
Teaching a computer to see starts with choosing the right level of visual understanding. Image classification provides the big picture: what’s in the image overall, for example: Is there a bird or not? Object detection adds location, showing where within the image each bird is located by drawing bounding boxes around them. And image segmentation goes all the way down to the pixel level, labeling every region to create a complete, detailed map of what the model sees, creating a mask on each entire bird's body.
In this article, we will explore image segmentation in depth. You'll learn about different types of image segmentation, we'll discuss traditional and modern segmentation methods, and we'll review key performance metrics.
What Is Image Segmentation?
Image segmentation draws precise boundaries, giving your model pixel-perfect understanding of what’s in your image. For example, imagine you’re analyzing a photo of a road. With image segmentation, you can identify all the pixels that exactly align to the road. Instead of a single label, you'll get a detailed map showing the exact shape, boundaries, and location of the road within your image.

Image Segmentation vs. Classification vs. Detection
Image segmentation, along with classification and detection, are common approaches used to understand and represent the contents of visual data. Here's how they differ.
1. Image Classification
Classification is the simplest form of computer vision. It predicts the overall category of an image like choosing between “cat” or “dog.” But it can’t tell you where those objects are. If both a dog and a cat appear in the same photo, a standard classifier will usually pick just one, since it assigns a single label per image. While a multi-label image classification model would label the image as both "cat" and "dog."
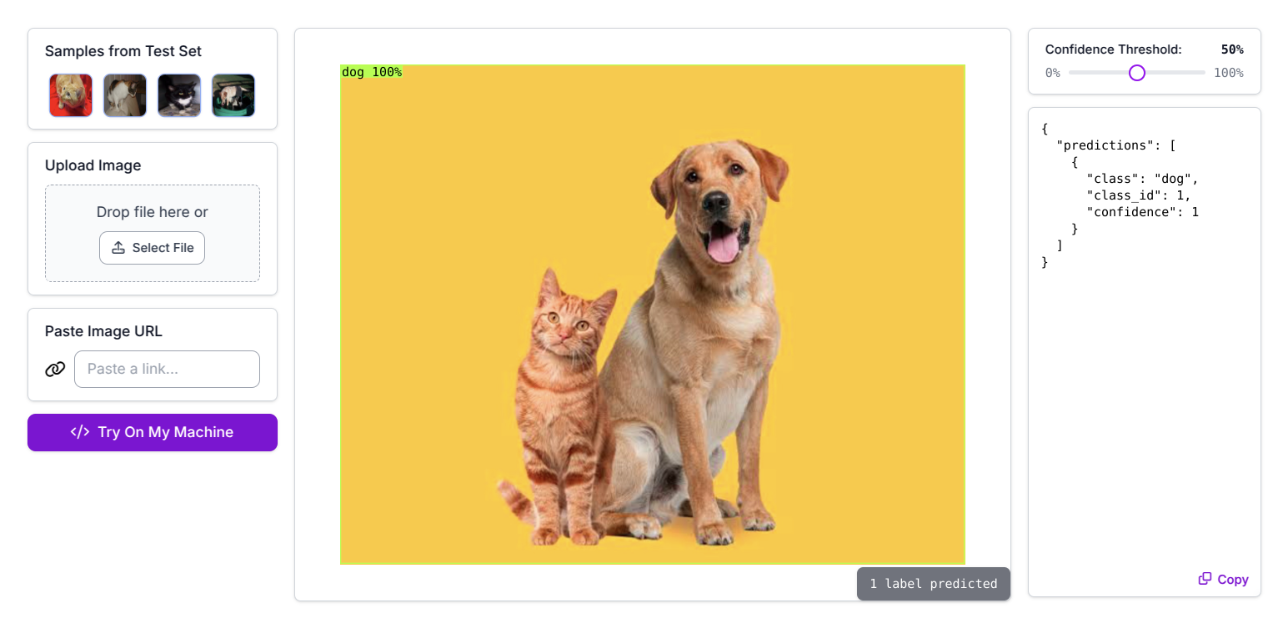
2. Object Detection
Object detection not only classifies the objects in an image, but also shows where they are by drawing bounding boxes around each detected object. While detection solves the localization problem, the bounding boxes it produces only roughly estimate an object’s position and shape.

