
Vision-language models (VLMs) have fundamentally changed how we work with images. These models are trained on images paired with text, which helps them relate visual features to language. Instead of training a new model for every task, you simply describe what you're looking for in plain words and get useful results instantly.
Models like CLIP demonstrated this was possible: a single pre-trained network could recognize thousands of visual concepts using only text prompts. This idea quickly expanded into a rich ecosystem of increasingly capable models. Today's VLMs - including Florence-2, Llama3.2 Vision, Qwen2.5-VL, PaliGemma, Gemini 3, GPT-5, and Claude 3 Opus - can perform an impressive range of computer vision tasks without any custom training. These tasks are as follows:
- Image captioning and description: Generate detailed narratives about what appears in an image
- Visual question answering: Respond to specific questions about image content, context, or relationships
- Object detection and localization: Identify and locate objects, people, or elements within scenes
- Image classification and categorization: Assign images to relevant categories or labels
- Semantic search and retrieval: Find images matching natural language queries
- Visual similarity comparison: Assess how closely images match text descriptions or other images
- Attribute recognition: Identify properties like colors, textures, materials, or conditions
- Scene understanding: Interpret the broader context, setting, and situation depicted
- Relationship reasoning: Understand how objects interact and relate to each other
- Text extraction (OCR): Read and extract text visible in images
- Anomaly and inconsistency detection: Spot visual defects, errors, or unusual patterns
- Phrase grounding: Connect specific image regions to text descriptions
- Counting and quantification: Enumerate objects or elements within scenes
