
Software engineer Adam Crawshaw built an Android app that uses object detection to automatically score Uno hands, handling the multi-round point system most players overlook. Starting from 41 source card images, he used OpenCV to synthetically composite cards into stacked groups, producing a dataset of 8,992 images with 26,976 annotations, now publicly available on Roboflow Universe. The trained model runs on-device via TensorFlow Lite and sums the point value of any hand in real time.

You've likely been playing Uno wrong all of your life.
It's a simple game, right? Rid your hand of all your cards first, and you're the victor.
In fact, Uno is a multi-stage game where players accumulate points across multiple hands. The first player to 500 points wins. A player can earn points only once they have completely rid their hand of all their cards. The player earns points based on the types of cards their opponent has remaining in their hand.
Buried in the Official Uno Rules, there's critical Uno scoring details for how many points each card is worth:

Simply put: rid your hand of all your cards, and sum the point values of your opponent's hand. First to 500 points wins.
Uno is More Fun with Computer Vision
Adam Crawshaw is a software engineer living in Cardiff, Wales, and he's been playing quite a bit of Uno in COVID-19 quarantine.
"After many, many Uno games, you come to a point where tallying up all those cards can, frankly, get a little tiresome. I wanted to toy around with building an application that could sum those points totals for me."
Adam turned to computer vision as a means to automate the identification and summation of all of a given hand of Uno cards. Without burying the lede, his results are phenomenal:
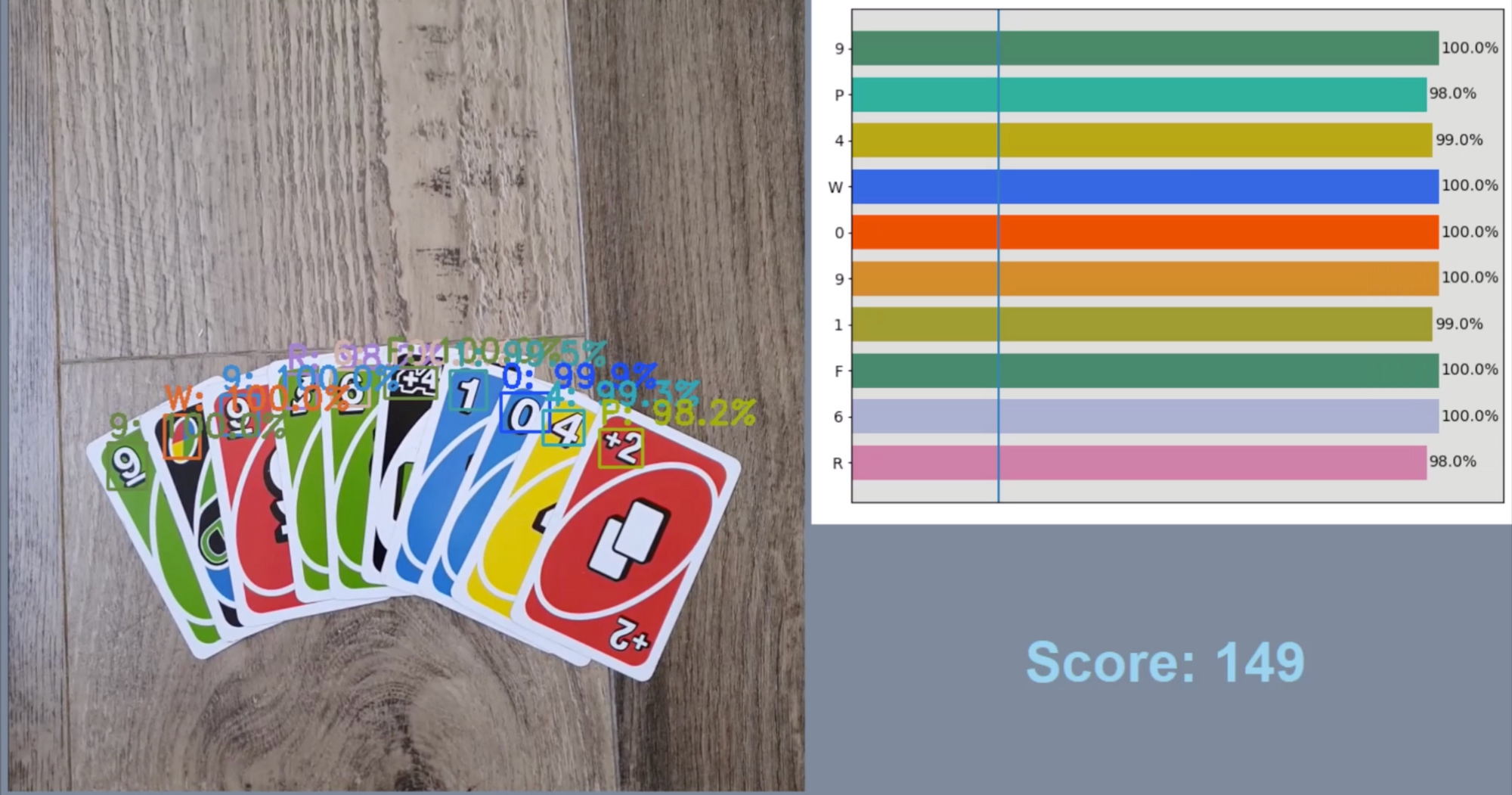
Using Object Detection to Score Uno
In order to build a system that scores Uno cards successfully, Adam needed to collect data, label it, assure the data resembled his test environment, preprocess it for a model, train a model, and deploy that model to a mobile device (Android, in his example).
Adam walked us through his process, and kindly even shared his full dataset below so you can reproduce his results.
Data Collection, Generation, and Labeling
Adam carefully collected one photo of each card in all its color varieties. This required capturing four photos of each 0, 2, 3, 4, 5, 6, 7, 8, 9, Skip, Draw 2, and Reverse plus one Wild and one Wild Draw Four – totaling 41 source raw source images.
Cleverly, Adam took advantage of synthetic data creation for computer vision. Specifically, he used Python's OpenCV package to do edge detection of his cards in order to layer cards on top of one in collections of three, randomly. This enabled him to create near infinite combinations of cards one might find in a hand.

