
Vision Language Models (VLMs) like GPT-5 can handle complex vision tasks such as OCR, VQA, and DocVQA with ease. But some smaller vision language models, like Llama 3.2 Vision, can perform remarkably well on these same tasks while being far more lightweight and efficient.
In this guide, we explore the best local VLMs you can run on your own hardware, from Llama 3.2 Vision to SmolVLM2, and show how to deploy them efficiently with Roboflow Inference.
Best Local Vision-Language Models Criteria
Here are the criteria we used to select these local models.
1. Local-friendly setup
The model should be easy to deploy locally using tools like Ollama or Llama.cpp, without requiring complex server infrastructure or constant internet connectivity. That ensures a smoother setup process if you want to experiment or build offline applications.
2. Capability across vision-language tasks
The model should be able to handle key tasks such as Visual Question Answering (VQA), Optical Character Recognition (OCR), and Document Visual Question Answering (DocVQA), which showcase real-world utility and reasoning over visual inputs.
3. Compact model size
We limited our selection to models with under 20 billion parameters for a balance between performance and efficiency. These smaller models are easier to run on your hardware while still delivering competitive results.
4. Quantization support
Models that support GGUF quantization or similar techniques are preferred, since quantization reduces memory footprint and speeds up inference. This makes local deployment much more practical, especially for users without access to high-end GPUs.
5. Active maintenance and support
Lastly, we considered how well each model is maintained. Actively developed models with strong community backing tend to receive regular updates, optimizations, and compatibility improvements, which are crucial for long-term usability.
To explore top-performing models across computer vision tasks check out the Vision AI Leaderboard.
Best Local Vision Language Models
Here's our list of the best local vision language models.
1. Llama 3.2-Vision (11B)
Llama 3.2 Vision comes in two sizes: 11B and 90B parameters. Our focus is on the 11B model, as it fits the selection criteria for local deployment.
With a model size of roughly 7.8 GB, it can easily run on most consumer-grade GPUs. When quantized, the model’s footprint can be reduced even further while still retaining strong performance on complex vision-language tasks.
