
Roboflow Inference enables you to deploy fine-tuned and foundation models for use in computer vision projects. Inference works across a range of devices and architectures, from x86 CPUs to ARM devices like a Raspberry Pi to NVIDIA GPUs.
Roboflow now offers an Inference command-line tool with which you can use the Roboflow Inference Server to infer on your images locally through the CLI. In just a few commands you can test and deploy your Roboflow model in your production environment.
For full documentation on the CLI, see the CLI reference documentation.
The CLI is part of the open source Roboflow Inference Server repository and is available to install as a standalone pip package, or bundled with the inference package version `0.9.1` or higher.
Why use the CLI?
The Inference CLI is a great way to get an inference server up and running without having to worry about your Docker/device configuration or write a script. You can use it to test your model on your local machine or integrate the server with any tools or services that can execute terminal commands.
Additionally, the CLI will take care of manual tasks like pulling the latest Docker image and restarting the server, making it easier to keep your inference server up to date.
Two CLI use cases that we'll explore in this guide:
- Test your model on your local machine, comparing it to the results from the hosted inference server.
- Start a cron job that starts a new inference server and runs inference on local images.
pip install inference-cli
Inference lets you easily get predictions from computer vision models through a simple, standardized interface.
The CLI works with the same variety of model architectures for tasks like object detection, instance segmentation, single-label classification, and multi-label classification and works seamlessly with custom models you’ve trained and/or deployed with Roboflow, along with the tens of thousands of fine-tuned models shared by our community.
In order to install the CLI, you will need to have Python 3.7 or higher installed on your machine. To check your Python version, run `python --version` in your terminal. If you don’t have Python installed, you can download the latest version on the Python website.
To install the package, run:
pip install inference-cliBasic usage
The Roboflow CLI provides a simple and intuitive way to interact with the Roboflow Inference Server. Here are some basic usage examples to get you started. For more information on the available commands and options, see the [CLI documentation](https://inference.roboflow.com/#cli).
Starting the Inference Server
Before you begin, ensure that you have Docker installed on your machine. Docker provides a containerized environment,
allowing the Roboflow Inference Server to run in a consistent and isolated manner. If you haven't installed Docker yet, you can get learn how to install Docker from their website
To start the local inference server, run the following command:
inference server startThis will start the inference server on port 9001. If there is already a container running on that port, the CLI will prompt you to stop it and start a new one.
This command will automatically detect whether your device has an Nvidia GPU, and pull the appropriate Docker image.
Running Inference
To run inference you will need your Roboflow project ID, model version number, and api key. Refer to our documentation on how to retrieve your workspace and project IDs and how to find your Roboflow API key.
To run inference on an image using the local inference server, run the following command:
inference infer /path/to/image.jpg --project-id your-project --model-version 1 --api-key your-api-keyThis command makes an http request to the inference server running on your machine, which returns the inference results in the terminal.
You can supply a path to your local image, or a url to a hosted image.
Use Case #1: Compare inference on your device with Roboflow Hosted API
For this example, we'll use a wildfire smoke detection model hosted on Roboflow Universe.
First start a local inference server with inference server start.
Then, open up the Universe page and scroll down to the code snippets section and select "On Device".