- Spatial reasoning: Understand positions, orientations, and spatial relationships
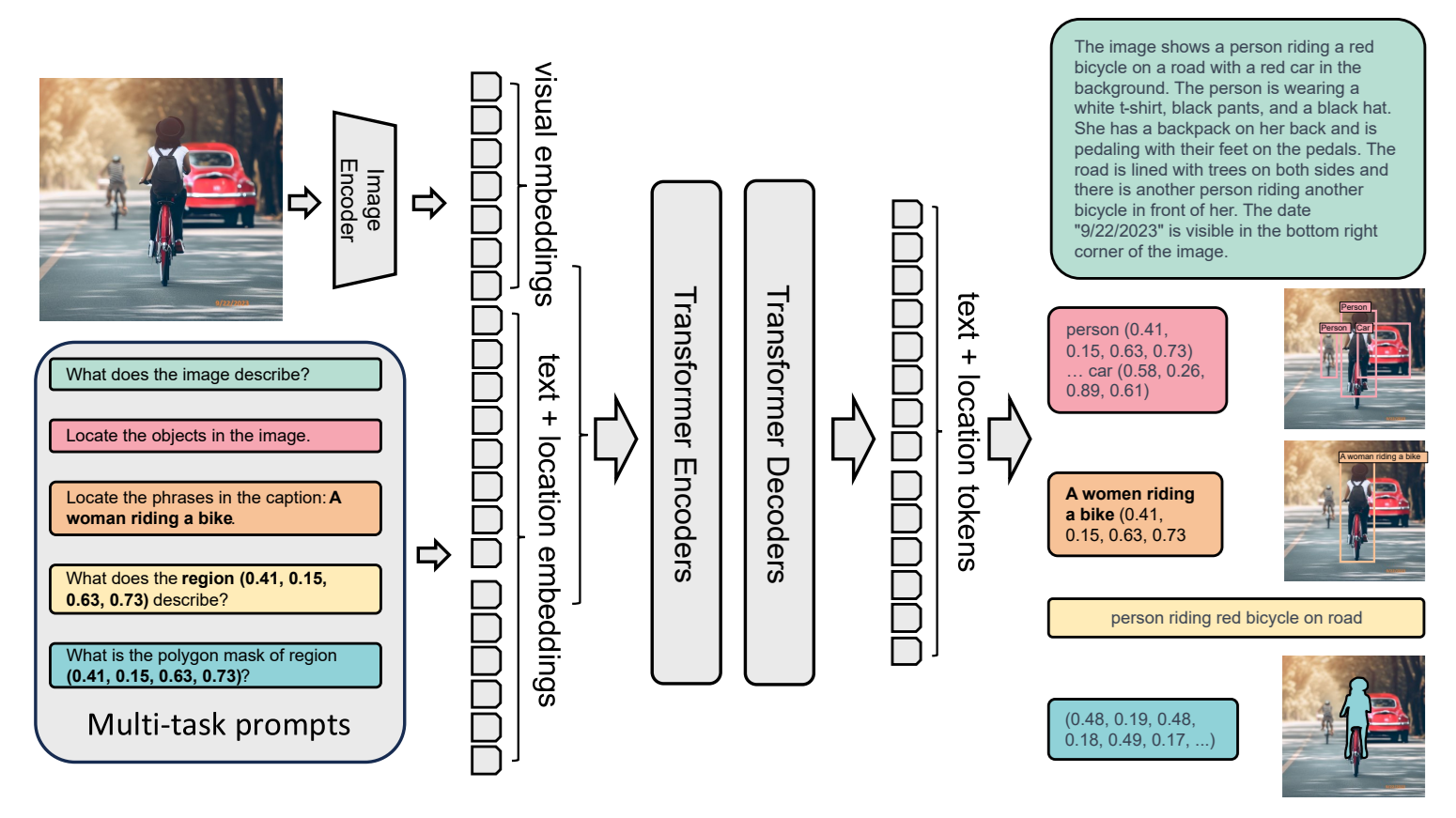
Learn more about VLMs, their capabilities and how to use them with Roboflow in our guides:
- Comprehensive Guide to Vision-Language Models
- Best Local Vision-Language Models
- Florence-2: Vision-language Model
- Object Detection vs Vision-Language Models: When Should You Use Each?
What Is Image Understanding?
Image understanding is about teaching computers to interpret images the way humans do. Image understanding answers questions like, "What's happening in this image?" or "Is this product defective?" Image understanding involves several key capabilities. Let's take a look with some examples from Roboflow Playground below:
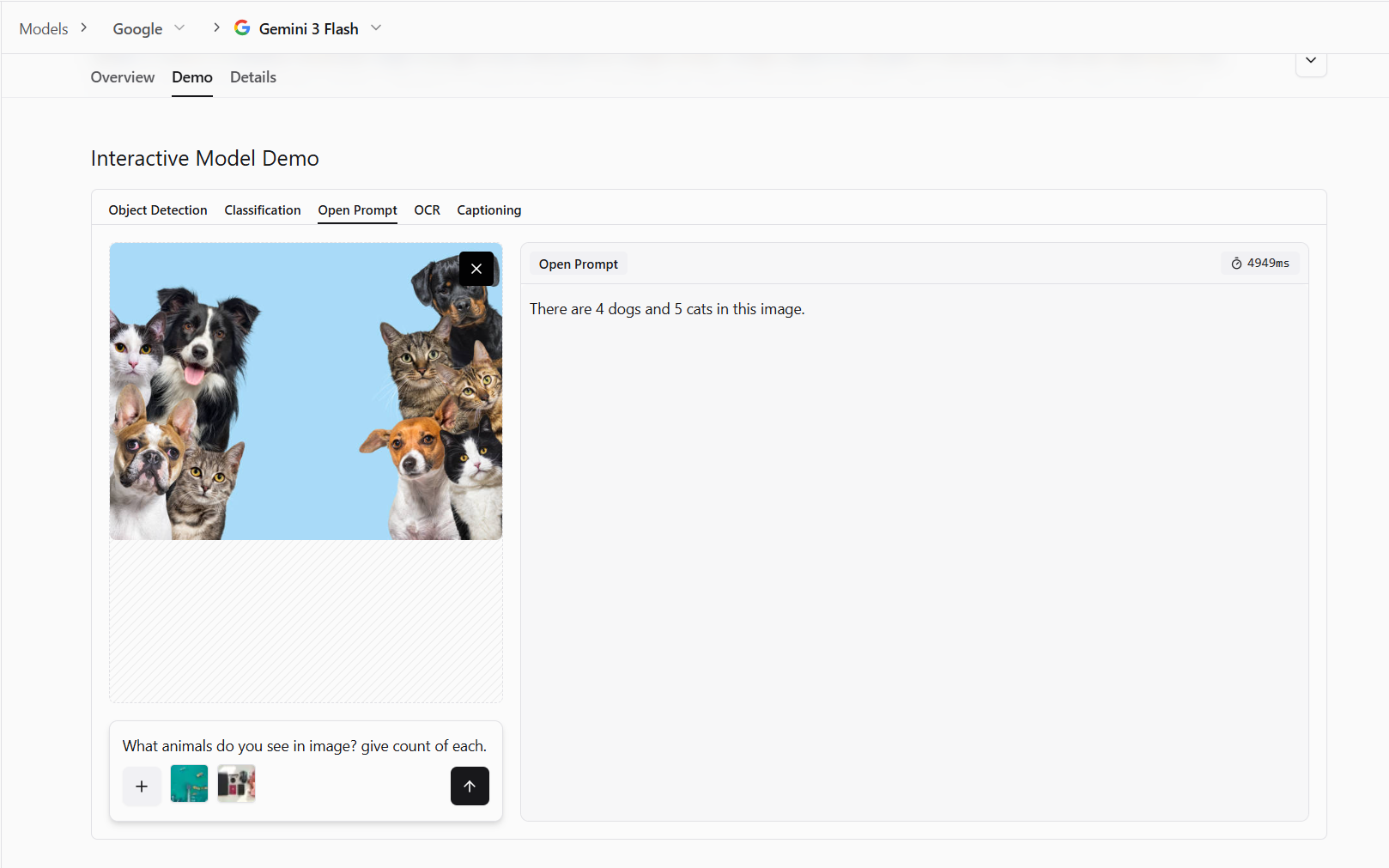
Recognition
This means identifying what's in the image such as objects, people, animals, or scenes. Is that a cat or a dog? Is this a kitchen or a bathroom?
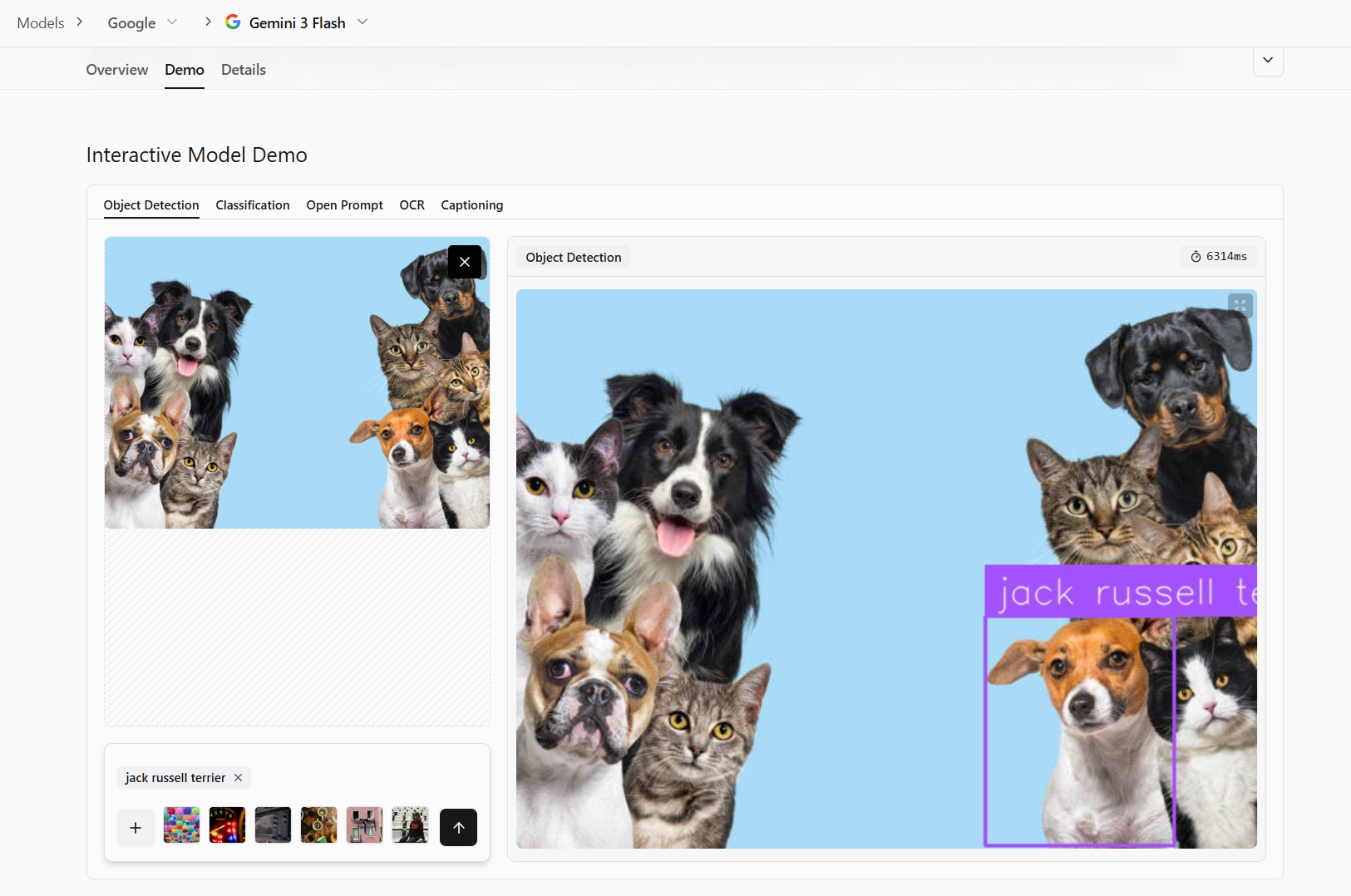
Localization
