
Have you ever wondered how a computer can understand the words on a photo, just like you do? That's where Optical Character Recognition, or OCR, steps in. OCR takes the text you see in images – be it from a book, a receipt, or an old letter – and turns it into something your computer can read, edit, and search.
OCR finds widespread applications in tasks such as automated data entry, document digitization, text extraction from images, invoice processing, form recognition, and enhancing accessibility for visually impaired individuals.
Let's explore the fundamentals of OCR, understanding its workings, the challenges it addresses, and why it remains a crucial component of present and future technology.
What Is Optical Character Recognition?
Optical Character Recognition (OCR) involves converting both handwritten and typed text from various sources, including images, videos, and scanned documents like PDFs, into a digitally editable format.
The output from OCR can be used by a computer to make decisions. Common use cases of OCR include:
Using OCR to read product identifiers on an assembly line. When each identifier is read, a piece of software can update an inventory tracking system to note the package with the given identifier has arrived.
Using OCR for scanned document recognition. This involves scanning printed documents, after which OCR software converts them into searchable and editable text. This method is widely employed to automate the handling of legal documents, extract data from bank statements and invoices, and streamline tasks like invoice processing and financial record-keeping.
Using OCR for “scene text recognition”, wherein an OCR system recognizes text from natural scenes, such as street signs, storefronts, or license plates.
Using OCR for alphanumeric, printed text, such as text that was written on a typewriter, or text that was printed out. But, you can also use OCR on handwriting. This usually involves using a separate system due to the differences in handwriting compared to printed text.

How Optical Character Recognition Works
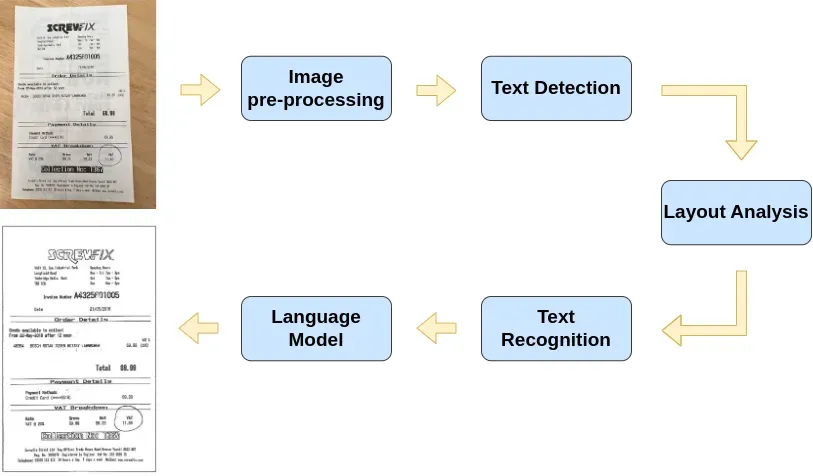
Let's discuss the typical steps modern OCR software uses to read text:
- Image pre-processing: After an image has been collected, the image undergoes pre-processing to enhance image quality, improving recognition. Pre-processing may involve resizing, contrast enhancement, binarization, noise reduction, and other techniques.
- Text Detection: Using a specialized deep-learning model trained on large datasets of images and text, the computer vision model detects regions in the input image that likely contain text. This process is usually a crucial step.
- Layout Analysis: After detecting text regions, the computer vision model conducts layout analysis to determine the structure and order of the text in the image. This step ensures the preservation of context and organizes the output for readability, but is not run by all OCR systems.
- Text Recognition: Detected text regions pass through a deep learning-based text recognition model, utilizing a combination of convolutional neural networks (CNNs) and recurrent neural networks (RNNs). This model recognizes individual characters and words in the input image, converting them into machine-readable text.
- Language Model: The final output undergoes post-processing to remove noise, correct spelling mistakes, and enhance overall accuracy. The predicted sequence of characters may contain errors, especially for long or uncommon words. Language models, acting as word processors, refine the output by predicting the probability of a sequence of words based on the input image. Statistical models and advanced methods, including deep learning, may be employed for this purpose.
Having acquired an understanding of how OCR operates, let's examine its algorithms and investigate their operational mechanisms, covering the old and the new.
Traditional Approaches to OCR
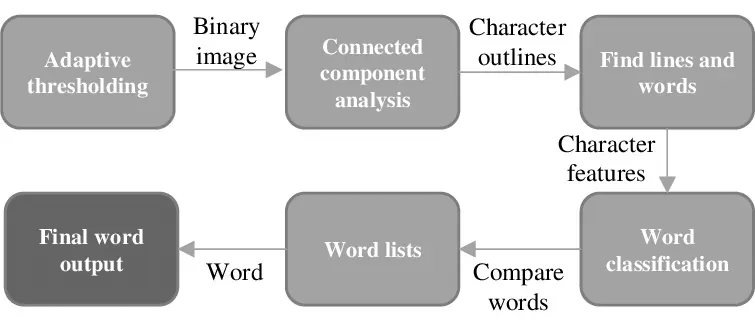
The first OCR algorithms rooted in image processing were typically rule-based systems. One well-known OCR that uses this approach is Tesseract. These systems relied on manually crafted features and heuristic rules to identify characters within images. The approach involved segmenting characters into individual units and applying a set of rules for character classification.