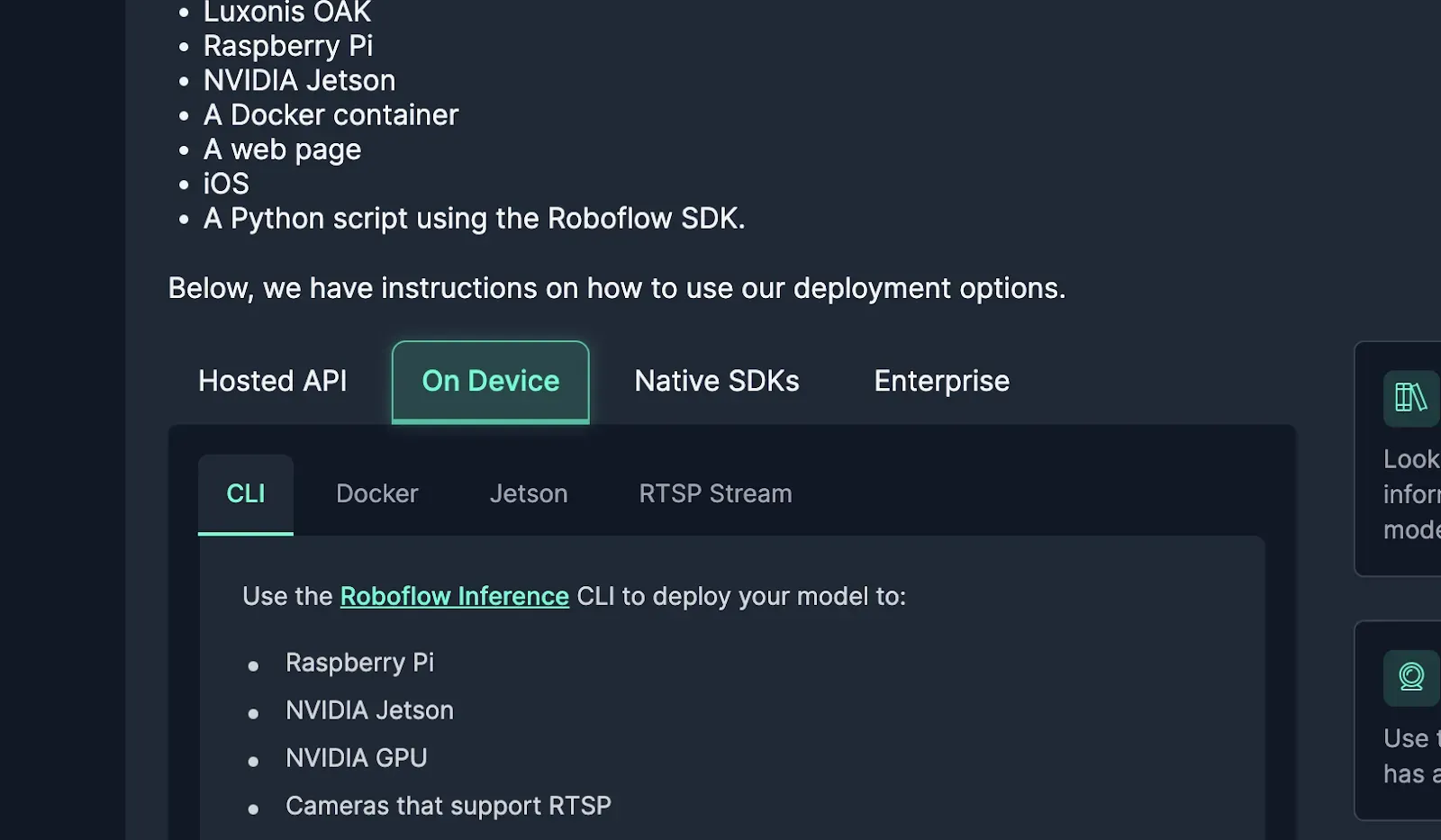
Scroll down to “Run inference on an image”, and copy the bash command.
