
We can’t capture a photo of what every object looks like in the real world. (Trying to find an image to prove the prior sentence is a fun paradox!) Thus, when we create computer vision models, we need them to learn what general representations of objects look like. This is where data augmentation comes into play.
Data augmentation is the practice of using data we already have to create new training examples to help our machine learning models generalize better.
Random Crop Data Augmentation
Random crop is a data augmentation technique wherein we create a random subset of an original image. This helps our model generalize better because the object(s) of interest we want our models to learn are not always wholly visible in the image or the same scale in our training data.
This helps a model learn that objects:
- may appear partially in frame
- may appear at different distances or scales
- may not always be cleanly centered
- may be occluded or cut off in natural ways
For example, imagine we are creating a deep learning model that recognizes raccoons in a yard. We may have a camera streaming images to an object detection model reporting when a raccoon is visible. The animals are not always completely in frame, nor are they constantly the same distance from the camera. A random crop is a great choice as an augmentation technique in this case.
More generally, most mobile app computer vision model examples may benefit from random crop data augmentation. A user may hold their phone at varying distances from the objects we seek to recognize, and those objects are not always completely in frame.
Implementing Random Crop
There are many variations of random crop that we can perform. Those implementations also depend on type of computer vision problem we’re solving.
Consider: How much of the image do we seek to crop? Do we want the same sized crop every time? If we’re cropping images that contain bounding boxes, what area of a bounding box must be present in the resulting image for the bounding box to still be valid?
In the most basic case, a classification problem where we don’t need to worry about bounding boxes or segmentation annotations, we’re creating a random subset of an image. We’d set the desired output area of our crop, determine random output coordinates, and perform the crop.
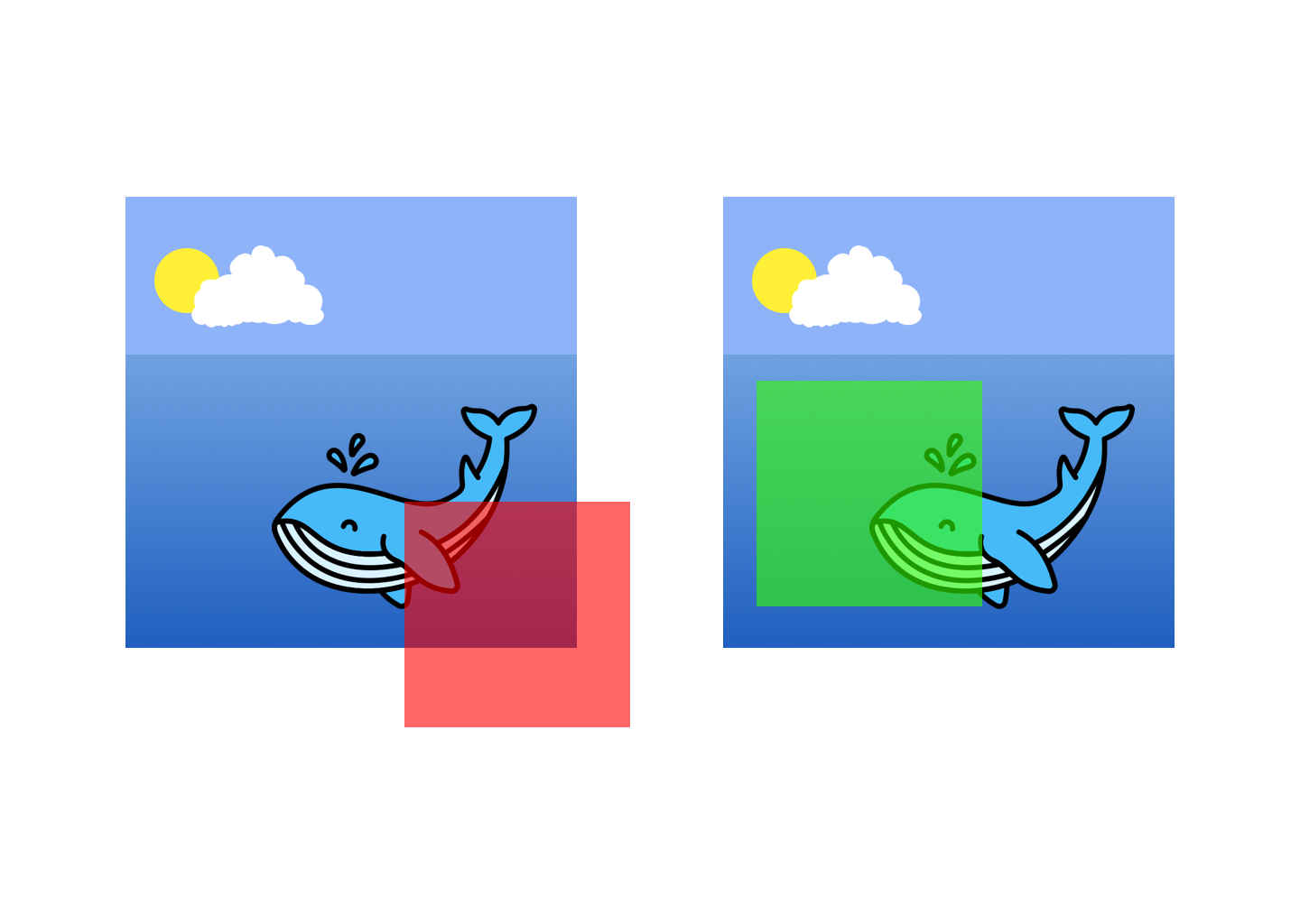
There is one wrinkle even in this simple example: our randomly determined (X,Y) coordinates defining our output image center cannot truly be any position on our input image. The output cropped image needs to be a wholly subset of the original image. If we randomly choose center coordinates that are on the edge of the input image, our output will require padding to be our truly desired dimensions.
Many frameworks like TensorFlow and PyTorch include open source implementations of random crop. (Notably, Keras does not currently have an implementation for random crop.) For example, to leverage TensorFlow, we would write a Python function like the one below for RGB images:
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[NEW_IMG_HEIGHT, NEW_IMG_WIDTH, 3])
return cropped_imageIf we aim to apply a random crop to an object detection problem, we must also handle updating the bounding box. Specifically, if our newly cropped image contains an annotation that is completely outside the frame, we should drop that annotation. If the annotation is partially in frame, we need to crop the annotation to line up with the newly created edge of the frame.
This is exactly how Roboflow implements a random crop when also resizing an image. Returning to our raccoon example, we may have an image like this:

In Roboflow, if we select random crop with 50 percent (to keep 50 percent of the original image pixels) plus a resize to 416x416, we get this result:

Note that, in this case, the original raccoon bounding box needed to be cropped to still be a valid annotation. Annotations that extend outside of frame throw an error in model training.
If you want to see this exact version of the raccoon dataset including the resize settings selected, it is publicly available here. (Note: you can fork this raccoon dataset and modify your own image preprocessing and augmentation steps.)
If we aim to apply a crop for semantic segmentation, we need to proportionally handle the mask the same way we handle the image (X,Y) adjustments. GitHub user wouterdewinter provided an example like the below:
def random_crop(img, mask, width, height):
assert img.shape[0] >= height
assert img.shape[1] >= width
assert img.shape[0] == mask.shape[0]
assert img.shape[1] == mask.shape[1]
x = random.randint(0, img.shape[1] - width)
y = random.randint(0, img.shape[0] - height)
img = img[y:y+height, x:x+width]
mask = mask[y:y+height, x:x+width]
return img, maskWhat’s Next
Research is being conducted to create new data out of cropped together images from multiclass problems. Random Image Cropping and Patching (RICAP), for example, combines pieces of various input images into a single image, and also gives an image a mix of class labels, which results in advantages similar to label smoothing.

At Roboflow, we’re actively experimenting with methods like these as well so you can have a single place that is model-building agnostic for image preprocessing and augmentation.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Feb 21, 2020). Why and How to Implement Random Crop Data Augmentation. Roboflow Blog: https://blog.roboflow.com/why-and-how-to-implement-random-crop-data-augmentation/