
By default, Docker containers do not inherit GPU access from the host machine, which produces CUDA and nvidia-smi errors when running computer vision workloads. The fix is the NVIDIA Container Toolkit, which exposes the host GPU drivers to containers without needing to bake drivers into the image itself. This post walks through driver installation, toolkit setup, the brute-force alternative for custom base images, and using nvidia-smi inside a running container to monitor utilization and verify the configuration is working.
Configuring the GPU on your machine can be immensely difficult. The configuration steps change based on your machine's operating system and the kind of NVIDIA GPU that your machine has. To add another layer of difficulty, when Docker starts a container - it starts from almost scratch.
Certain things like the CPU drivers are pre-configured for you, but the GPU is not configured when you run a docker container. Luckily, you have found the solution explained here. It is called the NVIDIA Container Toolkit.
In this post, we walk through the steps required to access your machine's GPU within a Docker container. Roboflow uses this method to let you easily deploy to NVIDIA Jetson devices.
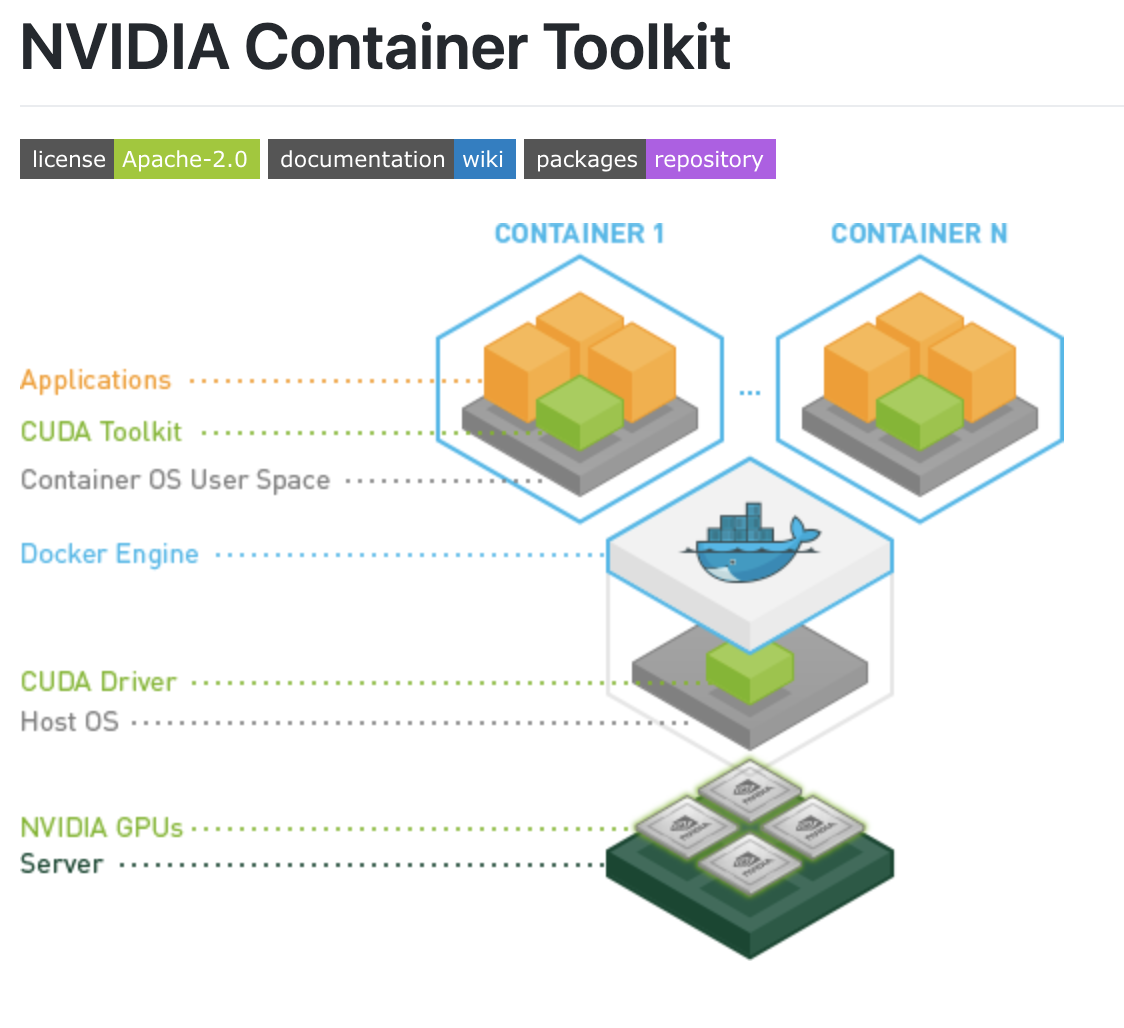
Docker GPU Errors
When you attempt to run your container that needs the GPU in Docker, you might receive any of the errors listed below. These errors are indicative of an issue where Docker and Docker compose is unable to connect to your GPU.