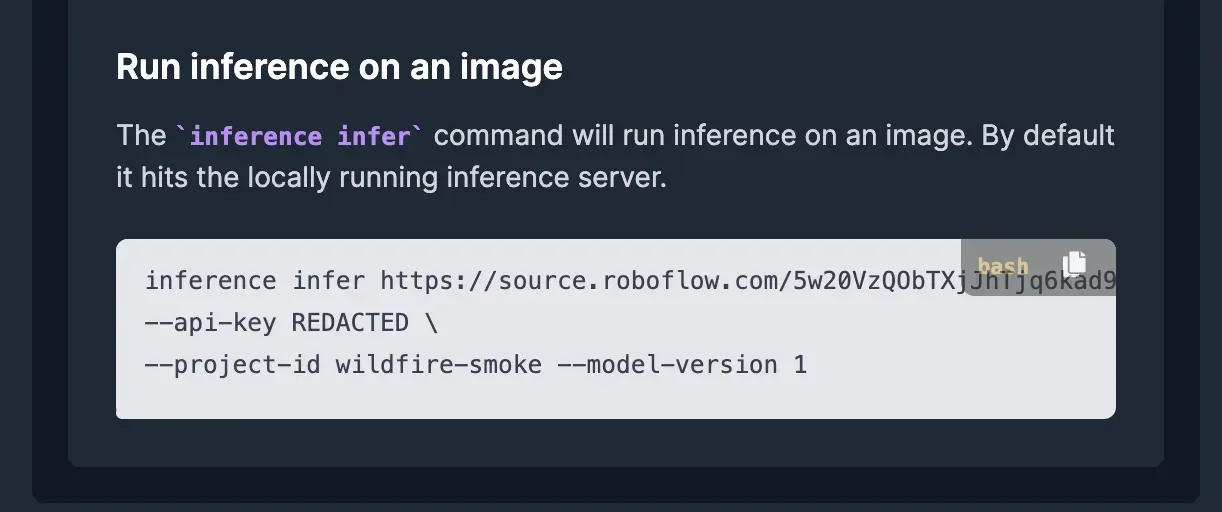
Open your terminal, and run the copied command, you should see a JSON output printed to the console, with a predictions array.
Scroll up to the top of the page, and paste the image URL from the command here, to compare your local predictions with the Roboflow Hosted API.