Localization is the ability to determine where objects or regions are positioned within an image. Instead of only identifying what is present, localization focuses on the spatial placement of those elements. For example, in a street image, localization answers questions such as, “Where exactly is the stop sign?” or “Which part of the image contains the pedestrian?”
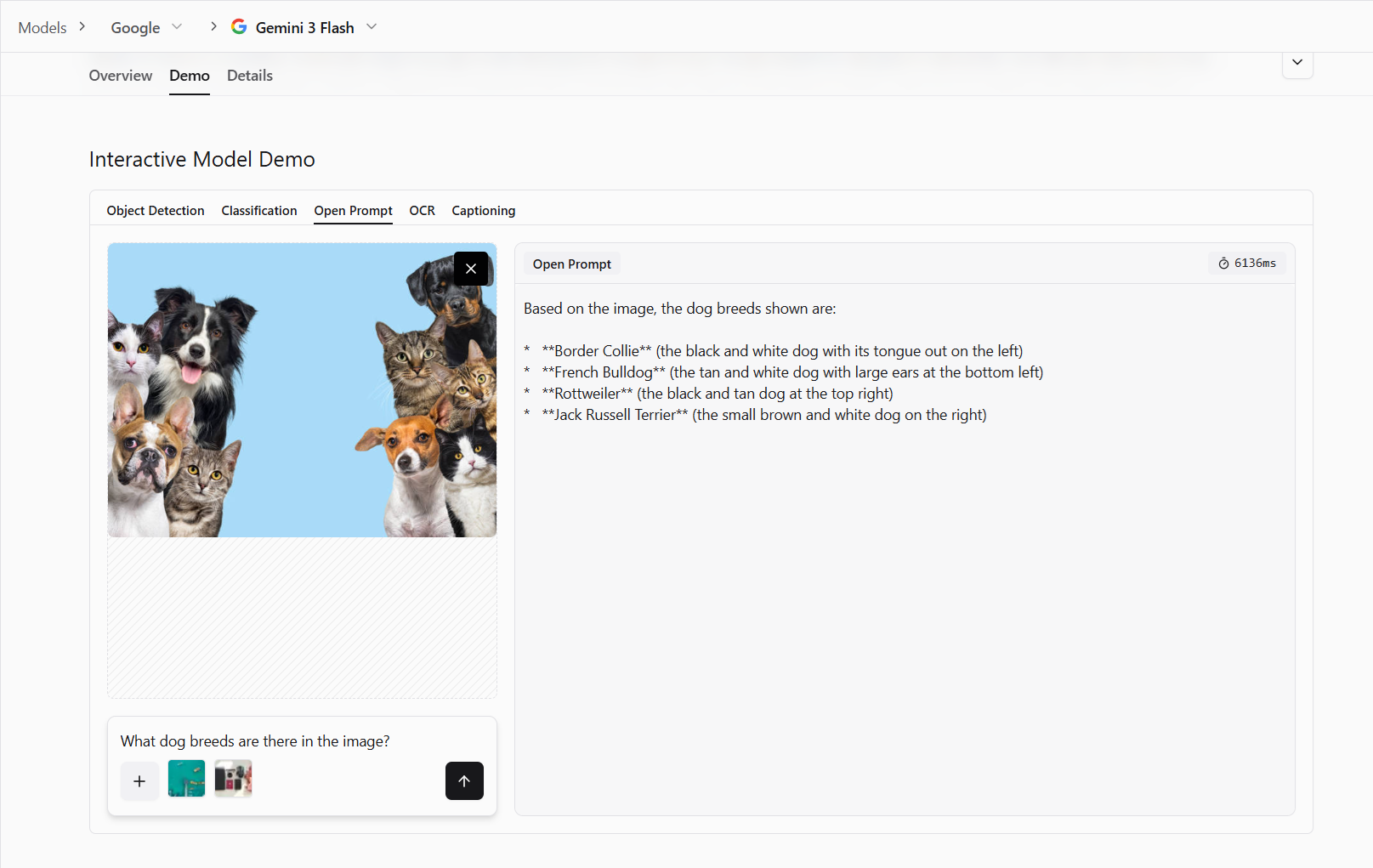
Attribute Analysis
Attribute analysis is the ability to identify and describe the properties of objects in an image. Instead of only recognizing what an object is, attribute analysis focuses on how the object appears. This includes characteristics such as color, size, texture, condition, material, or visible defects.
Relationship Understanding
Relationship understanding is the ability to recognize how objects and people in an image are connected to each other. It goes beyond identifying what is present and focuses on how elements interact. For example, an image