Here are a few of the errors you may encounter:
docker: Error response from daemon: Container command 'nvidia-smi' not found or does not exist..
Error: Docker does not find Nvidia drivers
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:150] kernel reported version is: 352.93
I tensorflow/core/common_runtime/gpu/gpu_init.cc:81] No GPU devices available on machine.tensorflow cannot access GPU in Docker
RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at /pytorch/aten/src/THC/THCGeneral.cpp:50pytorch cannot access GPU in Docker
The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.keras cannot access the GPU in Docker
Enabling Docker to Use Your GPU
If you have encountered any errors that look like the above ones listed above, the steps below will get you past them. Let's talk through what you need to do to allow Docker to use your GPU step-by-step.
Install NVIDIA GPU Drivers on your Base Machine
First, you must install NVIDIA GPU drivers on your base machine before you can utilize your GPU in Docker.
As previously mentioned, this can be difficult given the plethora of distribution of operating systems, NVIDIA GPUs, and NVIDIA GPU drivers. The exact commands you will run will vary based on these parameters.
If you're using the NVIDIA TAO Toolkit, we have a guide on how to build and deploy a custom model.
The resources below may be useful in helping your configure the GPU on your computer:
- NVIDIA's official toolkit documentation
- Installing NVIDIA drivers on Ubuntu guide
- Installing NVIDIA drivers from the command line
Once you have worked through those steps, run the the nvidia-smi command. If the command lists information about your GPU, you know that your GPU has been successfully identified and recognised by your computer. You may see an output that looks like this:
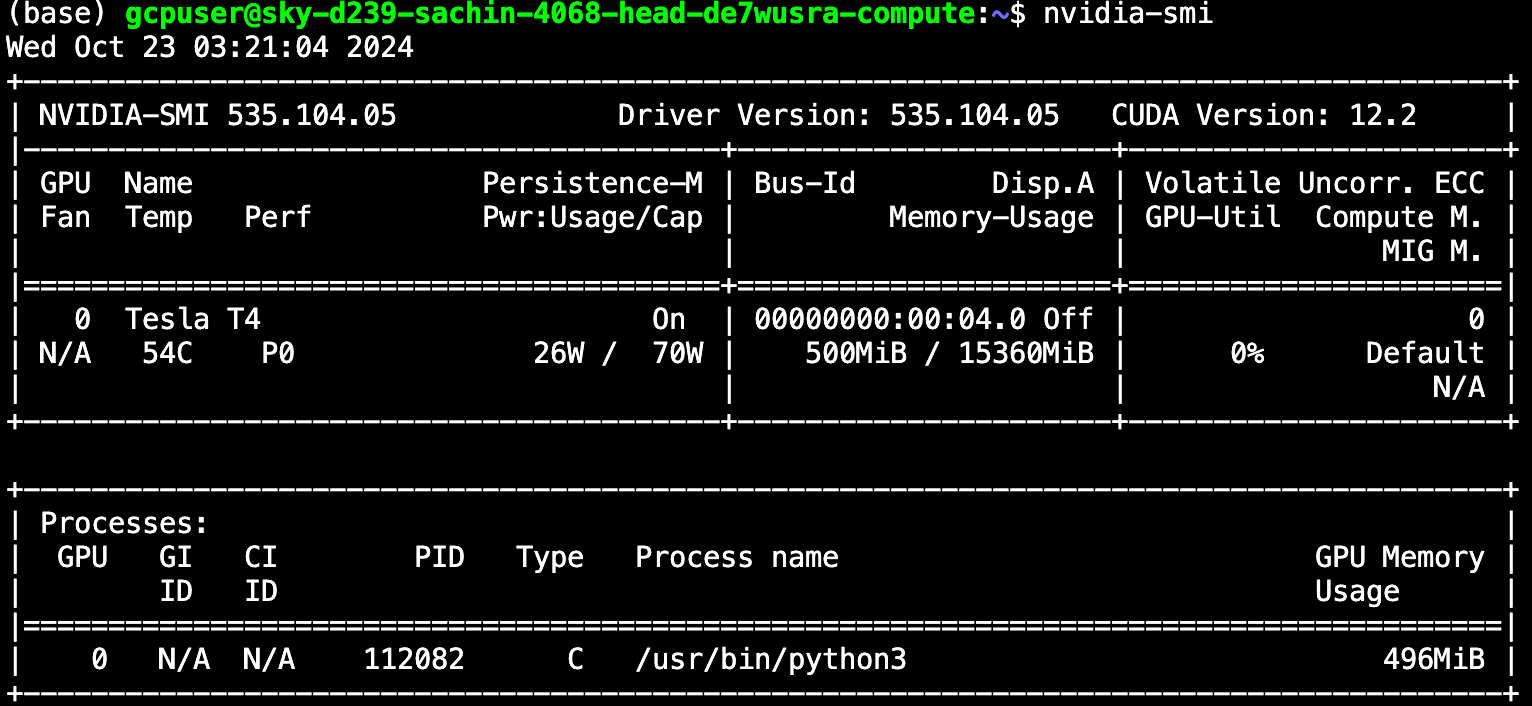
Now that we know the NVIDIA GPU drivers are installed on the base machine, we can move one layer deeper to the Docker container. See Roboflow's Docker repository for examples of how Docker containers are used to deploy computer vision models.
Exposing GPU Drivers to Docker using the NVIDIA Toolkit
The best approach is to use the NVIDIA Container Toolkit. The NVIDIA Container Toolkit is a docker image that provides support to automatically recognize GPU drivers on your base machine and pass those same drivers to your Docker container when it runs.
If you are able to run nvidia-smi on your base machine, you will also be able to run it in your Docker container (and all of your programs will be able to reference the GPU). In order to use the NVIDIA Container Toolkit, you pull the NVIDIA Container Toolkit image at the top of your Dockerfile like so:
FROM nvidia/cuda:12.6.2-devel-ubuntu22.04
CMD nvidia-smiThe code you need to expose GPU drivers to Docker
In that Dockerfile we have imported the NVIDIA Container Toolkit image for 10.2 drivers and then we have specified a command to run when we run the container to check for the drivers. You might want to update the base image version (in this case, 10.2) as new versions come out.
Now we build the image with the following command:
docker build . -t nvidia-test
Now, we can run the container from the image by using this command:
docker run --gpus all nvidia-testKeep in mind, we need the --gpus all flag or else the GPU will not be exposed to the running container.