Another highlight is its 128K context window, which allows the model to reason over large inputs such as lengthy documents, multi-page PDFs, or sequences of related images, an impressive feat for a model of this size.
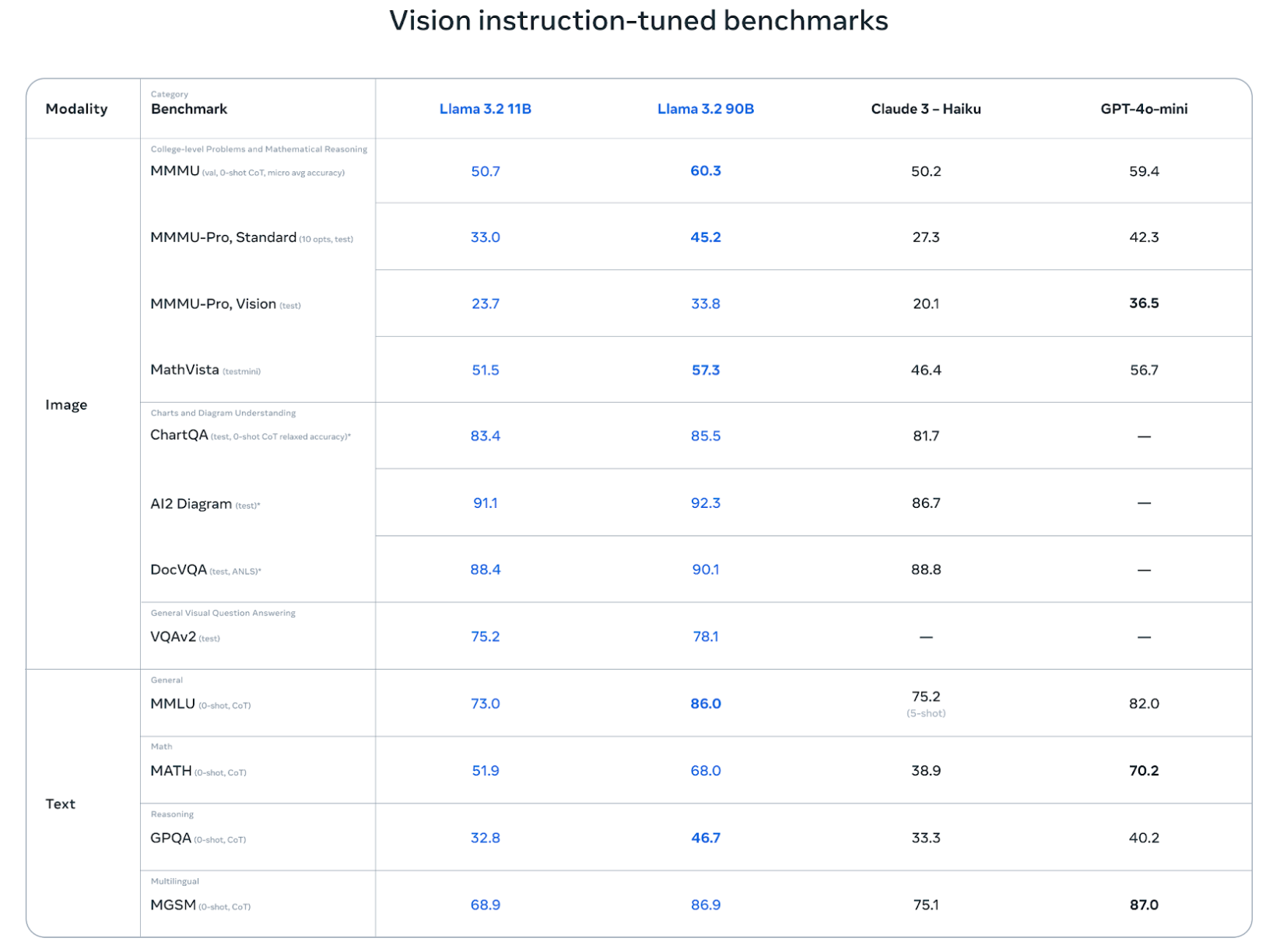
At the time of its release, Llama 3.2 Vision 11B performed exceptionally well across major benchmarks, outperforming models like Claude 3 Haiku and GPT-4o Mini. Below are some of its benchmark results:
- MMMU: 50.7 - Shows that Llama 3.2 Vision can handle broad multimodal understanding across diverse topics.
- MMMU Pro (Vision): 23.7 - Demonstrates the model’s strength in visual reasoning and interpreting complex scenes.
- MMMU Pro (Standard): 33.0 - Highlights its ability to combine text and image reasoning effectively.
- MathVista: 51.5 - Indicates strong performance in solving visually grounded math and logical reasoning problems.
- DocVQA: 88.4 - Confirms the model’s capability in document understanding and reading text within images.
- VQAv2: 75.2 - Reflects its proficiency in general visual question answering and contextual image comprehension.
2. Qwen2.5-VL
Qwen2.5-VL is a family of vision-language models available in 3B, 7B, and 72B variants. The 7B model offers the best balance between performance and efficiency, with a model size of around 6 GB and a 125K context window, making it well-suited for local deployment on most consumer-grade devices.
What’s particularly impressive is that the 7B variant of Qwen2.5-VL manages to outperform the larger 11B Llama 3.2 Vision across several major benchmarks, showing just how far model efficiency and training quality have come.
- MMMU: 58.6 - Surpasses Llama 3.2 Vision in general multimodal reasoning.
- MMMU Pro (Vision): 38.3 - Delivers stronger performance in visual perception and complex scene understanding.
- MathVista: 68.2 - Outperforms Llama 3.2 Vision in visual math and logical reasoning tasks.
- DocVQA: 95.7 - Achieves higher accuracy in document understanding and OCR-related benchmarks.
3. LLaVA-NeXT
One of the earliest small VLMs to gain traction was LLaVA, originally built on top of Vicuna and the CLIP vision encoder.
Since its initial release, the creators have continually refined the model, leading to the development of LLaVA-NeXT, which comes in 7B, 13B, and 34.75B variants. It comes in variants that either use Vicuna or Qwen as their language backbone.
Our focus is on the 7B model with a Qwen base, which delivers strong performance while remaining lightweight and efficient:
- VQAv2: 82.2 – Strong performance in visual question answering.
- MMMU: 35.3 – Solid general multimodal reasoning.