may contain a person and an umbrella, but the meaning changes depending on whether the person is holding the umbrella, standing under it, or simply standing nearby.
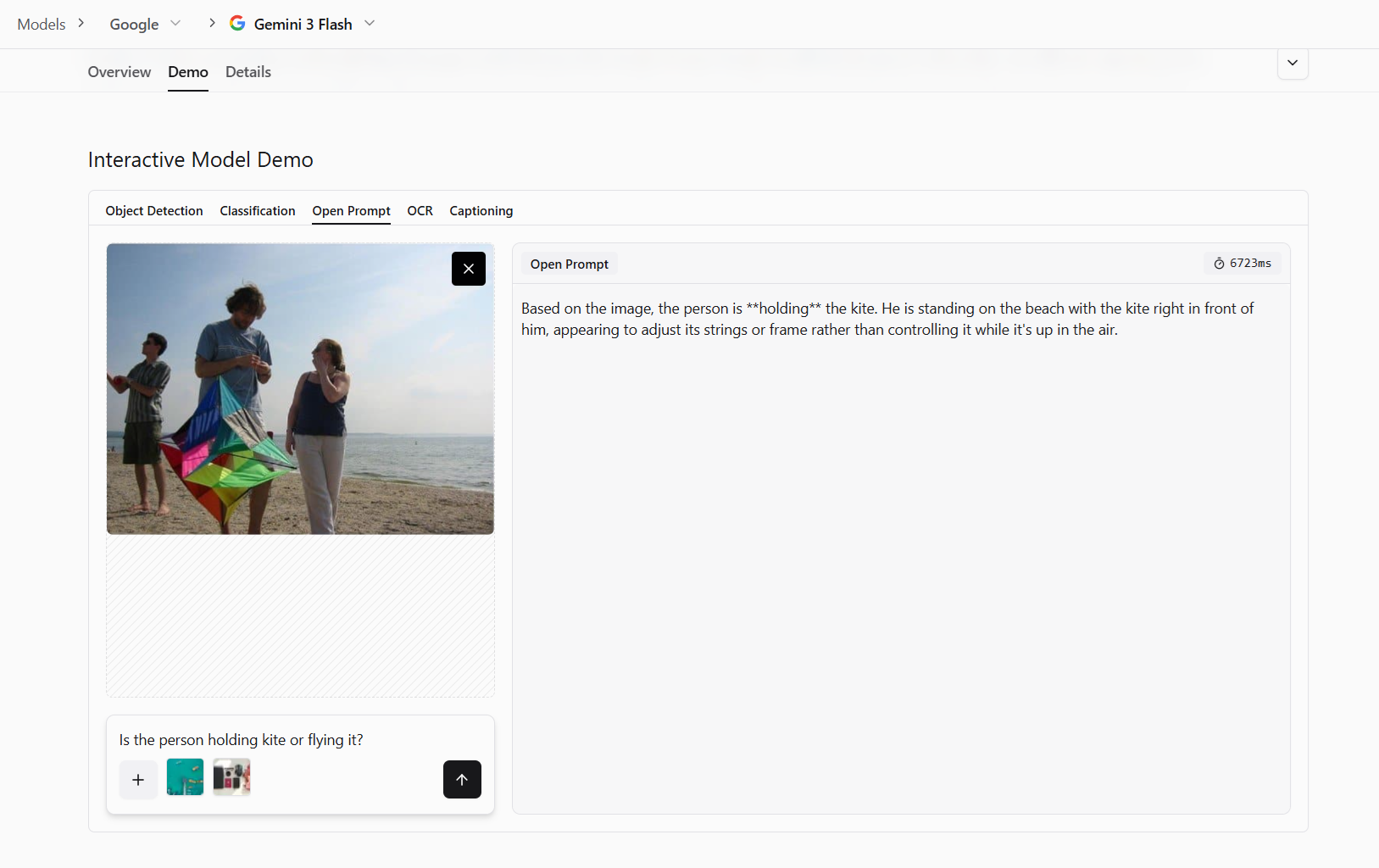
Context Interpretation
Context interpretation is the ability to understand what is happening in an image, not just what objects appear in it. The same objects can mean different things depending on the situation. For example, a stopped machine could indicate a fault, a maintenance task, or a planned pause. Looking at pixels alone is not enough, the surrounding visual clues matter.
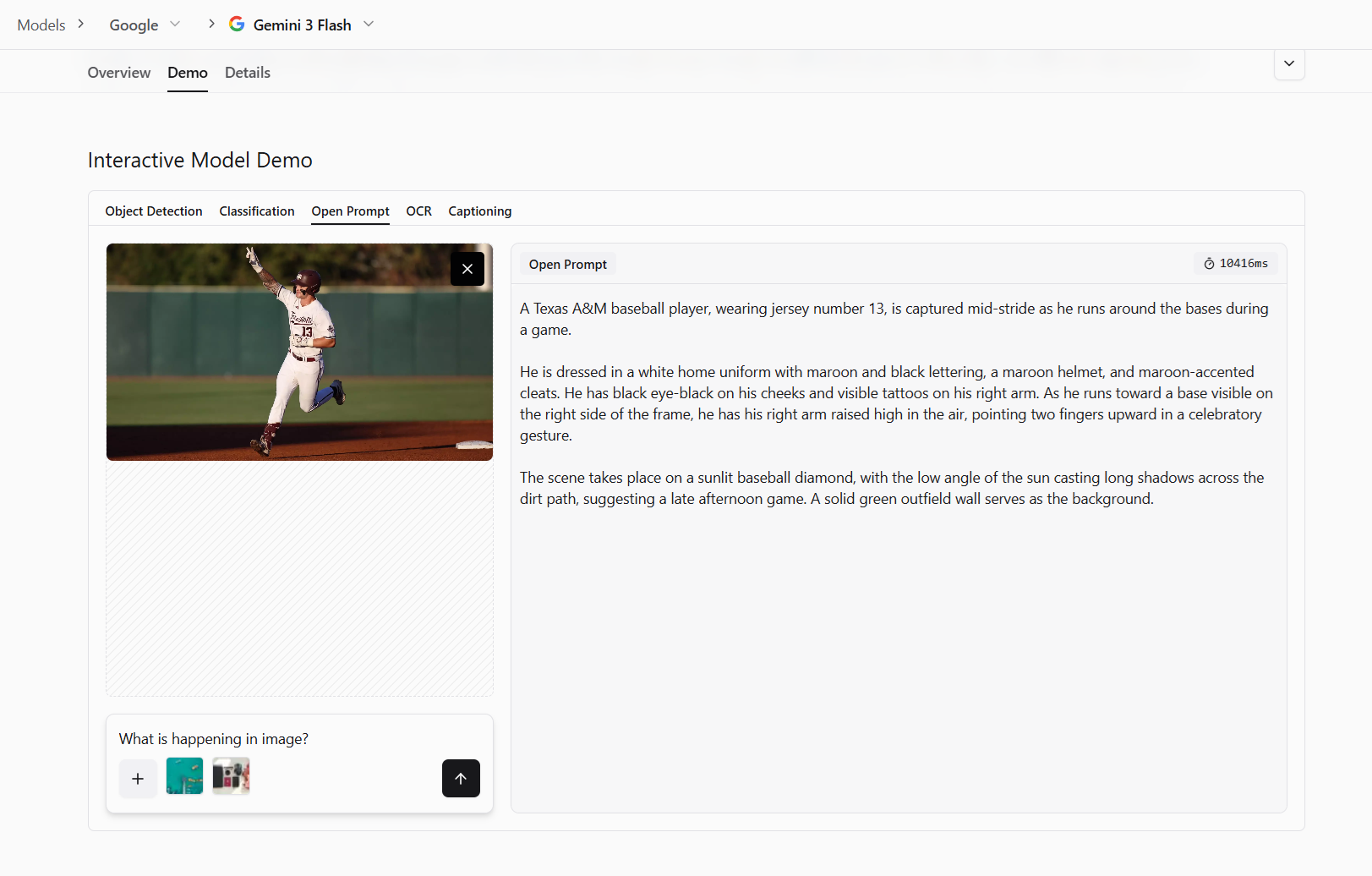
As we have seen in the above examples, the overall goal of image understanding is to bridge the gap between raw pixel data and human-interpretable meaning. This information is very helpful in various tasks such as dataset preparation for model training.
How VLMs Help with Image Understanding During Dataset Preparation