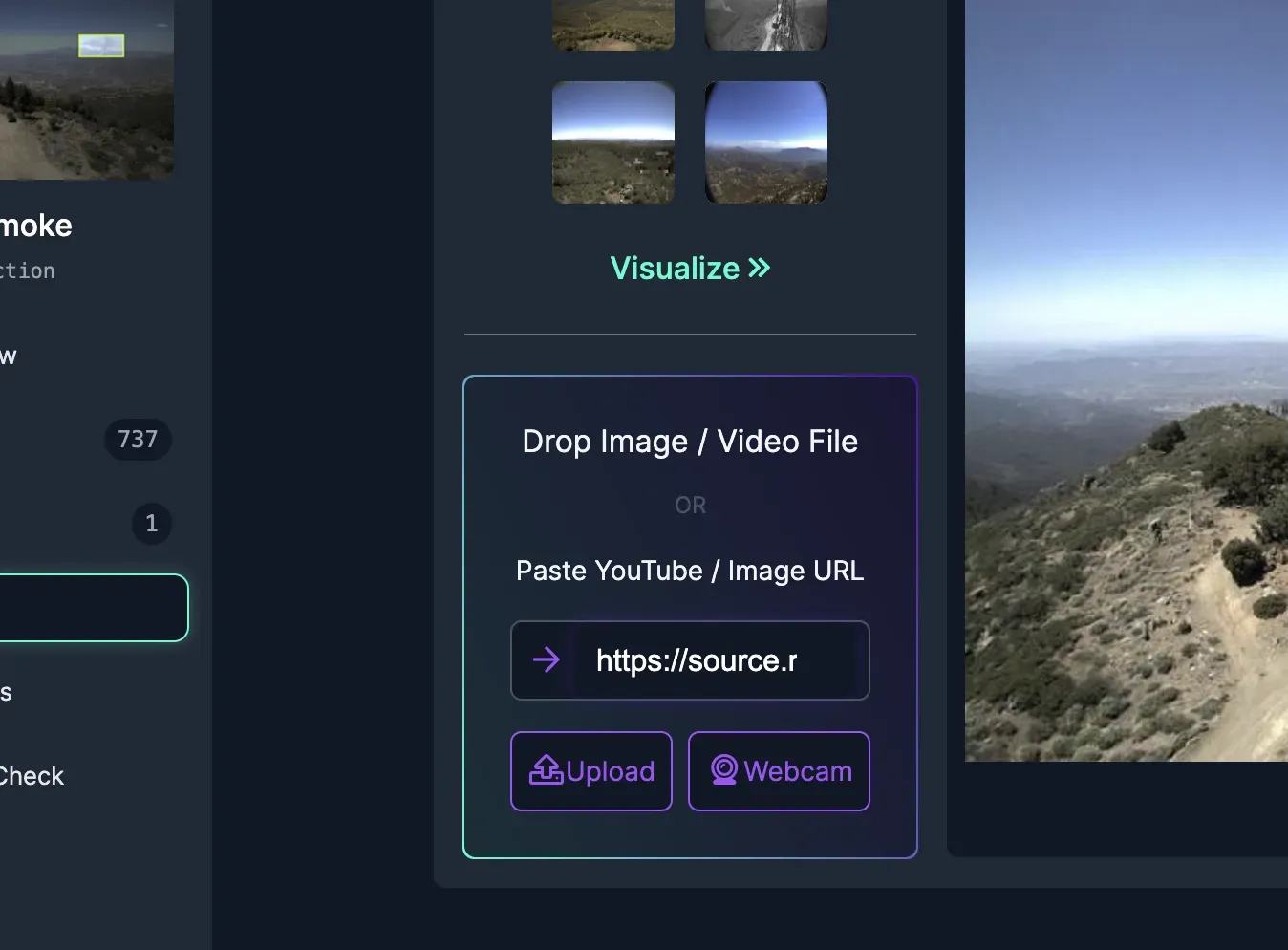
After hitting the arrow (or pressing Enter), you can compare the output predictions with the ones from your terminal.
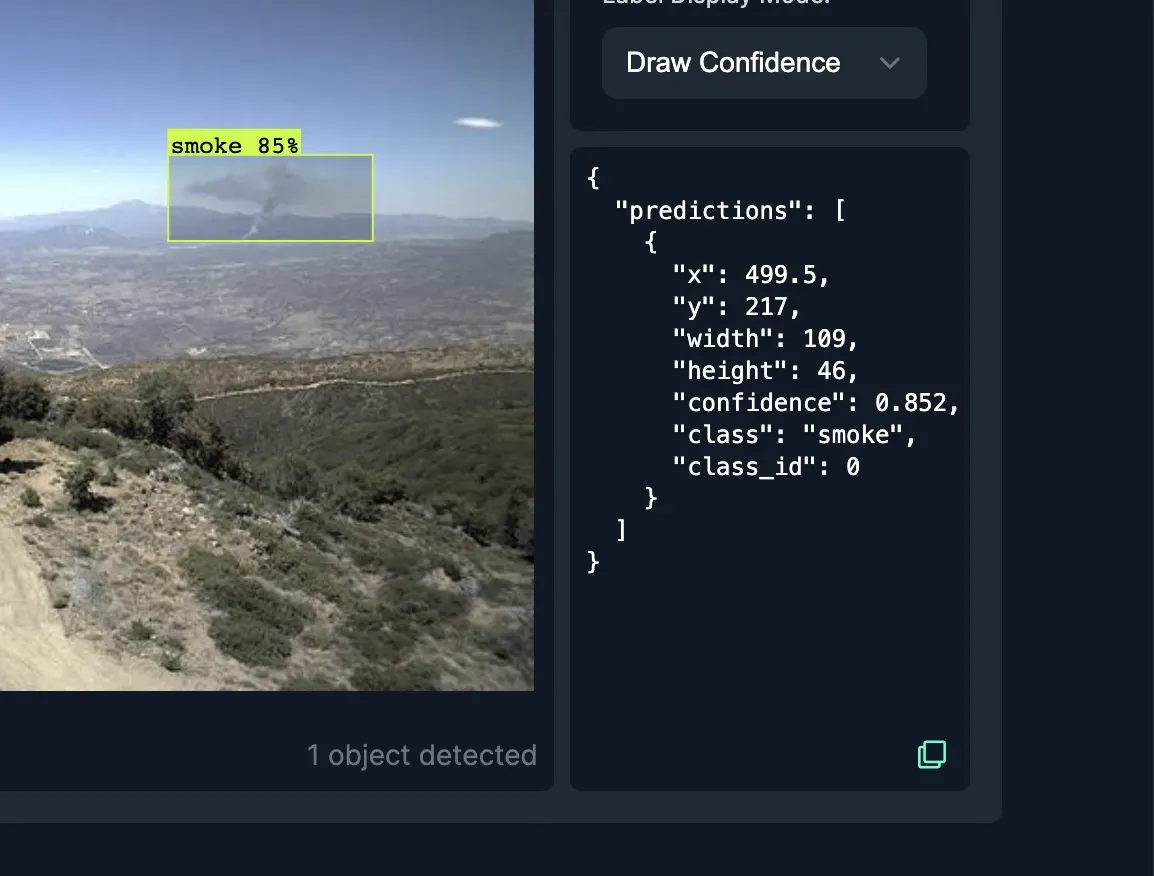
The predictions should be similar, but results can vary slightly based on inference server version and device hardware.
