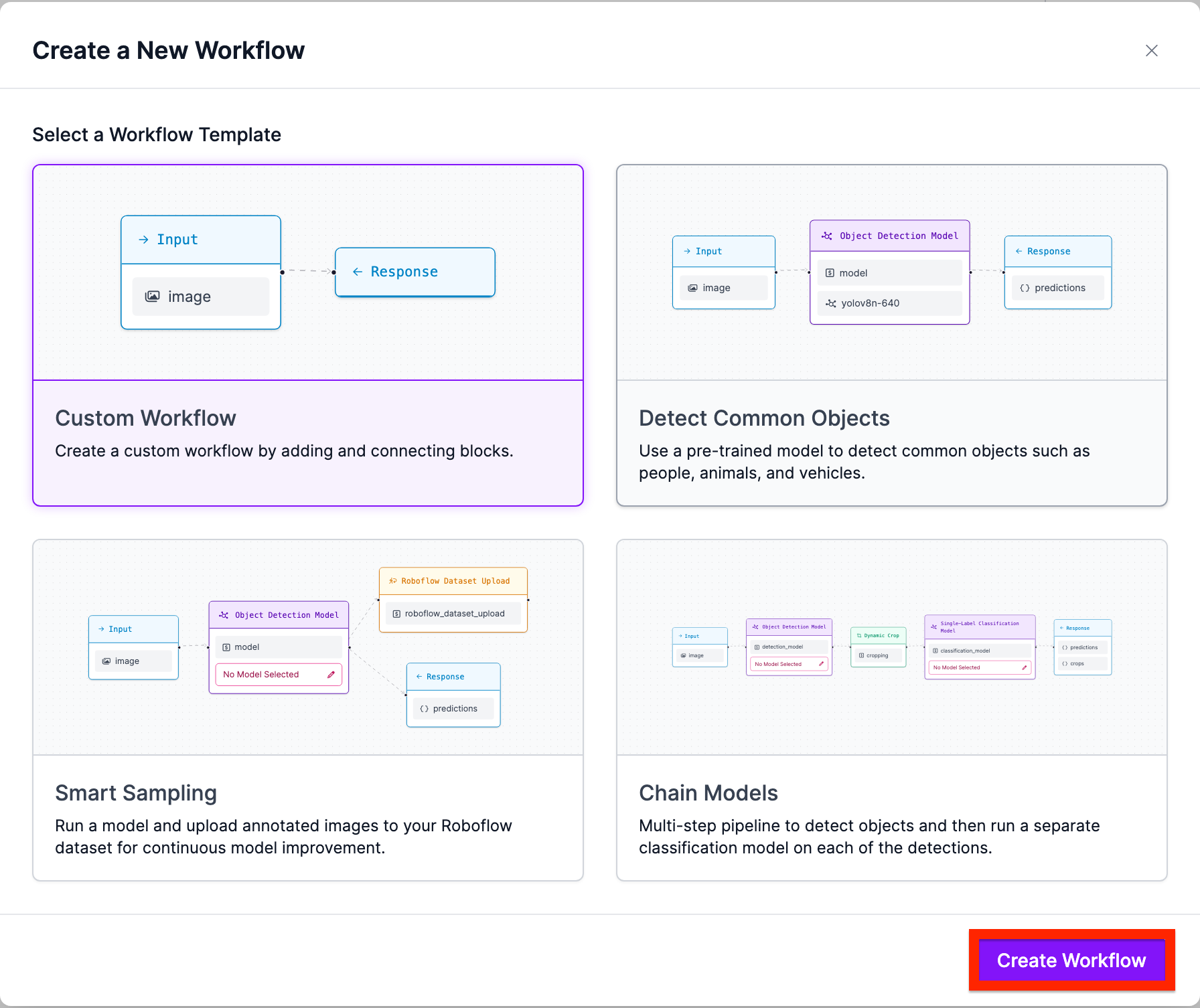
Next, navigate to add block and search for “Object Detection”:
Add the Object detection block.
