
In March 2025, we introduced RF-DETR, the first real-time object detection model that achieves 60+ mAP when validated on the Microsoft COCO benchmark. RF-DETR is also the best at generalising in different domains as measured by the RF100-VL benchmark.
Today, we are excited to introduce the addition of three new state-of-the-art model sizes to the RF-DETR family: Nano, Small, and Medium. The RF-DETR family of models are the fastest and most accurate object detection models available. RF-DETR is open source, licensed under an Apache 2.0 license.
RF-DETR ("Roboflow detection transformer") is a real-time object detection transformer-based architecture designed to transfer well to both a wide variety of domains and to datasets big and small. As such, RF-DETR is in the "DETR" (detection transformers) lineage of models. It is developed for projects that need a model that can run high speeds with a high degree of accuracy and often on limited compute (like on the edge or low latency). It is also increasingly important to complement LLMs and VLMs with fast and accurate grounding capabilities.
RF-DETR is accompanied by a paper, RF-DETR: Neural Architecture Search for Real-Time Detection Transformers, which is available on Arxiv. The paper contains detailed information about the RF-DETR model architecture, our results from benchmarking the model, and more.
The new RF-DETR model sizes are available to train in the cloud with Roboflow, as well as with the open source RF-DETR Python package.
RF-DETR Nano in action. It is the fastest, most accurate model for its size, running at 100 FPS on an NVIDIA T4. It's baller.
Try out RF-DETR in the interactive workflow below.
Model Performance and Benchmarks
To evaluate models, we use both the Microsoft Common Objects in Context (MS COCO) and Roboflow 100 Vision Language (RF100-VL) benchmarks. COCO enables easy comparisons to prior model families, though increasingly faces limitations in eval optimization and potential overfitting since its last release in 2017.
RF100-VL measures domain adaptability. The benchmark is a selection of 100 open source datasets from the 500,000+ open source datasets on Roboflow Universe powered by, you, the community. RF100-VL represents how computer vision is being applied to real-world problems like aerial imagery, industrial contexts, nature, laboratory imaging, and more.
RF-DETR results are as follows:
| Family | Size | COCO mAP50 | COCO mAP50:95 | RF100VL mAP50 | RF100VL mAP50:95 | Latency (ms) |
|---|---|---|---|---|---|---|
| RF-DETR | Nano | 67.6 | 48.4 | 84.1 | 57.1 | 2.32 |
| RF-DETR | Small | 72.1 | 53 | 85.9 | 59.6 | 3.52 |
| RF-DETR | Medium | 73.6 | 54.7 | 86.6 | 60.6 | 4.52 |
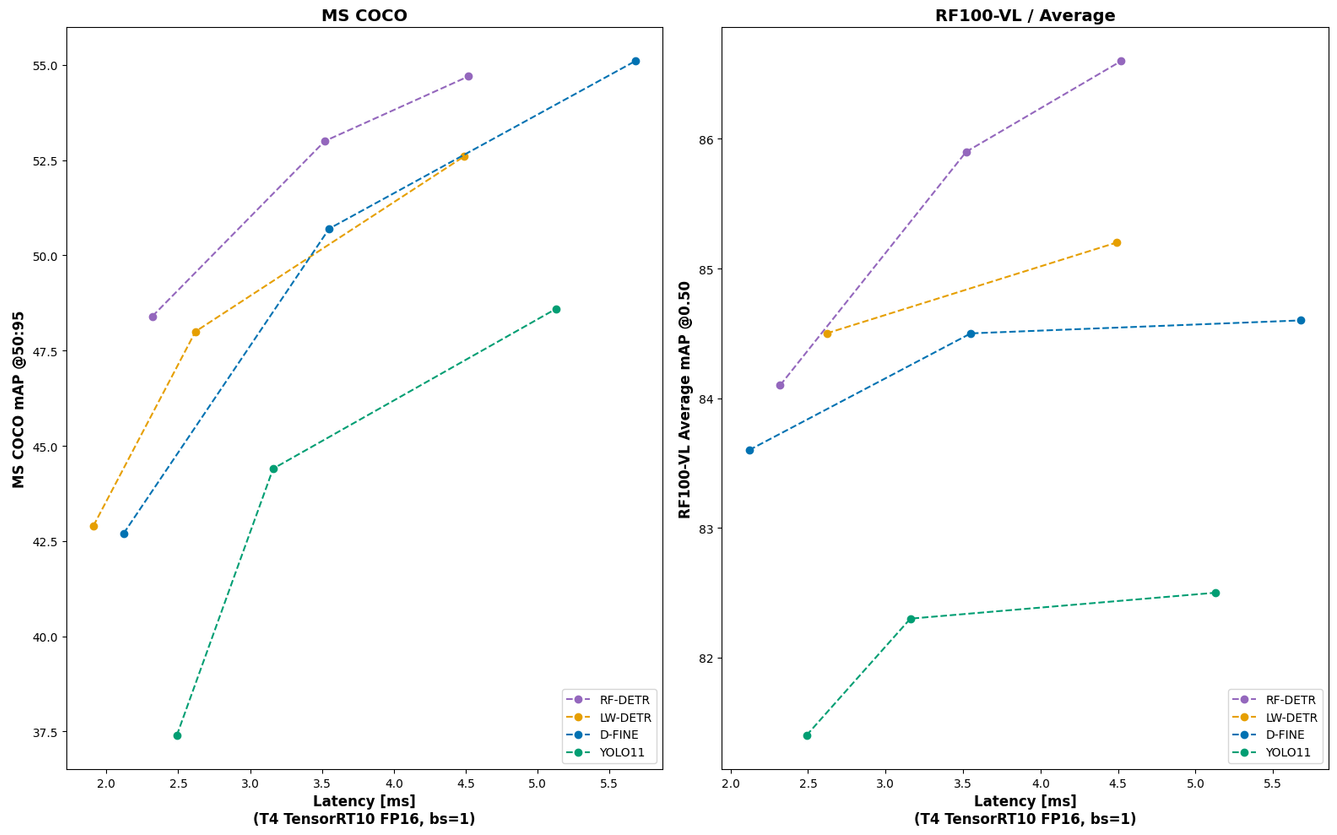
We further evaluate RF-DETR relative to other current realtime COCO transformer models (D-FINE, LW-DETR) and YOLO CNN architectures (YOLO11).