- MathVista: 35.3 – Moderate capability in visual math and logical reasoning tasks.
LLaVA-NeXT’s biggest advantage lies in its training efficiency. The model was trained on 32 GPUs for roughly one day using 1.3 million data samples, showing that high-quality multimodal reasoning doesn’t necessarily require massive compute or resources.
4. Idefics2
Idefics2 is Hugging Face’s open-source vision-language model built on top of a Mistral-7B language backbone and a SigLIP vision encoder. With 8 billion parameters, it strikes an excellent balance between capability and efficiency, offering strong multimodal reasoning while still being suitable for local deployment.
When compared to Llama 3.2 Vision 11B, the 8B Idefics2 performs competitively across multiple benchmarks, particularly in document understanding and text-based visual reasoning.
Its ability to handle high-resolution images and maintain visual fidelity gives it a distinct edge in OCR-heavy and detailed visual tasks.
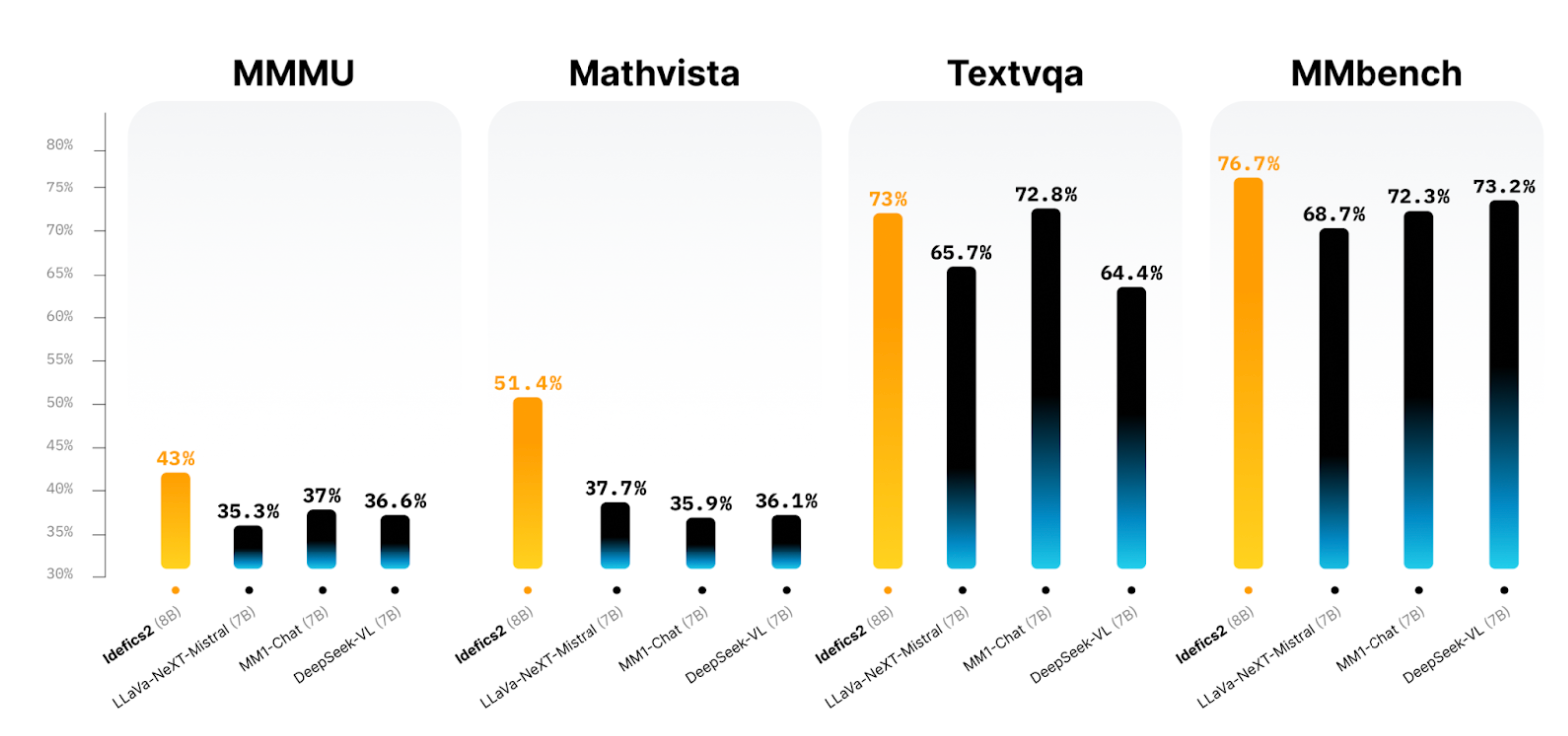
- MMMU: 43.0 - Strong general multimodal reasoning, outperforming Llama 3.2 Vision 11B.