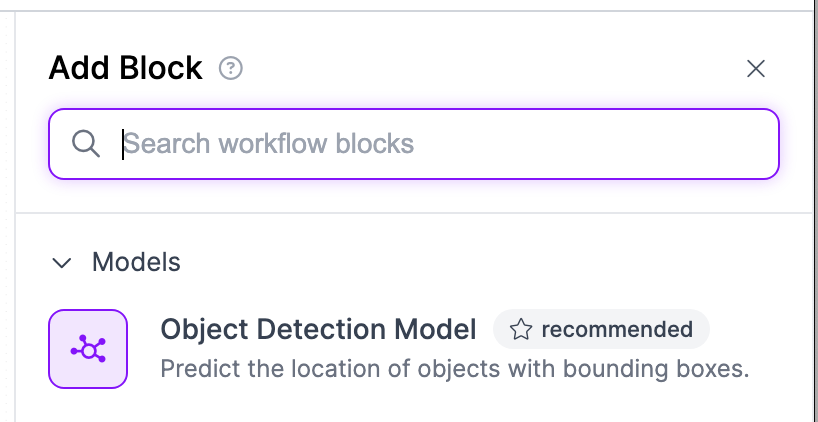
Now we have to pick which specific object detection model we want to use. To do this, click on the Model button.
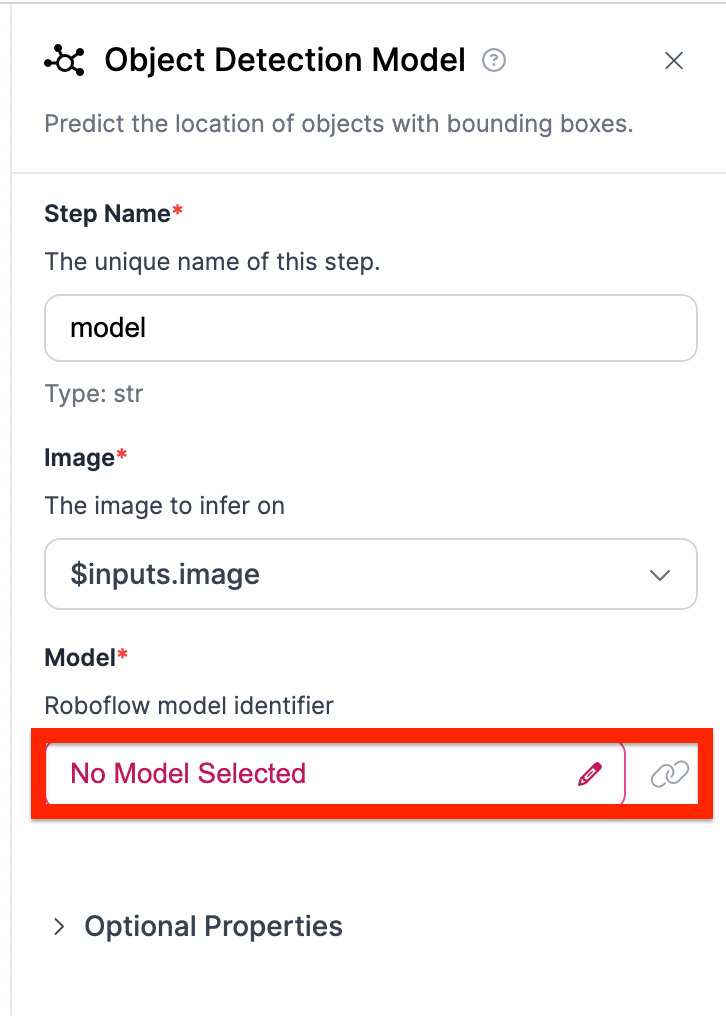
Select the specific object detection model as the one you need.
