
Knowing where an object is in a frame is the core output of object detection, and it applies directly to industrial automation, robotics, and autonomous vehicles where physical position drives downstream decisions. This post covers 2D object detection using Roboflow Inference and an RF-DETR model, explains how bounding box coordinates translate to object position on a 2D plane, and contrasts that with 3D positioning techniques that require depth data. The tutorial walks through installing Inference, loading a model, running inference on an image, and interpreting the bounding box output.
Artificial intelligence (AI), specifically computer vision, can help you find the position of an object or group of objects in an image or video frame.
Understanding the position of an object is the premise of "object detection", a subset of computer vision focused on detecting the location of objects in an image. There are several other techniques that can be applied, too: segmentation (for localizing objects at a pixel level), and traditional techniques like pattern matching (ideal for localizing objects with clear borders that align with an expected input).
Object position understanding is applied across many fields. For example, when it comes to industrial automation, object positioning can be used to count and sort products and materials. In self-driving cars, onboard systems can use computer vision and object positioning to detect pedestrians and other vehicles on the road.
In this article, we'll learn all about the concept of understanding the position of an object using computer vision and walk through an example of object detection.
Understanding an Object's Position
Calculating the position of an object in visual data can be easy with the help of computer vision tasks like 2D object detection. Two-dimensional object detection uses complex algorithms and deep learning models to find objects in an image. These deep learning models use techniques like region proposal networks or single-shot detectors to identify regions that might have an object. After the object is detected, precise localization makes it possible to refine the regions and encapsulate the object using bounding boxes.
Understanding the position of an object in 2D and 3D is similar but not quite the same. In 2D object detection, we can find the position of an object on a 2D plane. While in 3D positioning, we also need to take depth into account. Since it's a 3D space, the z-axis coordinate also comes into play, not just (x,y). Technologies like structured light, laser triangulation, and stereoscopic vision are used to capture this 'depth' information and create a 3D representation of the object.
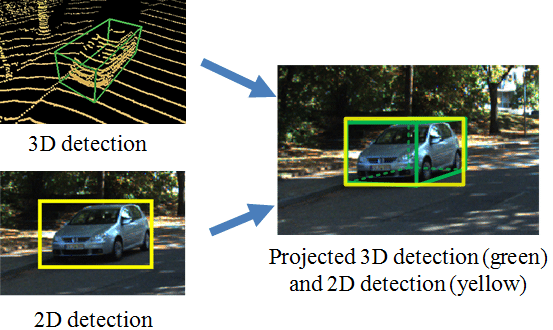
Two-dimensional object detection is useful for computer vision applications on a 2D plane. For example, in the manufacturing sector, it can be used for quality control applications like surface inspections, product recognition, and defect detection. On the other hand, 3D object detection can be used in inventory management to locate and track items in a very cluttered environment.
However, 3D object detection requires additional resources to capture information related to depth and it requires a lot more computational resources than 2D.
How to Determine an Object's Position Using Roboflow
Now that we have a better understanding of how object detection can be used to find out the position of an object in an image, let's get hands-on with a coding example. We'll focus on how you can use Roboflow and RF-DETR to find the position of an object in an image in 2D. We'll go through the code step by step. You'll need an image (with an object) to test out this code. We'll be using an image of a puppy.
Step #1: Install Inference
To get started, you'll need to install Roboflow's Inference library. It will provide easy access to pre-trained computer vision models like RF-DETR. It can also help you deploy these models directly into your computer vision applications. You'll also install the Supervision library which provides reusable computer vision tools.
You can install these packages using 'pip' with the following command:
pip install inference supervisionStep #2: Load an RF-DETR Model
After installing the library, the next step is to import the needed packages and load the pre-trained RF-DETR model. Here's how to do it:
from inference import get_model
import cv2
import supervision as sv
# Load the RF-DETR model
model = get_model(model_id="rf-detr-b-1")Step #3: Run Inference
Once the model is loaded, the next step is to pass an image through it to get the position of the object within it. The process of analyzing an image using a model is known as running an inference on the image. The code snippet below will help you load the image you want to analyze and then use the model to predict the object's position and other data like the width and height of bounding boxes.