- MathVista: 51.4 - Excellent performance in mathematical and visual reasoning tasks.
- TextVQA: 73.0 - Solid text-based visual understanding, close to larger proprietary models.
- MMBench: 76.7 - Well-rounded vision-language reasoning and comprehension ability.
5. MiniCPM-V 2.6
MiniCPM-V 2.6 is the latest and most capable model in the MiniCPM-V series. Built on SigLIP-400M and Qwen2-7B, it has 8 billion parameters and introduces major improvements in efficiency, multimodal reasoning, and visual understanding.
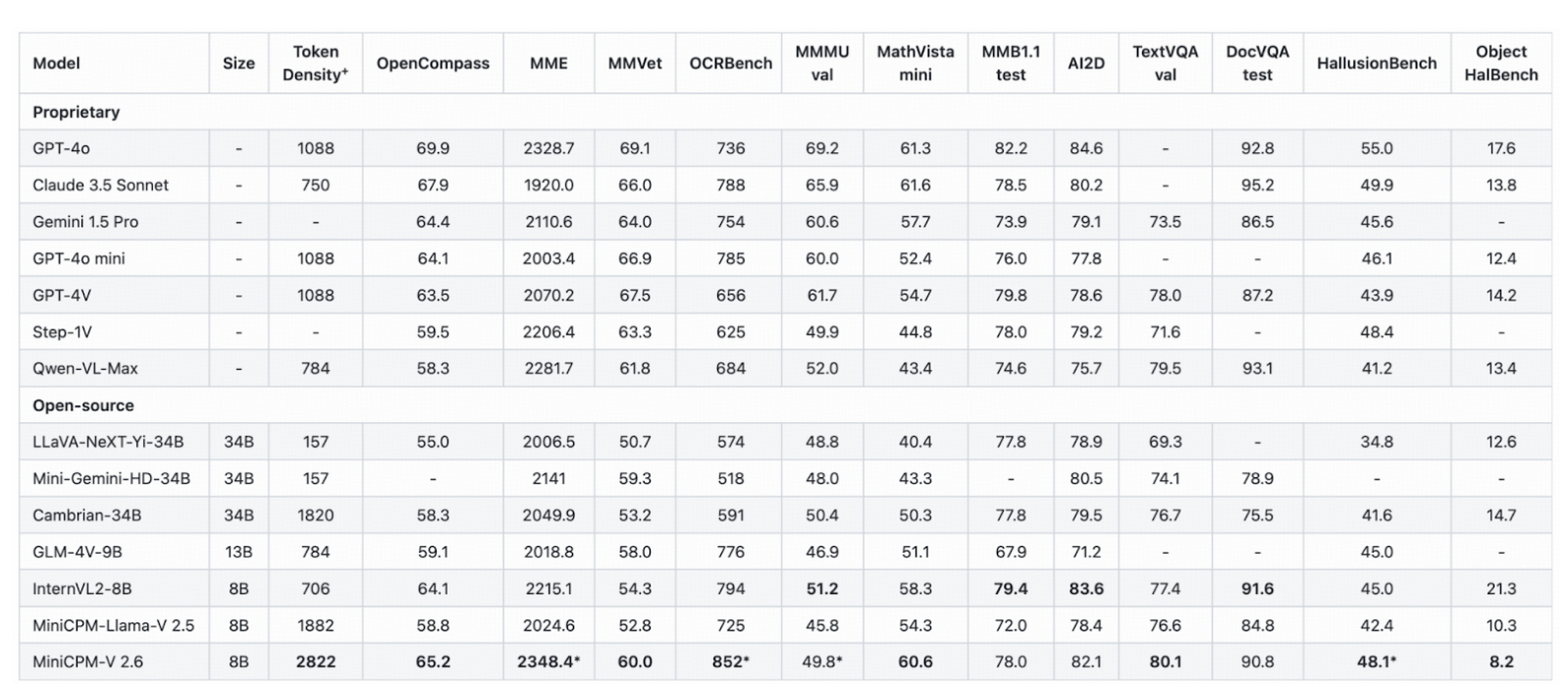
MiniCPM-V 2.6 has a compact size of about 5.5 GB and ~8.1B params, which makes it one of the smallest VLMs suitable for local deployment. The 32k context window helps with long-form multimodal reasoning. It’s also notably adept at conversation and reasoning across multiple images and video frames.
