
OpenAI's CLIP model enables zero-shot content moderation by comparing image embeddings to text prompt embeddings using cosine similarity, so a platform can flag images as NSFW, containing hate speech, or matching other policy categories without collecting and labeling a training set for each category first. This post shows how the paint.wtf game used CLIP to automatically hide policy-violating images at scale, including a scoring penalty that discourages players from writing letters directly in their drawings to circumvent prompts.
When creating a platform on which people can create and share content, there’s often a question of content moderation. Content moderation can mean a whole host of different things, but by and large it describes rules or approaches that platforms use to classify content as acceptable or unacceptable.
- Platforms like Facebook, Twitter, and Reddit all have limits about what you can and cannot share. Facebook, for example, recently took a more aggressive stance against vaccine misinformation by more rigorously reviewing vaccine-related content and adding a link to authoritative sources (e.g. the Centers for Disease Control and Prevention in the U.S.) when vaccines are mentioned.
- Public schools in the United States can place certain limits on what students can and cannot publish in school-sponsored newspapers.
There are all sorts of reasons why organizations want to shape the conversations that take place in a setting that’s under their purview. While we can understand why organizations want to have a say in the content that’s shared in an arena, content moderation is not a trivial thing to implement. Whether it’s due to scale or sensitivity or something else, there are plenty of challenges with content moderation.
Content moderation usually comes in one of three forms: human moderation, model-based, and non-model-based moderation.
- Human moderation is pretty straightforward: it means that a human will review and classify content as acceptable (or unacceptable).
- Non-model-based moderation is an automated technique that uses a rule-based approach to filtering content; you might think of this like “If X, then Y.” For example, “if content includes the phrase ‘Iowa is not the greatest state in the United States,’ then take the content down,” or “if content includes the word [insert word here], then have a human review the content.” (The latter example is an example of non-model-based moderation that flags content to later be human-moderated -- these techniques don’t live in a silo!)
- Model-based moderation uses a statistical model or machine learning model to classify content as acceptable or unacceptable. If we’re talking about text posts, for example, someone may train a logistic regression model or random forest model on a set of text data that includes acceptable and unacceptable posts. That model, once trained, can be used to generate predictions for new posts. We can do the same with images. (More on that later.)
There are advantages and disadvantages to any approach. Human moderation is the most bespoke, but is difficult to scale because a human is required to review each post. Either automated moderation technique (model-based and non-model-based) is attractive for its scalability, but will fall prey to the biases to which all machine learning models fall prey and, in the case of non-model-based moderation, is limited by the human inputs used to filter out content.
If you want to use a model-based moderation technique, you previously needed a lot of training data of a similar composition to your user generated content. But what about for new sites that don’t yet have data to train a model? You could use off-the-shelf content moderation but that only works if your content is similar enough to the data the pre-trained model learned from.
Enter a new approach: OpenAI's new CLIP model.
OpenAI's CLIP model can understand the semantic meaning of images. This means that you can provide the CLIP model with an image and CLIP can, for example, generate a good description of the image. You might think of CLIP as a really, really good caption writer. At a higher level, CLIP is a bridge between computer vision and natural language processing.
The way that the CLIP model is trained, CLIP doesn't need a specifically-curated training set of images of interest beforehand – in fact, it doesn't need to see similar or closely related images, either. This is called “zero-shot,” where a model is capable of predicting a class it's never seen before. (If you want more details on how the CLIP model works, read our “explain it like I'm 5” CLIP blog post for beginners.)
We can use that feature of the CLIP model to do content moderation on unique image domains without first having to train a specialized model.
Using CLIP for paint.wtf content moderation
Recently, Roboflow (and friends at Booste.io) developed paint.wtf, a game where you're given a caption, you try to draw that prompt using a Microsoft Paint-like interface, and the CLIP model judges how good your drawing is.
For example, if the caption is a cute raccoon using a computer, you might draw this:

How do we use the CLIP model to moderate paint.wtf content?
It's helpful to understand how paint.wtf judges the “goodness” of a drawing.
