
Image segmentation architectures have traditionally been designed for specific tasks, such as semantic segmentation or instance segmentation. However, this approach has several limitations. First, it requires specialized knowledge for each task, which can be time-consuming and expensive to train a model to achieve. Second, developing specialized knowledge for two separate tasks can lead to suboptimal performance, as the architecture is not optimized for the specific task.
In recent years, there has been a trend towards developing universal image segmentation architectures that can be used for a variety of tasks. One such architecture is MaskFormer, which was proposed in 2021. MaskFormer is based on the DETR architecture, which uses a transformer decoder to predict masks for each object in an image.
MaskFormer has been shown to be effective for both semantic segmentation and panoptic segmentation. However, it has not been as successful for instance segmentation. This is because MaskFormer uses a single decoder for all tasks, which is not ideal for instance segmentation, which requires more fine-grained information.
To address the limitations of MaskFormer, Mask2Former has been proposed. Mask2Former has two key innovations: A multi-scale decoder that helps Mask2Former to identify small objects as well as large objects and a masked attention mechanism that allows Mask2Former to focus on the relevant features for each object to prevent the decoder from better handling background noise.
In this blog post, we will explore Mask2Former in detail, examining how it works, where it performs well, and what limitations the model has.
What is Mask2Former?
Mask2Former is a universal image segmentation architecture that was proposed in 2022 by Meta AI Research. It is based on the DETR architecture, which uses a transformer decoder to predict masks for each object in an image.
Mask2Former is a universal architecture that can be used for a variety of tasks, including semantic segmentation, panoptic segmentation, and instance segmentation. It is more accurate than previous image segmentation architectures due to its use of a multi-scale decoder and a masked attention mechanism.
The multi-scale decoder in Mask2Former allows it to attend to both local and global features. This is important for instance segmentation, as it allows Mask2Former to identify small objects as well as large objects.
The masked attention mechanism in Mask2Former restricts the attention of the decoder to the foreground region of each object. This helps Mask2Former to focus on the relevant features for each object, and it also helps to prevent the decoder from attending to background noise.
The masked attention mechanism in Mask2Former works by only allowing the decoder to attend to the foreground region of each object. This is done by masking out the background regions in the attention weights. This helps Mask2Former to focus on the relevant features for each object, and it also helps to prevent the decoder from attending to background noise.
Mask2Former has been shown to be effective for a variety of image segmentation tasks, including semantic segmentation, panoptic segmentation, and instance segmentation. It has achieved state-of-the-art results on several popular datasets, including COCO, ADE20K, and Cityscapes.
Mask2Former Pros and Cons
Let’s talk about some of the advantages and disadvantages with the Mask2Former model. The advantages include:
- Mask2Former is a universal architecture that can be used for a variety of tasks. This means that you don't need to have a separate architecture for each task, which can save time and resources.
- Mask2Former is more accurate than previous image segmentation architectures. This is due to its use of a multi-scale decoder and a masked attention mechanism.
- Mask2Former is more efficient than previous image segmentation architectures. This is due to its use of the transformer decoder, which is a more efficient way to process information than traditional CNNs.
With that said, there are limitations, which include:
- Mask2Former can be computationally expensive to train and deploy. This is due to its use of the transformer decoder, which is a computationally intensive model.
- It can be difficult to fine-tune Mask2Former for specific tasks. This is because it is a universal architecture, and it may not be as well-suited for some tasks as it is for others.
Mask2Former Architecture
To better understand the Mask2Former architecture, it is useful to first describe the architecture from which Mask2Former was inspired> the MaskFormer architecture. The MaskFormer architecture is shown in the below picture.
