
Roboflow Inference can be deployed as a Docker container on any cloud provider, and SkyPilot automates the process by selecting the cheapest available cloud region and configuring the infrastructure automatically. This tutorial shows how to spin up a GPU-backed Inference server using a single CLI command, then use it to run YOLO-World zero-shot detection, custom models from Roboflow Universe, and CLIP image embeddings, with a matching teardown command to shut everything down when finished.
You can now deploy Roboflow Inference into any cloud with SkyPilot. In this guide, we walk through how to deploy Inference with SkyPilot.
Read the Inference Cloud Deploy documentation, including all the options available, and more about SkyPilot.
What Is Inference?
Roboflow Inference is an open-source platform that simplifies the deployment of state-of-the-art foundation and custom computer vision models.
Inference allows you to perform object detection, classification, and instance segmentation and use foundation models like CLIP, Segment Anything, and YOLO-World through a Python-native package, a self-hosted inference server, or a fully managed API. Inference supports streaming on video, active learning (smart sampling of where your models fail), and a unified API to swap between models.
The close integration between Inference and Roboflow’s comprehensive computer vision dataset management suite and serverless auto-training make Inference the no-friction choice for over 250,000 developers and ML practitioners. Inference is built from the learnings we encounter serving hundreds of millions of API calls per month across tens of thousands of models.
Using Inference with SkyPilot
The Roboflow Inference server can be downloaded as a Docker image and deployed on CPU or GPU machines on any cloud provider.
To simplify this process, Roboflow Inference has integrated SkyPilot into the inference CLI. SkyPilot implements the Sky Computing paradigm: Workloads are submitted to SkyPilot, which automatically figures out the cheapest and most available clouds/regions to suit the workload’s requirements, and seamlessly orchestrates the workload on the chosen location(s). In this Sky paradigm, infrastructure differences across clouds are abstracted away by the framework, making different clouds much easier to use for the end users.
Roboflow has integrated the sky API into its inference CLI, so now the rich and accessible computer vision Roboflow inference feature set can be spun up in cloud environments using Sky Pilot's extensive cloud infrastructure abstraction.
The integration makes deploying an inference server for state-of-the-art models on CPUs or GPUs possible with a couple of commands from the terminal. This gets you to inference fast and without having to worry about spinning up right-sized VMs, installing/configuring GPU drivers and Docker, and dealing with issues like firewalls.
Setup SkyPilot
To get started, run the following commands:
pip install inference "skypilot[gcp,aws]"
inference cloud deploy --provider gcp --compute-type gpuNote this assumes that you have already installed and configured the gcloud CLI with a GCP project on the terminal.
This installs the Roboflow Inference and SkyPilot (along with its AWS and GCP plugins) and also starts a virtual machine with a GPU on the GCP cloud.
The inference CLI invokes SkyPilot to launch a GPU VM and install the appropriate Roboflow inference server docker containers and configure the firewall/port (9001).
The high level architecture diagram shows the integration between Skypilot and Roboflow Inference Server:
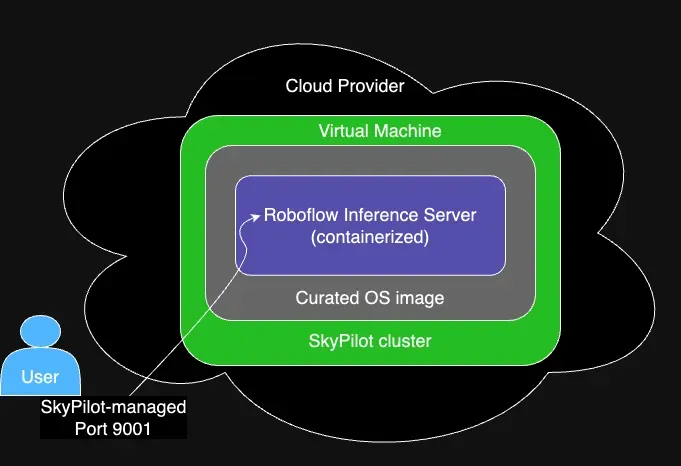
The final output should be the following:
Deployed Roboflow Inference to gcp on gpu, deployment name is roboflow-inference-gcp-gpu-oafsh
To get a list of your deployments: inference status
To delete your deployment: inference undeploy roboflow-inference-gcp-gpu-oafsh
To ssh into the deployed server: ssh roboflow-inference-gcp-gpu-oafsh
The Roboflow Inference Server is running at http://34.66.116.66:9001The output contains some useful information
- The name of the SkyPilot cluster (roboflow-inference-gcp-gpu-oafsh), this handle can be used with all sky cli commands.