MiniCPM-V 2.6 handles images up to 1.8 million pixels and shows top-tier results on OCRBench with lower hallucination rates for OCR use cases.
6. InternVL
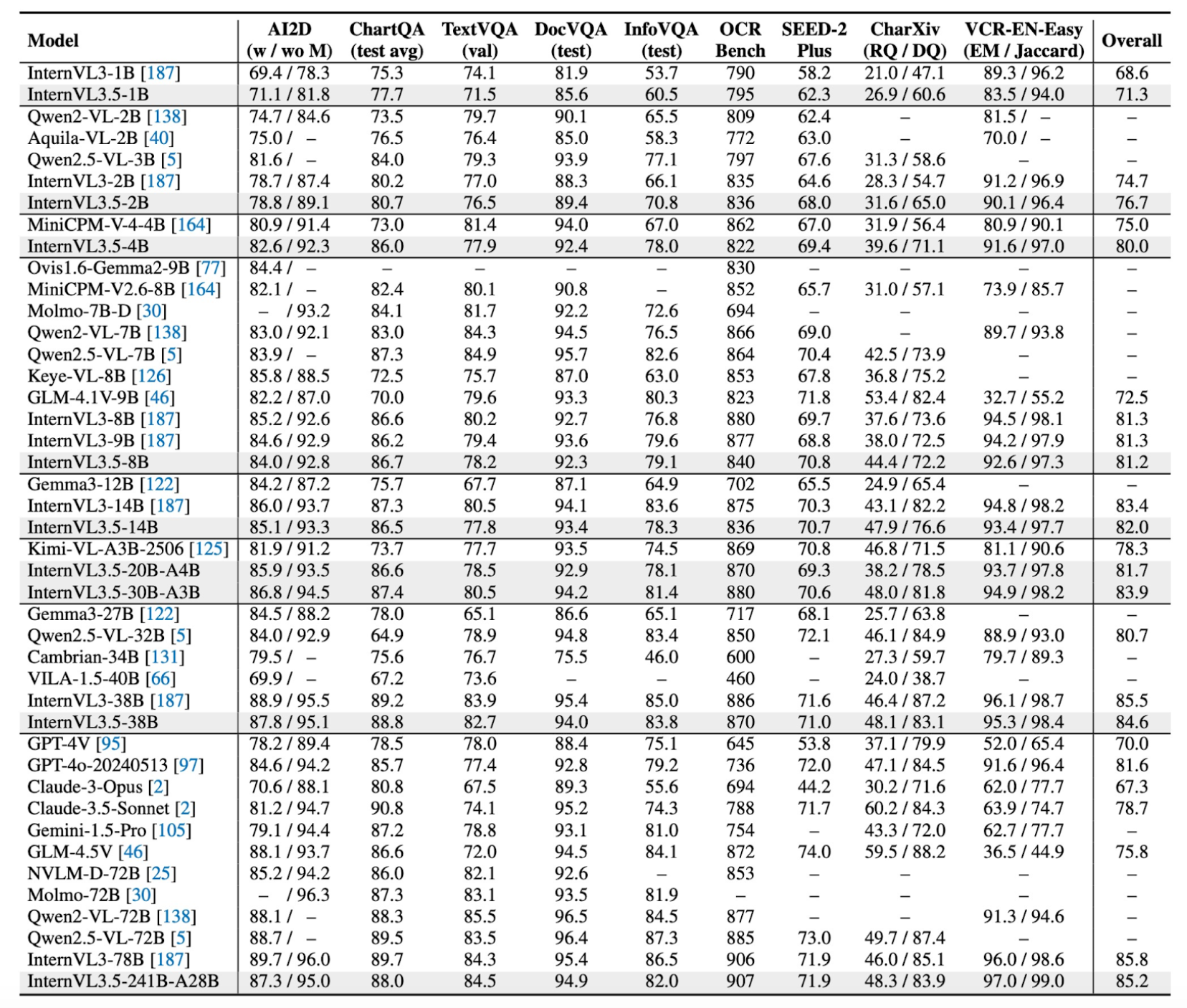
The InternVL family of compact VLMs was designed with a clear goal to close the gap between open-source and proprietary multimodal systems. True to its mission, InternVL competes directly with high-end models like GPT-4V in visual reasoning and multimodal understanding.

