
Optical character recognition (OCR) allows text in images to be understandable by machines, allowing programs and scripts to process the text. OCR is commonly seen across a wide range of applications, but primarily in document-related scenarios, including document digitization and receipt processing.
While solutions for document OCR have been heavily investigated, the current state-of-the-art for OCR solutions on non-document OCR applications, occasionally referred to as "focused scene OCR", like reading license plates or logos, is less clear.
In this blog post, we compare different OCR solutions and compare their efficacy in ten different areas of industrial OCR applications.
OCR Solutions
We will test 25 different OCR models:
- TrOCR
- Qwen2.5-VL
- Moondream2
- Mistral OCR
- Idefics2
- OpenAI o1
- OpenAI GPT-4o & 4o mini
- OpenAI GPT-4.5 Preview
- Gemini 2.5 Pro Preview
- Gemini 2.0 (Flash, Flash-Lite)
- Gemini 1.5 (Flash, Flash-8B, Pro)
- Florence 2 (Large, Base)
- EasyOCR
- DocTR
- Claude 3.7 Sonnet
- Claude 3.5 (Sonnet, Sonnet v2, Haiku)
- Claude 3 (Opus, Sonnet, Haiku)
Within these tests, we include both local and cloud OCR models, including both closed and open source models. We test several Vision Language Models (VLMs) such as the OpenAI GPT-4 and o1 family, Google Gemini, Anthropic's Claude, as well as open-source, local VLMs such as Moondream2, Qwen2.5-VL, Idefics2 and Florence2.
On April 10, 2025 we updated this article with 18 new models including Qwen2.5-VL, Moondream2, Mistral OCR, new OpenAI models (o1, 4o, 4o mini, 4.5 Preview), new Gemini models (2.5 Pro, 2.0 family, more 1.5 varients), Florence 2 and new Claude models (3.7 Sonnet, 3.5 family, more 3.0 varients)
(Gemini Pro 1.5 was added March 28, 2024. Idefics2 by Hugging Face was added April 18, 2024.)
OCR Testing Methodology
Most OCR solutions, as well as benchmarks, are primarily designed for reading entire pages of text.
Informed by our experiences deploying computer vision models in physical world environments and industrial use cases, we have seen the benefit of omitting a “text detection” or localization step within the OCR process in favor of a custom-trained object detection model, cropping the result of the detection model to be passed onto an OCR model.
Our goal, and the scope of this experiment, is to test as many non-document use case domains as possible with localized text examples. With the influence of what we have seen from our own experiences and our customers’ use cases, we outlined twenty different domains to test.

For each domain, we selected an open-source dataset from Roboflow Universe and imported ten images from each domain dataset at random. The criteria we used to select images were that if an image could be reasonably read and transcribed by a human, it was included.
In most cases, the domain images were cropped to correspond to object detection annotations made within the original Universe dataset. In cases where there were either no detections to crop from or the detections contained extra text that could introduce variability in our testing, we manually cropped images.
For example, with license plates, the dataset we used contained the entire license plate, which in the cases of U.S. license plates included the state, taglines, and registration stickers. In this case, we cropped the image only to include the primary identifying numbers and letters.
To create a ground truth to compare OCR predictions against, each image was manually read, annotated, and reviewed with the text in the image as it appeared.
Once we prepared the dataset, we evaluated each OCR solution. A Levenshtein distance ratio, a metric used for measuring the difference between two strings, was calculated and used for scoring.
Results
Our testing gave us several insights into the various OCR solutions and when to use them. We examine the accuracy, speed, and cost aspects of the results.