Moreover, the background surfaces on which one plays Uno are not constant. There's a variety of different tabletop textures that a model would need to learn to "tune out" when searching for cards and their corresponding numbers. Thus, Adam turned to the Oxford Describable Textures Dataset (DTD) to create synthetic backgrounds for his data.








Adam would layer his Uno cards on top of these textures, but first, he would need to label each of the point values. Critically, only the upper-right hand corner on a card should be labeled. If the model identified the right-side up (upper right hand corner) and upside-down (bottom left hand corner) demarkations for an Uno card, it would count some cards twice. Consider our example of the 1, 3, and Draw Two above. If the model learned to identify the upside-down Draw Two, that card would be counted twice.

Ultimately, after labeling and placing cards on their unique backgrounds, Adam's dataset collection process was complete. All told, he generated 8,992 examples.

Interested in creating your own synthetic dataset? Follow synthetic dataset generation guide. Alternatively, get in touch to learn more about how we provide this as a service.
Data Preparation and Augmentation
Upon having his data collected and labeled, Adam turned to Roboflow, a dataset management platform, to preprocess, augment, and export his data in a variety of annotation formats to test multiple models.
Adam's images were all appropriately sized to squares (416x416) to support many model architectures. He was curious, moreover, how grayscale might affect his model performance, so he created multiple versions of his dataset that could fuel reproducible experimentation.
In addition, Roboflow's augmentation options enabled Adam to experiment with further increasing his dataset size with contextual augmentation options. For example, random crop augmentation simulates what a real-world scenario may be like where cards are in different portions of the camera frame and at various distances (sizes) relative to the person holding the mobile device.
Because of Roboflow's consistent versioning and ease of exporting the same dataset to any annotation format, Adam was able to trust the fairness of running head-to-head experiments.
"The data is right there; it's in the right format, and I know it's all there... It goes from God knows how many lines of code from whatever it needs to be to knowing my data is easily available in any environment."
Modeling
Given the application would need to perform real-time inference, Adam opted for models known to be small and mobile-friendly like YOLOv3 and MobileNetSSDv2.
Adam spun up training resources in Google Cloud Platform, leveraged the Roboflow Model Library for the base model architecture, dropped in his dataset URL from Roboflow, and was off to the races training.
Ultimately, Adam found YOLOv3 to be most performant for his use case – but he has recently begun to re-evaluate those results against YOLOv5.
Deployment
To deploy to a mobile device, Adam compiled his model as a TensorFlow Lite model, and dropped its outputs into an application he's carefully developed. Like that, he created an automatic Uno scorer always available in your pocket!
"All in, I have to say – it makes scoring Uno games a little bit simpler after having a few glasses of wine."
Releasing the Uno Object Detection Dataset
Adam Crawshaw was kind enough to release his 8,992 (and 26,976 annotations!) dataset for public use via Roboflow Public Datasets to be used alongside other free computer vision object detection datasets.

The dataset is released under a modified MIT license: The Hippocratic License 2.1. This enables anyone to use the dataset, even for commercial use, but in doing so, they abide by the terms to use the dataset ethically.
Now, what are you waiting for? Get started making your own Uno auto scoring application!
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Jun 28, 2020). Improving Uno with Computer Vision (Plus the Dataset so You Can Too). Roboflow Blog: https://blog.roboflow.com/improving-uno-with-computer-vision/