
A University of Glasgow study used computer vision to measure litter density across city streets and then tested whether that density correlated with socio-economic deprivation indicators like employment rate, income, and education level. Researcher Gary Blackwood collected Google Street View images as a scalable substitute for field surveys, trained an object detection model to count litter instances per frame, and applied statistical analysis to find meaningful correlations. The methodology, including data collection from public mapping APIs, model training, and correlation analysis, is reproducible for other cities with their own annotated datasets.
In 2021, Gary Blackwood, a postgraduate student at the University of Glasgow, created a study to identify whether there were correlations between the amounts of litter in a region of a city and socio-economic factors. This exploratory study was aimed at identifying factors that influence litter beyond the location of trash cans, providing key evidence that policymakers could use to better understand the causes of litter in urban areas.
To perform this study, Gary used computer vision to count litter in regions around the city of Glasgow, Scotland, and used statistical analysis techniques to identify correlations between local socio-economic data and littering. In this article, we are going to discuss the findings from Gary’s published paper and how computer vision helped advance his research study.
The source code and paper associated with Gary’s project is available on GitHub.
Studying links between litter and deprivation
In May 2022, Gary published “Regressing Litter on Deprivation in Glasgow City with Object Detection”, an analysis of the extent to which factors associated with deprivation – employment rate, income rate, the percentage of people with no qualifications in an area – were linked with litter. To work on this paper, Gary faced a big problem: how to gather enough data on littering to explore any potential correlations.
Gary decided to use an object detection model powered by computer vision to identify pieces of litter in an image. An object detection model could be trained to identify various different pieces of trash and run at scale on as many images as Gary could collect. With this approach, Gary could build his own primary source of data on which to rely for his study.
To collect data for the project, Gary used an API provided by Google Maps through which one can access images of Google Street View. Google Maps provided a large and robust data source of images collected from across the streets of Glasgow. This eliminated the need for days or weeks of field work to gather enough data to create the project.
Each image could be run through the object detection model that Gary planned to build to identify all of the pieces of litter in the image. Then, using this data, Gary could study correlations between government socio-economic data and the amount of litter studied in each region.
Preparing data for the model
With a hypothesis in mind and a robust, reliable data source in place, Gary began work on building a computer vision model. The first step to building the model, after having a clearly defined problem in mind, was to prepare data that could be used to train the model.
Gary collected 7,260 images from Google Street View and annotated them by hand. Bounding boxes were drawn around each piece of litter found in images. This was the most time consuming part of the project, but an essential step to ensure Gary’s model would be as accurate as possible when used to draw conclusions. Images were selected from regions across the Glasgow City area as Glasgow is a massive area. Having a narrow scope in terms of location let Gary focus his efforts when annotating.
After annotating images, Gary found that one in six images contained litter. Determining the type of litter in an image was difficult due to the low resolution of images that would be fed into the model (and the relative size of litter compared to the rest of the image). As a result, Gary used the class “litter” rather than having sub-classes for different types of litter (i.e. bottles, plastic).
Here is an example of an annotated image from the dataset:

With all of his images annotated, Gary turned to Roboflow to prepare data for his model. Using Roboflow, Gary split his images into training, test, and validation sets that he could use after choosing an architecture for his model and commencing the training process. The data used in this split was narrowed down from the original 7,260 images to include a larger proportion of images that included litter to optimize the training process.
In addition, Gary used Roboflow to pre-process his data to ensure all images that would later be used in his model were the same. He decided to use Roboflow’s null filter and contrast steps.
Then, Gary applied image augmentation across his training set. This was used to increase the number of images from which the model could learn. Using Roboflow’s data augmentation tool, Gary could generate thousands more images to boost his model’s ability to identify litter in an image. He tried various different augmentations and settled on mosaic – taking random crops of various images and merging them into one image – and noise augmentations.
