
AI has undergone a remarkable transformation with the rise of powerful multimodal models. Multimodal models are complex systems that can understand, analyze, and generate content spanning text, images, and video.
These models are also highly regarded for performing computer vision related tasks such as OCR and visual question answering. In this guide, we explore the best multimodal models as of early 2026, examining their architecture, innovations, and what they excel at.
Best Multimodal Models Criteria
Since these models are heavily used in computer vision, Roboflow provides valuable insights on Playground comparing and ranking various multimodal models:
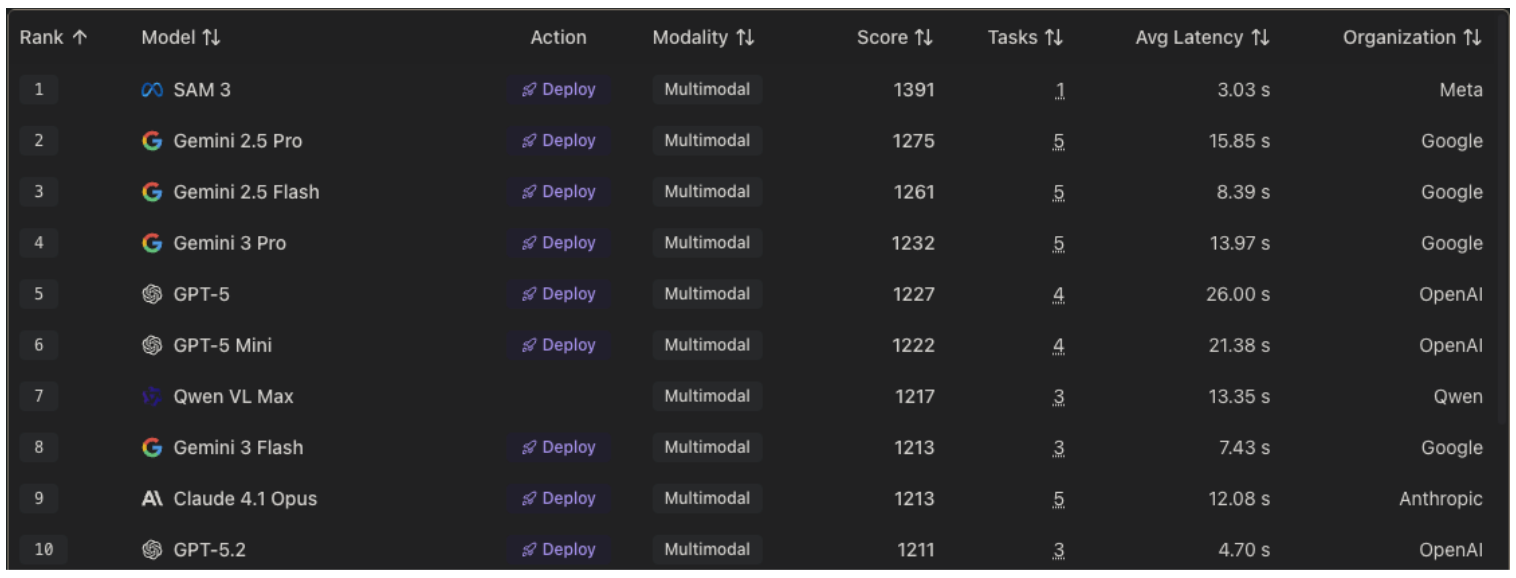
While these rankings are helpful for figuring out and prioritizing things like performance and latency, the following list was evaluated with a specific criteria in mind:
- For starters, they should be able to effectively integrate information from multiple modalities (text, image, video, audio), enabling most common computer vision tasks.
- Second they should support practical deployment with reasonable inference times, manageable computational requirements, and availability through accessible APIs or frameworks.
- Strong multimodal models should also excel at multiple downstream tasks without extensive fine-tuning, demonstrating generalizable representations applicable across varied use cases.