- An ssh command to log into the VM (ssh roboflow-inference-gcp-gpu-oafsh)
- Commands to list deployments and delete this deployment
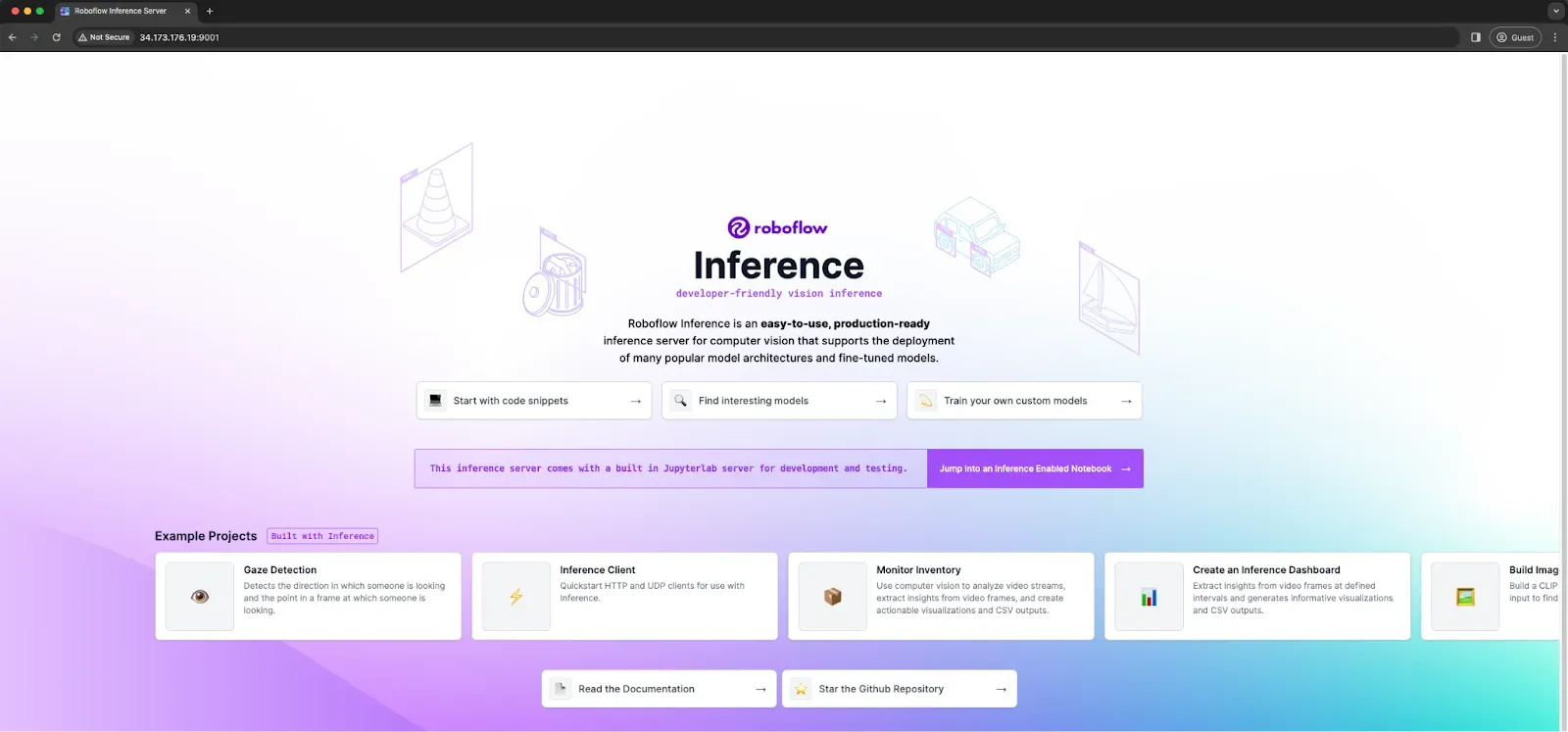
- The url for the inference server endpoint (http://34.66.106.65:9001); Visiting that link should open the Roboflow Inference server endpoint like shown below:
Use Inference
Now let's use our Roboflow GPU Inference server. We are going to use it to run zero-shot object detection, calculate CLIP embeddings, and run a custom Roboflow-trained model. This link opens a Colab notebook with all the code used below.
A side note: All the inference examples shown here will incur a “cold-start” when the model is first downloaded into the inference server (the first inference will be slow); subsequent inferences to the same model will be much faster.
Yolo World for Zero Shot Object Detection
YOLO-World is a zero-shot object detection model. You can use YOLO-World to identify objects in images and videos using arbitrary text prompts.
Create a new Python file and add the following code:
from inference_sdk import InferenceHTTPClient
from pprint import pprint
import supervision as sv
CLIENT = InferenceHTTPClient(api_url=roboflow_inference_server_url)
classes= ["apple", "strawberry", "grapes","blueberry","oranges","pinapples"]
results = CLIENT.infer_from_yolo_world(
image_url,
classes,
model_version="v2-m",
confidence=0.1,
)
detections = sv.Detections.from_inference(results[0])
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
labels = [classes[class_id] for class_id in detections.class_id]
annotated_image = bounding_box_annotator.annotate(
scene=img, detections=detections
)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections, labels=labels
)
sv.plot_image(annotated_image)Above, replace the classes variable with the names of the objects you want to identify
Here are the results from the script:

Our script successfully identified many fruits in the image. For a zero-shot model, the performance is significant.
