
GPT-4o is OpenAI's unified multimodal model that handles text, vision, and audio in a single architecture rather than routing between separate specialized models, making it twice as fast and 50% cheaper than GPT-4 Turbo with a 128K context window. This post evaluates GPT-4o across computer vision tasks including OCR, document understanding, visual question answering, and object detection, and outlines where it fits in a production pipeline alongside fine-tuned or open-source models. It is most useful for rapid prototyping and for tasks where a custom-trained model is not yet available, with cost and lack of fine-tuning support remaining the main constraints for specialized applications.
GPT-4o is OpenAI’s third major iteration of their popular large multimodal model, GPT-4, which expands on the capabilities of GPT-4 with Vision. The newly released model is able to talk, see, and interact with the user in an integrated and seamless way, more so than previous versions when using the ChatGPT interface.
In the GPT-4o announcement, OpenAI focused the model’s ability for "much more natural human-computer interaction". In this article, we will discuss what GPT-4o is, how it differs from previous models, evaluate its performance, and use cases for GPT-4o.
What is GPT-4o?
OpenAI’s GPT-4o, the “o” stands for omni (meaning ‘all’ or ‘universally’), was released during a live-streamed announcement and demo on May 13, 2024. It is a multimodal model with text, visual and audio input and output capabilities, building on the previous iteration of OpenAI’s GPT-4 with Vision model, GPT-4 Turbo. The power and speed of GPT-4o comes from being a single model handling multiple modalities. Previous GPT-4 versions used multiple single purpose models (voice to text, text to voice, text to image) and created a fragmented experience of switching between models for different tasks.
Compared to GPT-4T, OpenAI claims it is twice as fast, 50% cheaper across both input tokens ($5 per million) and output tokens ($15 per million), and has five times the rate limit (up to 10 million tokens per minute). GPT-4o has a 128K context window and has a knowledge cut-off date of October 2023. Some of the new abilities are currently available online through ChatGPT, through the ChatGPT app on desktop and mobile devices, through the OpenAI API (see API release notes), and through Microsoft Azure.
What’s New in GPT-4o?
While the release demo only showed GPT-4o’s visual and audio capabilities, the release blog contains examples that extend far beyond the previous capabilities of GPT-4 releases. Like its predecessors, it has text and vision capabilities, but GPT-4o also has native understanding and generation capabilities across all its supported modalities, including video.
As Sam Altman points out in his personal blog, the most exciting advancement is the speed of the model, especially when the model is communicating with voice. This is the first time there is nearly zero delay in response and you can engage with GPT-4o similarly to how you interact in daily conversations with people.
Less than a year after releasing GPT-4 with Vision (see our analysis of GPT-4 from September 2023), OpenAI has made meaningful advances in performance and speed which you don’t want to miss.