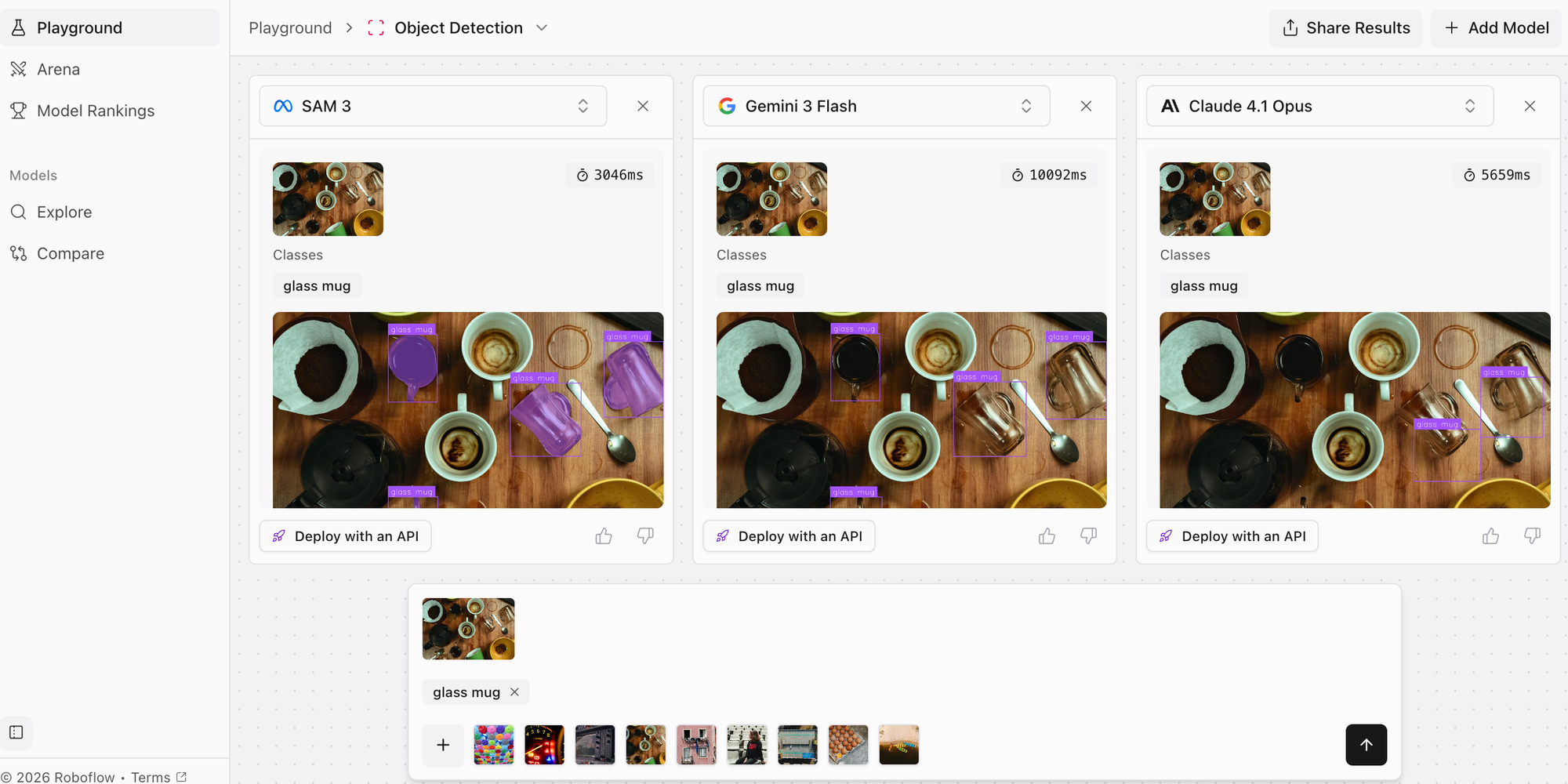
Best Multimodal Models Ranking
Explore the top models that can "see," reason, and deploy in production today.