However, the accuracy and performance of these algorithms were often constrained due to the intricate process of developing and fine-tuning the necessary handcrafted features and rules for effective recognition.
Tesseract
Tesseract, an open-source optical character recognition engine, originated at Hewlett-Packard Laboratories in the 1980s and subsequently became open-source in 2005.
Initially designed to recognize English text exclusively, Tesseract has evolved into a versatile OCR engine. Working from traditional image processing principles, which involves manual logic unlike the deep learning processes in modern systems, Tesseract analyzes images to identify patterns for character recognition.
First, Tesseract preprocesses the image to enhance input quality, a step which encompasses tasks like contrast improvement and noise removal. Following this, Tesseract employs feature extraction techniques, including edge detection and pattern recognition, to identify and recognize characters.
Deep Learning Approaches to Optical Character Recognition
With the rise of deep learning, the integration of neural networks into OCR systems has gained substantial popularity. In particular, deep learning methodologies like Convolutional Neural Networks and Long Short-Term Memory networks are leveraged, for precise text recognition. Neural networks regularly achieve better performance than traditional OCR techniques.
In recent years, there has also been a surge in novel approaches that leverage pre-trained image and text Transformers, a deep learning architecture. Transformers are ushering in a new era of end-to-end optical word recognition.
PaddleOCR
Paddle OCR is an open-source engine developed by Baidu's PaddlePaddle team. Leveraging deep learning techniques, including CNNs and recurrent neural networks, Paddle OCR excels in accurate text recognition. It comprises two key components: the detector and the extractor. The detector is tasked with pinpointing text within an image or document. It employs various algorithms, such as EAST (Efficient and Accurate Scene Text) or DB (Differentiable Binarization) detectors, to identify text regions.
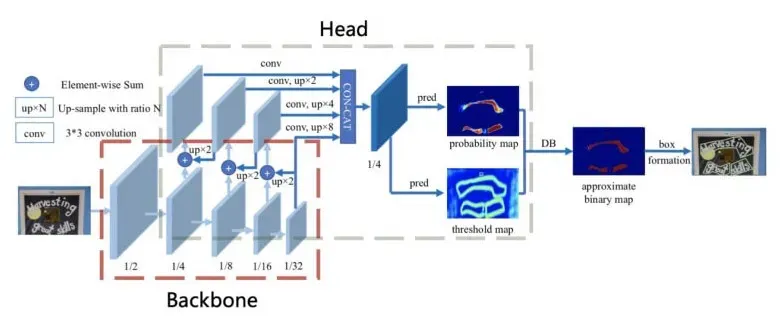
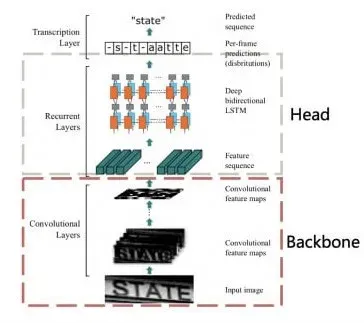
After the detector locates the text, the extractor comes into play, retrieving the text from the image. It employs a blend of Convolutional Neural Networks and Recurrent Neural Networks for precise text recognition. CNNs are utilized to extract features from the text, while RNNs play a crucial role in recognizing the sequence of characters.
Paddle OCR stands out for its remarkable speed, making it among the swiftest OCR engines. Its efficiency is attributed to the utilization of parallel computing and GPU acceleration. This feature renders it particularly suitable for extensive OCR tasks, including document scanning and image recognition. Moreover, its adaptability shines through as it can be tailored and fine-tuned for specific tasks and datasets, enhancing its versatility and robustness in various OCR applications.
TrOCR
Transformer-based Optical Character Recognition (TrOCR) is one of many transformer-based OCR models. In contrast to traditional OCR systems, TrOCR adopts a methodology where both input image processing and the generation of corresponding text output occur within a single model.
The encoder segment of TrOCR employs a transformer-based architecture to handle the input image, segmenting it into a grid of patches and extracting visual features from each patch. Simultaneously, the decoder component utilizes a transformer-based model to produce the relevant text output, incorporating the visual features extracted from the image.