Let’s get started!
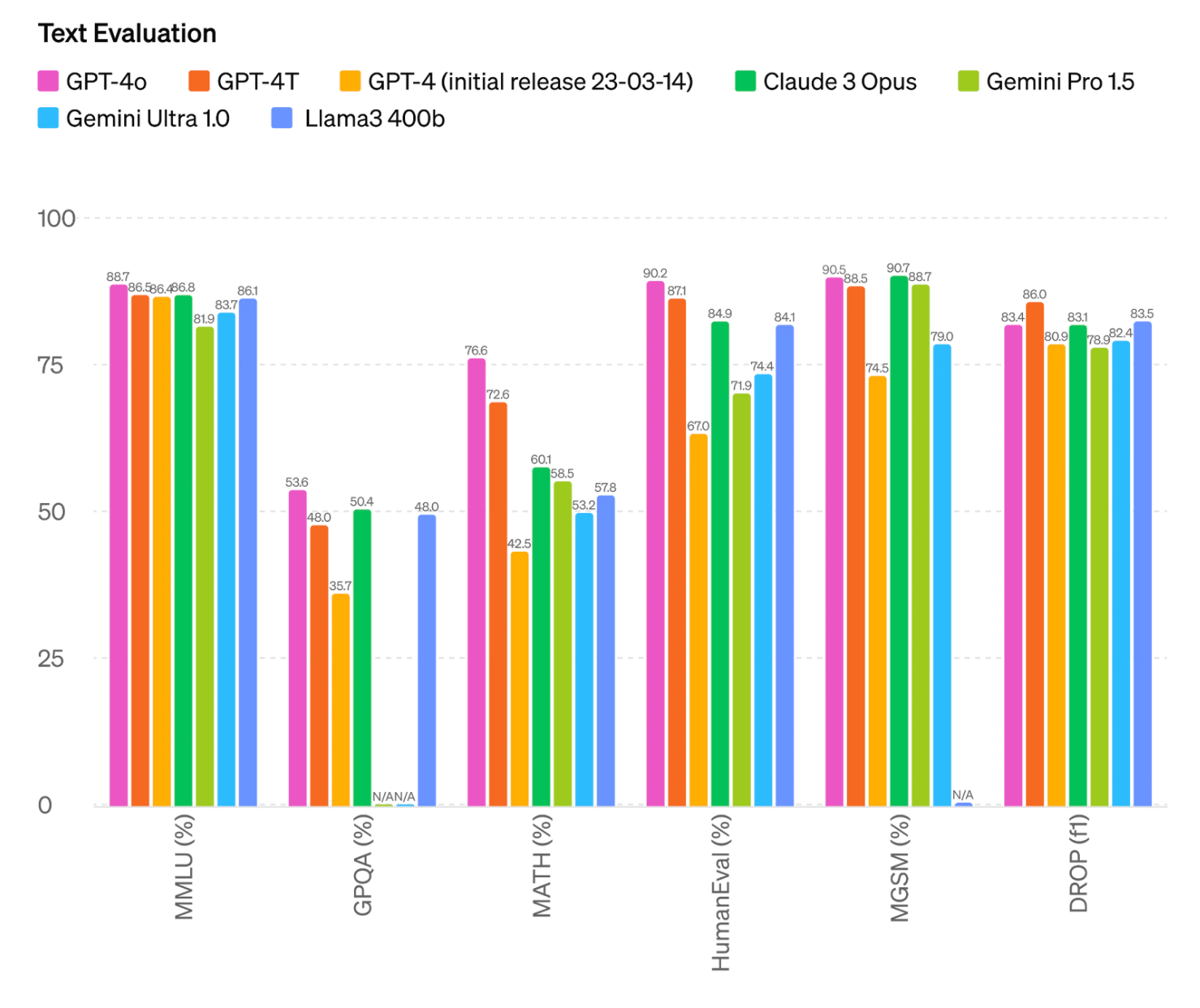
Text Evaluation of GPT-4o
For text, GPT-4o features slightly improved or similar scores compared to other LMMs like previous GPT-4 iterations, Anthropic's Claude 3 Opus, Google's Gemini and Meta's Llama3, according to self-released benchmark results by OpenAI.
Note that in the text evaluation benchmark results provided, OpenAI compares the 400b variant of Meta’s Llama3. At the time of publication of the results, Meta has not finished training its 400b variant model.
Video Capabilities of GPT-4o
Important note from the API release notes regarding use with video: “GPT-4o in the API supports understanding video (without audio) via vision capabilities. Specifically, videos need to be converted to frames (2-4 frames per second, either sampled uniformly or via a keyframe selection algorithm) to input into the model.” Use the OpenAI cookbook for vision to better understand how to use video as an input and the limitations of the release.
GPT-4o is demonstrated having both the ability to view and understand video and audio from an uploaded video file, as well as the ability to generate short videos.
Within the initial demo, there were many occurrences of GPT-4o being asked to comment on or respond to visual elements. Similar to our initial observations of Gemini, the demo didn’t make it clear if the model was receiving video or triggering an image capture whenever it needed to “see” real-time information. There was a moment in the initial demo where GPT-4o may have not triggered an image capture and therefore saw the previously captured image.
In this demo video on YouTube, GPT-4o “notices” a person coming up behind Greg Brockman to make bunny ears. On the visible phone screen, a “blink” animation occurs in addition to a sound effect. This means GPT-4o might use a similar approach to video as Gemini, where audio is processed alongside extracted image frames of a video.

The only demonstrated example of video generation is a 3D model video reconstruction, though it is speculated to possibly have the ability to generate more complex videos.
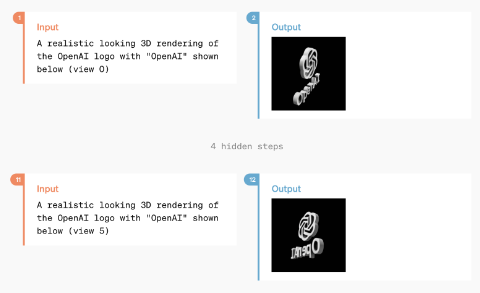

An exchange between GPT-4o where a user requests and receives a 3D video reconstruction of a spinning logo based on several reference images
Audio Capabilities of GPT-4o
Similar to video and images, GPT-4o also possesses the ability to ingest and generate audio files.
GPT-4o shows an impressive level of granular control over the generated voice, being able to change speed of communication, alter tones when requested, and even sing on demand. Not only could GPT-4o control its own output, it has the ability to understand the sound of input audio as additional context to any request. Demos show GPT-4o giving tone feedback to someone attempting to speak Chinese as well as feedback on the speed of someone’s breath during a breathing exercise.
According to self-released benchmarks, GPT-4o outperforms OpenAI’s own Whisper-v3, the previous state-of-the-art in automatic speech recognition (ASR) and outperforms audio translation by other models from Meta and Google.