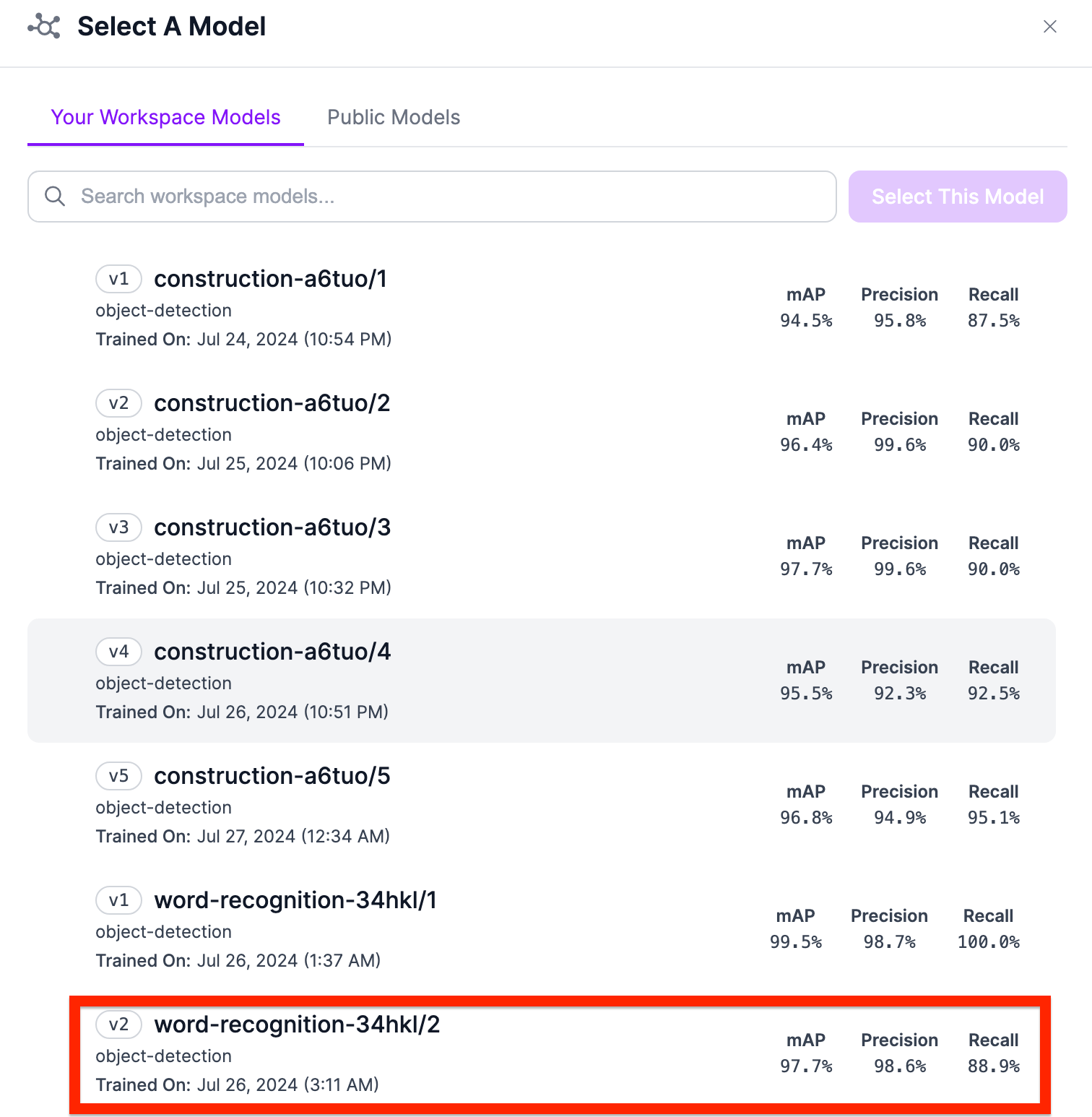
Nice! We have completed our first block. Next, let's add a dynamic crop block to crop the image.
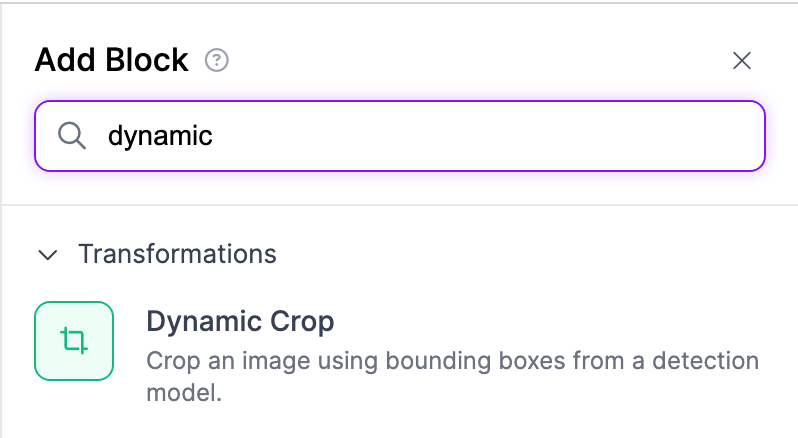
Finally, using the crop, we need to use object character recognition to get the letters displayed on the screen.
