
OpenAI's CLIP model performs zero-shot image classification by matching text prompts to image content, but the exact wording of each prompt has a significant effect on accuracy. This post walks through that sensitivity using a rock, paper, scissors hand-sign dataset, showing how prompts like "a photo of a rock hand sign" and "a hand making rock" produce different results from the same model on the same images. Choosing the right prompt is an iterative process, and understanding it is essential before relying on CLIP for any classification task.
Featuring rock, paper, scissors.
OpenAI's CLIP model (Contrastive Language-Image Pre-Training) is a powerful zero-shot classifier that leverages knowledge of the English language to classify images without having to be trained on any specific dataset.
In other words, CLIP already knows a lot about the content of images without needing to be trained. (We've written a deeper dive explaining how CLIP works and even how to use CLIP for content moderation.)
But to unlock the power of CLIP, developers need to leverage something known as prompt engineering.
What is Prompt Engineering?
As useful context, note that CLIP does a fantastic job at mapping arbitrary strings of text to image content.
For example, let's say you run an online grocery order and delivery platform, and you have a high number of images of fruit that were submitted from grocery stores, but the stores didn't label which fruits were in each image. You could manually sort through the images and puts grapes in the grapes images folder, apples in the apples images folder, and so on. You could train a classifier to recognize each fruit and then run all the images through that classifier to sort for you – but this still requires training a model with labeled data. With CLIP, you could tell CLIP to show "an image containing grapes." 🍇 The structure of that prompt – the statement you tell CLIP to recognize in images – is the basis of prompt engineering.