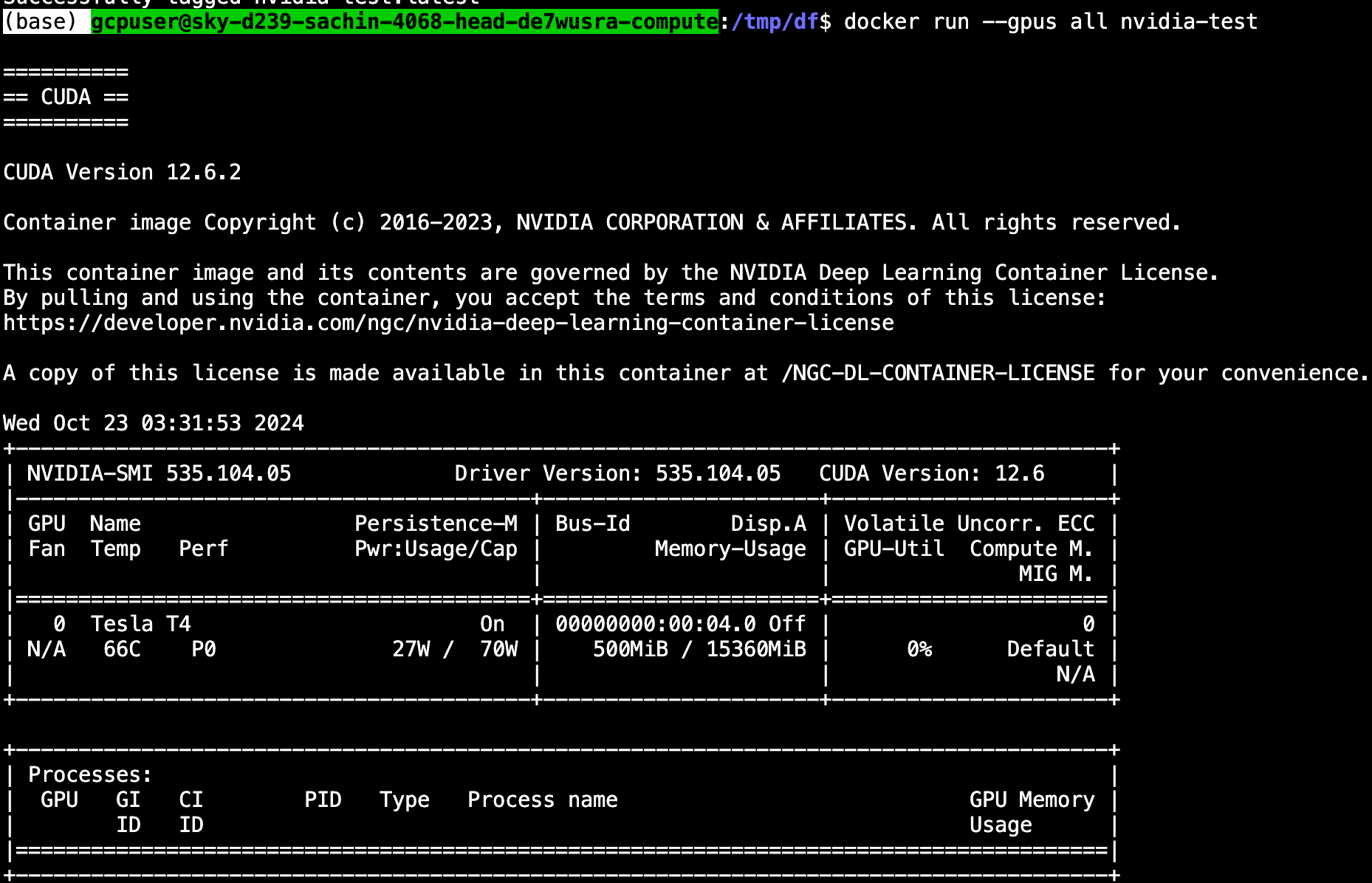
From this state, you can develop your app. In our example case, we use the NVIDIA Container Toolkit to power experimental deep learning frameworks. The layout of a fully built Dockerfile might look something like the following (where /app/ contains all of the python files):
FROM nvidia/cuda:12.6.2-devel-ubuntu22.04
CMD nvidia-smi
#set up environment
RUN apt-get update && apt-get install --no-install-recommends --no-install-suggests -y curl
RUN apt-get install unzip
RUN apt-get -y install python3
RUN apt-get -y install python3-pip
COPY app/requirements_verbose.txt /app/requirements_verbose.txt
RUN pip3 install -r /app/requirements_verbose.txt
#copies the applicaiton from local path to container path
COPY app/ /app/
WORKDIR /app
ENV NUM_EPOCHS=10
ENV MODEL_TYPE='EfficientDet'
ENV DATASET_LINK='HIDDEN'
ENV TRAIN_TIME_SEC=100
CMD ["python3", "train_and_eval.py"]A full python application using the NVIDIA Container Toolkit
The above Docker container trains and evaluates a deep learning model based on specifications using the base machines GPU.
