
Edge and cloud inference each solve different problems. Edge deployment offers low latency, offline reliability, and greater data privacy, while cloud deployment provides virtually unlimited compute and simpler maintenance. Rather than treating them as competing approaches, many production systems combine both, using edge devices for real-time decisions and the cloud for heavier analysis. Roboflow supports this flexibility by allowing the same model and workflow to run seamlessly across either environment.
Once a computer vision model is trained and validated, deciding how it will run is a major challenge. While model training dominates research papers, inference (the repetitive act of running that model on live production data) is what dictates your system’s latency, operational cost, and long-term maintainability.
You don't have to lock yourself into a single deployment architecture early on. The goal should be to understand how your physical constraints dictate your deployment strategy, and how to build a pipeline that can transition between the cloud and the edge as your project scales.
Edge vs. Cloud Inference
Neither architecture is inherently better. Each is optimized for a different set of constraints, and identifying which constraints matter most for a given application is the real task.
What Is Cloud Inference?
Cloud inference means a trained model lives on a remote server. An application captures an image or video frame, sends it across a network to that server, and receives a prediction once the server finishes its computation. The experience is similar to submitting a homework assignment on Google Classroom and waiting for a graded response to arrive.
What Is Edge Inference?
Edge inference means the model runs directly on the device that captured the data. Examples include a security camera, a factory sensor, a smartphone, or a low-cost board like a Raspberry Pi.
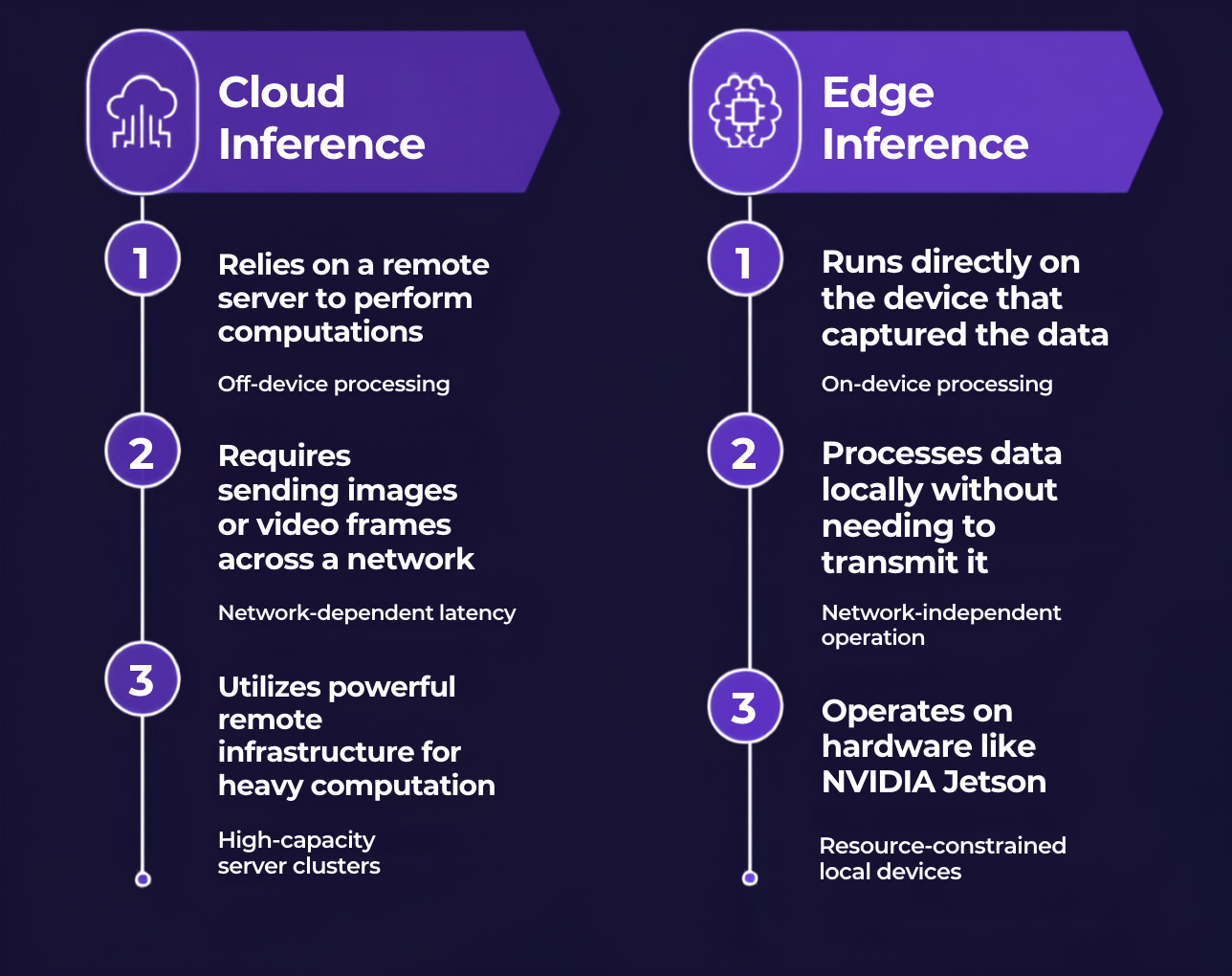
The Trade-Offs That Matter for Edge vs. Cloud Inference
Latency
Latency is usually the primary forcing function. A standard cloud inference round-trip takes between 100ms and 300ms. While that's fine for asynchronous tasks, this delay isn’t practical for real-time robotics or high-speed automation.