With CLIP, prompt engineering is the act of writing text (a prompt) that we believe will best elicit correct image classifications from CLIP. Asking CLIP to recognize, "an image containing grapes" is not the same as "a photo of grapes" or even the same as "a collection of grapes."
Writing the best prompt often becomes a game of trial and error.
Rock, Paper, Scissors and CLIP Prompt Engineering
To demonstrate the importance of prompt engineering, let's pretend we want to use CLIP to recognize hand signs from the classic game rock, paper, scissors.






For how to try OpenAI CLIP, we'll use this CLIP Jupyter Notebook, a few images from a rock, paper, scissors dataset, and ClipPlayground from @JavierFnts.
Initially, we'll provide the following three prompts to CLIP for each image:
- a person showing rock from the game rock, paper, scissors
- a person showing paper from the game rock, paper, scissors
- a person showing scissors from the game rock, paper, scissors
With these prompts, CLIP gets three of the six images correct – both rock and one of the scissors. In fact, CLIP predicted rock as the top class for every image except the one time it got scissors correct.
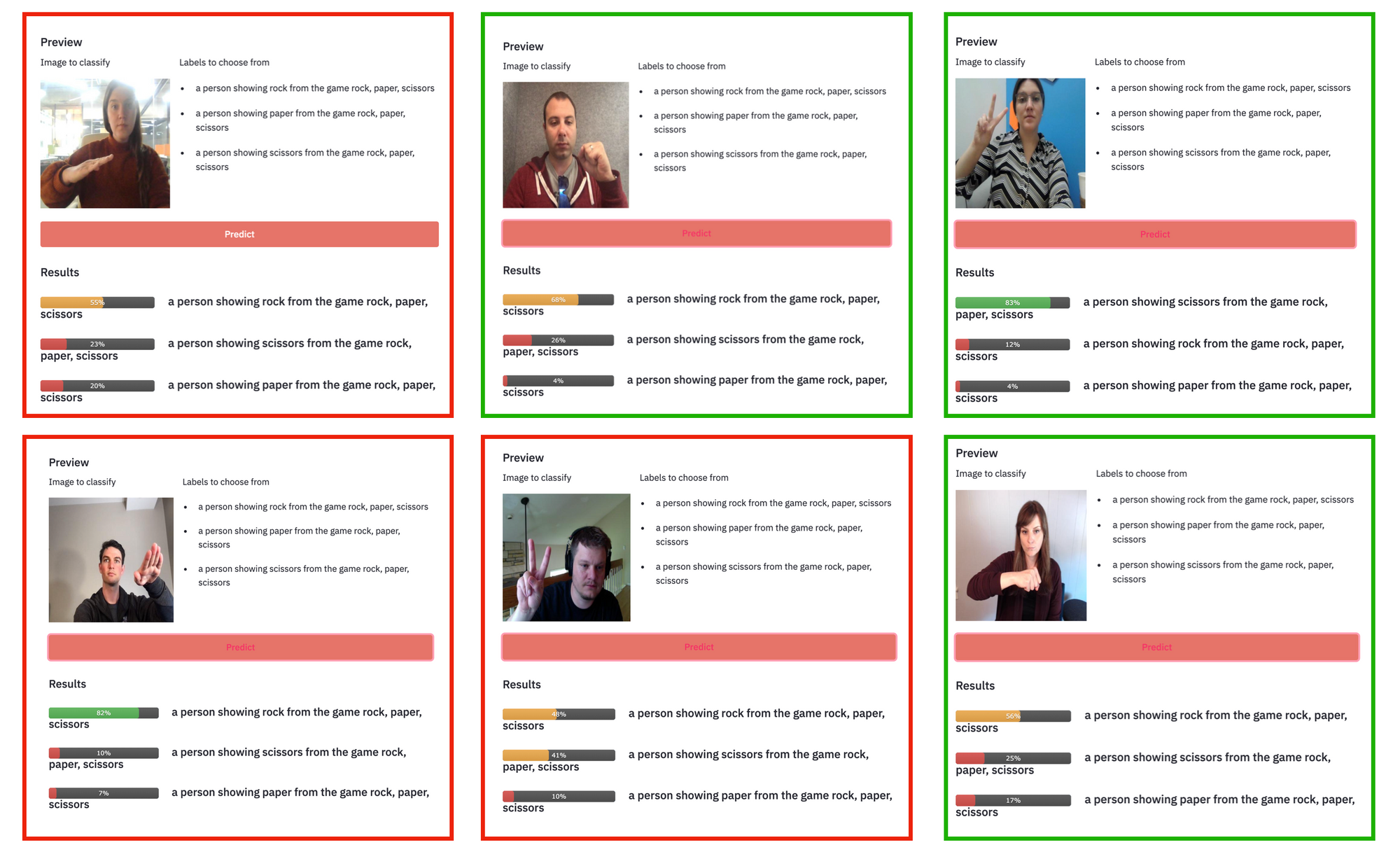
After quite a bit of trial-and-error (described below), I landed on the following prompts to try on our six images:
- a person making a fist
- a person holding up a flat hand
- two fingers
With these prompts, CLIP gets five of our six test cases correct. Incidentally, the one it misses is one of the rock ("fist") prompts.