The CLI can also query the same API as the web view, using the –host option. Add the following line to your infer command --host https://detect.roboflow.com.
Your command should now look similar to this, but with your API key instead of “API_KEY”:
inference infer https://source.roboflow.com/5w20VzQObTXjJhTjq6kad9ubrm33/ZOPyGOffmPEdoSyStK7C/original.jpg \
--api-key API_KEY \
--project-id wildfire-smoke --model-version 1 --host https://detect.roboflow.comThe results should now look exactly the same as the ones on Roboflow Universe, as inference is being run on the same version and hardware on our remote servers.
Now you can take these steps to test out your Roboflow models on your local device!
Use case 2 (Unix only): Bash script can be run once a day
You can use the CLI to integrate with your existing bash pipelines. To demonstrate this, we will set up a cron job on your machine that runs this script once a day.
Here's an example of a script that starts a new inference server (with the latest version) and runs inference on local images, saving results to an output file.
#!/bin/bash
# Directory containing input images
IMAGES_DIR="/path/to/images"
# List of input images
IMAGES=("$IMAGES_DIR"/*.jpg)
# Start inference server
inference server start
# Wait for inference server to start
echo "Waiting for inference server to start..."
sleep 3
inference server status
# Output file for inference results
OUTPUT_FILE="inference_results.txt"
# Run inference for each image
for IMAGE in "${IMAGES[@]}"; do
echo "Running inference for $IMAGE..."
inference infer "$IMAGE" \
--api-key REDACTED \
--project-id wildfire-smoke --model-version 1 \
>> "$OUTPUT_FILE"
done
echo "Inference results written to $OUTPUT_FILE"You will need to replace the IMAGES_DIR with a path to a folder containing images, and update the API key to use yours, instead of REDACTED.
Save this script to a file, such as run_inference.sh. Make the script executable by running the following command:
chmod +x run_inference.shOpen your crontab file by running the following command:
crontab -eFinally, paste the following line to the crontab file to run the script once a day:
0 9 * * * /path/to/run_inference.shThis will run the inference.sh script once a day at 9AM. Replace path/to/run_inference.sh with the full system path to your .sh file.
Next, save and close the crontab file (by default using vim controls, type :wq, and hit Enter).
With these steps, you should now have a cron job set up to run inference on local images once a day. You can modify the script and the cron job schedule to suit your needs.
Conclusion
The Inference CLI can be used to easily get Roboflow Inference up and running. Use simple commands to test your model locally, or integrate with other command-line programs.
The CLI will continue to be updated with the latest Inference Server features as they are added in the coming months. Find the latest commands in the CLI reference documentation. You can contribute to the CLI directly by submitting an Issue or Pull Request in the Inference GitHub repository.
Cite this Post
Use the following entry to cite this post in your research:
Lake Giffen-Hunter. (Oct 16, 2023). Launch: Roboflow Inference Server CLI. Roboflow Blog: https://blog.roboflow.com/inference-cli/