
This benchmarking study measures Roboflow computer vision model inference on Intel 4th Gen Xeon Sapphire Rapids against AWS Lambda (Broadwell) and GCP C3 instances across speed, frames per hour, and cost per frame. With Intel optimization techniques applied to M7i instance types, inference time drops by over 60% compared to the baseline, and the m7i-flex.8xlarge delivers the best cost-speed tradeoff at roughly $0.004 per frame, making it a practical CPU alternative during GPU shortages.
With the rise of large language models (LLM’s), people often forget about the vast, important world of computer vision. This world is evolving at an unprecedented pace, driven by advancements in hardware and AI models, just as with LLM’s.
In this three-part blog post, through the Intel Disruptor program, we embark on a benchmarking study that explores how to achieve superior performance gains of Roboflow's models on Intel's 4th generation Xeon processor known as Sapphire Rapids.
Sapphire Rapids was released in January of 2023. It is built with CPU + Accelerators and provides superior performance for AI workloads. It is a general purpose processor but also improves greatly on acceleration and AI workloads from previous generations.
These new accelerators average 2.9X improvement in performance-per-watt over those previous-gen models in some workloads. They also have a 10X improvement in AI inference and training, and a 3X improvement in data analytics workloads.
In the following post we first start out benchmarking inference of a Roboflow model on Sapphire Rapids vs AWS Lambda. Lambda is a serverless computing platform provided by AWS and runs code in response to events and automatically manages the computing resources required by that code. It is ideal for smaller scale, less heavy AI inference workloads.
Let's get started!
Part 1: Benchmarking Superior Accelerated Performance with Intel Xeon Sapphire Rapids
First, we will dive into benchmarking Sapphire Rapids vs AWS Lambda to showcase the great capabilities of this new chip. We are utilizing Roboflow models and comparing Lambda to that of GCP C3 instances. In this case we are actually benchmarking Intel against an older generation chip, as AWS Lambda runs on Intel's Xeon Broadwell.