1. Segment Anything Model 3 (SAM 3)
Specialized Multimodal Vision Model, Primary strength: Zero-shot Segmentation
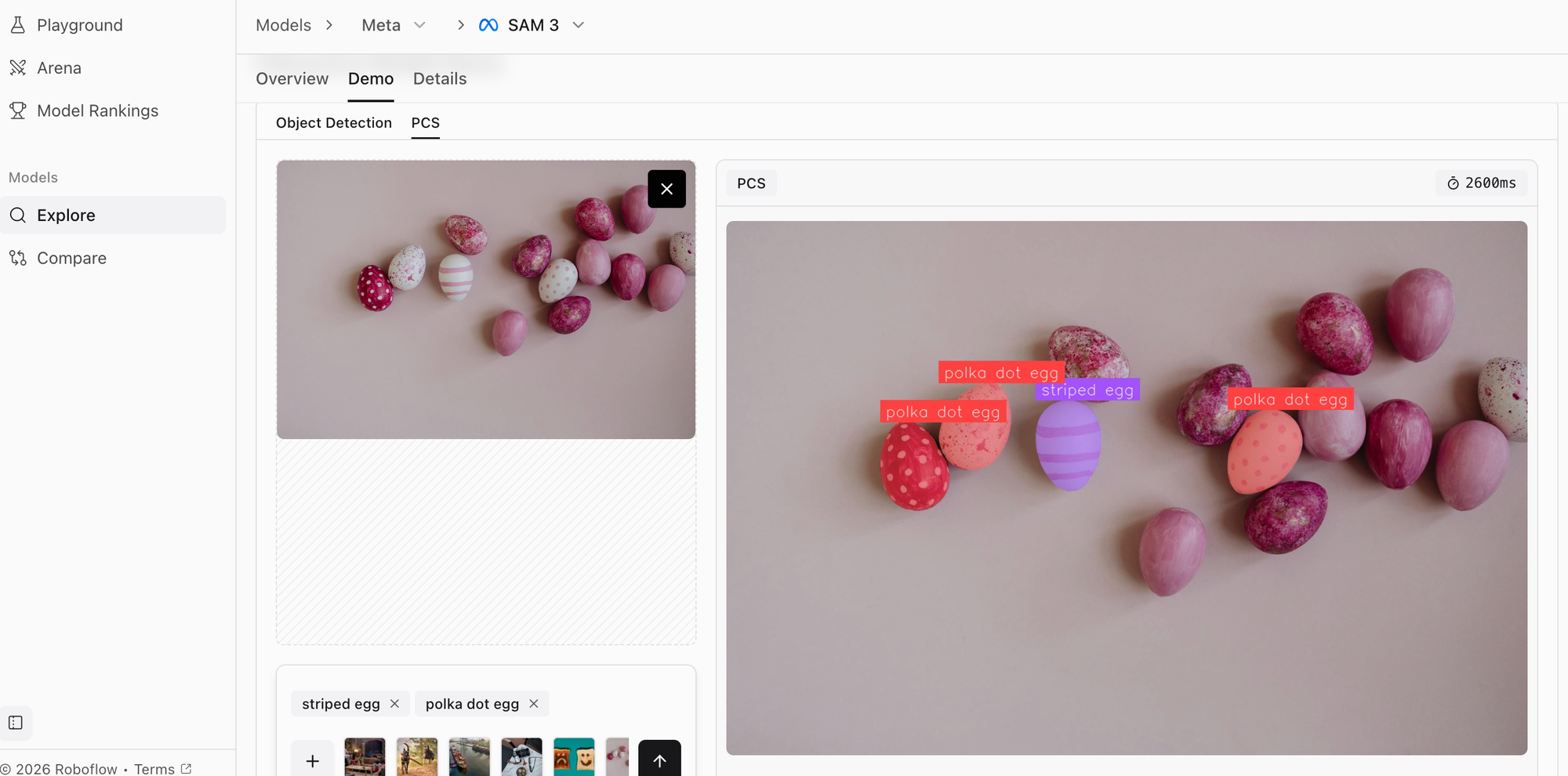
SAM 3, released by Meta AI in February 2025, dominates Roboflow's AI Vision Model Rankings with a score of 1391. The model accepts multimodal prompts - text descriptions, bounding boxes, points, or rough masks - and generates precise segmentation masks in response.
What sets SAM 3 apart is its zero-shot transfer capability. The model can segment objects it has never seen during training, making it incredibly versatile across diverse computer vision applications from medical imaging to autonomous vehicles.
The architecture combines three key components: a Vision Transformer (ViT) image encoder that processes images into rich embeddings, a prompt encoder that handles multiple input types, and a lightweight mask decoder using cross-attention to generate segmentation masks. Key innovations include multimodal prompt fusion through advanced cross-attention layers and hierarchical mask prediction at multiple resolutions.
SAM 3 achieves its top ranking with an average latency of just 3.03 seconds while excelling at handling occlusions and complex scenes. The model's memory-efficient design enables real-time inference even on edge devices, and extended temporal modeling allows consistent segmentation across video frames with minimal drift.
SAM 3 is ideal for interactive annotation tools, creating high-quality training datasets, medical image analysis, and video editing applications. Its ability to segment objects from natural language descriptions has proven particularly valuable for building intuitive AI-powered annotation platforms.
