
In March 2025, we released a new, state-of-the-art model architecture: RF-DETR. We initially launched with a single model size for object detection, later expanding the RF-DETR family to four object detection models: Nano, Small, Medium, and Large.
Today, we are excited to announce that we are expanding RF-DETR to support instance segmentation with the launch of RF-DETR Segmentation.
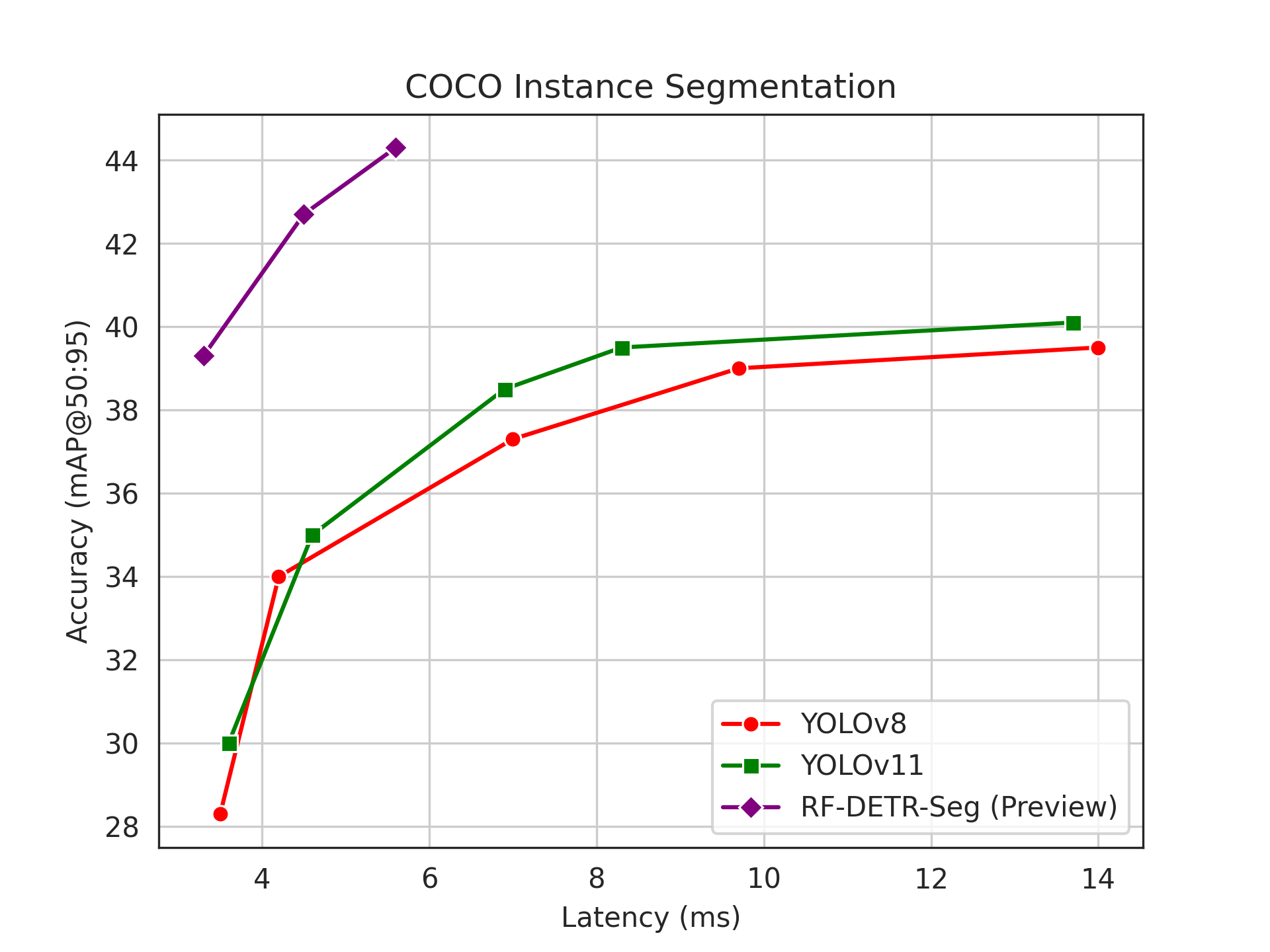
RF-DETR Segmentation is 3x faster and more accurate than the largest YOLO11 when evaluated on the Microsoft COCO Segmentation benchmark, defining a new real-time state-of-the-art for the industry-standard benchmark in segmentation model evaluation.
RF-DETR is accompanied by a paper, RF-DETR: Neural Architecture Search for Real-Time Detection Transformers, which is available on Arxiv. The paper contains detailed information about the RF-DETR model architecture, our results from benchmarking the model, and more.
Here is an example of an RF-DETR Segmentation model trained on the Microsoft COCO dataset identifying various objects:

Here is an example of a single image to highlight the precision of the masks:

You can now train RF-DETR Segmentation models in the cloud with Roboflow Train, in our open source rfdetr Python package, and with Autodistill, our Python ecosystem for using foundation models to label data for training smaller, real-time models like RF-DETR.