Add the LMM Block.
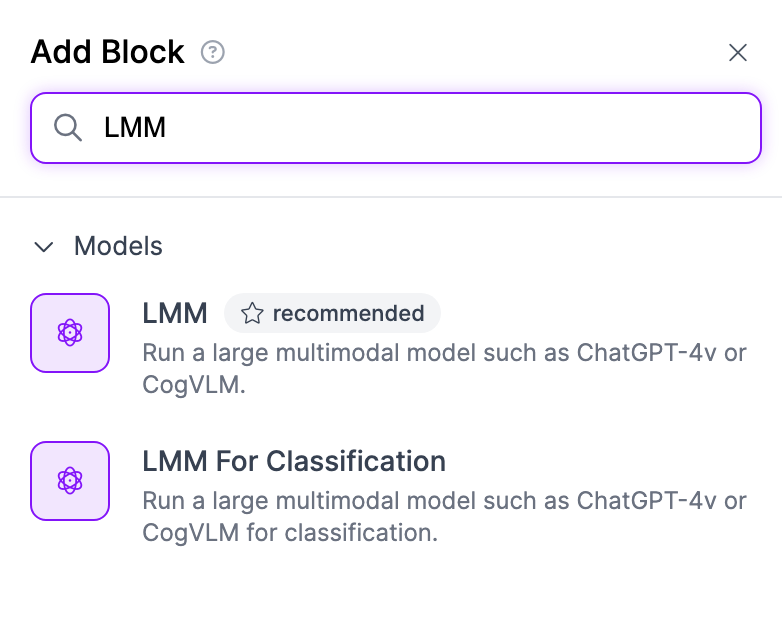
When using a large vision model, you can input a prompt. This is the prompt that will be sent to GPT-4v with our image. A prompt we have found to work well is:
“Give me the text in the image. Nothing else. It should output only one word. The word should be the one I am pointing at. No other words or periods. There should be one main word that is found in the image (right above the finger). ” This prompt works since we are creating an OCR model.