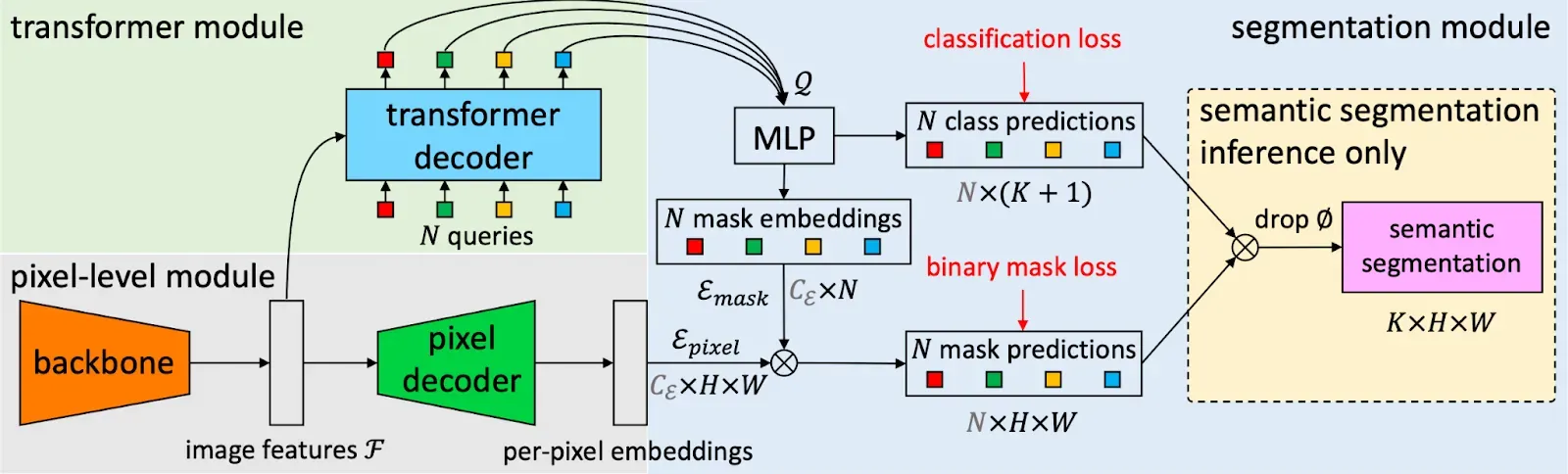
The initial stage of MaskFormer involves the usage of a backbone network to extract image features. These features undergo an upsampling process to generate per-pixel embeddings.
Concurrently, a Transformer Decoder comes into play, crafting per-segment embeddings that encapsulate potential objects within the image.
These embeddings serve as the foundation for predicting class labels and their corresponding mask embeddings. Binary masks are then formed by executing a dot product between pixel and mask embeddings, ultimately yielding potentially overlapping binary masks for each instance of an object.
In scenarios like semantic segmentation, the ultimate prediction materializes by amalgamating binary masks with their associated class predictions.
The pivotal question now emerges: what sets Mask2Former apart, allowing the model to achieve superior performance over MaskFormer?
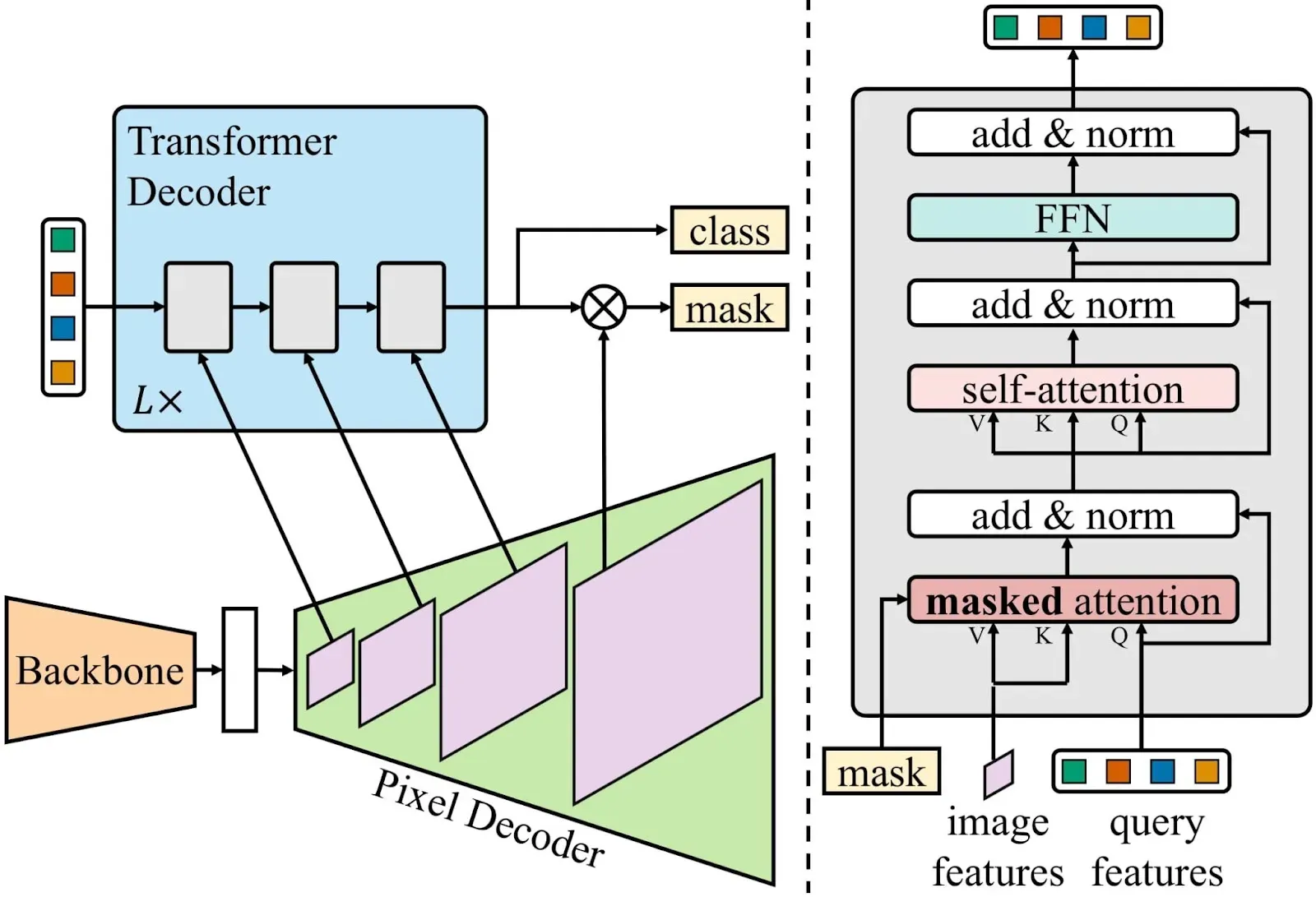
Mask2former employs an architecture identical to that of MaskFormer, marked by two primary distinctions: using mask attention instead of cross attention, and the multi-scale high-resolution features with which the model works.
Using Mask Attention instead of Cross Attention
Mask2Former uses masked attention instead of cross attention to improve its performance for instance segmentation. Cross attention allows the decoder to attend to all pixels in the image, including background pixels. This can be problematic for instance segmentation, as the decoder can be easily distracted by background noise.
Masked attention restricts the attention of the decoder to the foreground region of each object. This helps the decoder to focus on the relevant features for each object, and it also helps to prevent the decoder from attending to background noise.