2. Gemini 2.5 and Gemini 3
Generalist Multimodal Models, Primary Strength: Massive Context & Reasoning
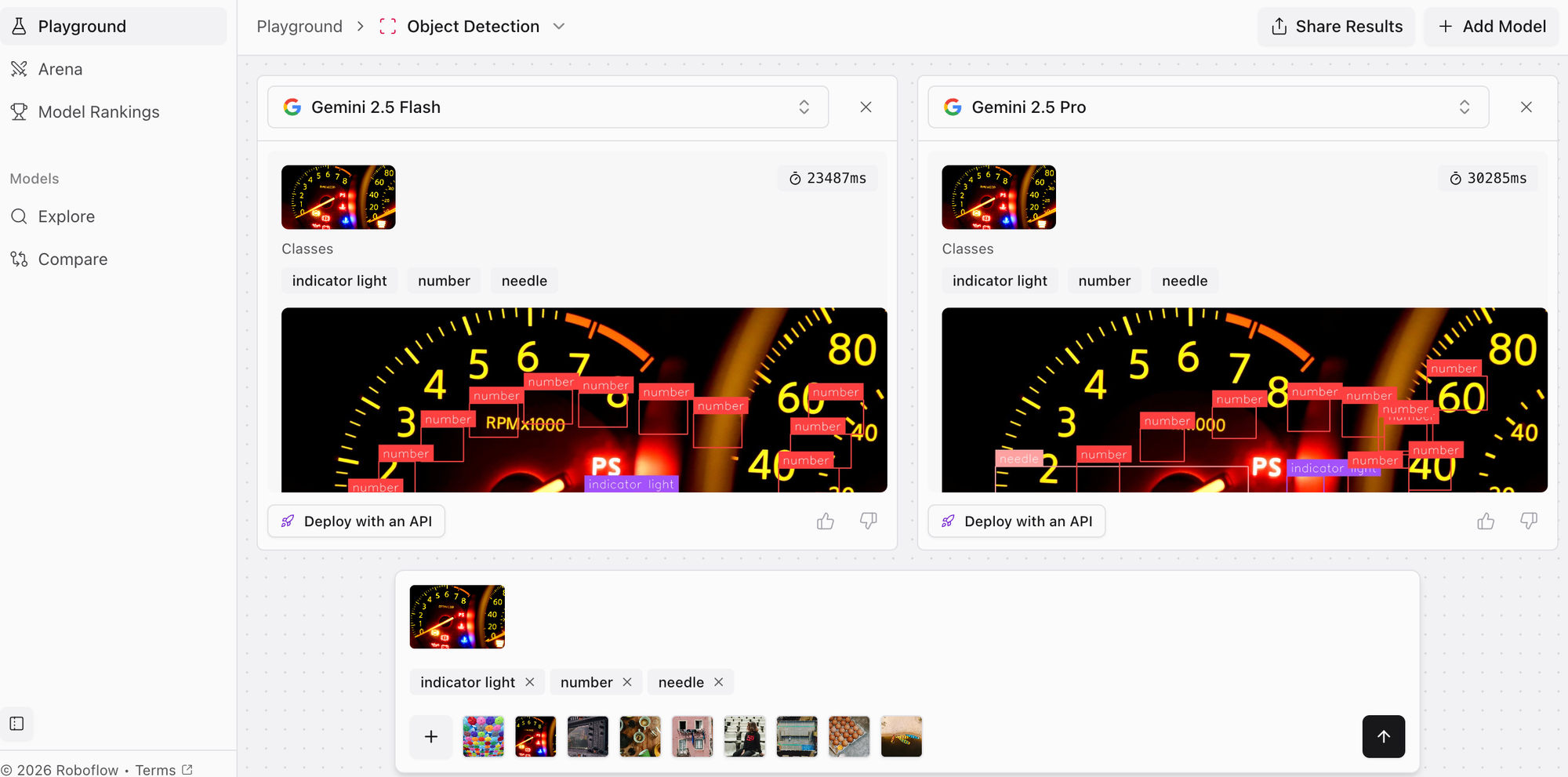
Google's Gemini family ranks second through fourth in Roboflow's multimodal rankings, with Gemini 2.5 Pro (1275 score, 15.85s), Gemini 2.5 Flash (1261 score, 8.39s), and Gemini 3 Pro (1232 score, 13.97s) all delivering exceptional performance. These models process text, image, video, and audio through a unified transformer architecture.