Introducing RF-DETR Segmentation
RF-DETR ("Roboflow detection transformer") is a real-time transformer-based architecture designed to transfer well to both a wide variety of domains and to datasets big and small. RF-DETR Segmentation adds a segmentation head to the RF-DETR model architecture, allowing you to use the model for real-time image segmentation.
RF-DETR Segmentation is the first DETR-based segmentation model that achieves over 30 FPS on a T4 machine. The end-to-end latency of the model is 5.6ms, which corresponds to over 170 FPS.
RF-DETR Seg adds a masking head to RF-DETR inspired by MaskDINO, along with a more memory efficient implementation of its loss function. There are many differences between the MaskDINO segmentation head and that of RF-DETR Seg, but the two most important differences are in its upsampling strategy and its layerwise layout parallel to the decoder layers.
In existing segmentation heads for DETR-like models, the backbone of the model is hierarchical and the features fed into the segmentation head are from the high resolution features from the hierarchical backbone. However, RF-DETR uses the DINOv2 backbone, which is a (non-hierarchical) ViT. We therefore don’t have readily available high resolution features.
To address this, we make the key observation that the deformable cross attention used in the RF-DETR object decoder induces an inductive bias in the post-backbone features to be amenable to bilinear interpolation. Following this, we bilinearly upsample the post-backbone features to generate high resolution features amenable to mask generation. In this way both the segmentation head and the object decoder leverage a shared feature space, improving learning ability without requiring that the backbone supply high resolution features.
In modern DETR models, each layer in the decoder receives its own loss function for generating accurate boxes and classes for objects. Because of this, the decoder layers can be thought of as refining the set of predicted boxes. Similarly, we impose a masking loss on each layer of the segmentation head by computing a mask based on the representation of the parallel layer from the decoder.
In this way, we make the segmentation head refine the mask representation in subsequent layers, improving learning efficiency just as adding a loss on each decoder layer improves efficiency.
When compared to YOLO models, RF-DETR Seg is more memory intensive during the training process. This means that the maximum batch size that can be trained on is smaller. However, all RF-DETR models do not use batch normalization, which allows them to leverage gradient accumulation during training to make it easier to train models on consumer hardware. When training RF-DETR Seg models, use a lower batch size and more gradient accumulation steps than you would to train RF-DETR.
Model Performance
When validated on the Microsoft COCO Segmentation benchmark, RF-DETR Seg mentation achieves 44.3 mAP@50:95, a state-of-the-art result for real-time segmentation models. It does this while running at over 170fps on a T4 GPU.
Of note, the Roboflow research team specifically measures end-to-end latency, as opposed to only measuring the time spent in the model's parametric layers. We believe this is a fairer method of evaluating the latency of a model than excluding required steps (such as non-maximal suppression (NMS), object mask generation from prototypes, and mask cropping) from counting towards latency and instead binning them as postprocessing.
In the same way that RT-DETR set the precedent of including the non-maximal suppression (NMS) time in latency calculation for object detectors, we set the precedent of including the time to compute object masks from prototype masks. Prototype masks aren’t directly useful for consumers, so the conversion from prototype mask to object mask is required postprocessing, and therefore should be considered part of the end-to-end latency. For the same reason, the time to crop masks to bounding boxes should be included as latency.
However, modern latency measurements rely on TensorRT and ONNX, while often this prototype conversion is done with raw PyTorch, sometimes even on a CPU. To address this we introduce tooling to add to any YOLO model optimized prototype application within TensorRT, significantly improving end-to-end latency. This also enables fair comparison with RF-DETR Seg, which directly generates usable object masks.
Finally, as discussed previously, we measure model accuracy and latency with the same model artifact in fp16. For YOLO models, we use fused NMS and a confidence threshold of 0.01 following prior work.
RF-DETR Seg-Preview obtains 44.3 mAP@50:95 on COCO in 5.6ms. By scaling resolution, we can also obtain state-of-the-art models at lower latencies. For example, at 312 resolution, RF-DETR Seg-Preview 39.3 mAP in 3.3ms. ‘Measured Latency’ means end-to-end latency measured in fp16, and ‘Measured mAP’ means mAP@50:95 obtained from running that same model.
Despite just being a preview of our ultimate RF-DETR Seg model, RF-DETR Seg-Preview@432 already outperforms the reported mAP for YOLO11x-Seg, while being nearly 3x faster than the reported latency. When we measure latency and accuracy using the same end-to-end model in fp16, RF-DETR Seg-Preview@312 outspeeds YOLO11n-Seg while outperforming it by 9.3 mAP.
To reproduce our end-to-end latency and accuracy numbers, please use our new benchmarking repo here. We would love community engagement on getting better results for all models!
Train an RF-DETR Segmentation Model
Starting today, you can train an RF-DETR Segmentation model in two ways:
- In the Roboflow platform, and;
- Using the open source rfdetr Python package.
You can use all of your RF-DETR Segmentation models with Roboflow Workflows, our tool for building multi-step computer vision applications. Your models can then be deployed in the cloud using our serverless API, on dedicated infrastructure using a Dedicated Deployment, or on your own hardware using Inference, our open source computer vision inference server.