- RF-DETR outperforms (speed, accuracy) all approaches in mAP50 and mAP50:95 on COCO
- RF-DETR outperforms all approaches in mAP50 and is comparable in mAP50:95 on RF100-VL
Notably, transformer-based approaches like RF-DETR are not only higher performance at comparable model sizes to CNN-based approaches like YOLO. Smaller RF-DETR models outperform larger YOLO models in speed and accuracy. For example, for mAP50:95 COCO, RF-DETR-Small is 1.8 higher than YOLO11-x (the largest YOLO11 model) with a 7.77 ms latency speed up. Similar results are consistent in LW-DETR and D-FINE vs pure CNNs.
Here are full table of results with comparable model sizes where results are easily replicated:
| family | size | coco_map50 | coco_map50:95 | rf100vl_map50 | rv100vl_map50:95 | latency |
|---|---|---|---|---|---|---|
| RF-DETR | Nano | 67.6 | 48.4 | 84.1 | 57.1 | 2.32 |
| RF-DETR | Small | 72.1 | 53.0 | 85.9 | 59.6 | 3.52 |
| RF-DETR | Medium | 73.6 | 54.7 | 86.6 | 60.6 | 4.52 |
| YOLO11 | n | 52.0 | 37.4 | 81.4 | 55.3 | 2.49 |
| YOLO11 | s | 59.7 | 44.4 | 82.3 | 56.2 | 3.16 |
| YOLO11 | m | 64.1 | 48.6 | 82.5 | 56.5 | 5.13 |
| YOLO11 | l | 65.3 | 50.2 | x | x | 6.65 |
| YOLO11 | x | 66.5 | 51.2 | x | x | 11.92 |
| LW-DETR | Tiny | 60.7 | 42.9 | x | x | 1.91 |
| LW-DETR | Small | 66.8 | 48.0 | 84.5 | 58.0 | 2.62 |
| LW-DETR | Medium | 72.0 | 52.6 | 85.2 | 59.4 | 4.49 |
| D-FINE | Nano | 60.2 | 42.7 | 83.6 | 57.7 | 2.12 |
| D-FINE | Small | 67.6 | 50.7 | 84.5 | 59.9 | 3.55 |
| D-FINE | Medium | 72.6 | 55.1 | 84.6 | 60.2 | 5.68 |
Of note, the speed shown is the GPU latency on a T4 using TensorRT10 FP16 (ms/img) in a concept LW-DETR popularized called "Total Latency." Unlike transformer models, YOLO models conduct NMS following model predictions to provide candidate bounding box predictions to improve accuracy.
However, NMS results in a slight decrease in speed as bounding box filtering requires computation (the amount varies based on the number of objects in an image). Note most YOLO benchmarks use NMS to report the model's accuracy, yet do not include NMS latency to report the model's corresponding speed for that accuracy.
Benchmarking here follows LW-DETR's philosophy of providing a total amount of time to receive a result uniformly applied on the same machine across all models. Like LW-DETR, we present latency using a tuned NMS designed to optimize latency while having minimal impact on accuracy.
Start Training with the New RF-DETR Model Sizes
All three RF-DETR model sizes can be trained in the cloud with the Roboflow platform as well as on your own hardware using the RF-DETR repository. The best way to see which model size is best for your use case is to try them.
You can access these sizes when you go to train a model in Roboflow:
Alongside this model release, we have written new documentation for RF-DETR with all the information you need to use the RF-DETR SDK.
You can deploy RF-DETR models on your own hardware with Roboflow Inference, our computer vision inference server, and easily use RF-DETR in tandem with Roboflow Workflows, a computer vision application builder to chain together models and logic for optimized runtime.
RF-DETR models can also be run on the cloud with the Roboflow Serverless V2 API and on Dedicated CPU or GPU Deployments provisioned on Roboflow.
We also have a detailed video tutorial that walks through our RF-DETR training notebook:
What’s Next for RF-DETR?
The three new model sizes we are releasing today is the result of work built on top of our initial release of RF-DETR following community feedback. We expect to release more soon, with continued motivation by community feedback.
The top priorities we've heard so far include optimizing model deployment on edge offerings, CoreML support for Apple devices, and in-browser support with Inference.js. We've also heard demand for segmentation and classification heads with the RF-DETR architecture.
We have written about architecture details in RF-DETR, and we anticipate publishing an RF-DETR paper with even greater detail on how we achieved state-of-the-art results for object detection.
We look forward to seeing what you make with RF-DETR. If you have feedback on the model, please open an issue on the RF-DETR GitHub repository.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher, Joseph Nelson. (Jul 24, 2025). Advancing State of the Art Object Detection (Again) with RF-DETR. Roboflow Blog: https://blog.roboflow.com/rf-detr-nano-small-medium/