
CVPR 2022 in New Orleans surfaced three clear themes across its submitted research: vision transformers displacing CNN architectures at scale, multi-modal models expanding what computer vision systems can reason about, and transfer learning techniques being hardened for reliable cross-domain adaptation. Notable directions included slimming vision transformers for real-time inference, few-shot object detection, and findings that transformer-based models generalize better than CNNs when moved beyond ImageNet benchmarks. For teams in applied computer vision, these trends point toward transformer-based backbones and pre-trained foundation models as the practical default going forward.
The Computer Vision and Pattern Recognition (CVPR) conference was held this week (June 2022) in New Orleans, pushing the boundaries of computer vision research.

In this post, we take the opportunity to reflect on the computer vision research landscape at CVPR 2022 and highlight our favorite research papers and themes.
Computer Vision Research Landscape at CVPR 2022
When one says computer vision, a number of things come to mind such as self-driving cars and facial recognition. For those of us in applied computer vision, tasks like object detection and instance segmentation come to mind.
For computer vision researchers at CVPR, computer vision means many things according to their focus. Here are the research categories at CVPR 2022 sorted by number of papers in each focus:
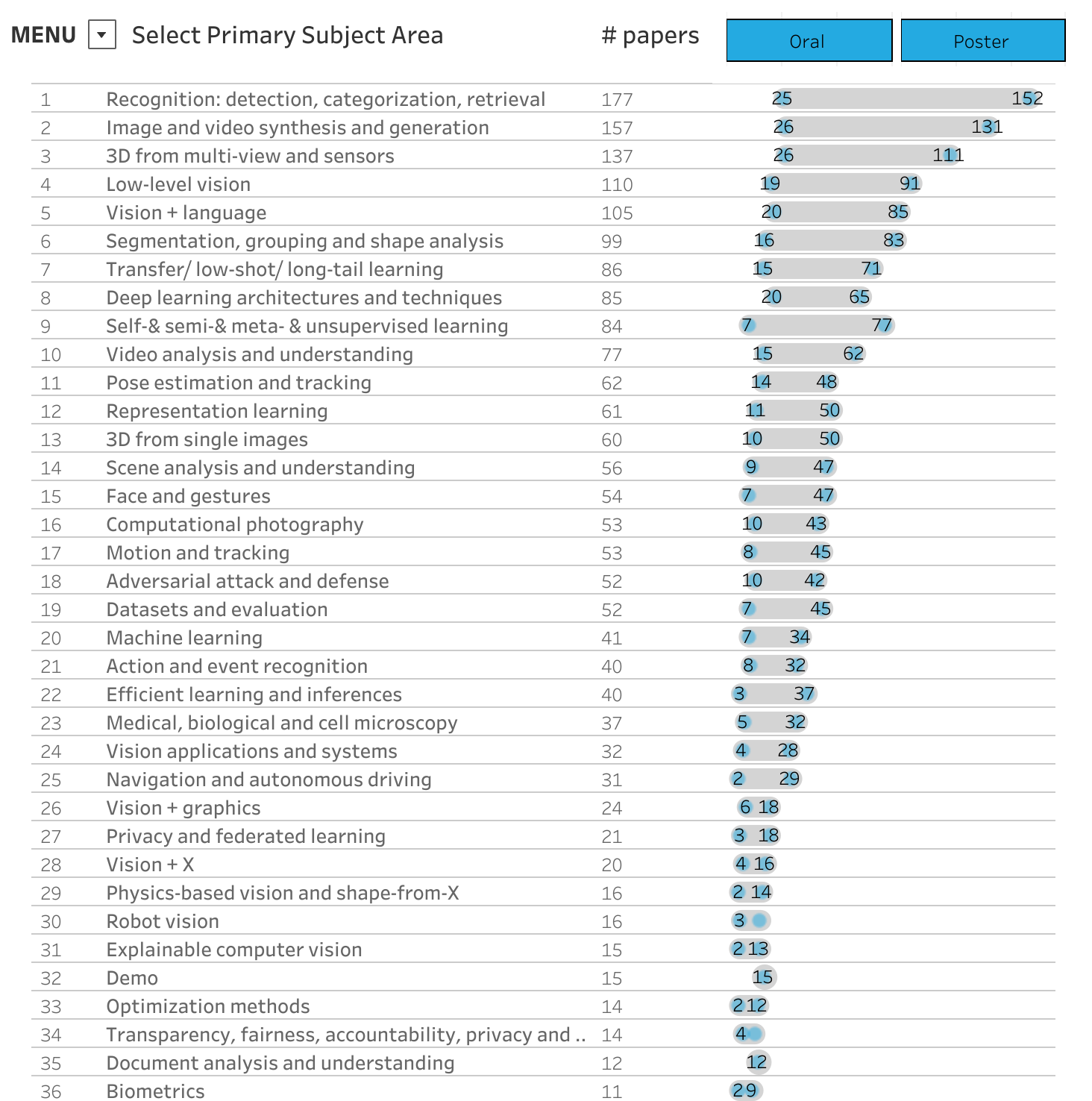
From this list we can see the top two categories that researchers focus on: detection/recognition and generation. Detection involves making inference from an image like object detection and generation involves generating new images, like DALL E. Other categories at CVPR are more foundational, such as deep learning architectures.