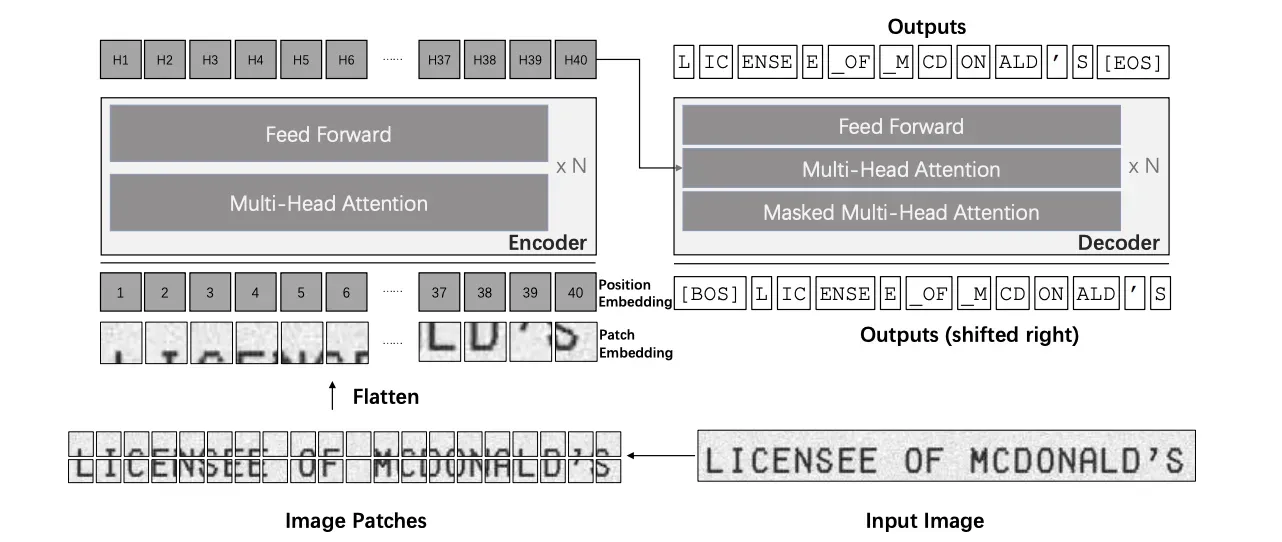
This comprehensive and transformer-based methodology empowers TrOCR to attain strong performance across diverse OCR benchmarks, establishing the model as a highly dependable and effective tool for text recognition tasks.
Advantages of Modern OCR Techniques
One of the primary advantages of OCR is its ability to automate the data entry process. Traditional manual data entry is not only time-consuming but also prone to errors. OCR technology streamlines this process by automatically extracting text from images or scanned documents, eliminating the need for human input. This automation significantly reduces the time required for tasks such as transcribing printed or handwritten text into digital formats.
In addition, OCR facilitates the digitization of documents, leading to improved efficiency in document management. By converting physical documents into digital formats, OCR enables easy storage, retrieval, and organization of information.
Digital documents are more accessible and can be quickly searched, eliminating the need for manual sorting through paper files. This advantage is particularly crucial in business settings where quick access to relevant information is essential.
Limitations of Modern OCR Techniques
OCR systems, while proficient in recognizing printed text, often face challenges when it comes to accurately interpreting handwritten text. Handwriting is inherently diverse, varying in styles, shapes, and legibility. Unlike printed text, which follows standardized fonts and structures, handwritten text can exhibit significant variability, making it difficult for OCR algorithms to consistently and accurately recognize every nuance.
This limitation is particularly pronounced in scenarios where the handwriting is cursive, unconventional, or poorly formed. Overcoming this challenge requires more advanced techniques, such as integrating machine learning models specifically trained on diverse handwritten datasets.
Furthermore, OCR systems can be sensitive to the quality of the input image and may struggle with images that have poor resolution, low contrast, or significant noise. Additionally, documents with complex layouts, multiple columns, or irregular text arrangements pose challenges for traditional OCR methods.
The image preprocessing steps performed by OCR engines, such as Tesseract, are crucial for improving recognition accuracy, but they may not always suffice for images with inherent complexities. Complex layouts can disrupt the OCR's ability to accurately segment text regions and extract meaningful content, leading to errors in character recognition.
To mitigate these issues, additional preprocessing techniques or more advanced OCR methods may be necessary, adding complexity to the implementation process.
Optical Character Recognition
Optical Character Recognition (OCR) is the extraction of text from scanned documents or images, converting it into machine-readable data to enhance information accessibility.
OCR can reduce the time and resources needed for managing non-searchable or elusive data, eliminating manual data input, reducing errors, and boosting productivity. However, challenges such as handwritten text recognition and sensitivity to image quality persist in OCR systems.
Despite these challenges, OCR remains pivotal in present and future technology, automating data entry, improving document management, and enhancing accessibility. Its adaptability and multilingual support position OCR as a fundamental component in shaping technological advancements.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Nov 21, 2023). What Is Optical Character Recognition (OCR)?. Roboflow Blog: https://blog.roboflow.com/what-is-optical-character-recognition-ocr/