3. Image Segmentation
Segmentation provides a much more detailed and pixel-level localization of objects. Instead of bounding boxes, it creates masks that outline the exact pixels taken up by each object. This makes segmentation especially useful in tasks that require fine-grained spatial understanding, such as self-driving cars, where the system must not only detect that a road exists but also identify the precise path and boundaries of the road to stay on it.

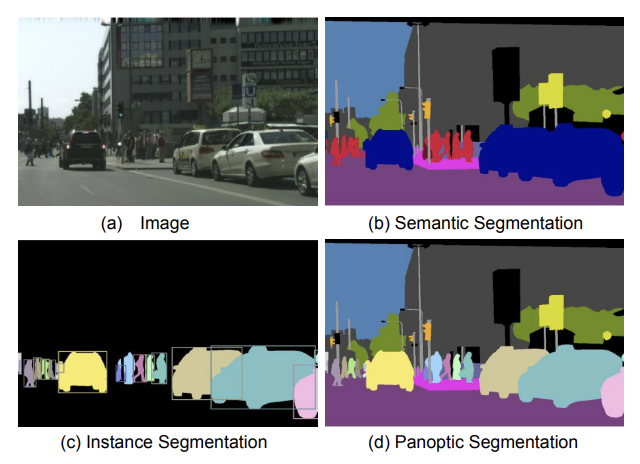
Types of Image Segmentation: Semantic vs Instance vs Panoptic
Image segmentation can be broadly divided into three main categories: semantic segmentation, instance segmentation, and panoptic segmentation.
Semantic Segmentation
Semantic segmentation classifies every pixel in an image by what it represents: road, sky, car, person, without distinguishing between individual instances.
If you have a photo with four cars, all car pixels share the same label: car. The model understands what is in the image, but not which specific object is which. This makes semantic segmentation perfect for tasks like surface analysis, land cover mapping, or material classification, where identifying categories matters more than tracking individual objects.
Instance Segmentation
Instance segmentation takes it a step further. This task not only identifies object classes, but also distinguishes between separate instances of the same class. So instead of labeling all four cars as a single car segment, each car in the image gets its own unique mask with labels such as "car 1", "car 2", etc. This allows the model to differentiate between multiple objects that belong to the same category.
Panoptic Segmentation
Panoptic segmentation combines both semantic and instance segmentation into a unified approach. It assigns unique masks to individual object instances (like people or cars) while also labeling background regions (like sky, road, or grass) as single segments since these don’t have multiple instances. This provides a complete understanding of the scene, capturing both the unique objects and the overall structure of the environment.
Traditional Segmentation Techniques
Before deep learning became the default for segmentation, several traditional methods were used to separate regions in an image based on color, intensity, or texture. These techniques are still very useful today, especially when you don’t need the full weight of a neural network.
Thresholding
Thresholding is one of the simplest segmentation techniques. It separates an image into foreground and background by dividing pixels based on their intensity values. This makes it useful when there is a clear difference between the object and its background, such as black text on a white page.

Color-Space Segmentation
Color-based segmentation groups pixels that share similar color values. By focusing on color rather than brightness, this technique works well when different objects in an image can be distinguished by their color, such as separating fruits of different colors in a photo.

Edge Detection
Edge-based segmentation identifies object boundaries by detecting sharp changes in pixel intensity. It highlights the outlines of shapes within the image, making it useful for identifying distinct objects or structural details like the edges of buildings, roads, or leaves.

Watershed Segmentation
Watershed segmentation treats the image like a landscape of hills and valleys. It “floods” the image from low-lying regions, and where two floods meet, it marks a boundary. This helps separate objects that touch or overlap, such as coins or cells in a microscopic image.