From our view, the most important themes at CVPR 2022 this year boiled down to:
- Transformers Taking over CV Modeling
- Multi-modal Research Expanding What is Possible
- Transfer Learning is Being Battle Hardened
Transformers Taking over CV Modeling
The transformer architecture was originally introduced in the NLP world for machine translation. The transformer architecture was part of a family of sequence modeling frameworks used on language like RNNs, and LSTMs. It has become increasingly evident that transformers do a better job of modeling most tasks, and the computer vision community is leaning into their adoption and implementation.
- Scaling Vision Transformers - researchers are working on techniques to more efficiently scale the size of vision transformers
- Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space - researchers are working on ways to slim vision transformers down to make them more tractable for inference. This will be an important area of study as vision transformers become more usable in realtime applications
- Delving Deep Into the Generalization of Vision Transformers Under Distribution Shifts - Vision transformers are found to generalize better than CNNs to domain shift
Multi-modal Research Expanding What is Possible
Multi-modal research involves combining the semantics of multiple data types, like text and images. Recently, it has been found that rich deep learning representations are formed in multi-modal models, pushing the limits of what is possible - like generating an image from text, or providing a list of captions to draw detection predictions out of an image.
Globetrotter: Connecting Languages by Connecting Images - Images are found to provide connecting semantics across human languages.
Learning To Prompt for Open-Vocabulary Object Detection With Vision-Language Mode - zero-shot description+image detection approaches require a prompt or "proposal". It can be hard to nail down the right "proposal" to feed a network to accurately describe what you are after. This paper investigates how to generate proper proposals.
Are Multimodal Transformers Robust to Missing Modality? - This paper investigates whether multi-modal models learn representations that are general to semantics in general, not just the data types that they have seen.
Grounded Language-Image Pre-Training - GLIP learns across language and images - GLIP demonstrates state of the art performance on object detection COCO when fine-tuned and while less accurate, astonishing zero-shot performance.
Transfer Learning is Being Battle Hardened
It is common in machine learning today to pre-train a model on a general domain (like the entire web) with a general task, and then fine-tune that model into the domain that it is being applied to (like identifying missing screws in a factory). A lot of work at CVPR was done on battle hardening these techniques.
Robust Fine-Tuning of Zero-Shot Models - this paper finds that it is effective to keep a set of pre-trained weights along with fine-tuned weights when adapting across domains.
Few-Shot Object Detection With Fully Cross-Transformer - when you do not have much data few-shot detection allows you to train a model quickly with just a few examples to learn from. Few-shot detection is often used to measure how quickly new models adapt to new domains.
Does Robustness on ImageNet Transfer to Downstream Tasks? - Transformers are found to generalize better than traditional CNNs as they are applied to tasks beyond ImageNet, a popular computer vision classification benchmark.
There are many papers released during each CVPR annual conference and you can access previous papers to see how the industry focus has evolved. Hopefully this shortened list was a helpful way to find important takeaways from this year's group of papers.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Jun 24, 2022). CVPR 2022 - Best Papers and Highlights. Roboflow Blog: https://blog.roboflow.com/cvpr-2022-best-papers-and-highlights/