Exposing GPU Drivers to Docker by Brute Force
In order to get Docker to recognize the GPU, we need to make it aware of the GPU drivers. We do this in the image creation process. This is when we run a series of commands to configure the environment in which our Docker container will run.
The "brute force approach" to ensure Docker can recognise your GPU drivers is to include the same commands that you used to configure the GPU on your base machine. When docker builds the image, these commands will run and install the GPU drivers on your image and all should be well.
There are downsides to the brute force approach. Every time you rebuild the docker image, you will have to reinstall the image. This will slow down your development speed.
In addition, if you decide to lift the Docker image off of the current machine and onto a new one that has a different GPU, operating system, or you would like new drivers - you will have to re-code this step every time for each machine.
This kind of defeats the purpose of build a Docker image. Also, you might not remember the commands to install the drivers on your local machine, and there you are back at configuring the GPU again inside of Docker.
The brute force approach will look something like this in your Dockerfile:
FROM ubuntu:22.04
MAINTAINER Regan <http://stackoverflow.com/questions/25185405/using-gpu-from-a-docker-container>
RUN apt-get update && apt-get install -y build-essential
RUN apt-get --purge remove -y nvidia*
ADD ./Downloads/nvidia_installers /tmp/nvidia > Get the install files you used to install CUDA and the NVIDIA drivers on your host
RUN /tmp/nvidia/NVIDIA-Linux-x86_64-331.62.run -s -N --no-kernel-module > Install the driver.
RUN rm -rf /tmp/selfgz7 > For some reason the driver installer left temp files when used during a docker build (i don't have any explanation why) and the CUDA installer will fail if there still there so we delete them.
RUN /tmp/nvidia/cuda-linux64-rel-6.0.37-18176142.run -noprompt > CUDA driver installer.
RUN /tmp/nvidia/cuda-samples-linux-6.0.37-18176142.run -noprompt -cudaprefix=/usr/local/cuda-6.0 > CUDA samples comment if you don't want them.
RUN export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 > Add CUDA library into your PATH
RUN touch /etc/ld.so.conf.d/cuda.conf > Update the ld.so.conf.d directory
RUN rm -rf /temp/* > Delete installer files.Code credit to stack overflow
This approach requires you to have your NVIDIA drivers in a local folder. You can replace the "./Downloads" folder in the example above with the directory where you have saved your GPU drivers.
What if I need a different base image in my Dockerfile?
Let's say you have been relying on a different base image in your Dockerfile. Then, you should consider using the NVIDIA Container Toolkit alongside the base image that you currently have by using Docker multi-stage builds.
Now that you have you written your image to pass through the base machine's GPU drivers, you will be able to lift the image off the current machine and deploy it to containers running on any instance that you desire.
The Power of Metrics: Understanding GPU Utilization in your running Docker Container
Monitoring your GPU's performance metrics is crucial for optimizing your applications and maximizing the value you get from your hardware. Metrics like GPU utilization, memory usage, and thermal characteristics provide valuable insights into how efficiently your containerized workloads are utilizing the GPU resources. These insights can help you identify bottlenecks, fine-tune application configurations, and ultimately reduce costs.