The Gemini lineup offers strategic variants: Pro models maximize capability with dense architectures, while Flash models use sparse Mixture-of-Experts (MoE) for 2x faster inference. Gemini 3 represents the latest generation with architectural refinements, while 2.5 Pro still leads in raw performance. All variants support Google's signature extended context windows, with Pro models handling up to 2 million tokens.
The architecture employs hierarchical tokenization optimized for each modality and cross-modal attention layers that ground textual concepts in visual content. Key innovations include native code execution that can generate and debug code in real-time, enhanced diagram understanding for technical documents, and RLHF post-training that improves response quality and safety.
Gemini achieves 70.2% accuracy on the MMMU benchmark and supports 100+ languages with strong cross-lingual transfer. The Flash variants maintain competitive performance while delivering inference speeds under 8.5 seconds, making them ideal for production deployments requiring both quality and throughput.
Gemini excels in document understanding and analysis, video content moderation, educational tutoring systems, code generation with visual context, and medical image interpretation. The massive context window makes it invaluable for analyzing research papers, legal documents, and scientific data that would overwhelm competing models.
3. GPT-5
Generalist Multimodal Model, Primary Strength: Complex Problem Solving
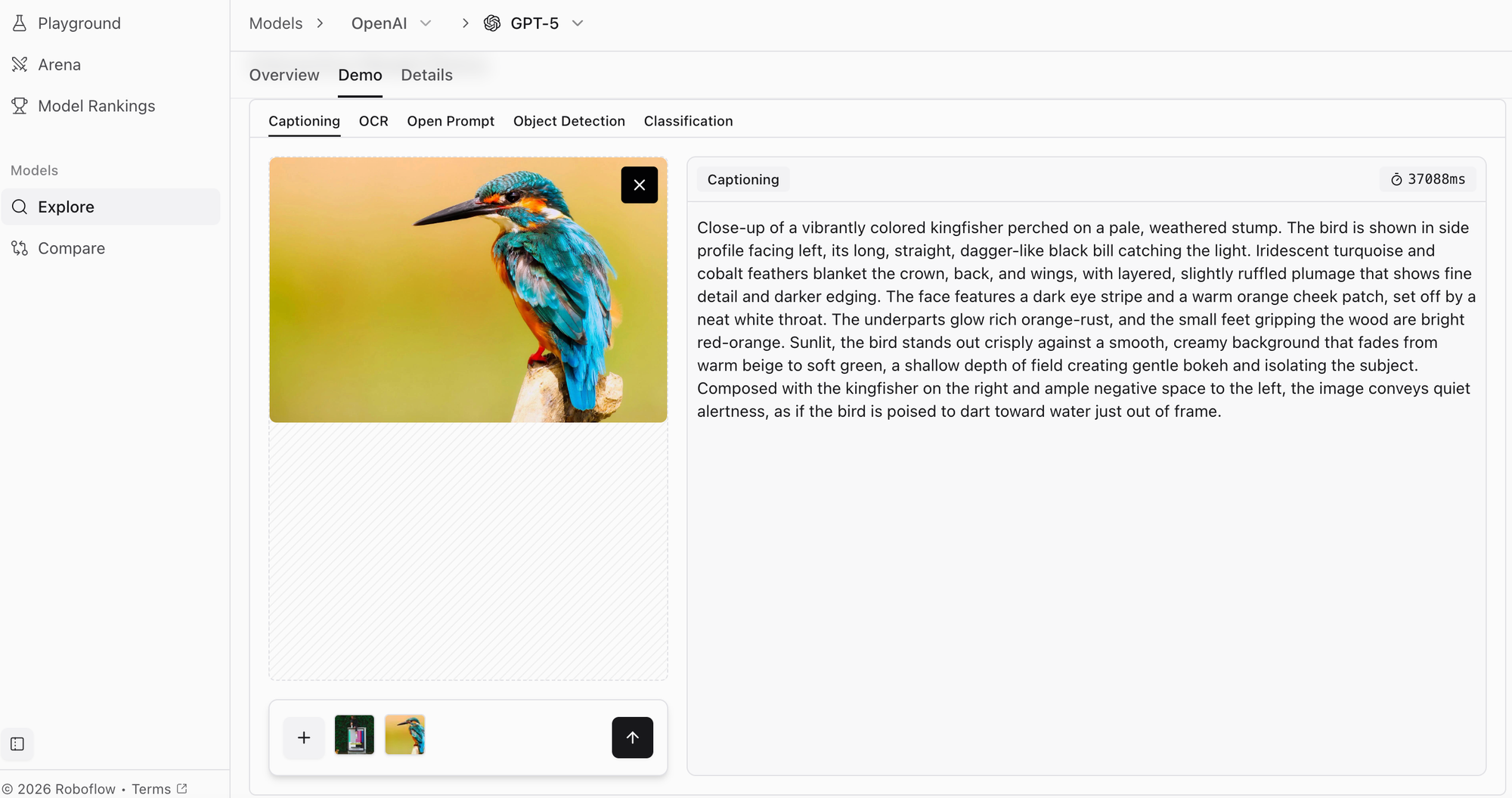
GPT-5, ranking fifth in Roboflow's overall standings with a score of 1227 across 4 tasks and 26.00 seconds latency, represents OpenAI's latest leap in multimodal reasoning. While maintaining the GPT series' text generation prowess, GPT-5 introduces enhanced vision understanding and more robust reasoning capabilities.