Pros and Cons of Traditional Segmentation Techniques
These methods are fast and lightweight. However, they are highly sensitive to lighting changes, shadows, and texture variations.
Because of that, they often serve as preprocessing or post-processing steps for deep learning models rather than full solutions.
They also have the advantage of not requiring any labeled training data, which makes them ideal for quick experimentation or analysis in controlled settings.
Deep Learning for Segmentation
Deep learning changed segmentation forever. Instead of relying on hand-tuned filters or edge detectors, modern models learn to label every pixel directly from data, capturing shapes, boundaries, and context far better than any rule-based system. A few core segmentation model families have emerged, each built for specific levels of detail and real-world performance.
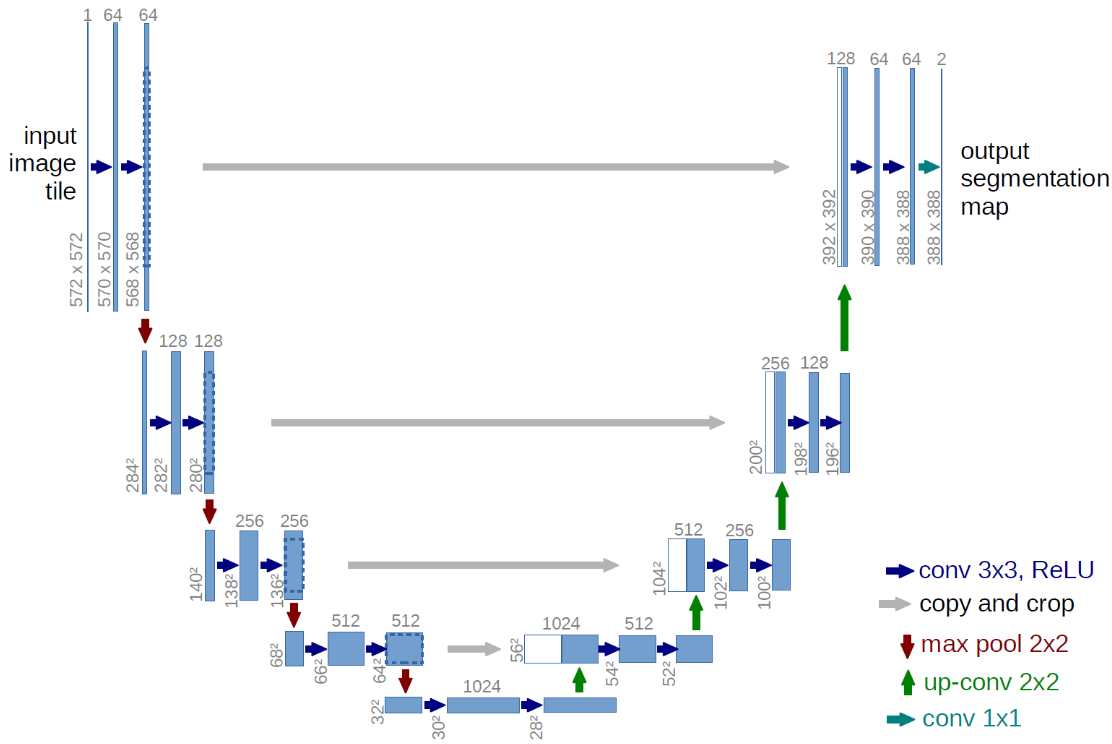
Semantic Segmentation Models
The most widely used models in this category are based on the U-Net architecture and its many variants. U-Net introduced the encoder–decoder structure with skip connections, allowing models to capture both global context and fine-grained details. Modern versions improve on this with attention modules, transformer backbones, and better feature fusion techniques.
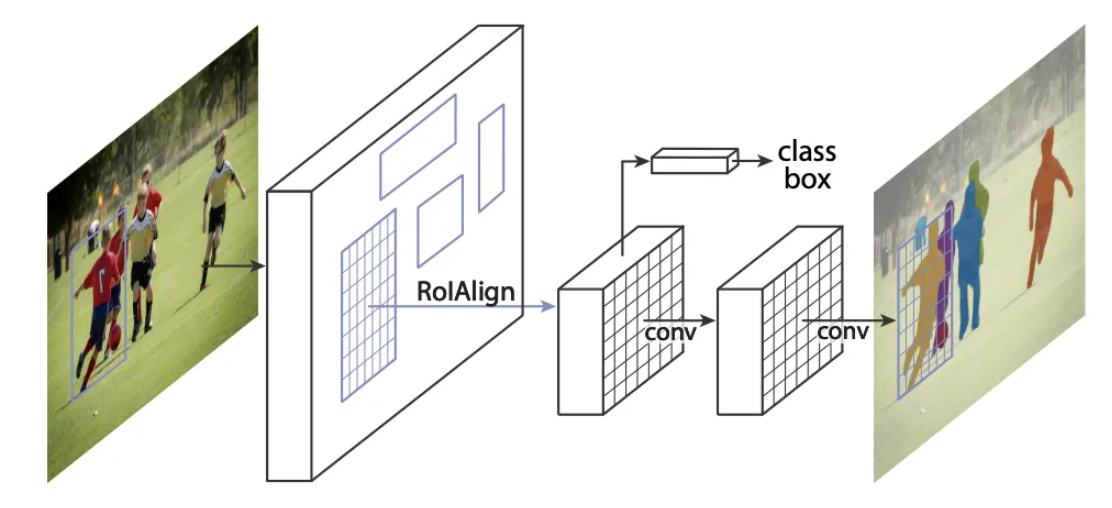
Instance Segmentation Models
Instance segmentation models are designed to separate individual objects of the same class. A common example is Mask R-CNN, which extends object detection pipelines by adding a mask prediction branch that produces pixel-level masks for each detected instance.
Panoptic Segmentation Models
Panoptic models unify semantic and instance segmentation within one network. They are typically trained on large-scale datasets like COCO-Panoptic and Cityscapes, which provide both “thing” and “stuff” annotations. Recent architectures merge detection and segmentation heads to produce consistent, scene-wide pixel labeling.
Interactive and Prompt-Based Segmentation
Newer approaches, such as the Segment Anything Model (SAM) and vision-language models like PaliGemma, have made segmentation far more flexible. Instead of retraining for every new dataset, these models can take human guidance through clicks, sketches, or text prompts. This allows users to adapt segmentation to new categories or tasks instantly, bridging the gap between visual understanding and natural language interaction.