Introducing DCGM: A Suite for GPU Monitoring
NVIDIA's Data Center GPU Manager (DCGM) is a powerful suite of tools specifically designed for managing and monitoring NVIDIA datacenter GPUs in clustered environments. It offers comprehensive features like:
- Active health monitoring to proactively identify potential issues before they impact your workloads.
- Detailed diagnostics to provide deep analysis of GPU performance.
- System alerts to notify you of any critical events related to your GPUs.
Running a Sample GPU Inference Container
Now, let's put theory into practice. We'll use Roboflow's GPU inference server docker image as an example GPU workload and monitor its GPU usage using DCGM, Prometheus and Grafana. Here's how to pull and run the Roboflow GPU inference container:
Bash
docker pull roboflow/roboflow-inference-server-gpu
docker run -it --net=host --gpus all roboflow/roboflow-inference-server-gpu:latest
Unified Monitoring with Prometheus, Grafana, and DCGM
To simplify GPU metrics collection and visualization, we'll leverage an excellent open-source project that integrates Prometheus, Grafana, and DCGM from here. This project provides a pre-configured Docker Compose file that sets up all the necessary components:
- DCGM Exporter: This container scrapes raw metrics from your NVIDIA GPUs.
- Prometheus: This container serves as the central repository for collecting and storing metrics.
- Grafana: This container provides a user-friendly interface for visualizing and analyzing your collected metrics.
The provided Docker Compose file defines the configurations for each component, including resource allocation, network settings, and environment variables. By deploying this Docker Compose stack, you'll have a complete monitoring system up and running in no time.
To get your monitoring stack setup:
git@github.com:hongshibao/gpu-monitoring-docker-compose.git
docker compose upThis should bring up the DCGM exporter, Prometheus and Grafana pods.
Explanation of the Docker Compose File:
The repository-provided Docker Compose file compose.yaml defines various services and configurations:
- Services:
dcgm_exporter: This service runs the DCGM exporter container to collect GPU metrics. It utilizes thenvidiadevice driver and requests access to all available GPUs with GPU capabilities.prometheus: This service runs the Prometheus container to store and serve the collected metrics. You can customize storage parameters like retention time.grafana: This service runs the Grafana container for visualizing the metrics. You can configure user credentials for access control.