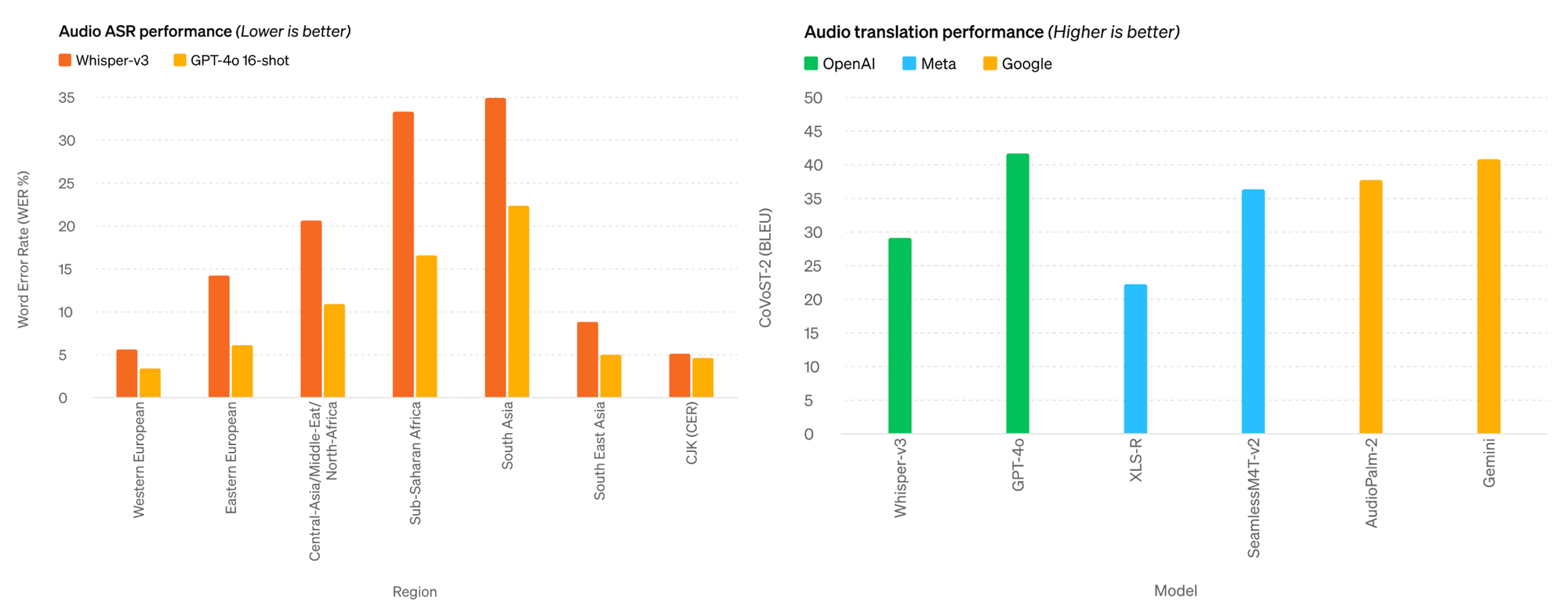
Image Generation with GPT-4o
GPT-4o has powerful image generation abilities, with demonstrations of one-shot reference-based image generation and accurate text depictions.
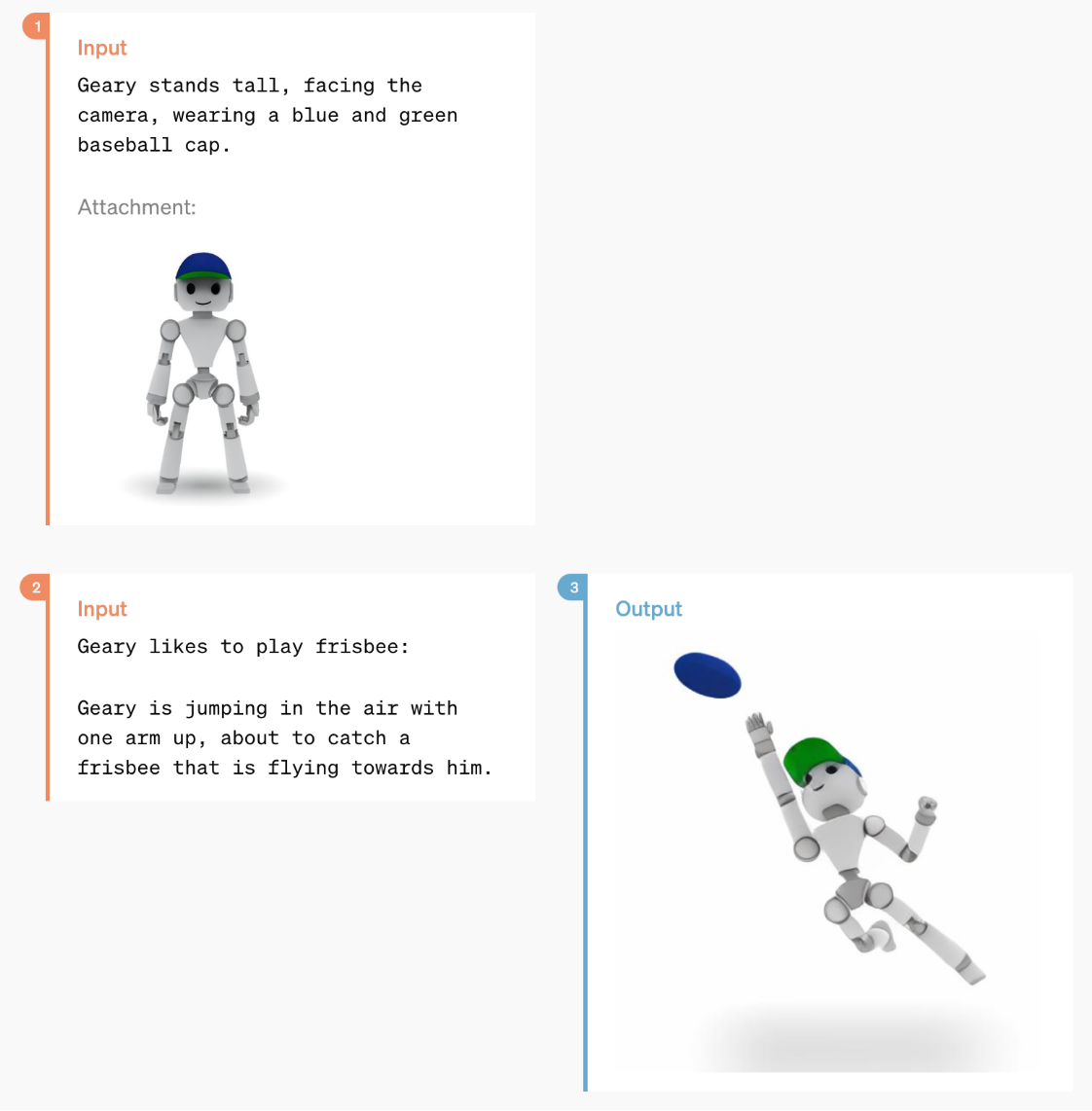
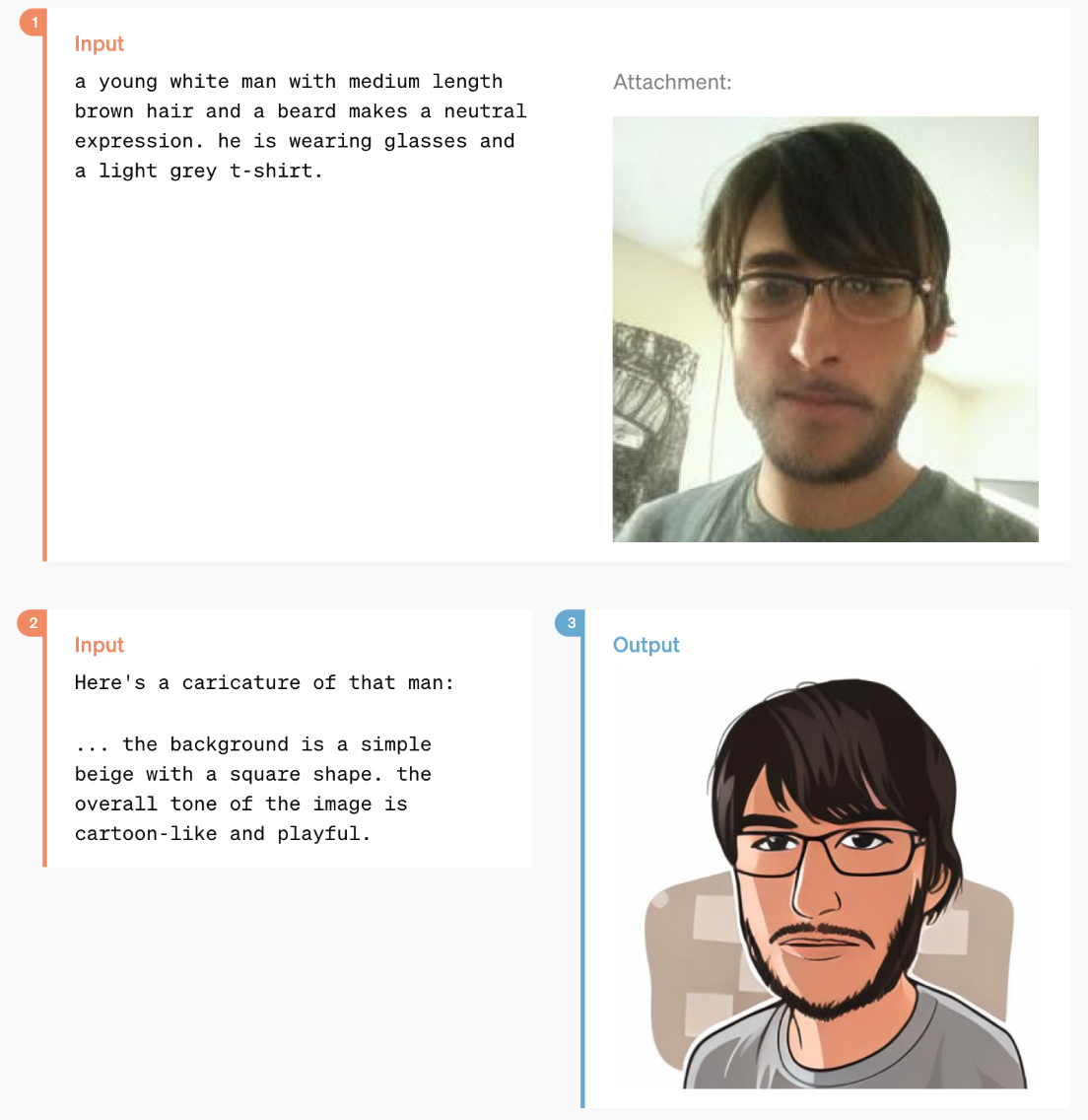
User/GPT-4o exchanges generating images (Image Credit: OpenAI)
