
See the Quickstart to get started.
Deploy Models to NVIDIA Embedded Devices
Deploying models to the edge offers unique benefits: inference speeds can be increased, the model can run offline, and data can be processed locally. But getting models onto embedded hardware can be a tedious task – compiling a model in the right format, wrestling with running GPU on Docker containers, ensuring CUDA is configured correctly, and a host of other challenges require embedded hardware expertise. But alas, no longer.
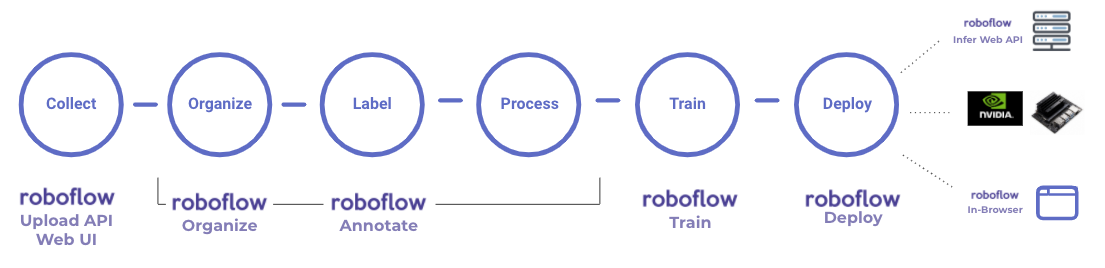
We're introducing Roboflow support for the NVIDIA Jetson family of models. This enables you to deploy your computer vision model to your Jetson with three simple commands. By default, the model will leverage the GPU of your device, achieving up to 15 frames per second (on the Jetson Xavier NX).
Deploying your computer vision model on your NVIDIA Jetson is as easy as (1) pulling the Roboflow Inference Server Docker Container (2) running docker run on the container (3) passing images to the inference server on the device.
In other words: it works seamlessly with the code you've already written! Our on-device inference server runs locally on your Jetson device using the same custom trained models while maintaining API compatibility with our cloud hosted Roboflow Infer endpoints. This means you can prototype your app against our infinitely-scalable hosted inference API and then choose to deploy on-prem simply by changing a single line in your code.
And because the model you're running on your embedded device is a Roboflow Train model, you'll easily be able to leverage active learning by default. For example, using Roboflow model-assisted labeling will surface which images your model is most struggling to understand. Every improvement you make to your dataset will flow through to the Roboflow model you deploy on your devices simply by bumping your model's version number, enabling you to identify and improve model errors substantially faster.
Resources
📚 Read the Documentation and follow the example tutorial
⭐️ Star the Repo
📡 Get the Docker Container
Additionally, because the inference logic is encapsulated in a Docker container, you can choose whichever language you prefer for crafting your application code and UI rather than being tied to a specific environment required by your machine learning stack. You can even use a single Jetson as a server on your local network handling inference for multiple client nodes.
We've optimized our integration to utilize the Jetsons' GPU and hardware acceleration out of the box to optimize performance no matter which version you choose (our inference server supports the Nano 2GB, Nano 4GB, and Xavier NX, along with NVIDIA's enterprise embedded devices). And, despite running on a low-power device, you won't be sacrificing any accuracy: the Roboflow Inference Server utilizes the same state of the art models we deploy on our datacenter machines.
See the full documentation for deploying to NVIDIA Jetson with Roboflow.
Ready to give it a spin? Contact our sales team to get started with some training credits and a Roboflow Pro account.