- Volumes:
- Persistent volumes are defined for Prometheus data and Grafana data to ensure data persistence even after container restarts.
- Networks:
- A custom network named
gpu_metricsis created to facilitate communication between the services.
- A custom network named
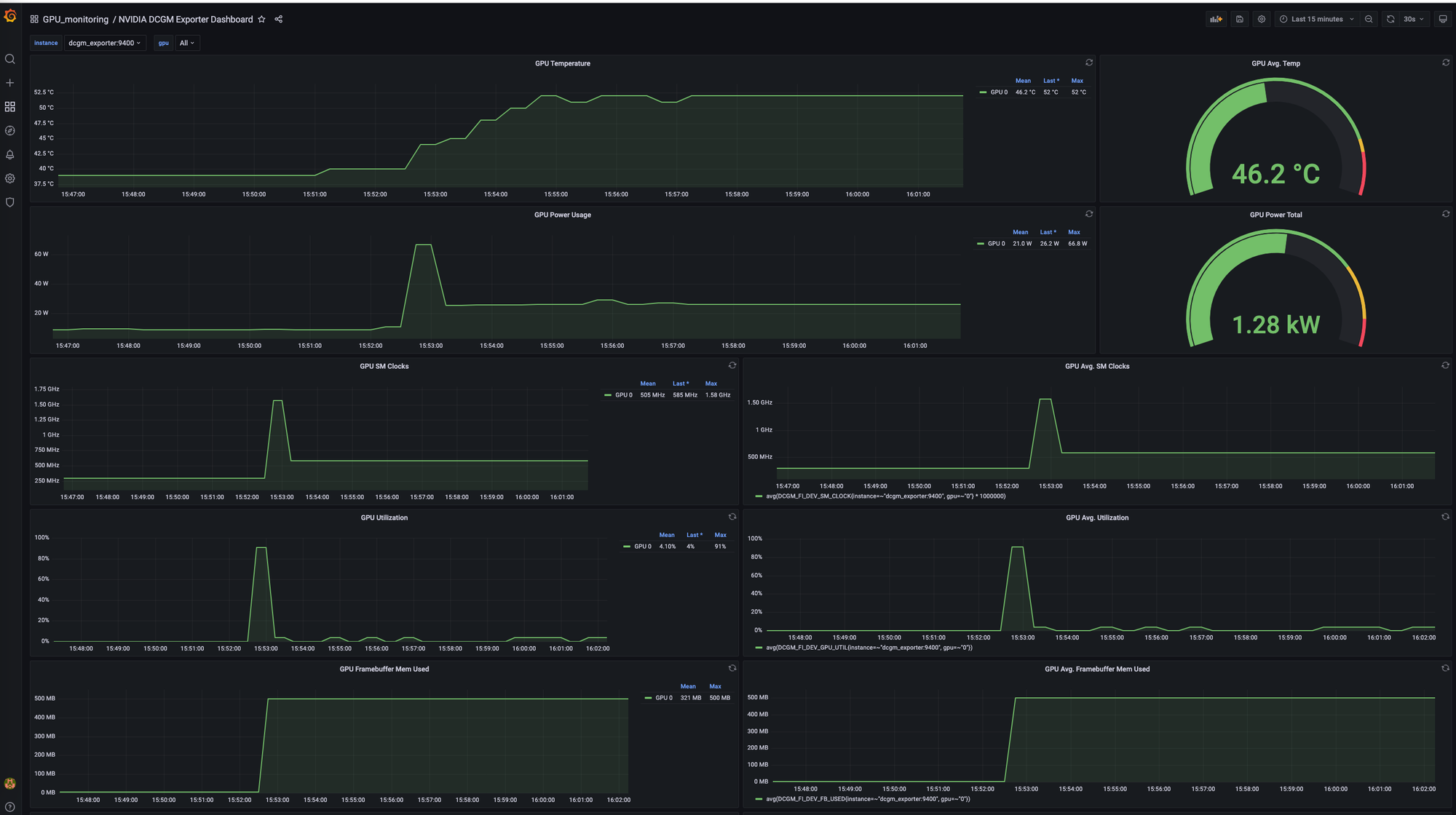
Opening http://localhost:3000 will show the Grafana interface (follow the instructions in the repository README about how to log into Grafana). You should see a dashboard like the one below:
docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04Then you will see this error:
Failed to watch metrics: Error watching fields: Host engine is running as non-root"Instead you need to give the docker container admin capability and run the command like so
docker run --gpus all --cap-add SYS_ADMIN -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04Conclusion: Optimizing Performance and Cost with GPU-Aware Docker
By following these steps and leveraging the power of metrics monitoring, you can ensure your Docker containers effectively utilize your NVIDIA GPUs. Fine-tuning your applications based on the insights gleaned from GPU metrics will lead to improved performance and cost savings. Remember, optimizing resource utilization is key to maximizing the return on your investment in powerful GPU hardware.
Alternative to Train and Deploy Models
Roboflow Train handles the training and deployment of your computer vision models for you.
Build and deploy with Roboflow for free
Use Roboflow to manage datasets, train models in one-click, and deploy to web, mobile, or the edge. With a few images, you can train a working computer vision model in an afternoon.
Next Steps
Now you know how to expose GPU Drivers to your running Docker container using the NVIDIA Container Toolkit. You should be able to use your GPU drivers and run Docker compose without running into any issues.
Want to use your new Docker capabilities to do something awesome? You might enjoy our other posts on training a state of the art object detection model, training a state of the art image classification model, or simply by looking into some free computer vision data.
Cite this Post
Use the following entry to cite this post in your research:
Sachin Agarwal, Jacob Solawetz. (Oct 22, 2024). How to Use Your GPU in a Docker Container. Roboflow Blog: https://blog.roboflow.com/use-the-gpu-in-docker/