Accuracy
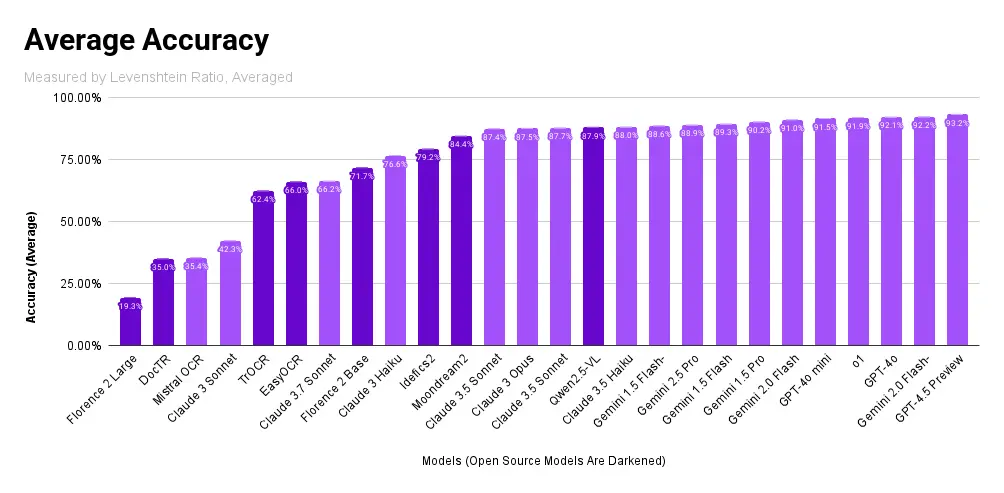
Across the board, considering all domains, multimodal VLM families scored well, with OpenAI's GPT-4.5 Preview scoring at the top, unseating Claude, which placed at the top when previously tested in March 2024. Qwen2.5-VL scores the highest among open-source models, closely followed by Moondream2.
Overall, most VLMs performed well, with the entire OpenAI's model family, the entire Gemini family, most Claude variants, as well as Qwen2.5-VL and Moondream 2 all scoring within a 10% margin of the top score.
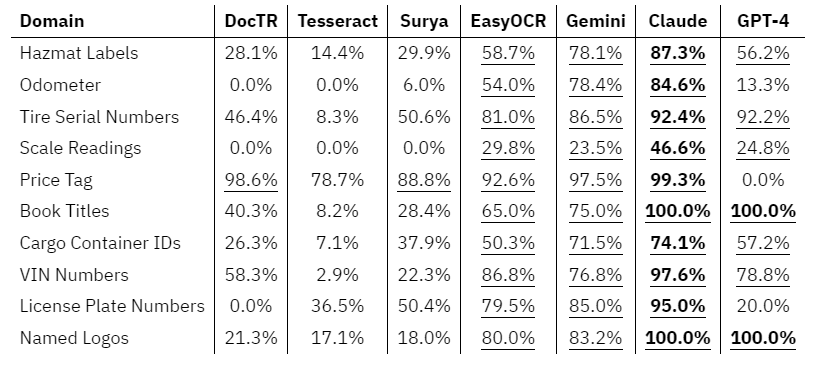
Across all domains, Claude achieved the highest accuracy score the most times, followed by GPT-4 and Gemini. EasyOCR performed generally well across most domains and far surpassed its specialized-package counterparts, but underperformed compared to LMMs.
In our previous iteration of testing, we noted GPT-4's high refusal rate. We no longer experienced this issue in the most recent round of testing. Rather, we found that Google's Gemini 1.5 Flash-8B was the only model in our recent round that had any significant issues, consistently producing Internal Server Errors where other models, even from Gemini, experienced none.
Speed
Accurate OCR is important, but speed is also a consideration when using OCR. OpenAI's reasoning model, o1, took the longest to respond, followed by Florence 2 (Large) and Gemini's reasoning model, Gemini 2.5 Pro.
Local non-VLM OCR models, unencumbered by network speeds and the large model sizes of VLMs, were the fastest with EasyOCR and TrOCR leading the way. They were followed by the lightest versions of VLMs.
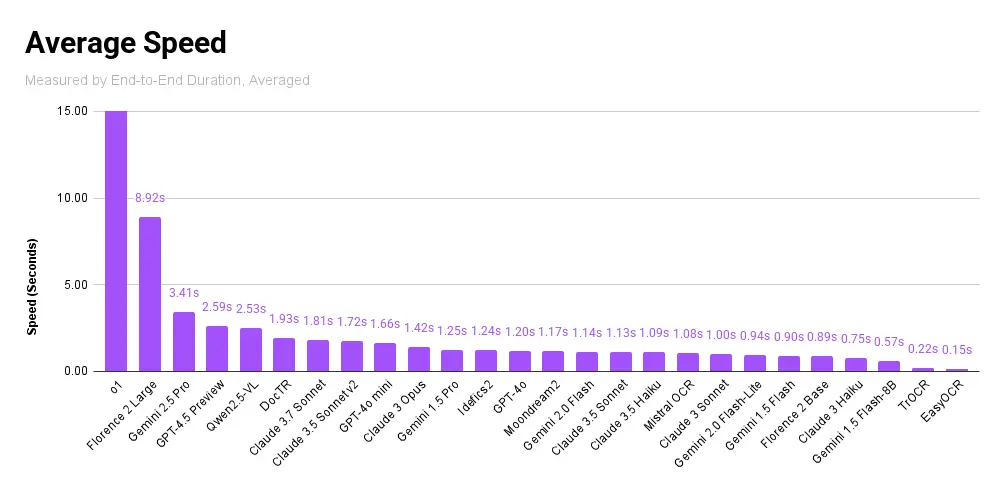
Speed itself, however, does not show the entire picture since a fast model with terrible accuracy is not useful.