The InternVL 3.5 lineup spans models from 1B to 15B parameters and even includes Mixture of Experts variants such as InternVL 3.5-20B-A4B, which has 20 billion parameters but activates only 4 billion during inference. This makes it one of the most versatile small vision language models.
7. SmolVLM2
There’s nothing on this list smaller than SmolVLM2, which is by far the smallest vision language model released to date. SmolVLM2 comes in three sizes: 256M, 500M, and 2.2B parameters.
Because of its extreme efficiency, it’s ideal for running locally on devices with limited compute. For example, the 256M version uses less than 1GB of GPU memory during inference.
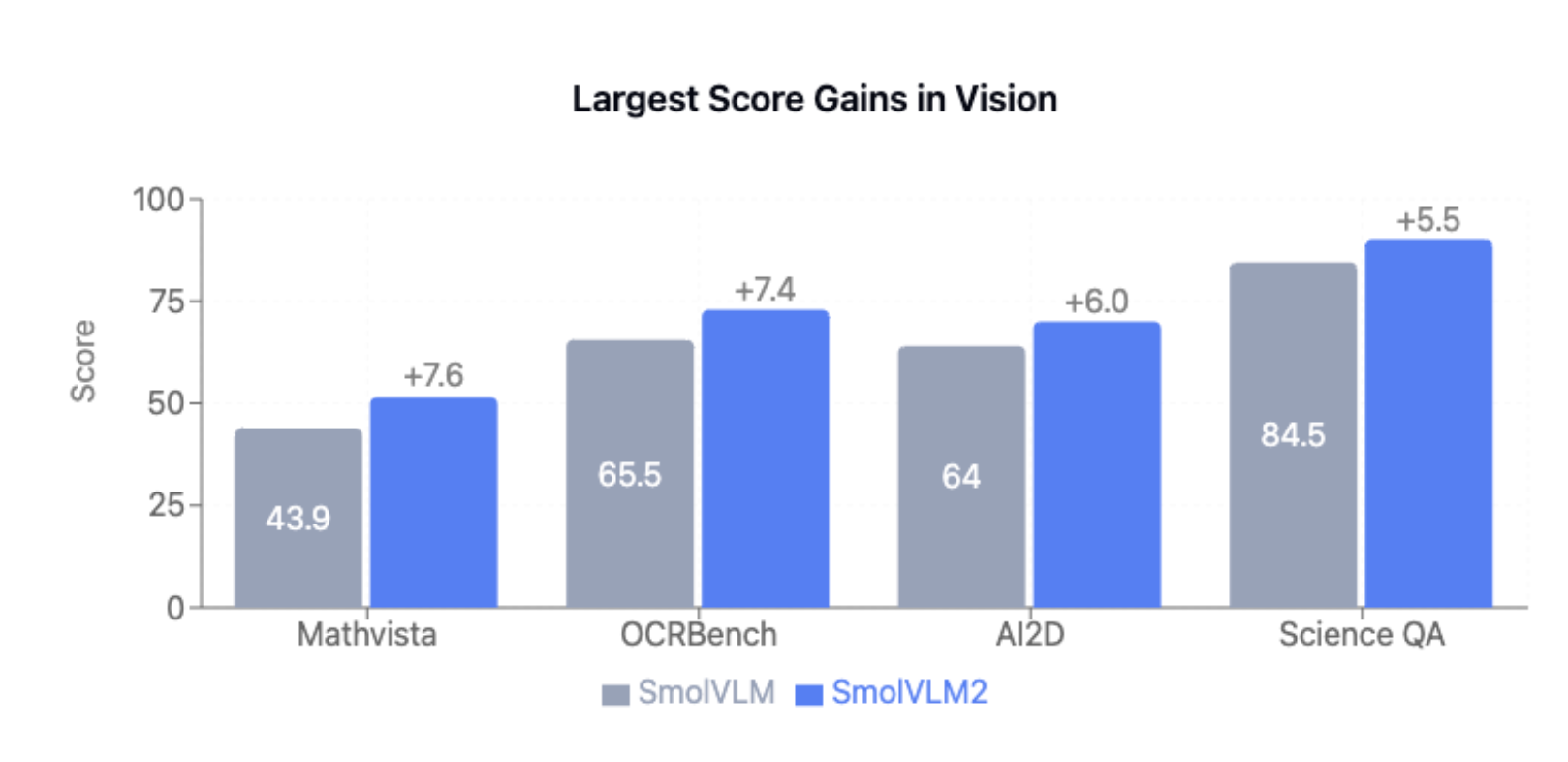
Beyond just static images, SmolVLM2 supports video understanding. It can handle video inputs (multiple frames) as well as images and text, making it suitable for tasks that require reasoning over sequences of frames, such as analyzing CCTV footage, summarizing video clips, or answering questions about video content.