The GCP C3 machine series are powered by the 4th Gen Intel Xeon Scalable processor Sapphire Rapids and Google’s custom Intel Infrastructure Processing Unit (IPU). This is paired with Hyperdisk block storage which offers 80% higher IOPS per vCPU for high-end database management system (DBMS) workloads when compared to other hyperscalers. C3’s deliver strong performance gains to enable high performance computing and data-intensive workloads.
The GCP C3 instance type comes standard, high CPU, high memory and local SSD, as well in a variety of sizes.
For this benchmarking we used a relatively small instance type of c3-highcpu-8 in GCP and a Roboflow model trained on the BCCD (BloodCell count) dataset in Roboflow Universe.
The benchmarking results are as follows:
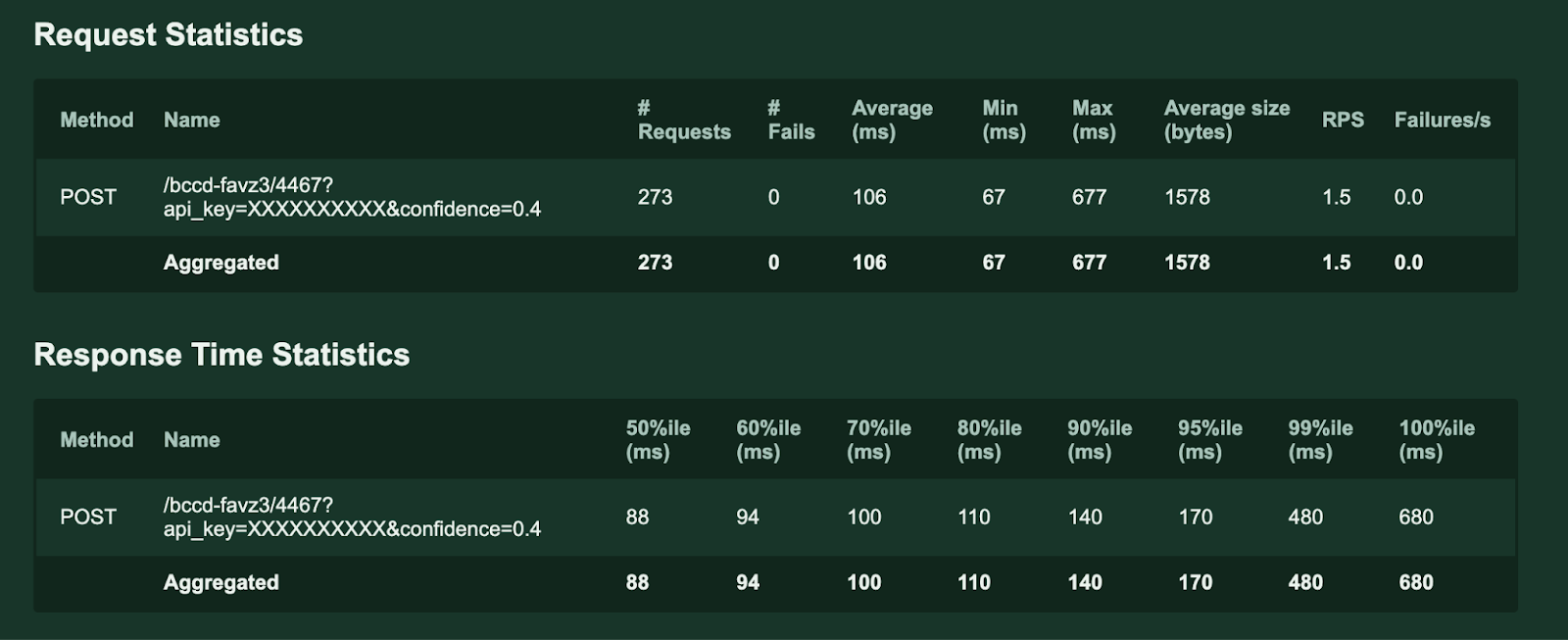
AWS Lambda
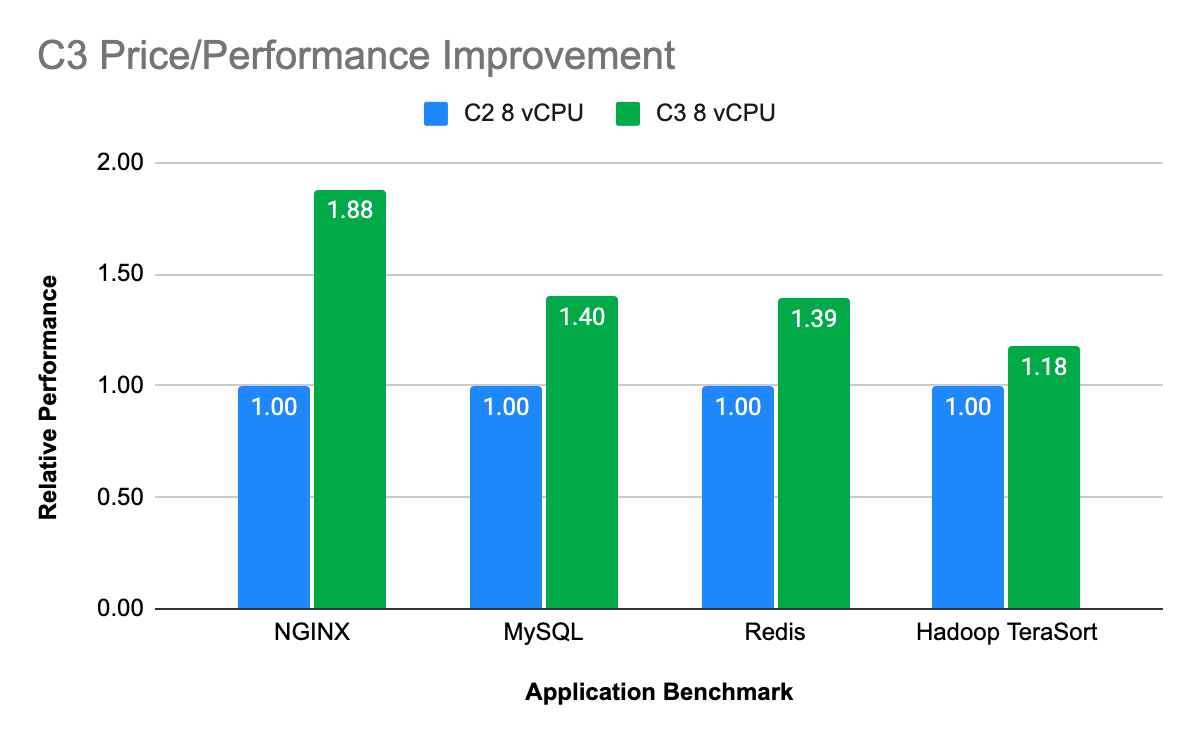
C3-highcpu-8
As you can see, the average response time per request is about 20% faster in the C3 Sapphire Rapids instance than that of AWS Lambda. This is not factoring further optimization of the C3 instance using Intel optimization techniques (which will be shown in our 3rd part of the blog)
As for pricing comparison, this is where it gets a little tricky. Lambda pricing is per request so a test of this small scale would definitely end up costing more in the GCP C3 instance, as it is a hard server that is charging you while up, and billed by the hour. But ML inference is typically at scale and often in real time or near real time. Lambda becomes extremely expensive and hard to manage when you hit it at production level inference at scale.
To conclude, these results show the superiority of Sapphire Rapids over its predecessor, Xeon Broadwell, revealing accelerated inference that outpaces legacy hardware. This leap in performance demonstrates the potential of Roboflow models to leverage the more efficient and accelerated compute of Intel hardware and CPU for accelerated inference, saving costs in comparison to running inference on GPU backed hardware.
Part 2: Benchmarking Meta's SAM Segmentation Model on AWS 3 generations of Intel hardware
Now we demonstrate the further progress of Intel hardware by moving over to AWS benchmarking older intel generations vs the new M7i and M7i-flex Sapphire Rapids instance types. These instances were just released at the beginning of August 2023, and offer up to 15% better performance over comparable x86-based Intel processors utilized by other cloud providers.