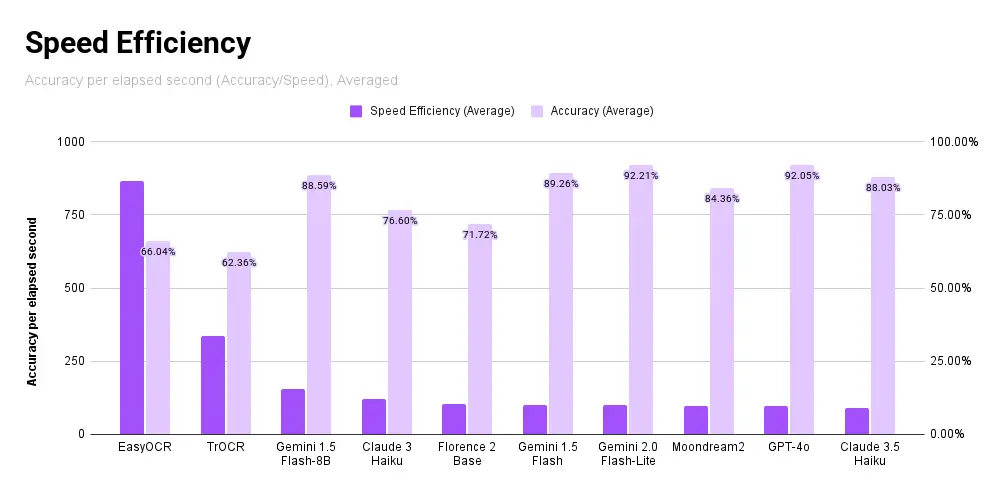
So, we calculate a metric, “speed efficiency”, which we define as accuracy over the elapsed time. Our goal with this metric is to show how accurate the model is, considering the time it took.
In this category, the local non-VLM models with their fast speed win by a considerable margin, followed by Gemini 1.5 Flash and Claude 3 Haiku. We also see local VLMs score high, with Florence 2 (Base) and Moondream 2 scoring fifth and eighth place, respectively.
Cost
A third factor to consider is the actual price it takes to perform each request. In high-volume use cases, costs can add up quickly, and having a sense of the financial impact it will have is important.
We did calculation costs in one of two separate methods, depending on the model:
- Hosted, Cloud Models: We calculated the actual cost depending on the provider's pricing model. (Ex: for LMMs, we calculated the average costs from the number of tokens used in the prompt and output, according to each provider's pricing)
- Local Models: We calculated the cost of the OCR request as the time it took to predict multiplied by the cost of the virtual machine on Google Cloud. (The tests were run on a Google Colab CPU environment, which we equated to a Computer Engine E2 instance with 2 vCPUs and 13 GB of memory).