Custom Models from Roboflow Universe
Use your Roboflow API key to use your own custom machine vision models or use any of the 100s of thousands of pre-trained models available on Roboflow Universe. Remember, since you are inferring on your own Roboflow inference server on your own infrastructure, you will not be billed per inference!
Lets start by using a model trained using the COCO dataset. This model is hosted on Roboflow Universe, a community where more than 50,000 computer vision models are available for deployment.
Create a new Python file and add the following code:
from inference_sdk import InferenceHTTPClient
from pprint import pprint
from google.colab import userdata
# Roboflow API Key - https://docs.roboflow.com/api-reference/authentication
ROBOFLOW_API_KEY = userdata.get("ROBOFLOW_API_KEY")
CLIENT = InferenceHTTPClient(
api_url=roboflow_inference_server_url,
api_key=ROBOFLOW_API_KEY
)
results = CLIENT.infer(image_url, model_id="coco/18")
detections = sv.Detections.from_inference(results)
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
labels = [ x['class'] for x in results['predictions']]
annotated_image = bounding_box_annotator.annotate(
scene=img, detections=detections
)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections, labels=labels
)
sv.plot_image(annotated_image)Our code returns:

The COCO model does not perform as well as YOLO-World for our use case, but this where training a fine-tuned model comes in.
You can also use your own custom trained Roboflow model and use the inference server to generate predictions. For this example we will use one of the hundreds of thousands of custom models created by the Roboflow community:
from inference_sdk import InferenceHTTPClient
from pprint import pprint
CLIENT = InferenceHTTPClient(
api_url=roboflow_inference_server_url,
api_key="YOUR-ROBOFLOW-API-KEY"
)
result = CLIENT.infer(image_url, model_id="animals-ij5d2/1")
pprint(result)The Roboflow inference server returns the inference result:
from inference_sdk import InferenceHTTPClient
from pprint import pprint
import requests
# Roboflow API Key - https://docs.roboflow.com/api-reference/authentication
ROBOFLOW_API_KEY = userdata.get("ROBOFLOW_API_KEY") # Visit
project_id = "fruit-classification-model"
model_version = 1
image_url = "https://source.roboflow.com/BTRTpB7nxxjUchrOQ9vT/eqiY4CjT1oBkB4grBFp8/original.jpg"
confidence = 0.01
iou_thresh = 0.2
api_key = ROBOFLOW_API_KEY
task = "object_detection"
# Use a raw HTTP request to get data from the inference server
infer_payload = {
"model_id": f"{project_id}/{model_version}",
"image": {
"type": "url",
"value": image_url,
},
"confidence": confidence,
"iou_threshold": iou_thresh,
"api_key": api_key,
}
res = requests.post(
f"{roboflow_inference_server_url}/infer/{task}",
json=infer_payload,
)
results = res.json()
detections = sv.Detections.from_inference(results)
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
labels = [ x['class'] for x in results['predictions']]
annotated_image = bounding_box_annotator.annotate(
scene=img, detections=detections
)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections, labels=labels
)
sv.plot_image(annotated_image)
The predictions from the Roboflow inference server for this model are visualized here:

CLIP Embeddings
CLIP is a machine learning model from OpenAI capable of generating embeddings for images and text. These embeddings can be used for zero shot classification, semantic image search, amongst many other use cases.
To generate image embeddings, use the following code:
import os
from inference_sdk import InferenceHTTPClient
from pprint import pprint
CLIENT = InferenceHTTPClient(
api_url=roboflow_inference_server_url,
)
embeddings = CLIENT.get_clip_image_embeddings(inference_input=image_url)
pprint(embeddings)Above, replace:
image_urlwith the URL of the image you want to use. This could be a URL, a NumPy array, or a file name.
The Roboflow inference server returns CLIP embeddings.
{'embeddings': [[0.3435309827327728,
-1.3829314708709717,
-0.2718336284160614,
0.1752624809741974,
-0.12145939469337463,
-0.3675161600112915,
0.20684199035167694,
0.674224317073822,
...
Cleanup
The infrastructure can be shut down with another single command, like so
inference cloud undeploy roboflow-inference-gcp-gpu-oafshSkyPilot Conclusion
Roboflow inference vastly simplifies users’ path to machine vision. Coupled with the powerful SkyPilot api that spins up infrastructure and configures it for Roboflow’s inference server, users can hit the ground running with powerful CPU or GPU-based inference servers of their choice, running within their own cloud provider accounts.
Bring vision models into production faster - start free with Roboflow.
Cite this Post
Use the following entry to cite this post in your research:
Sachin Agarwal. (Apr 3, 2024). Deploy and Monitor Computer Vision Models in Any Cloud with Roboflow and SkyPilot. Roboflow Blog: https://blog.roboflow.com/deploy-vision-models-skypilot/