The images below are especially impressive considering the request to maintain specific words and transform them into alternative visual designs. This skill is along the lines of GPT-4o’s ability to create custom fonts.

Visual Understanding of GPT-4o
Although state-of-the-art capability that existed in previous iterations, visual understanding is improved, achieving state of the art across several visual understanding benchmarks against GPT-4T, Gemini, and Claude. Roboflow maintains a less formal set of visual understanding evaluations, see results of real world vision use cases for open source large multimodal models.
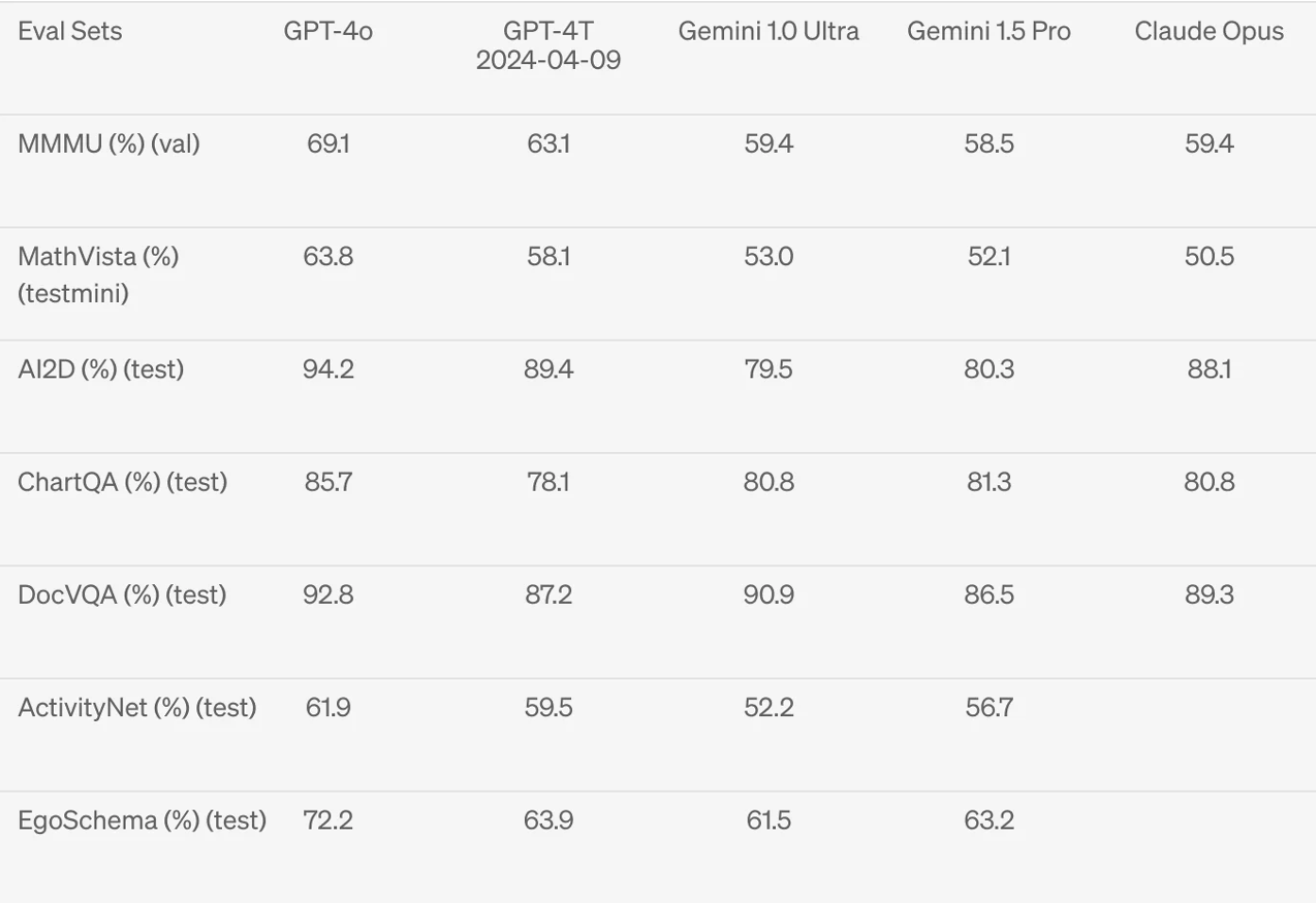
Although the OCR capability of GPT-4o was not published by OpenAI, we will evaluate it later in this article.