Here we will benchmark Meta's Segment Anything (SAM) segmentation model on a variety of Intel backed AWS instances such as the T2.2xlarge, M5.16xlarge, M6i,16xlarge, M7i.16xlarge, and the M7i-flex.8xlarge. SAM is a new computer vision model from Meta AI that can "cut out" any object, in any image, with a single click. This is a transformer based model so it is heavier - therefore harder on inference - than your typical vision model.
The T2 instance type is an older generation Xeon and powered by Intel Broadwell, just as AWS Lambda was in our previous benchmarking. Although they don't have the larger size instance types we used with the M5, M6 and M7, we were able to work backwards to get the cost per frame and frames per second counts for a true comparison.
The M5 instance type is another older generation Xeon and powered by Cascade Lake. The M6i is powered by the previous generation Xeon Ice Lake.
M7i-flex and M7i instances are next-generation general purpose instances powered by custom 4th Generation Intel Xeon Sapphire Rapids and feature a 4:1 ratio of memory to vCPU. M7 instances offer the best performance among comparable Intel processors in the cloud – up to 15% better performance than Intel processors utilized by other cloud providers.
M7i-flex instances provide the easiest way for you to get price performance benefits for a majority of general-purpose workloads. They deliver up to 19% better price performance compared to M6i instances.
M7i-flex instances offer the most common sizes, from large to 8xlarge, with up to 32 vCPUs, 128 GiB memory, and are a great first choice for applications that don't fully utilize all compute resources. M7i-flex instances are designed to seamlessly run the most common general-purpose workloads, including web and application servers, virtual desktops, batch processing, microservices, databases, and enterprise applications.
M7i instances offer price performance benefits for workloads that need larger instance sizes (up to 192 vCPUs and 768 GiB memory) or continuous high CPU usage. M7i instances are ideal for workloads including large application servers and databases, gaming servers, CPU-based machine learning (ML), and video streaming. M7i instances deliver up to 15% better price performance compared to M6i instances.
We dive deep in showcasing how the parallel processing capabilities of Intel's hardware enable real-time inference for complex segmentation tasks. The partnership between Roboflow and Intel empowers businesses with advanced segmentation capabilities, revolutionizing applications in industries ranging from medical imaging to autonomous vehicles.
Through this benchmarking we are able to show the superior performance for accelerated inference in the new M7i and M7i-flex instances.
The benchmarking results are as follows:
As you can see, our benchmarking shows that the new Sapphire Rapids instances are far superior in inference speed and cost per frame in comparison to previous Xeon generations, outside of the T2 instance type. But this is a bit misleading as the instance is small and would not be able to be used for anything at scale. It’s also extremely slow in comparison to the other instance types, which meets the hypothesis that Xeon Broadwell is an inferior chip at this point.
The M7i-flex gives you the best mix of speed and total cost. It is worth pointing out that this benchmarking is using baseline Intel instance types, without adding further Intel software optimizations. Adding these optimizations can greatly increase your inference speed and reduce overall cost. Next we will jump right into benchmarking these software optimizations.
Part 3: Accelerated Inference and Optimization with Intel's Advanced Software
Now we will move onto a powerful piece to Intel - pairing their accelerated software with hardware and explore the art of optimization and accelerated inference by leveraging Intel's state-of-the-art optimization software.
Here we have applied several optimization techniques to inferencing. Leveraging IntelMPI, the inferencing task is evenly distributed and bonded to the physical cores to handle complex computations. Intel Extension for PyTorch (IPEX) enabled PyTorch to run the model efficiently using well optimized operators. The unique Advanced Matrix Extensions (AMX) instructions on 4th generation Xeon Sapphire Rapids improved the throughput by utilizing a new datatype - BF16 (through Automatic Mixed Precision) in the model.
Optimization techniques:
- IntelMPI
- Intel Extension for PyTorch (IPEX)
- AMX + BF16 + Automatic Mixed Precision
Results:


Through this experimentation and refinement, we discover the ability of Intel's optimization tools in unlocking peak performance and efficiency.
As in the previous benchmarking, AMX+BF16 were not used. Now with the unique AMX + BF16 support on SPR, inference is much improved.
The results are as follow:
As you can see, through optimization techniques and Intel software, we are able to get even better results when it comes to inference time and accelerated inference. For the M7 instance types we were able to reduce our inference times over 60% when integrating Intel optimization techniques, with a massive spike on the frames you can process per hour, therefore greatly reducing the cost. As you can see, once again the M7i-Flex wins out for best combination of speed and cost per frame.
The convergence of Roboflow's advanced computer vision models and Intel's cutting-edge hardware sets the stage for a new era of innovation in computer vision. This benchmarking was able to showcase the performance leap Intel has taken into AI with Sapphire Rapids offering a CPU alternative for ML inference at scale.
With GPU shortages happening across the world, Intel is in a unique position to capitalize on a market hungry for AI compute.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (Sep 14, 2023). Roboflow Computer Vision Models on Intel® 4th Generation Xeon Processors. Roboflow Blog: https://blog.roboflow.com/computer-vision-intel-4th-generation-xeon-processors/