Here is an example of an image after augmentations were applied:

The result of Gary’s data annotation work is available publicly on Roboflow Universe.
Training a computer vision model
With his data prepared, Gary then began work on training his object detection model to identify pieces of litter in an image. Two options were considered: YOLO and R-CNN, both common options for object detections. After extensive evaluation, YOLO was selected as the model to use for the project as it was found to achieve a higher rate of accuracy on Gary’s problem. Specifically, a YOLOv5s model was used.
Gary trained his computer vision model outside of Roboflow by taking advantage of our data export features. This was essential because Gary wanted to get hands on with computer vision code while working on his project. Gary reported the following results after training his YOLO model:
A YOLOv5s litter detection model that had been trained using mosaic and noise augmented image data was chosen as the final model as it produced the best mean average precision of 58.2. It was found that it may generalise well to new data as it produced a true positive rate of 77% on an unseen test data set containing 254 littered objects, with only 28 false positives. When applied to 37,300 images of Glasgow City it found 7,732 litter objects within 746 data zones using a confidence threshold of 80%.
After selecting YOLO as the best candidate for object detection, Gary trained a model using his data and planned out an exploratory analysis stage to draw conclusions based on the results of his model. Gary ran his model against images that he divided by location, allowing him to create counts of how much litter was found in different locations. The model was applied to unannotated 37,000 Street View images taken across Glasgow City.
This data was later mapped out onto an interactive web application that provides an intuitive method through which one can explore the data collected by Gary. Here's a screenshot of the landing page of the application:
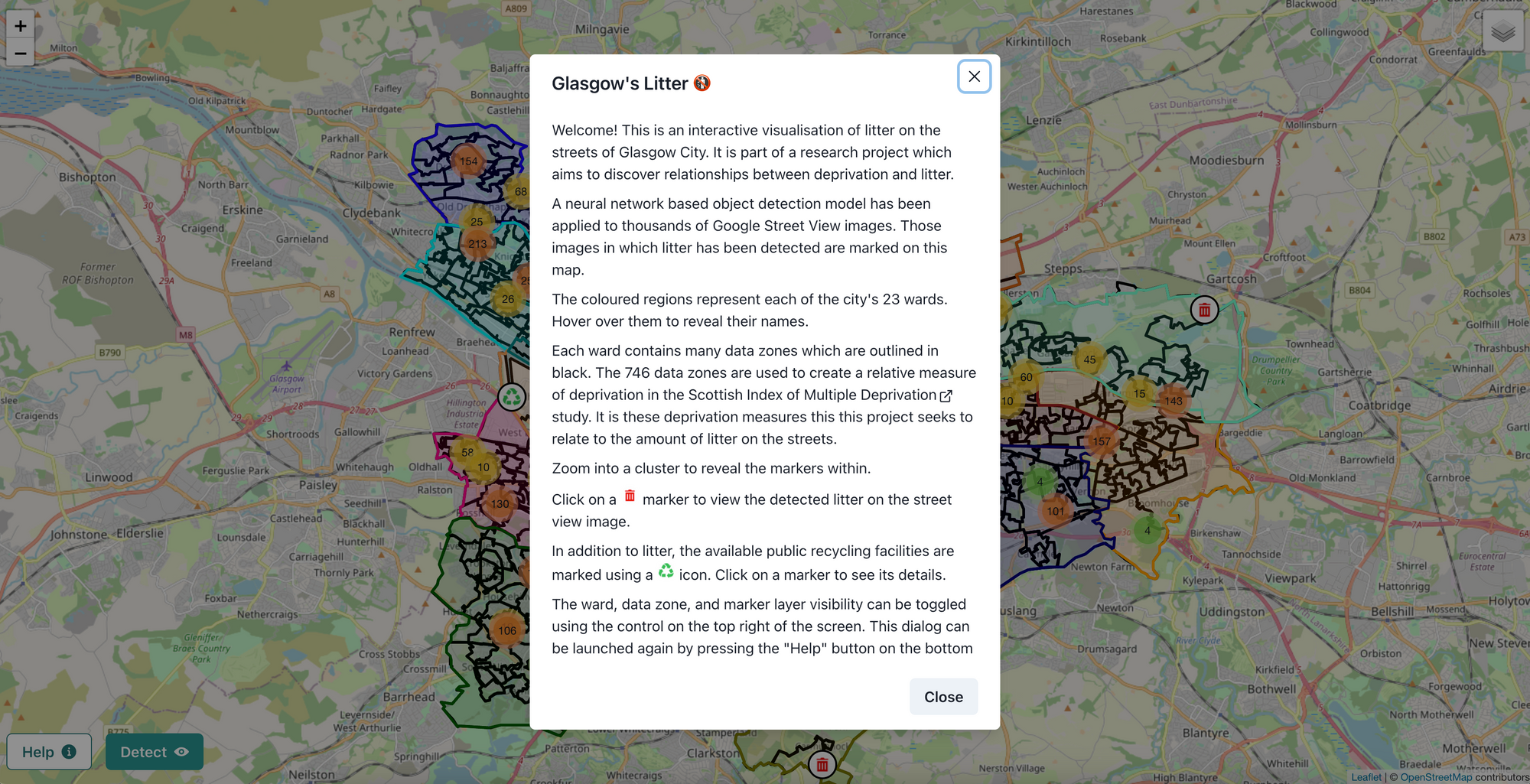
This interactive application also shows the number of public recycling points in each region, of which 741 are present in Glasgow. In his analysis, Gary found there was no correlation between the number of public recycling points and the amount of litter present in each data zone.