The model employs a dense transformer architecture with unified multimodal tokenization, converting text, image patches, and audio into a shared token space. Unlike sparse MoE approaches, GPT-5's dense design optimizes for reasoning depth rather than raw speed, making it particularly strong at complex problem-solving tasks.
Key innovations include enhanced chain-of-thought reasoning that explicitly models intermediate steps across modalities, improved factuality through novel training techniques that reduce hallucination, and native tool use integration for leveraging external APIs. The vision encoder processes images at multiple resolution levels, generating rich embeddings that feed into the main transformer.
GPT-5 demonstrates strong performance on complex reasoning benchmarks including GPQA and MATH. The model's visual understanding shows marked improvement over GPT-4, particularly on charts, diagrams, and technical figures that require analytical interpretation rather than simple recognition.
GPT-5 is well-suited for applications requiring sophisticated reasoning: complex document analysis and generation, research assistance and literature review, data analysis with visualization, code generation with visual specifications, and educational content creation. Its reasoning abilities make it valuable for domains requiring critical thinking and multi-step problem solving.
4. Qwen VL Max
Specialized Multimodal Vision Model, Primary Strength: Multilingual OCR & VQA
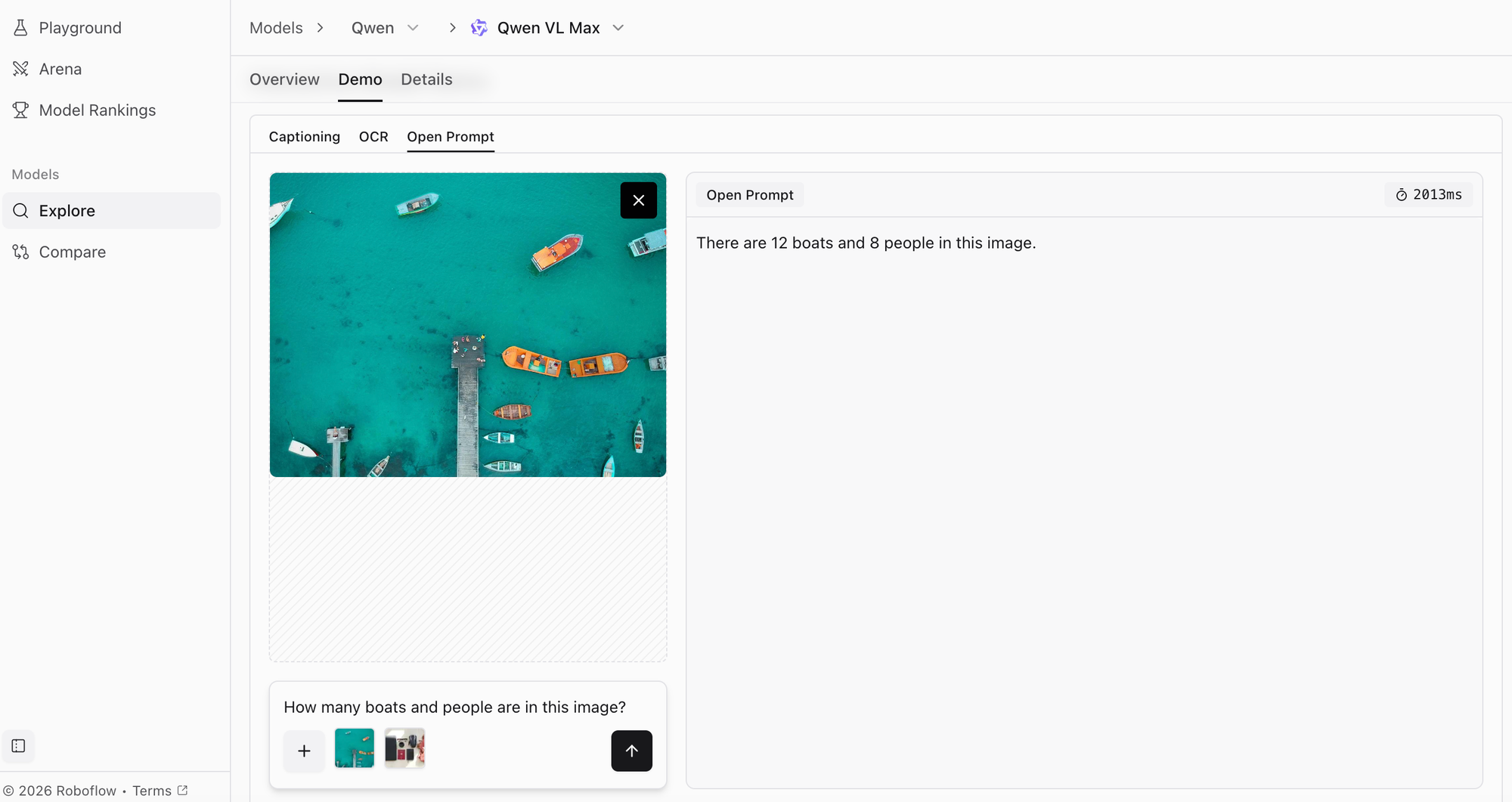
Qwen VL Max, developed by Alibaba Cloud, ranks seventh with a score of 1217 across 3 tasks at 13.35 seconds latency. As a leading open-source alternative to proprietary models, Qwen VL Max delivers competitive performance while offering greater accessibility for researchers and developers.