Before training any computer vision model, the most important work happens at the data level. Teams need to understand what is in their images, decide what should be labeled, check for mistakes, and prepare annotations that are consistent and useful. Mistakes made at this stage are expensive to fix later and often show up as poor model performance.
VLMs make this early stage faster and easier. By using natural language to query and reason about images, VLMs help teams understand their datasets before training begins. They can surface missing labels, reveal dataset structure, highlight potential errors, and assist with annotation without requiring a trained model or large labeled datasets. Here we look at four ways VLMs support image understanding during dataset preparation:
Label Discovery
Label discovery is the process of finding out what should be labeled in a dataset before committing to annotation or training. It answers a simple but critical question:
What visual concepts actually matter in this data?
In real projects, datasets often arrive unlabeled, partially labeled, or labeled with assumptions that do not hold up. Important objects, attributes, or conditions may be missing entirely. Traditionally, discovering these labels requires manual inspection which involves scrolling through images, taking notes, and revising label lists multiple times. This is slow and often happens too late, after annotation or model training has already started.
VLMs make label discovery faster by allowing images to be queried using natural language. Instead of defining labels upfront, teams can ask open-ended questions such as “What objects are visible?,” “What stands out in this image?,” or “What type of damage is present?”. For classification tasks, this surfaces candidate categories. For object detection, it reveals what objects and instances appear across scenes. For segmentation, it finds regions or visual patterns that may need pixel-level labels.