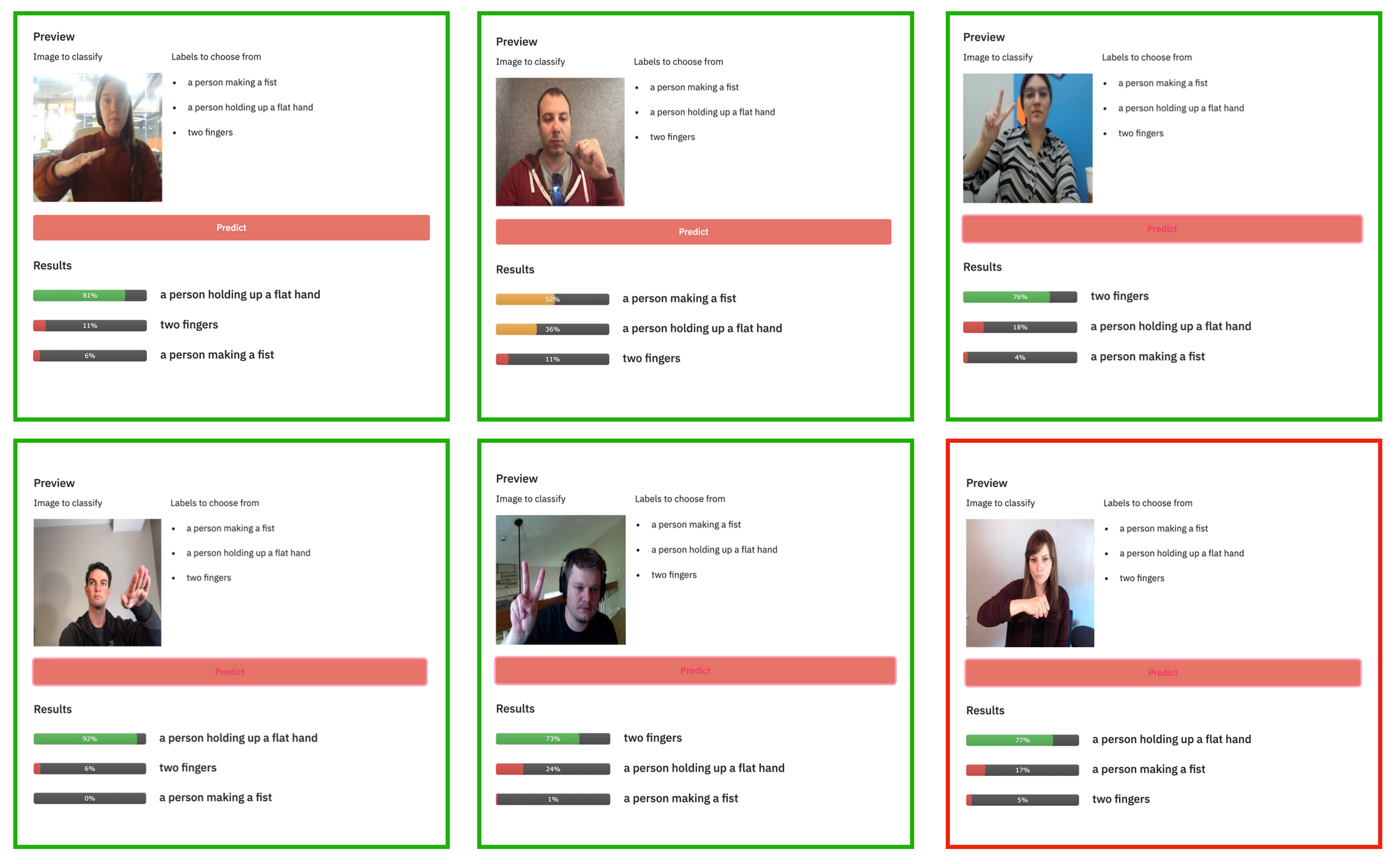
In the process of arriving at this second set of prompts, I realized including "a person ..." in the prompt was useful for the first two signals (a flat hand and a fist), but when including it for the third signal (scissors), CLIP began over-predict the scissors category.
Admittedly, prompt engineering in this case may be overfitting to my six test cases. By trying CLIP on a slightly larger 82 image dataset using a CLIP Jupyter Notebook, the following prompts appeared more effective: "Making a peace sign," "Making a fist," "A flat hand."
There are a few clear takeaways from the prompt engineering process. First, writing literal prompts (e.g. "a fist" vs "rock from rock, paper, scissors") may be a generally better approach. Secondly, the importance of iteration in prompt engineering cannot be understated (e.g. including "a person" in the prompt vs not).
Eager to try CLIP on your own dataset? Consider this guide:

Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (May 17, 2021). Prompt Engineering: The Magic Words to using OpenAI's CLIP. Roboflow Blog: https://blog.roboflow.com/openai-clip-prompt-engineering/