Moreover, masked attention is more efficient than cross attention, which can reduce the training and inference time of Mask2Former.
Multi-scale high-resolution features
To tackle the challenge of small objects, Mask2Former uses a multi-scale feature representation. This means that it uses features at different scales or resolutions, which allows it to capture both fine-grained details and broader context information.
For optimal processing of these multi-scale features, Mask2Former systematically directs a single scale of the multi-scale feature to an individual Transformer decoder layer during each iteration. Consequently, each Transformer decoder layer process features at a designated scale, such as 1/32, 1/16, or 1/8. This approach allows Mask2Former to significantly enhance its ability to adeptly manage objects of varying sizes.
Mask2Former Performance
In this section, we discuss Mask2Former performance alongside visual demonstrations of MaskFormer's capabilities in panoptic segmentation and instance segmentation on the COCO dataset. We also show semantic segmentation predictions on the ADE20K dataset.
Panoptic Segmentation
Panoptic segmentation on COCO panoptic val2017 with 133 categories. Mask2Former consistently outperforms MaskFormer by a large margin with different backbones on all metrics. The best Mask2Formere model outperforms prior state-of-the-art MaskFormer by 5.1 PQ and K-Net by 3.2 PQ.
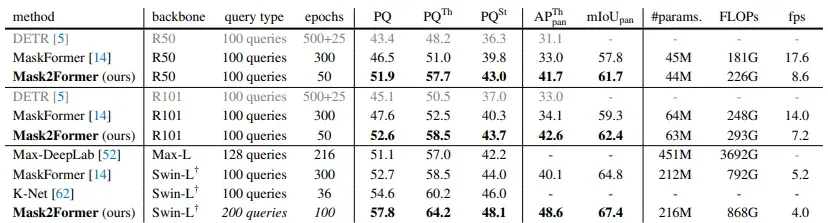
Mask2Former performance on panoptic segmentation. Source

Visualization of panoptic segmentation predictions on the COCO panoptic dataset: Mask2Former with Swin-L backbone which achieves 57.8 PQ on the validation set. First and third columns: ground truth. Second and fourth columns: prediction.