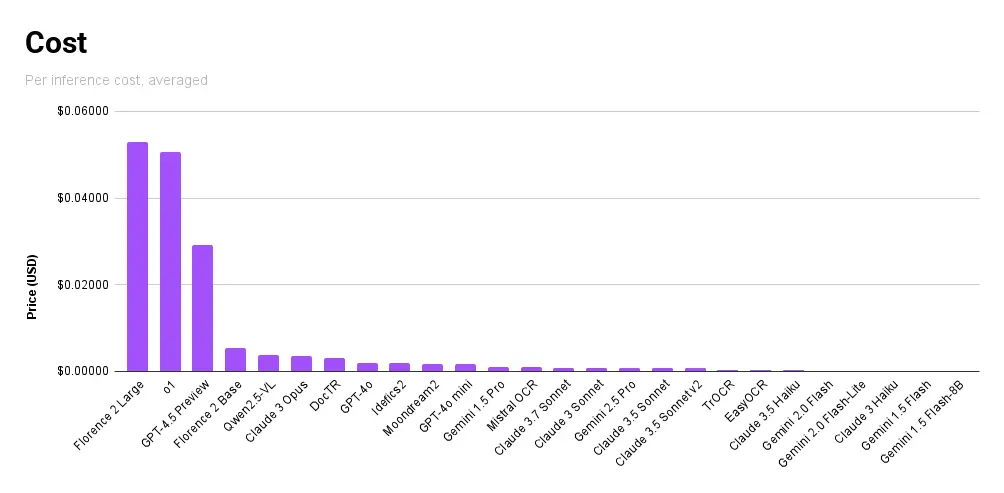
Surprisingly, the lightest of cloud-run models from Gemini's Flash variants and Claude's Haiku variants came it as the cheapest models. It was quickly followed by EasyOCR and TrOCR. The large VLMs unsurprisingly came in as the most expensive, with Florence 2 (Large), OpenAI o1 and GPT-4.5 Preview coming in at the top.
Similar to how we calculated speed efficiency, we calculated a cost efficiency metric, defined as the percentage accuracy over the price cost. This relates how performant a model is to the price of running the model. It is calculated by dividing the score achieved by the cost of the request.
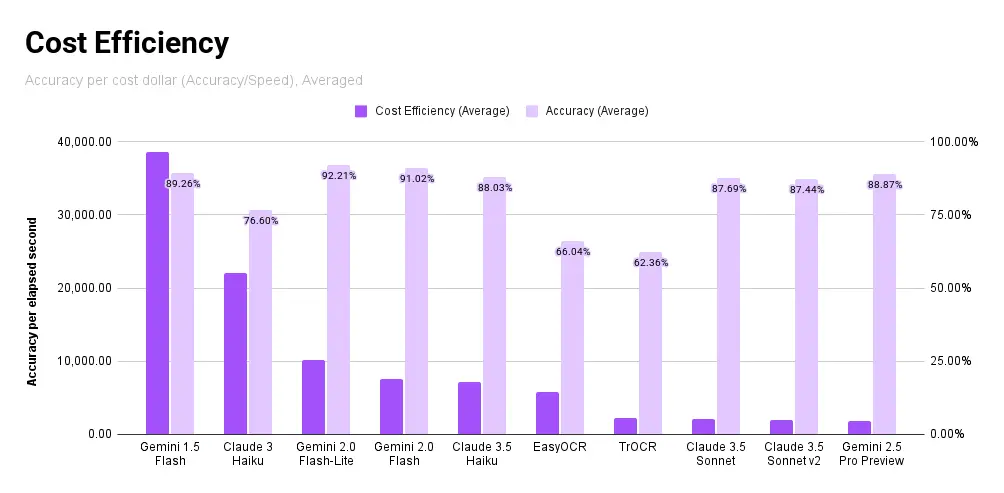
Gemini 1.5 Flash, Claude 3 Haiku, Gemini 2.0 Flash (and Flash-Lite), and Claude 3.5 Haiku, having generally good performance regardless of cost, came in at the top. Fast and local EasyOCR and TrOCR after, followed by more variants of Claude and Gemini.
Conclusion
In this blog post, we explored how different OCR solutions perform across domains that are commonly found in industrial vision use cases, comparing LMMs and open-source solutions on speed, accuracy, and cost.
Throughout testing, we find that running EasyOCR locally produces the most cost-efficient OCR results while maintaining competitive accuracy, while Anthropic’s Claude 3 Opus performed the best across the widest array of domains, and Google’s Gemini Pro 1.0 performs the best in terms of speed efficiency.
When comparing against local, open-source OCR solutions, EasyOCR far outperformed its counterparts in all metrics, performing at levels near or above other LMMs.
Compare accuracy, speed, and user votes for extracting text from images anytime with the OCR Leaderboard.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Mar 16, 2024). Best OCR Models for Text Recognition in Images. Roboflow Blog: https://blog.roboflow.com/best-ocr-models-text-recognition/