Evaluating GPT-4o for Vision Use Cases
Next, we use both the OpenAI API and the ChatGPT UI to evaluate different aspects of GPT-4o, including optical character recognition (OCR), document OCR, document understanding, visual question answering (VQA) and object detection.

Optical Character Recognition (OCR) with GPT-4o
OCR is a common computer vision task to return the visible text from an image in text format. Here, we prompt GPT-4o to “Read the serial number.” and “Read the text from the picture”, both of which it answers correctly.
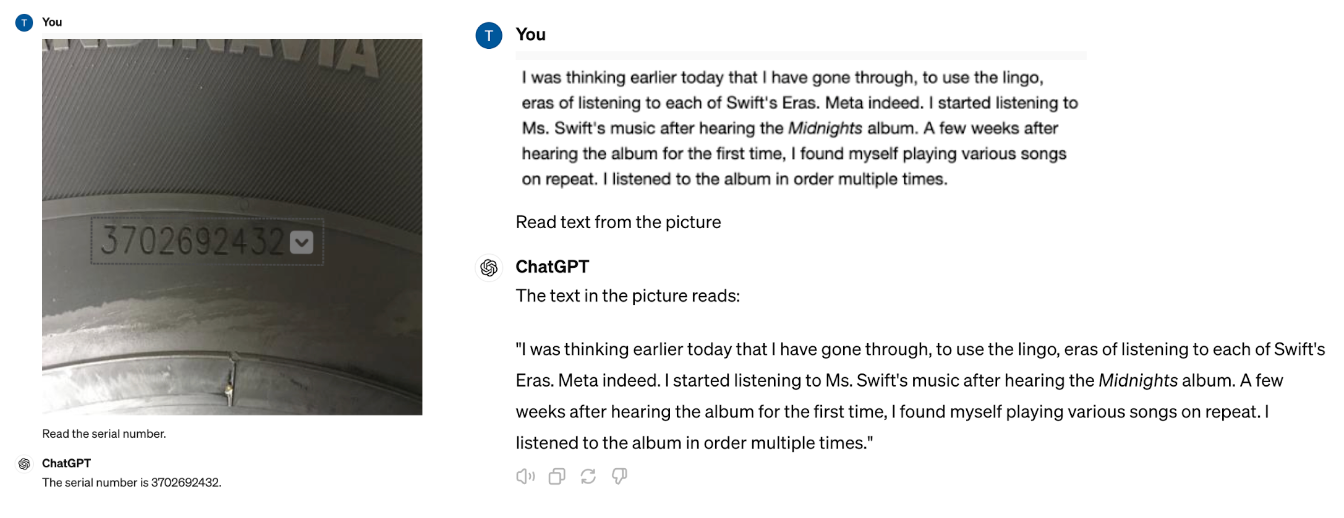
Next, we evaluated GPT-4o on the same dataset used to test other OCR models on real-world datasets.
Here we find a 94.12% average accuracy (+10.8% more than GPT-4V), a median accuracy of 60.76% (+4.78% more than GPT-4V) and an average inference time of 1.45 seconds.
The 58.47% speed increase over GPT-4V makes GPT-4o the leader in the category of speed efficiency (a metric of accuracy given time, calculated by accuracy divided by elapsed time).