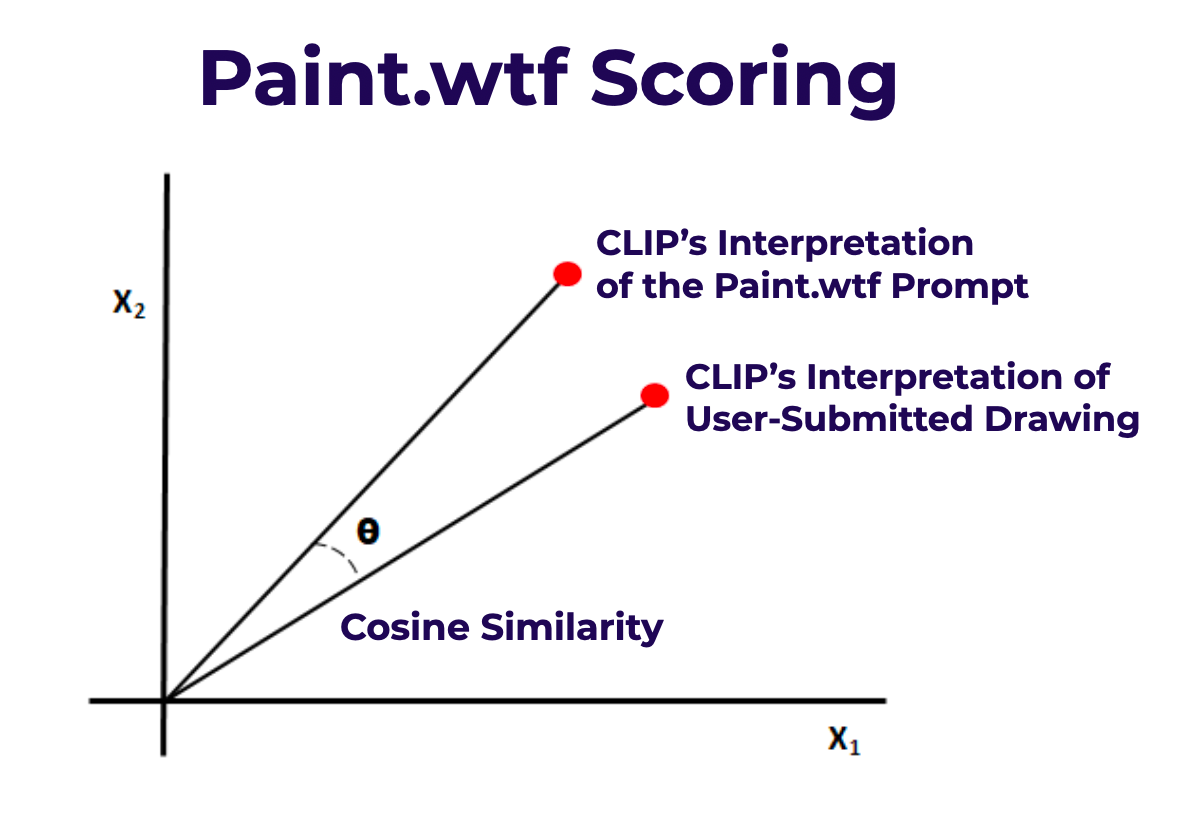
- CLIP can interpret where a prompt is in embedded space.
- CLIP can also interpret the user's drawing in that same embedded space.
- We use cosine similarity to calculate a distance between the CLIP interpretation of the prompt and the CLIP interpretation of the drawing. If CLIP judges the drawing to be “close to” the prompt, the cosine similarity will be closer to 1. If CLIP judges the drawing to be “far from” the prompt, the cosine similarity will be closer to 0.
- Submissions were originally ranked based only on their cosine similarity; the submission with the highest cosine similarity wins 1st place, the submission with the next-highest cosine similarity comes in 2nd place, and so on.
However, we pretty quickly saw the need to moderate content:
- It turns out that CLIP can read, so people were able to cheat by writing the text of the prompt in the image instead of drawing the prompt. That defeats the purpose of the game! We wanted to penalize for this – but using humans to do it would be extremely time-consuming.
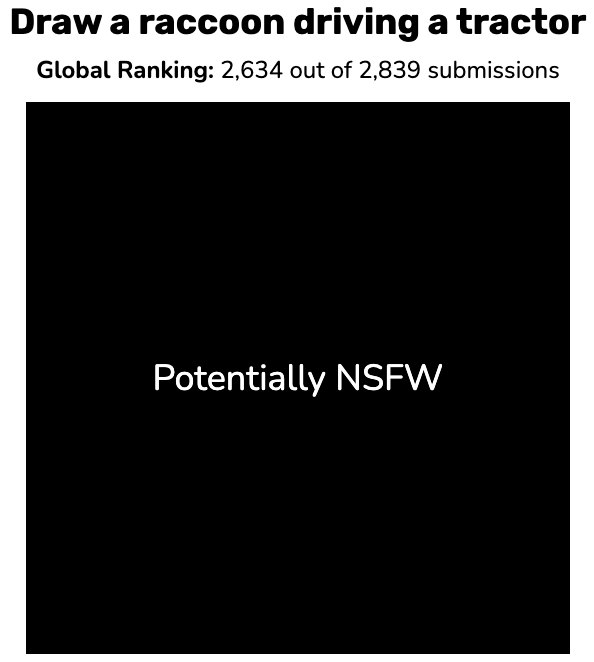
- As with many things on the internet, people started to submit images that were not safe for work (NSFW). We wanted to provide a fun environment in which people can play a game while minimizing the chance that someone stumbles upon something upsetting or offensive.
This is where CLIP and cosine similarity re-enter.
We can ask CLIP whether an image contains “NSFW” by comparing the CLIP interpretation of the image to the CLIP interpretation of “NSFW” via cosine similarity. If the cosine similarity is larger than some threshold, we automatically hide the image as potentially NSFW. We can expand this (and have done so!) for “racist symbols,” “hate speech,” “profanity,” “nudity,” and more.
We've also added a penalty for the written letters – we can use CLIP to compare the image to the CLIP interpretation of “written letters,” then subtract that cosine similarity from the cosine similarity between the image and the prompt.
score = cosine_sim(image,prompt) - cosine_sim(image,written letters)If you're trying to win (and generally neither be gross nor cheat at the game), you're better off avoiding NSFW content and writing out letters. Over time, we're continually adjusting our content moderation algorithm as well.
And that's how you can use CLIP for content moderation! One method of doing so, anyway. CLIP can be used in a ton of different ways. We've got a CLIP tutorial for you to follow.
- If you do something with CLIP, let us know and we'll help you show it off
- If you want to play our paint game, play paint.wtf here
- If you want to learn how we built paint.wtf, check out our writeup here.
Cite this Post
Use the following entry to cite this post in your research:
Matt Brems, Brad Dwyer. (Mar 28, 2021). Zero-Shot Content Moderation with OpenAI's New CLIP Model. Roboflow Blog: https://blog.roboflow.com/zero-shot-content-moderation-openai-new-clip-model/