Instance Segmentation
Instance segmentation on COCO val2017 with 80 categories. Mask2Former outperforms strong Mask R-CNN baselines for both AP and APboundary metrics when training with 8x fewer epochs. For a fair comparison, only single-scale inference and models trained using only COCO train2017 set data have been considered.
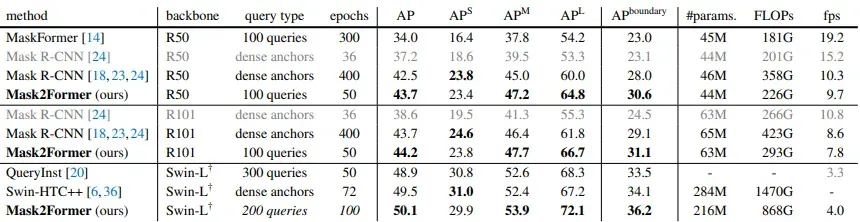
Mask2Former performance on instance segmentation. Source

Visualization of instance segmentation predictions on the COCO dataset: Mask2Former with Swin-L backbone which achieves 50.1 AP on the validation set. First and third columns: ground truth. Second and fourth columns: prediction. We show predictions with confidence scores greater than 0.5.
Semantic Segmentation
Semantic segmentation on ADE20K val with 150 categories. Mask2Former consistently outperforms MaskFormer by a large margin with different backbones (all Mask2Former models use MSDeformAttn as pixel decoder, except Swin-L-FaPN uses FaPN). Both single scale (s.s.) and multi-scale (m.s.) inference results have been reported.
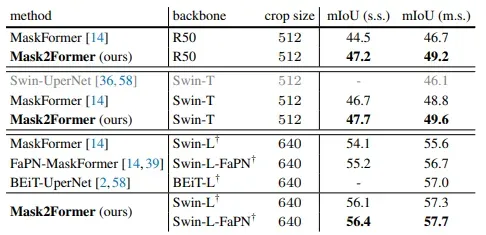
Mask2Former performance on semantic segmentation. Source
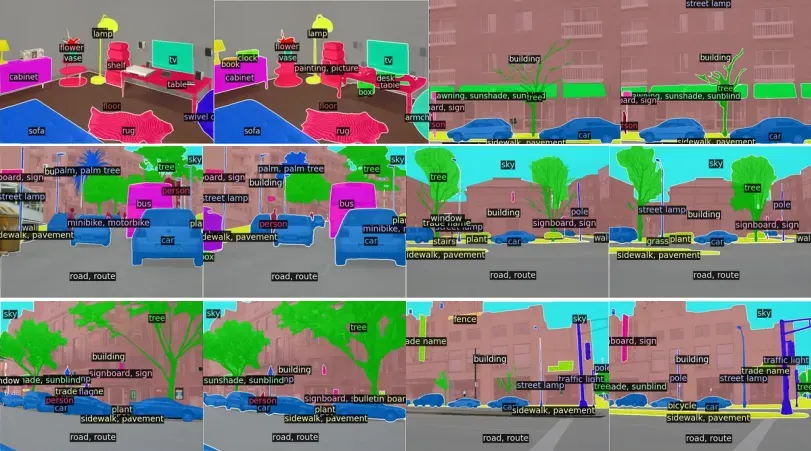
Visualization of semantic segmentation predictions on the ADE20K dataset: Mask2Former with Swin-L backbone which achieves 57.7 mIoU (multi-scale) on the validation set. First and third columns: ground truth. Second and fourth columns: prediction
Conclusion
MaskFormer is an advanced image segmentation model that adopts a unique combination of masked attention and transformer decoder. Through a series of visual demonstrations, we witnessed MaskFormer's outstanding performance in panoptic segmentation, instance segmentation, and semantic segmentation tasks on the COCO and ADE20K datasets.
MaskFormer's masked attention mechanism allows it to efficiently extract local features by focusing on the foreground areas of predicted masks, enabling precise segmentation and enhancing its adaptability across various tasks. Additionally, the implementation of an efficient multi-scale strategy empowers MaskFormer to handle small objects effectively, without compromising computational efficiency.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Aug 28, 2023). What is Mask2Former? The Ultimate Guide.. Roboflow Blog: https://blog.roboflow.com/what-is-mask2former/