How to Choose a Segmentation Model
When it comes to segmentation, most models force a tradeoff: accuracy or speed. But with RF-DETR Seg, you get both. Built as an evolution of Roboflow’s detection transformer, RF-DETR Seg unifies object detection and pixel-level segmentation in one efficient model.
Where older models such as U-Net or Mask R-CNN separate detection and mask prediction, RF-DETR Seg does both at once, producing sharper, faster, and more consistent results. So you can train, test, and deploy RF-DETR Seg in Roboflow, and get state-of-the-art accuracy and latency right out of the box.

Build Image Segmentation Masks in Roboflow
Building a segmentation model typically follows three main stages: data curation, model training, and inference. Roboflow streamlines the whole process, helping you go from raw images to a production-ready segmentation pipeline in just a few steps.
Step 1: Annotate Your Data
Start by labeling your images in Roboflow Annotate. Use Smart Polygon to outline objects with precision and create pixel-level segmentation masks. You can also accelerate the process with Label Assist, which uses AI to auto-generate masks that you can review and refine.
Step 2: Train Your Model
Once your dataset is annotated, train a segmentation model directly in Roboflow. Choose from models like RF-DETR Seg, YOLOv11-Seg, or SAM 2, and monitor training progress in real time with interactive metrics and visual validation tools.
Step 3: Deploy and Visualize with Workflows
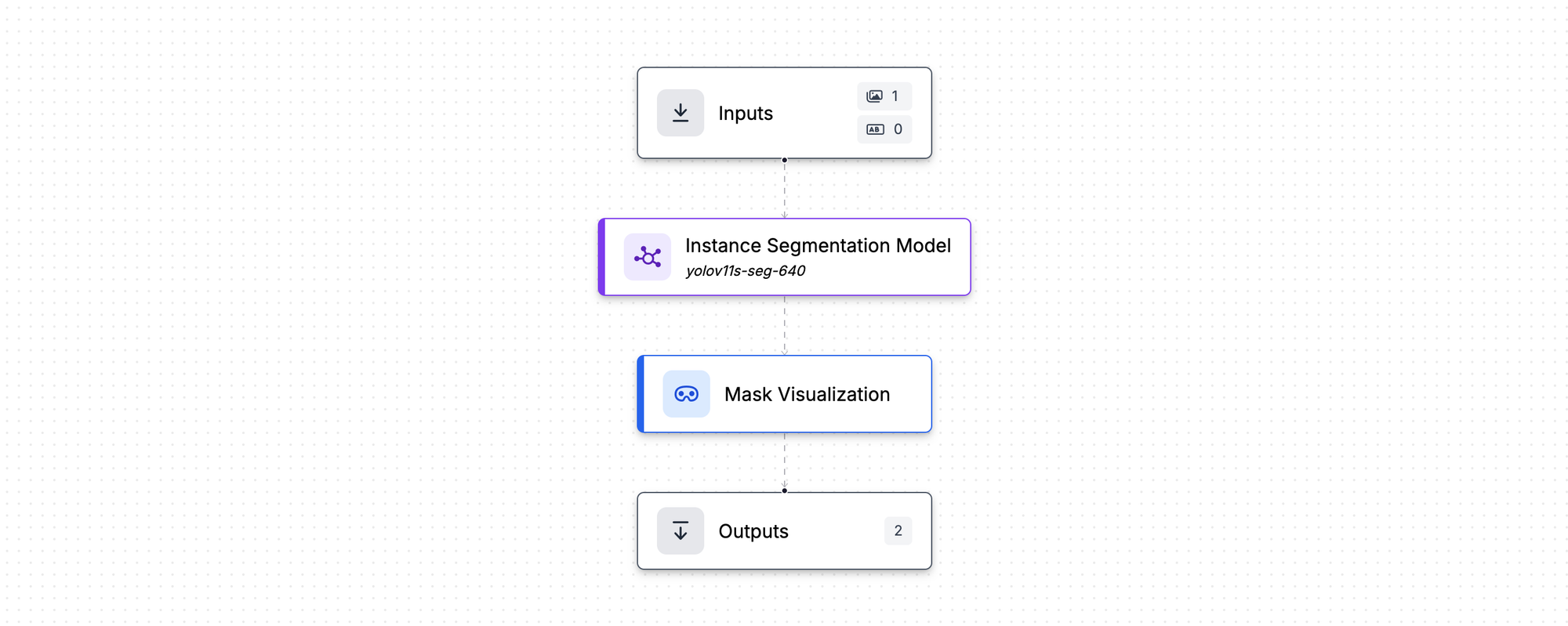
After training, integrate your model into a Roboflow Workflow to build a complete, automated segmentation pipeline. A typical segmentation workflow includes:
- Input Block: Receives images or video frames for segmentation.
- Segmentation Model Block: Runs your trained segmentation model.
- Visualization Block: Renders segmentation masks for review or monitoring.
- Output Block: Sends results to an endpoint, dashboard, or control system.
When you create a new Workflow, it comes pre-configured with Input and Output blocks. Simply add your Segmentation Model Block and a Mask Visualization Block to see your model’s predictions live.