The model builds on Qwen's large language model foundation with enhanced vision-language understanding. Its architecture employs dynamic resolution processing that adapts to input image quality and a vision encoder optimized for diverse visual content from natural photos to technical diagrams and documents.
What sets Qwen VL Max apart is its focus on multilingual capabilities, particularly for Asian languages including Chinese, Japanese, and Korean, where it outperforms many Western-centric models. The model demonstrates strong performance on visual question answering, OCR, and document understanding tasks.
Key innovations include efficient attention mechanisms that reduce computational overhead while maintaining quality, strong few-shot learning capabilities that adapt quickly to new tasks with minimal examples, and robust training on diverse datasets that improve generalization across domains. The model is available under a permissive license for research and commercial use.
Qwen-VL Max excels in multilingual document processing, OCR and text extraction from images, visual question answering for e-commerce and education, and cross-lingual visual understanding. Its open-source nature and strong Asian language support make it particularly valuable for international applications and research projects requiring model customization.
5. Claude 4.1 Opus
Generalist Multimodal Model, Primary Strength: Technical Analysis & Safety
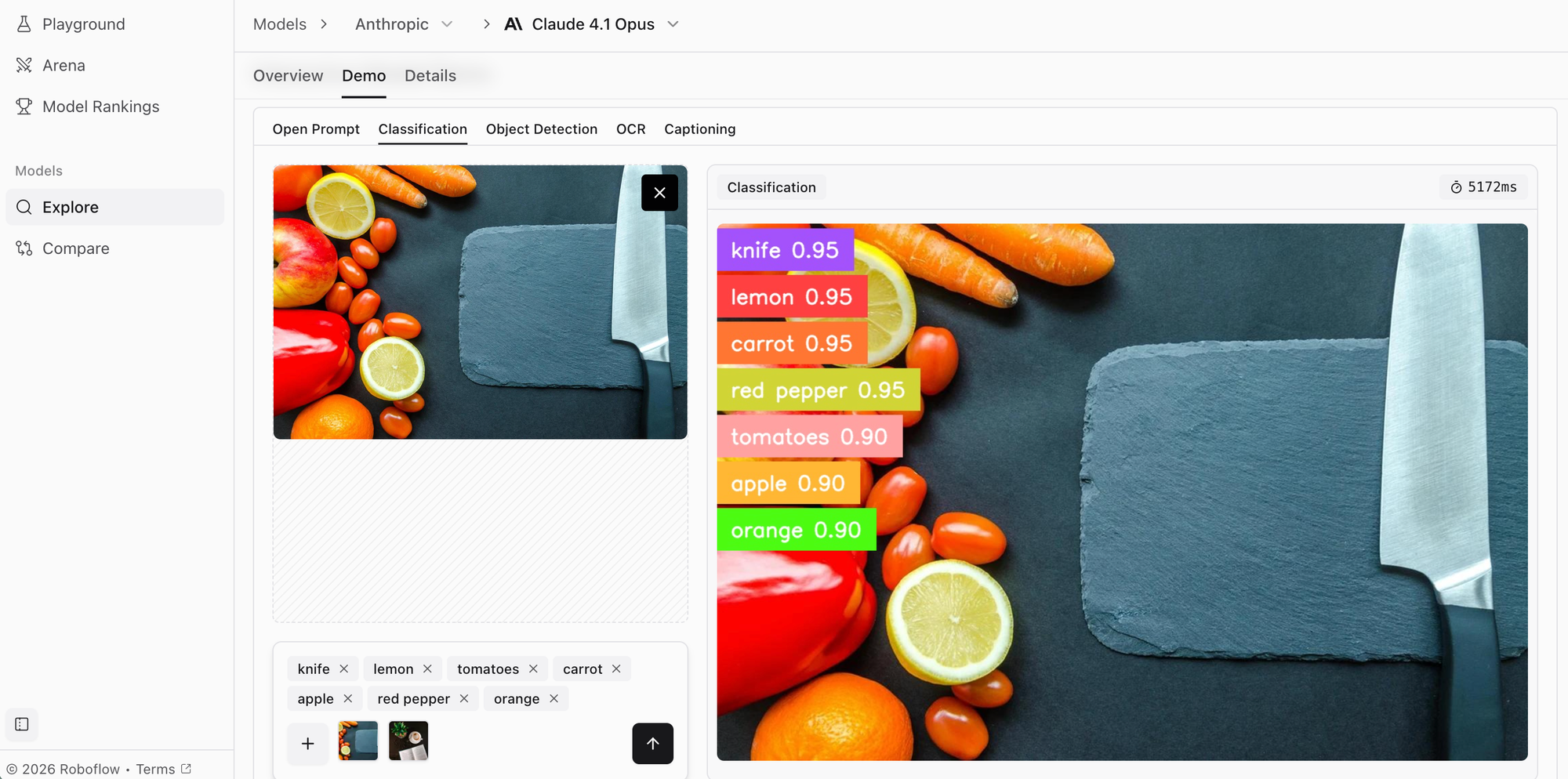
Claude 4.1 Opus, ranking ninth with a score of 1213 across 5 tasks and 12.08 seconds latency, represents Anthropic's latest advancement in the Claude family. Building on Claude 3 Opus's foundation, version 4.1 introduces enhanced reasoning capabilities and improved multimodal understanding.