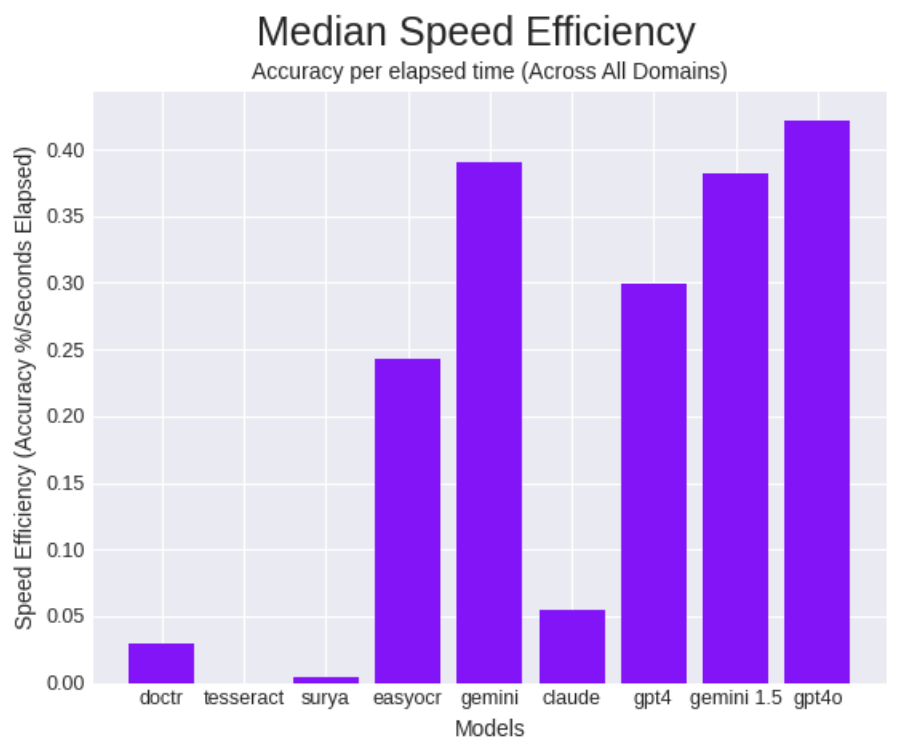
Document Understanding with GPT4-o
Next, we evaluate GPT-4o’s ability to extract key information from an image with dense text. Prompting GPT-4o with “How much tax did I pay?” referring to a receipt, and “What is the price of Pastrami Pizza” in reference to a pizza menu, GPT-4o answers both of these questions correctly.
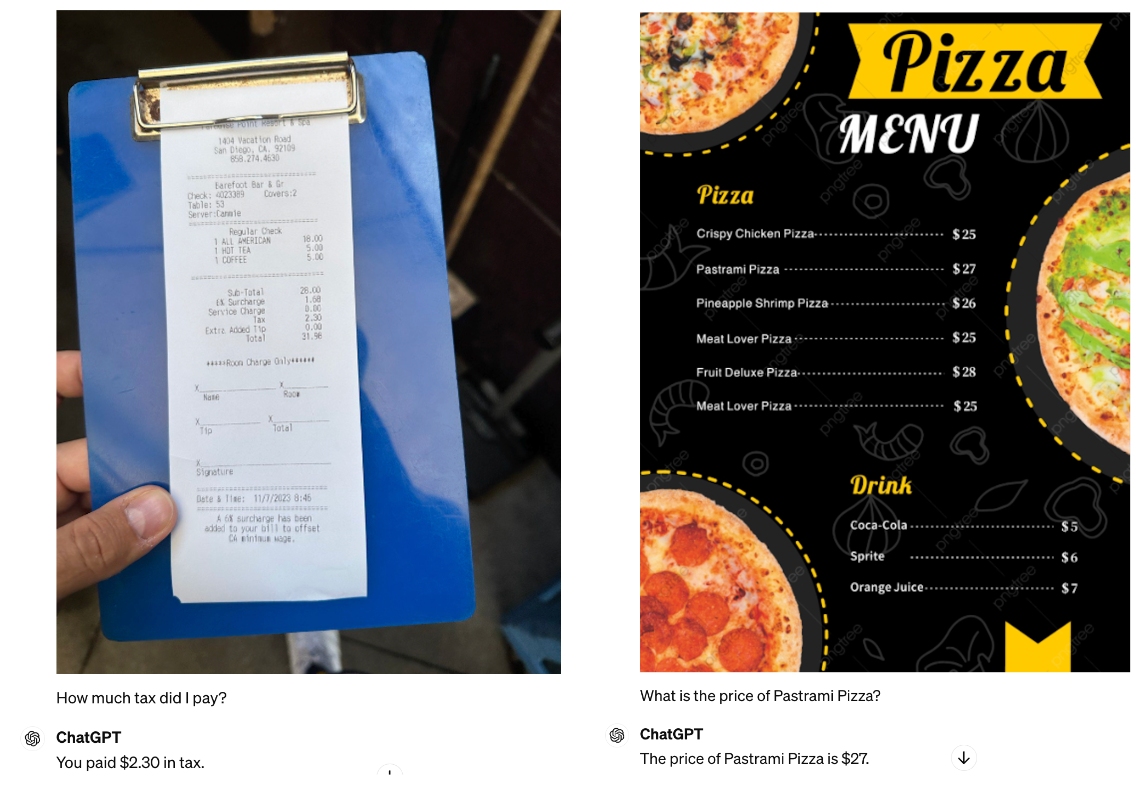
This is an improvement from GPT-4 with Vision, where it failed the tax extraction from the receipt.