Running SMOLVLM2 On Roboflow Inference
Now that we’ve covered our list of models, let’s see how to run one of them, SMOLVLM2, using Roboflow Inference. Roboflow offers multiple options for running VLMs. You can use Roboflow Workflows to build and deploy complete vision pipelines on their cloud servers, or you can self-host the inference engine locally for full control.
In this example, we’ll skip setting up a full server and instead demonstrate how to run the smallest model on our list, SMOLVLM2, for a simple document understanding task within a Google Colab free-tier environment.
Step 1: Install Roboflow Inference
Start by installing the GPU-enabled version of the Roboflow Inference package:
pip install inference-gpu[transformers]Step 2: Prepare a Sample Image
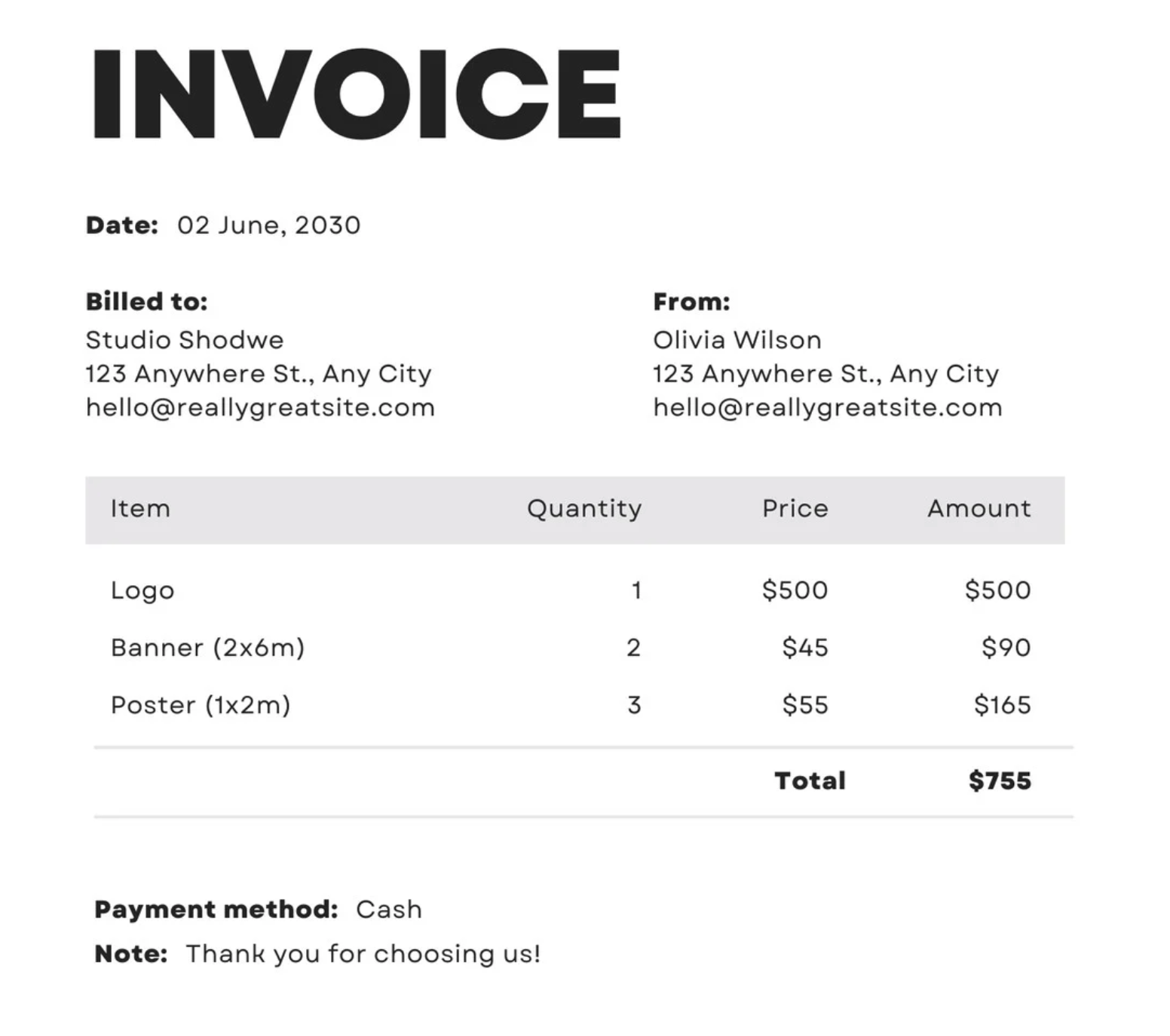
For this test, we’ll use a simple invoice image to see how SMOLVLM2 performs in extracting structured information.
Step 3: Import Dependencies
from PIL import Image
from inference.models.smolvlm.smolvlm import SmolVLMStep 4: Initialize the Model
Create an instance of the model and authenticate using your Roboflow API key.
pg = SmolVLM(api_key="YOUR_API_KEY")Step 5: Load the Image