The model employs Anthropic's constitutional AI architecture with sophisticated vision-language integration. Claude 4.1 Opus supports context windows exceeding 200,000 tokens with near-perfect recall, enabling analysis of extensive documents, codebases, and multi-modal content in a single session.
What distinguishes Claude 4.1 Opus is its exceptional performance on graduate-level reasoning tasks and technical analysis. The model processes photos, charts, graphs, and technical diagrams with remarkable accuracy, and can analyze dense research papers including complex equations and specialized notation in seconds.
Key innovations include nuanced safety mechanisms that better distinguish between harmful requests and legitimate edge cases, extensive factual accuracy training that significantly reduces hallucinations, and enhanced visual reasoning that improves performance on scientific diagrams and data visualizations. The model balances capability with responsible AI practices.
Claude 4.1 Opus excels in applications requiring sophisticated analysis and high reliability: scientific research assistance, legal document analysis, financial report interpretation, medical literature review, and technical documentation generation. Its combination of capability, safety, and long context makes it well-suited for sensitive or high-stakes applications.
Best Multimodal Models Conclusion
The early 2026 multimodal landscape offers diverse options for different needs. The rapid pace of innovation suggests we're only beginning to tap multimodal AI's potential. As these systems become more capable and efficient, they'll continue transforming how we interact with AI across every domain. Learn how to use multimodal models in workflows.
Written by Aryan Vasudevan
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Feb 4, 2026). Best Multimodal Models in 2026. Roboflow Blog: https://blog.roboflow.com/best-multimodal-models/