# Load an image
image = cv2.imread("path/to/image/file")
# Run the model on the image
results = model.infer(image)[0]
detections = sv.Detections.from_inference(results)
Here is the input image that we'll be using:
Step #4: Interpreting the Output
After running the inference, the next step is to extract the output and visualize it. The position of the object in the image will be the (x,y) coordinates that point to the center of the detected object. The code below will extract these coordinates and data for drawing bounding boxes. The final output image will have bounding boxes drawn around the object with the class name, confidence score, and coordinates labeled on top.
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator(text_scale=2,text_thickness=2)
# Generate labels with class names, confidence, and bounding box center coordinates
labels = [
f"{class_name} {confidence:.2f} ({(x1 + x2) / 2:.1f}, {(y1 + y2) / 2:.1f})"
for class_name, confidence, (x1, y1, x2, y2)
in zip(
detections['class_name'],
detections.confidence,
detections.xyxy
)
]
annotated_image = box_annotator.annotate(
scene=image, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections, labels=labels)
# Display the image
cv2.imshow(annotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()Below is the output image. The position of the object is at (2066.5, 978.5) in the image.
You can get the full coordinates by printing the value of the detections array.

Challenges and Considerations
Accurate object detection is very critical in computer vision, but it's also challenging. Factors such as occlusions (objects overlapping each other), lighting variations, and camera distortions can impact the precision of position data. Having to find the position of objects that are similar and objects that are off different scales can further complicate the process.
Unfavorable environmental conditions (rain, dirt on the camera, etc) also play a role in meddling with the accuracy of object detection. Excess light can obscure the details of the object, while shadows and reflections can create misleading information. Camera angles and lens distortions add another layer of difficulty in finding the position of objects.
A hurdle that isn't directly related to the input images themselves are the amount of computational resources needed for real-time processing. Needing to find the position of objects in high-definition images translates into a need for a lot of powerful hardware.
GPUs and their parallel processing capabilities have become essential for handling the computational load associated with modern computer vision tasks. However, GPUs can be expensive. Model optimization is also a great solution. For example, if you're working with devices that have limited resources, like edge devices, you can optimize the models to make sure they run efficiently.
Applications and Use Cases
Now that we've learned how to understand the position of an object in an image using computer vision and the challenges that can be involved, let's dive a bit deeper into the practical applications of object detection.
Industrial Automation
Object detection can be very useful in accurately identifying and locating objects in factory settings. These automated computer vision systems can perform quality control, inventory management, and assembly line operations efficiently. For example, object detection can be used in systems that can automatically locate defected products and remove them from production line. By doing so, manufacturers can significantly improve efficiency, reduce costs, and guarantee the overall quality of the product.
Robotics
Object detection plays a key role in how robots work. It allows robots to "see" and understand their surroundings through image analysis. By knowing the position of an object, robots can perform tasks like manipulation, assembly, and navigation. If the robot doesn't know the position of the object it is seeing, it can't pick it up. There are also robots (drones as well) that work with human gesture control. These systems need to know the position of hands and figures for them to work as well.

Autonomous Vehicles
Self-driving cars like Tesla and Waymo depend on object detection. Using AI and computer vision, these vehicles can accurately identify and locate objects in real-time. It helps cars find the position of pedestrians, other vehicles, traffic signs, and obstacles. Knowing this information helps these cars make better decisions to avoid collisions. Object detection can provide the sensory foundation for autonomous vehicles to perceive and interact intelligently with their environment.
Conclusion
Understanding the position of an object using computer vision is the foundation of many significant applications, from robots and self-driving cars to factory automation. You can use a variety of techniques to understand the position of an object, from 2D and 3D object detection to segmentation and pattern matching.
In this guide, we walked through an example of how to detect objects in 2D images using Roboflow Inference, an open source computer vision inference server, and an RF-DETR object detection model.
To learn more about the fundamentals of object detection, check out our What is Object Detection? guide.
Want to Learn More?
Check out these resources to keep exploring:
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Sep 4, 2024). Calculate the Position of an Object Using Computer Vision. Roboflow Blog: https://blog.roboflow.com/calculate-object-positions/