Then open the optional properties tab and add your OpenAI API-Key:
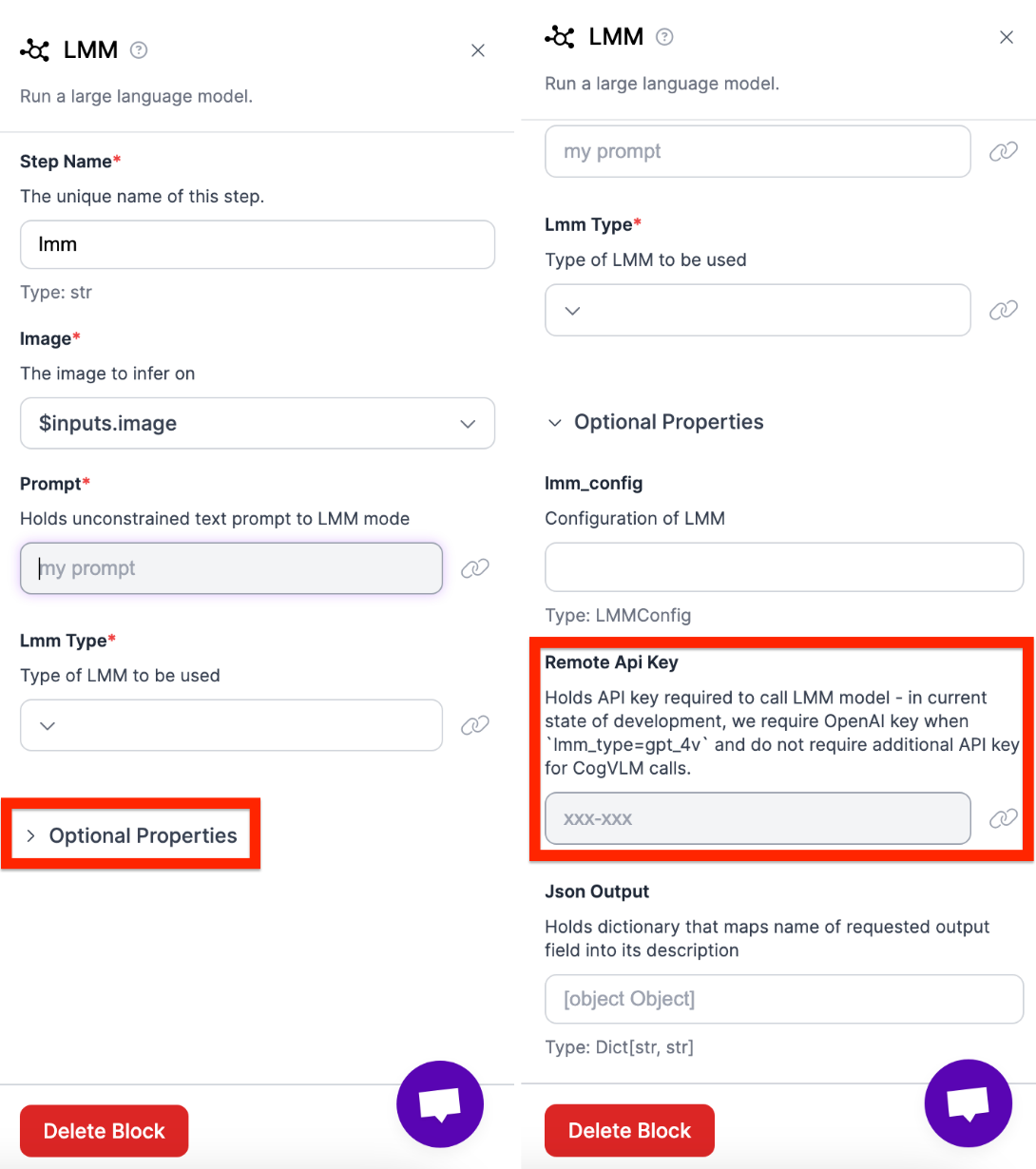
Next, we need to connect every block in order. To do this, change the image inputs and outputs of each model.
Lastly, connect the output with the object detection model. Also make sure to change the name of both models to “predictions” and “gpt”.
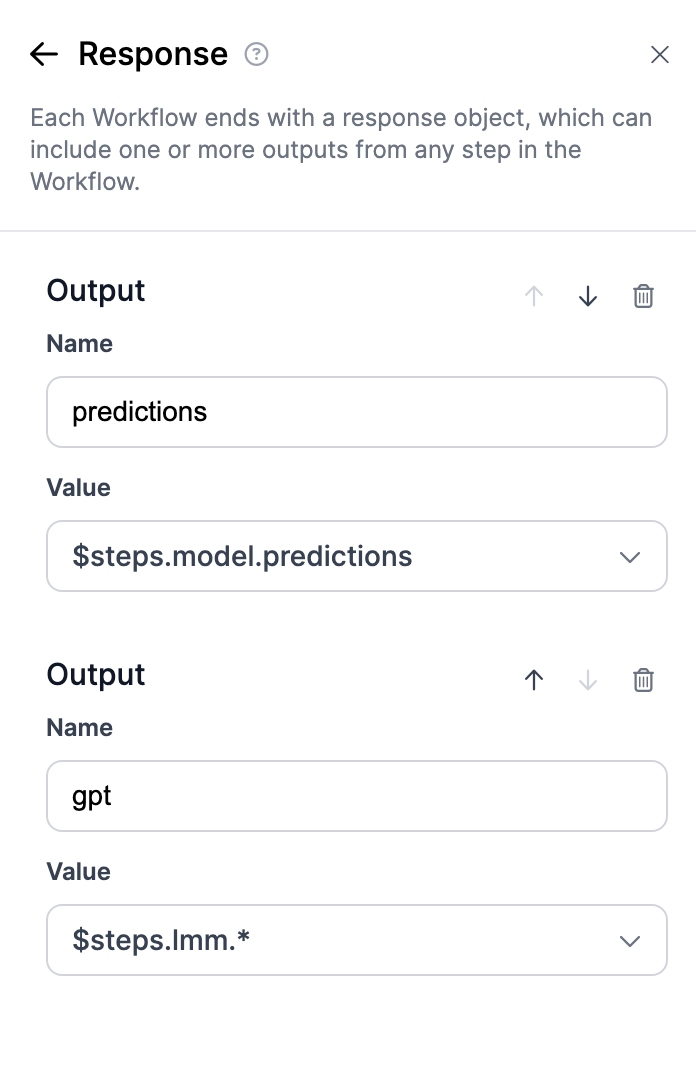
Finally, save the model and the deployment code.