However, edge inference eliminates the network hop, processing frames locally as fast as the hardware allows. For example, Fletcher Sports uses Roboflow to power AI camera systems that track fast-moving players at the US Open and Wimbledon.
To adjust a motorized camera smoothly, the system needs to process over 20 frames per second per stream. Waiting on a cloud server means the camera reacts after the ball has already left the frame, which isn’t optimal for high-speed sports.
Hence, the system runs on edge devices at the venue instead, with no dependence on an internet connection and low latency.

Connectivity and Reliability
Cloud inference assumes a stable, fast internet connection. That assumption is okay to keep for typical office work, but it stops companies that operate on an offshore oil platform, a remote farm, or use delivery drones outside a reliable signal range.
Edge devices keep working even when there’s no network connection. This matters most for mission-critical systems or anything operating in an isolated location. BNSF Railway (another Roboflow customer) is a clear example here.
The company uses computer vision to track inventory across its intermodal yards and inspect train wheels in real time, across a rail network spanning 10,000+ miles. Many of those yards are not well-served by reliable broadband, and inspection results need to be available immediately instead of after a delayed upload.
Running inference locally at each yard rather than routing every frame back to a central server, keeps the system working regardless of any connectivity issues.

Compute Power
Cloud infrastructure offers serious computational resources, including GPUs and TPUs, that fifty-dollar edge devices cannot fit due to their physical and thermal limits. These resources allow efficient models like SAM 3, Florence-2, VLMs, LLMs to be run.
Roboflow's Dedicated Deployments (under the enterprise plan) provide single-tenant GPU instances specifically so teams can run these heavier models in production without needing specialized hardware on-site.
When a model is large, complex, or needs to process high-resolution video at scale, cloud computing's raw power is hard to match. However, edge hardware has also improved a great deal, and Roboflow's AI1 as well as boards like the NVIDIA Jetson are quite capable. Even so, there are real physical limits to what fits inside a device small enough to hold in one hand.
Cost Structure
Cloud inference is usually priced by consumption, so costs rise with the number of requests processed. Edge inference shifts most of that cost to an upfront hardware purchase instead. Here's what that looks like:
Cloud (priced by consumption):
- Core plan: $79/month billed annually, includes 50 credits/month (Roboflow Pricing)
- Extra credits: $4/credit prepaid, or $6/credit if billed as flex/overage (Roboflow Credits)
- Serverless Hosted API: ~2.2 credits per 1,000 images when a model has to "cold start" after sitting idle (Serverless API Pricing Docs). When there's steady, high-frequency traffic, this can be avoided, but bursty or low-volume traffic pays it more often.