Visual Question Answering with GPT-4o
Next is a series of visual question and answer prompts. First, we ask how many coins GPT-4o counts in an image with four coins.
GPT-4o the answer of five coins. However, when retried, it did answer correctly. This change in response is a reason a site call GPT Checkup exists – closed-source LMM performance changes overtime and it’s important to monitor how it performs so you can confidently use an LMM in your application.

This suggests that GPT-4o suffers from the same inconsistent ability to count as we saw in GPT-4 with Vision.
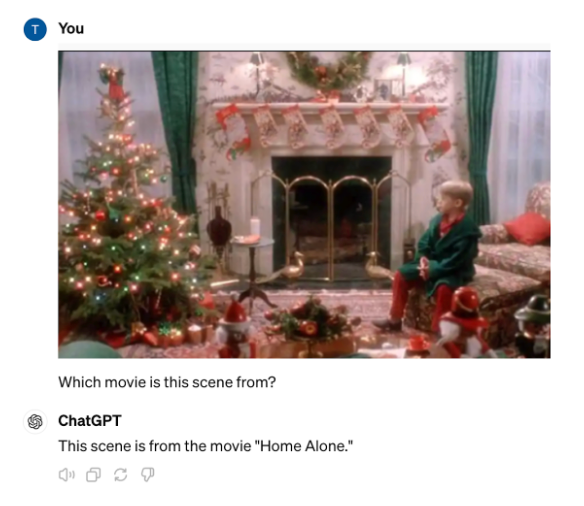
Further, GPT-4o correctly identifies an image from a scene of Home Alone.
Object Detection with GPT-4o
Finally, we test object detection, which has proven to be a difficult task for multimodal models. Where Gemini, GPT-4 with Vision, and Claude 3 Opus failed, GPT-4o also fails to generate an accurate bounding box.

GPT-4o Use Cases
As OpenAI continues to expand the capabilities of GPT-4, and eventual release of GPT-5, use cases will expand exponentially. The release of GPT-4 made image classification and tagging extremely easy, although OpenAI’s open source CLIP model performs similarly for much cheaper. Adding vision capabilities made it possible to combine GPT-4 with other models in computer vision pipelines which creates the opportunity to augment open source models with GPT-4 for a more fully featured custom application using vision.
A few key elements of GPT-4o opens up another set of use cases that were previously not possible and none of these use cases have anything to do with better model performance on benchmarks. Sam Altman’s personal blog states they have a clear intention to “Create AI and then other people will use it to create all sorts of amazing things that we all benefit from“. If OpenAI’s goal is to keep driving cost down and improve performance, where does that take things?
Let’s consider a few new use cases.
Real-time Computer Vision Use Cases
The new speed improvements matched with visual and audio finally open up real-time use cases for GPT-4, which is especially exciting for computer vision use cases. Using a real-time view of the world around you and being able to speak to a GPT-4o model means you can quickly gather intelligence and make decisions. This is useful for everything from navigation to translation to guided instructions to understanding complex visual data.
Interacting with GPT-4o at the speed you’d interact with an extremely capable human means less time typing text to us AI and more time interacting with the world around you as AI augments your needs.
One-device Multimodal Use Cases
Enabling GPT-4o to run on-device for desktop and mobile (and if the trend continues, wearables like Apple VisionPro) lets you use one interface to troubleshoot many tasks. Rather than typing in text to prompt your way into an answer, you can show your desktop screen. Instead of copying and pasting content into the ChatGPT window, you pass the visual information while simultaneously asking questions. This decreases switching between various screens and models and prompting requirements to create an integrated experience.
GPT4-o’s single multimodal model removes friction, increases speed, and streamlines connecting your device inputs to decrease the difficulty of interacting with the model.
General Enterprise Applications
With additional modalities integrating into one model and improved performance, GPT-4o is suitable for certain aspects of an enterprise application pipeline that do not require fine-tuning on custom data. Although considerably more expensive than running open source models, faster performance brings GPT-4o closer to being useful when building custom vision applications.
You can use GPT-4o where open source models or fine-tuned models aren’t yet available, and then use your custom models for other steps in your application to augment GPT-4o’s knowledge or decrease costs. This means you can quickly start prototyping complex workflows and not be blocked by model capabilities for many use cases.
Conclusion
GPT-4o’s newest improvements are twice as fast, 50% cheaper, 5x rate limit, 128K context window, and a single multimodal model are exciting advancements for people building AI applications. More and more use cases are suitable to be solved with AI and the multiple inputs allow for a seamless interface.
Faster performance and image/video inputs means GPT-4o can be used in a computer vision workflow alongside custom fine-tuned models and pre-trained open-source models to create enterprise applications.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno, Trevor Lynn. (May 14, 2024). GPT-4o: The Comprehensive Guide and Explanation. Roboflow Blog: https://blog.roboflow.com/gpt-4o-vision-use-cases/