Identifying correlations between litter and socio-economic data
Gary used data from the Scottish Index of Multiple Deprivation (SIMD) dataset, described by the Scottish Government as “a relative measure of deprivation across 6,976 small areas”. Each area is referred to as a data zone. Data zones contain information on seven areas:
- Income
- Employment
- Education
- Health
- Access to services
- Crime
- Housing
Gary used Poisson regression and negative binomial regression analyses to explore statistical relationships between factors in the SIMD dataset and rates of litter.
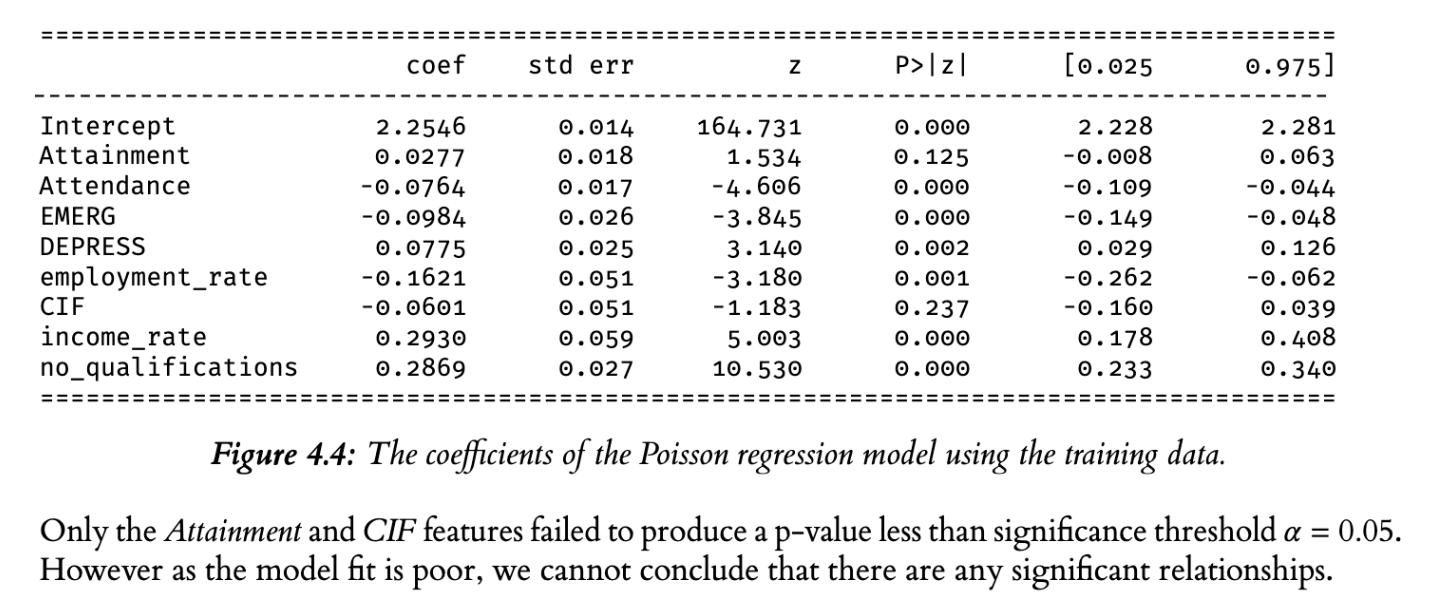
Gary concluded that there was no statistically significant relationship between any of the factors he studied and rates of litter. Gary’s conclusion states:
Only the Attainment and CIF features failed to produce a p-value less than the significance threshold a = 0.05. However as the model fit is poor, we cannot conclude that there are any significant relationships.
With that said, Gary noted that some limitations in his paper – such as the hardware used and the resolution of images – may have prevented more conclusions from being drawn. Additional hardware resources would allow larger models to be developed and tuned for better performance.
Gary found that they produce better results in nearly all cases, but he was limited to smaller models as he used his own personal computer. Furthermore, an input image that is twice as large would require a neural network to learn from four times as many pixels. The additional time needed to learn adds up quickly unless more hardware resources are made available.
Gary learned that counting litter on a city-level – Glasgow is the most populous city in Scotland, with a population of 632,000 in the City area – is feasible. This demonstrates the power of computer vision to tackle image-based problems at large scale. Gary’s study would not have been possible to conduct as a student research project without a model that could identify and count litter in different regions.