Dataset Exploration
Dataset exploration is about understanding the structure and content of a dataset as a whole. Rather than focusing on individual images, it asks broader questions:
- How diverse is this data?
- Are there clusters, gaps, or outliers?
- Does the dataset match the real-world problem we are trying to solve?
Without semantic tools, dataset exploration is limited. Images are stored in folders, searched by filename, or sampled randomly. This makes it difficult to see patterns, identify edge cases, or understand how visual content is distributed especially in large detection and segmentation datasets.
VLMs change this by converting images into semantic embeddings. These embeddings capture visual meaning, allowing images to be grouped, compared, and searched using language. With this approach, teams can explore datasets by similarity, find visually related samples, or search for concepts like “blurry image,” “crowded scene,” or “small objects.”
This works across tasks. For classification datasets, embeddings reveal overlapping or ambiguous classes. For object detection, they help surface scenes with many objects, rare layouts, or unusual backgrounds. For segmentation, they can expose images with complex boundaries or uncommon textures. Importantly, all of this happens before training a task-specific model.
Error Analysis
Error analysis involves finding mistakes and inconsistencies in datasets or model outputs. These errors may include incorrect labels, missing annotations, mislabeled objects, or segmentation masks that do not match visual content. Even small numbers of such issues can significantly harm model performance.
VLMs understand the relationship between images and text: they can be used to check whether visual content aligns with its labels. If an image labeled as one class is semantically closer to a different description, it can be flagged for review. In object detection datasets, VLMs can highlight images where the visible objects do not match the annotated classes. For segmentation datasets, they can help find regions where masks appear inconsistent with the surrounding visual context.
VLMs are not used to automatically declare labels wrong. Instead, they act as fast filters that surface suspicious cases. This reduces the amount of data humans need to inspect and focuses attention where it matters most.
Read more about How to Identify Mislabeled Images in Computer Vision Datasets
Auto-Annotation Assistance
Auto-annotation assistance refers to using models to help humans annotate faster, not to fully replace human judgment. The goal is to reduce repetitive work while keeping people in control of final labels.
VLMs are well suited for this role because they already understand visual concepts through language. For classification, they can suggest likely labels based on text similarity. For object detection and segmentation, they can indicate which objects might be present in an image, such as damaged areas or foreground objects, that annotators should focus on.
What makes VLMs particularly useful here is accessibility. They do not need to be trained on the target dataset before offering value. A team can start with rough suggestions, review them quickly, and refine annotations as needed. This is especially helpful during early dataset creation, when speed matters more than perfect accuracy.
Auto-annotation assistance shifts annotation from a blank-canvas task to a review task. Annotators spend less time drawing or typing from scratch and more time confirming or correcting suggestions. This leads to faster dataset creation without giving up quality or control.
Why Do These Ideas Matter Together?
Label discovery, dataset exploration, error analysis, and auto-annotation assistance are not isolated steps. Together, they form a fast, accessible workflow for understanding visual data before model training begins. VLMs enable this workflow by turning images into something that can be queried, compared, and reasoned about using language.
The key value is not perfect predictions but speed and accessibility of getting insight early, with minimal setup, and without specialized infrastructure. This is why VLMs fit naturally into modern computer vision workflows, not as replacements for trained models, but as tools that make working with images easier, faster, and more approachable.
Read more about how to do auto labeling using VLM in Roboflow:
How to Use Vision-Language Models for Image Understanding Conclusion
Vision-language models turn image understanding into a simple, prompt-driven process. They let teams explore data, discover labels, catch errors, and speed up annotation before any training begins. By making images searchable and understandable through language, VLMs reduce early friction and help teams build better datasets faster, setting a stronger foundation for any computer vision system that follows. Explore VLMs rankings here.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jan 22, 2026). Using Vision-Language Models for Image Understanding. Roboflow Blog: https://blog.roboflow.com/vision-language-models-image-understanding/