With just a few clicks, you’ll have a fully functional segmentation workflow that detects, labels, and visualizes regions in real time—ready for production or edge deployment. Explore the example segmentation workflow in Roboflow.
Real-World Use Cases for Image Segmentation
Image segmentation makes many real-world systems intelligent. By identifying every pixel in an image, segmentation brings precision to tasks where simple detection isn’t enough.
Manufacturing Quality Control
On production lines, segmentation highlights defects such as scratches, cracks, or missing parts that object detection alone might miss. Automated inspection systems can act instantly, reducing human error and catching flaws before they leave the factory floor.
Medical Imaging
In healthcare, segmentation enables models to isolate organs, tumors, and tissues for analysis. Whether identifying lung boundaries in a CT scan or measuring lesion changes over time, segmentation provides the granularity clinicians need for accurate, data-driven diagnostics.
Agriculture and Crop Monitoring
In precision agriculture, segmentation turns aerial and drone imagery into insights. It distinguishes crops from weeds, tracks growth, and maps field health, helping farmers optimize yield and resource use.
Autonomous Vehicles and Robotics
Robots and autonomous systems rely on segmentation to understand their environments in real time. By separating roads, vehicles, pedestrians, and obstacles pixel by pixel, segmentation provides the spatial awareness needed for decision-making and safe driving.
Geospatial and Environmental Mapping
From tracking deforestation to mapping urban expansion, segmentation converts satellite imagery into structured environmental data. For example, learn more about using computer vision with drones.
Image Segmentation Conclusion
When you’re ready to bring segmentation to your own projects, RF-DETR Seg is a great place to start. It combines high accuracy with exceptional speed, setting a new benchmark for real-time image segmentation. Try it here.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Nov 12, 2025). What Is Image Segmentation?. Roboflow Blog: https://blog.roboflow.com/image-segmentation/