- Dedicated Deployments: 1 credit/hr (GPU) or 0.25 credit/hr (CPU) (Dedicated Deployments Docs). Thus, a GPU instance running 24/7 for a month (~730 hrs) ≈ 730 credits ≈ $2,900/month, which is why this option is built for predictable, large workloads rather than occasional ones
Edge (priced upfront):
- NVIDIA Jetson Orin Nano Super developer kit: $249 per edge-device (NVIDIA)
- Raspberry Pi 5: $45–$305 depending on RAM (1GB–16GB); prices are currently elevated industry-wide due to a 2025–2026 memory shortage (Raspberry Pi)
- Roboflow's Inference server itself: The core engine codebase is free and open-source under an Apache 2.0 license. However, the core open-source license does not grant commercial rights for dual-licensed models (like YOLOv8 or other AGPL-3.0 structures). A Core plan unlocks commercial rights for models deployed via Roboflow's cloud API, but local edge hardware deployments at production scale require an Enterprise plan to obtain the full self-hosted Inference Model License and multi-device fleet management. (Roboflow Pricing)
- No separate per-inference credit charge once hardware is bought, so the cost of each additional inference is close to zero
The trade-off in short: low or occasional volume tends to be cheaper on the Serverless API, whereas a large or continuously running fleet tends to be cheaper with edge hardware.
Data Privacy and Sovereignty
Some industries, including healthcare, defense, and parts of manufacturing, face strict rules about where data can physically go. If a video frame is legally barred from leaving a facility, cloud inference can’t be used by default. In that case, edge inference becomes a requirement.
For enterprise customers with the strictest requirements, Roboflow also supports air-gapped deployment, where the inference server runs entirely offline, as well as deployment inside a customer's own virtual private cloud or on-premises servers, so sensitive footage never has to cross a public network.
Maintenance
Cloud deployments are centralized. An updated model can be deployed once and applied immediately to every new request. Edge deployments are decentralized instead, so updating a model across an entire fleet means pushing that update to potentially hundreds or thousands of individual devices. This operational burden is easy to underestimate during early planning.
Use Both Edge and Cloud Inference with Roboflow
The choice between edge and cloud shouldn't require maintaining two completely separate codebases or processing pipelines. Roboflow is architected so that a single trained model and its accompanying workflow logic can deploy seamlessly to either environment.
- In the Cloud: Roboflow provides a hosted, serverless API that manages auto-scaling, GPU provisioning, and workload allocation automatically. For predictable enterprise workloads, teams can pin models to Dedicated Deployments (single-tenant GPU instances) or run large-scale batch processing jobs on historical data.
- At the Edge: Roboflow distributes a containerized, open-source inference server. Whether it is deployed on a heavy on-premises server, an NVIDIA Jetson board, or Roboflow's AI1, the underlying API structure remains identical.
Because the API endpoints and workflow schemas are identical across both targets, you can prototype an application using the hosted cloud API today, and then point that exact same logic at an edge device for production tomorrow. This eliminates the behavioral mismatches that frequently derail computer vision projects during field deployment.
The Hybrid Approach
The most mature production systems rarely choose one architecture exclusively. Instead, they combine them. A standard hybrid architecture splits the workload:
- The Edge Layer: Handles high-speed, lightweight tasks like detecting a target object, cropping the region of interest, and discarding empty frames locally.
- The Cloud Layer: Receives the optimized, pre-processed images to run heavier analytical tasks, manage edge cases, and log data into a continuous retraining pipeline.
A practical example of this is FloVision, an automated food analytics platform. Depending on the specific layout of a processing facility, they run their quality and yield-tracking models either locally on the line or via the cloud. Where instant feedback is required to stop a conveyor belt, the edge handles the workload. Where bandwidth allows, and deep analytical tracking is the priority, the data is routed back to the cloud.
Criteria for Selecting an Approach
| If your project requires... | Favor this architecture |
|---|---|
| Millisecond-level response times for automation | Edge |
| Operation in remote areas or offline environments | Edge |
| Strict data compliance (data cannot leave the facility) | Edge |
| Running heavy architectures (VLMs, large foundation models) | Cloud |
| Rapid prototyping and maximum iteration speed | Cloud |
| Both low-latency actions and deep downstream analysis | Hybrid |
Edge vs Cloud Inference Conclusion
Edge inference and cloud inference sit on the same continuum, and most mature computer vision deployments draw on both. The best strategy is not to commit to one architecture early, but to pick a platform where switching between them, or combining them, does not mean starting over. That is the practical advantage Roboflow offers: one trained model and one set of workflow definitions, deployable wherever the use case actually demands it.
Cite this Post
Use the following entry to cite this post in your research:
Aarnav Shah. (May 6, 2026). Edge vs. Cloud Inference with Roboflow. Roboflow Blog: https://blog.roboflow.com/edge-vs-cloud-inference/