Gary concluded that his model could be scaled up to produce more data and used in policymaking. Indeed, the applications of the model go beyond assessing correlations between litter and socio-economic data. Local governments and council trash collection departments in Glasgow could leverage Gary’s model to analyze the relationship between other factors and rates of litter. These could include studying:
- The rate of litter around food establishments versus other areas.
- How emptying bins less or more frequently influences the amount of litter.
Indeed, there are many potential applications of Gary’s model to solve litter problems. Gary notes that the model could be used in other locations in Scotland, although the model should be first tested to see whether adding more annotated images of litter in another location would boost performance. This is important to note because cities and towns are distinct and the model has not yet been tested on other locations in Scotland.
A significantly greater portion of data would need to be added to help the model generalize to other cities such as San Francisco or Berlin because the cities are distinct in many ways from the cities photographed in Gary’s dataset. With that said, the same approach Gary used could be copied for different cities: collect data from Google Maps, annotate instances of litter on a set of images, train a computer vision model to identify litter, then analyze the results.
In sum, Gary’s model shows how computer vision models can be applied to solve real-world problems. In this case, Gary studied links between litter and socio-economic factors, an analysis that has resulted in useful information that can advance initiatives to reduce rates of litter.
If you are interested in training your own computer vision model, check out Roboflow. We have created an end-to-end computer vision platform that can assist you with all of your needs when building a model, from preparing your data to training and deploying multiple versions of your model. We also have an open application for research credits for which you can apply if you plan to use Roboflow in your research or education.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Dec 1, 2022). Studying Links Between Litter and Socio-Economic Factors with Computer Vision. Roboflow Blog: https://blog.roboflow.com/litter-detection-computer-vision/