Step 3. Download and Install libraries
Before we start programming, we need to install some libraries beforehand.
First, install the needed libraries.
pip install opencv-python openai pydub inference supervisionNext import the necessary libraries.
Step 4. Create Audio functions
In this step, we will create an audio function that will play any word depending on the inputted word.
First, paste in your OpenAI API key. We are using Openai here to access text to speech capabilities.
client = OpenAI(api_key="OPENAI_API_KEY")Next, add the following function to run the audio.
def run_audio(message):
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input=f"{message}"
)
response.stream_to_file(speech_file_path)
speech_file_path = speech_file_path
audio = AudioSegment.from_file(speech_file_path)
play(audio)This function first defines a path for the speech file, then adds the audio into the file, and lastly plays the file through pydub.
Step 5. Create an Object Detection Function
Now that we finished our audio function, we need to detect when there is a finger in sight. To accomplish this, we need an object detection function that runs on every frame.
First define our annotators. These will help us draw in the detections.
COLOR_ANNOTATOR = sv.ColorAnnotator()
LABEL_ANNOTATOR = sv.LabelAnnotator()Next, add the object detection function. Here is the overall cope snippet.
def on_prediction(res: dict, frame:VideoFrame) -> None:
image = frame.image
annotated_frame = image.copy()
detections = res["predictions"]
if detections is not None:
detections = sv.Detections.from_inference(detections)
annotated_frame = COLOR_ANNOTATOR.annotate(
scene = annotated_frame,
detections = detections
)
annotated_frame = LABEL_ANNOTATOR.annotate(
scene = annotated_frame,
detections = detections,
)
gpt = res["gpt"]
if gpt:
word = gpt[0]["raw_output"]
print(word)
# Print the extracted word
run_audio(word)
cv2.imshow("frame", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
ReturnThe function first gets the frames of the video (located at frame) as well as the corresponding detections (located at res), obtained from the workflow we previously created.
image = frame.image
annotated_frame = image.copy()
detections = res["predictions"]
Using the predictions from our model on workflows, we are able to see if there is a finger in the frame. If there is, we add the logic to draw out the bounding box as well as play the audio by calling the function.
detections = sv.Detections.from_inference(detections)
annotated_frame = COLOR_ANNOTATOR.annotate(
scene = annotated_frame,
detections = detections
)
annotated_frame = LABEL_ANNOTATOR.annotate(
scene = annotated_frame,
detections = detections,
)
gpt = res["gpt"]
if gpt:
word = gpt[0]["raw_output"]
print(word)
# Print the extracted word
run_audio(word)Lastly, we show the frame and quit the code when the waitkey is pressed.
cv2.imshow("frame", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
ReturnStep 6. Add the Workflow Code
We can now use previously gotten workflow code.
Using the code below, replace your workspace name, id, and api_key with the information on your personal workflow.
pipeline = InferencePipeline.init_with_workflow(
video_reference=0, #Uses personal web camera
workspace_name="WORKSPACE_NAME",
workflow_id="ID",
max_fps = 60,
api_key="KEY",
on_prediction=on_prediction,
)To run the live model add these last two lines.
pipeline.start()
pipeline.join()Conclusion
In this article, we learned how to effectively apply multiple computer vision techniques to create an automated reading assistant. We also learned how to use Workflows to implement multiple techniques with little to no code.
Cite this Post
Use the following entry to cite this post in your research:
Nathan Y.. (Aug 14, 2024). How to Build a Reading Assistant with AI. Roboflow Blog: https://blog.roboflow.com/build-ai-book-reading-assistant/