image = Image.open("PATH_TO_IMAGE")Step 6: Extract Information Using a Prompt
Now, we’ll prompt the model to extract the item description, price, and quantity from the invoice.
prompt = "Extract the description, price, and quantity of all items?"
result = pg.predict(image,prompt)
print(result)
Here’s the output of this model run:
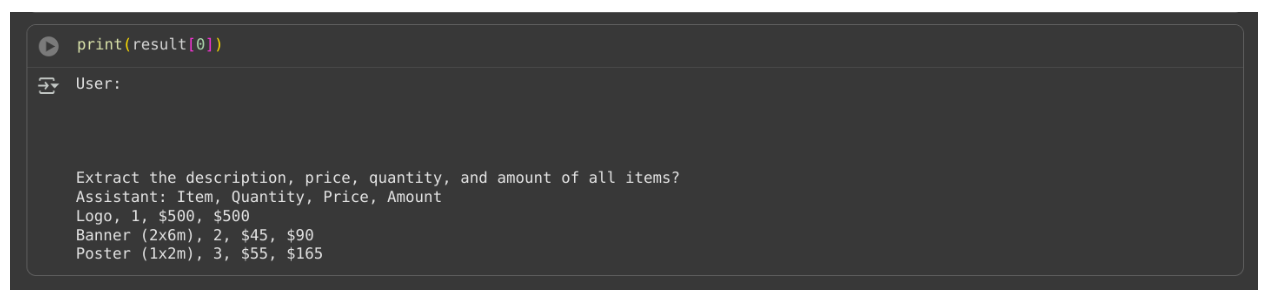
SMOLVLM2 successfully extracted the relevant text and numerical details from the image, demonstrating its ability to perform document understanding tasks with remarkable accuracy even on lightweight hardware like Google Colab’s free GPU.
Recommended: How to Fine-Tune a SmolVLM2 Model on a Custom Dataset
Conclusion: Best Local Vision-Language Models
Local vision language models prove that powerful multimodal reasoning doesn’t have to come with heavy compute costs. There’s now an entire generation of lightweight VLMs capable of handling complex visual and language tasks efficiently, making advanced AI more accessible than ever before.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Oct 10, 2025). Best Local Vision-Language Models. Roboflow Blog: https://blog.roboflow.com/local-vision-language-models/