Train a Model in the Roboflow Cloud
To train an RF-DETR Segmentation model in the cloud, first prepare an instance segmentation dataset in Roboflow. Create a new dataset version, then click “Train a Model”. A window will appear from which you can choose the RF-DETR model architecture:
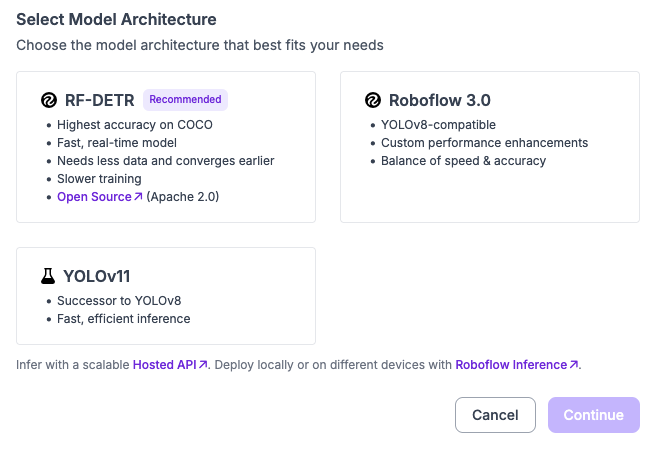
Once you select RF-DETR, you will then be asked to choose a model size. For now, we only support the base RF-DETR Segmnentation weights. We anticipate releasing three new models by the end of the year, all of which will be available for training in the cloud.
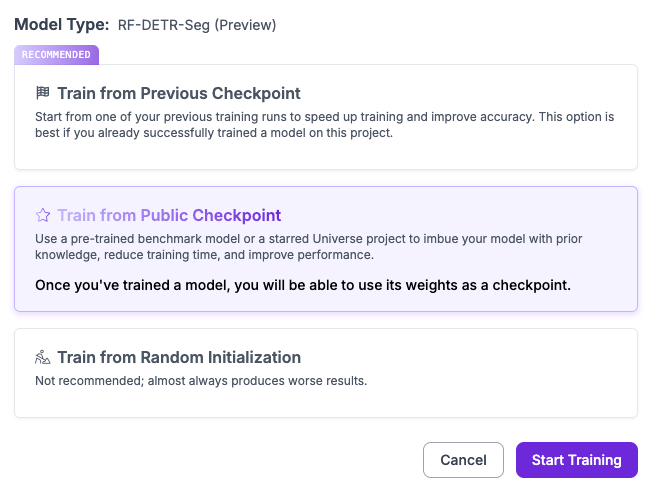
Select RF-DETR Segmentation. You will then be able to configure your training job. We recommend training from our pre-trained default checkpoint:
Once you have configured your training job, click “Start Training” to start your job.
You will receive an estimate of how long we expect your training job to take. The duration of your training job will depend on the number of images in your dataset.
We will send you an email once your model is ready to use.
Train a Model with the RF-DETR Python Package
We have updated the rfdetr Python package to include a new RFDETRSegPreview class. You can use this class to train your RF-DETR models.
To train a model with the rfdetr Python package, first prepare a dataset in the Microsoft COCO Segmentation format. You can export any segmentation dataset hosted on Roboflow in this format for use in training an RF-DETR Segmentation model.
Then, use the following code to train your model:
from rfdetr import RFDETRSegPreview
model = RFDETRSegPreview()
model.train(
dataset_dir=<DATASET_PATH>,
epochs=100,
batch_size=4,
grad_accum_steps=4,
lr=1e-4,
output_dir=<OUTPUT_PATH>
)
For more information on training parameters, refer to the RF-DETR training documentation.
All models trained with the open source Python package can be deployed with the Python package, or uploaded back to Roboflow for deployment in the cloud or on your own hardware with Roboflow Inference.
What’s Next for RF-DETR?
This year, we have re-defined the state of the art for object detection models twice, first with the launch of RF-DETR Base, then with the launch of our full model family.
We are excited to follow our progress in object detection with RF-DETR Segmentation. Today, we have announced the first model in the RF-DETR Segmentation family: Seg (Preview). We plan to launch a full family of three models by the end of October.
We also plan to release a paper describing RF-DETR by the end of October.
We would love your feedback on RF-DETR! If you have feedback, questions, or encounter any issues, please leave a comment or Issue on the RF-DETR GitHub repository. If you train a model with RF-DETR, let us know on social media by tagging us @Roboflow. We would love to see how people are using RF-DETR to solve real-world problems.
If you find this useful for your work, please cite the GitHub RF-DETR repo until we have released our paper, at which point please cite the paper!
Cite this Post
Use the following entry to cite this post in your research:
Isaac Robinson, Peter Robicheaux, Matvei Popov, Neehar Peri. (Oct 2, 2025). SOTA Instance Segmentation with RF-DETR. Roboflow Blog: https://blog.roboflow.com/rf-detr-segmentation-preview/